






 本文介绍了卷积神经网络在图像分类中的基本步骤,包括图片预处理、特征提取(通过感受野和滤波器)、参数共享以及池化层的应用,以降低过拟合风险。卷积层的弹性较小,专为图像处理设计,而全连接层则提供了更大的灵活性但易过拟合。
本文介绍了卷积神经网络在图像分类中的基本步骤,包括图片预处理、特征提取(通过感受野和滤波器)、参数共享以及池化层的应用,以降低过拟合风险。卷积层的弹性较小,专为图像处理设计,而全连接层则提供了更大的灵活性但易过拟合。
卷积神经网络(CNN)
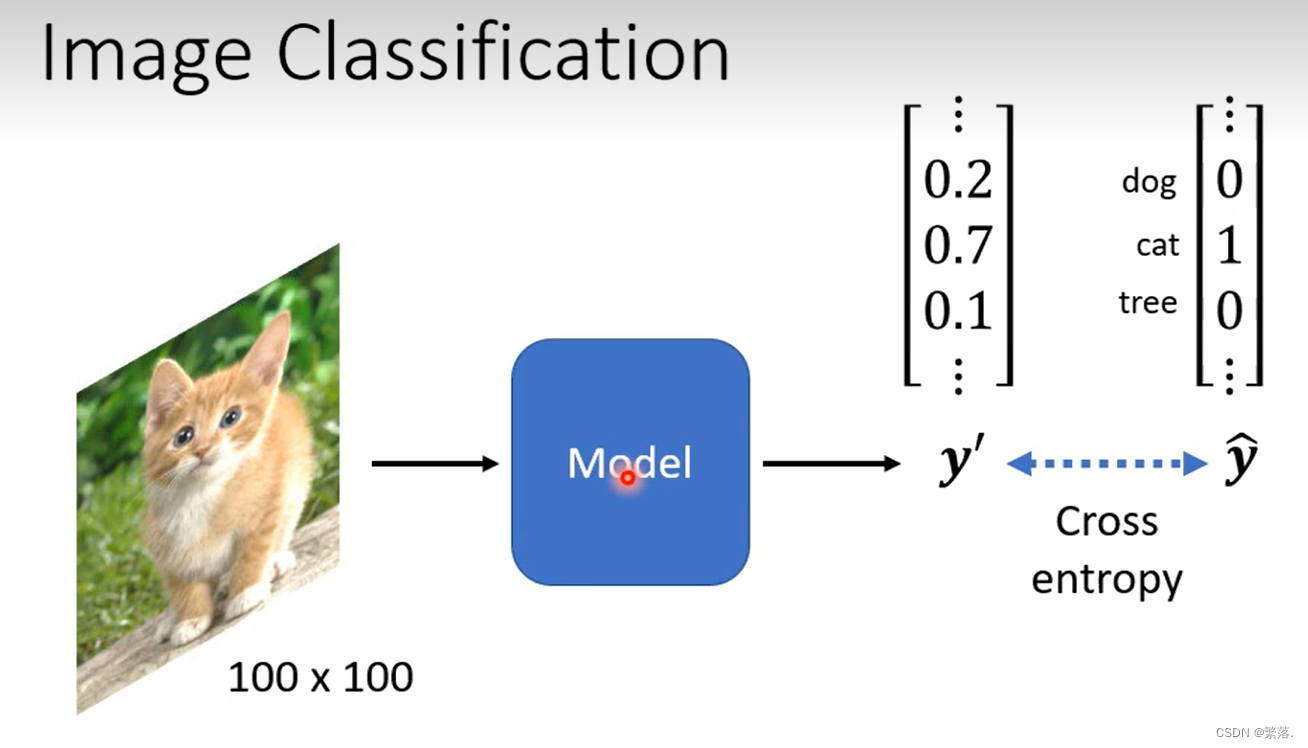
应用:Image Classification
基本步骤:
- 把所有图片都先 Rescale 成大小一样
- 把每一个类别,表示成一个 One-Hot 的 Vector(Dimension 的长度就决定了模型可以辨识出多少不同种类的东西,)
- 将图像【输入】到模型中
如何将图片输入到模型中去:

神经网络的输入是向量表示的,可以将图片表示为H*W*C的tensor,H表示长,W表示款,C表示通道数。将H*W*C的tensor可以展开为一个长为H*W*C的向量。从而输入到神经网络中。在本例中,H=100,W=100,C=3,就生成了一个长度为30000的向量。
但这样会存在一个问题:参数量过大

如果输入的向量长度是 100 × 100×3,有 1000 个 Neuron,那我们现在第一层的 Weight,就有 1000×100 × 100×3,也就是 3×10 的 7 次方,是一个非常巨大的数目。
虽然随著参数的增加,我们可以增加模型的弹性,我们可以增加它的能力,但是我们也增加了 Overfitting 的风险。
思考:**考虑到影像辨识这个问题本身的特性,其实我们并不一定需要 Fully Connected,不需要每一个 Neuron跟 Input的每一个 Dimension 都有一个 Weight
理解CNN的方式一:通过神经元角度
观察一:模型通过识别一些“特定模式”来识别物体,而非“整张图”
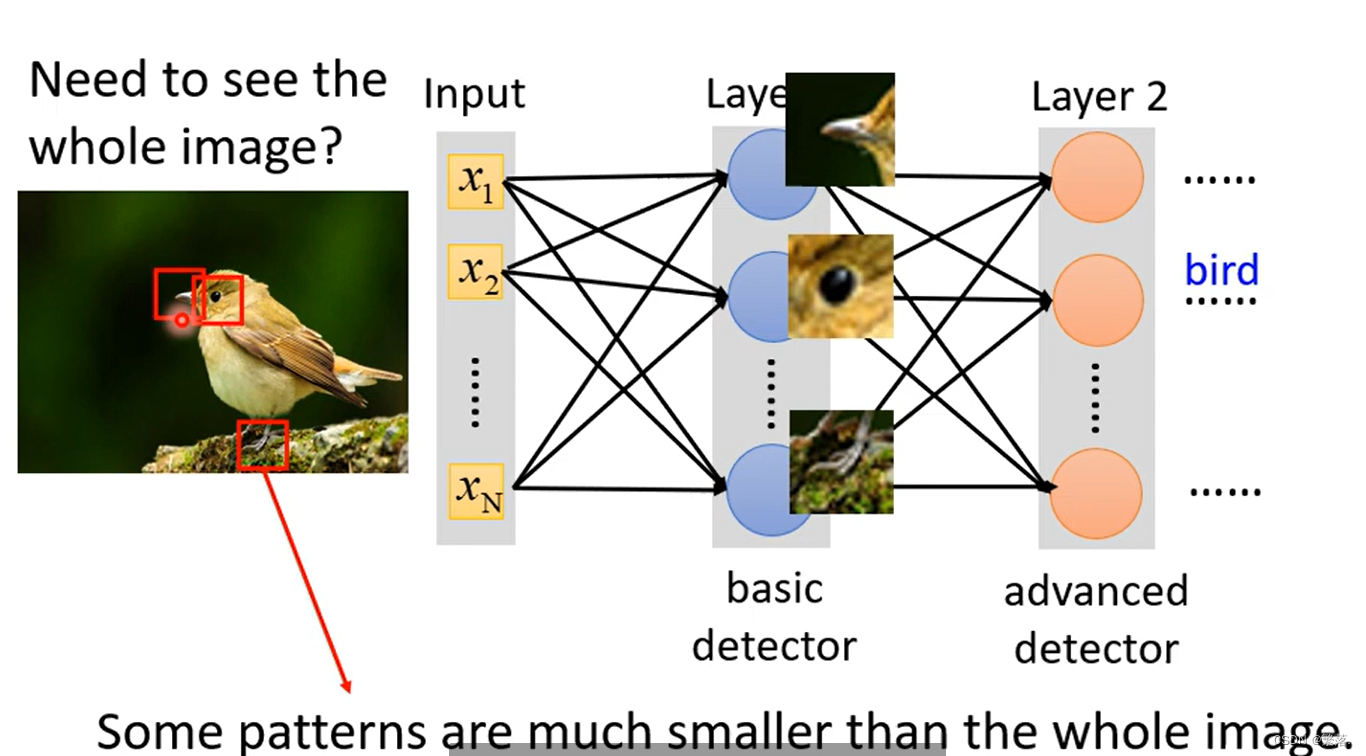
Neuron 也许根本就不需要,把整张图片当作输入,它们只需要把图片的一小部分当作输入,就足以让它们侦测某些特别关键的 Pattern有没有出现了
简化(1):设定“感受野”(Receptive Field)
每个神经元只需要考察特定范围内的图像信息,将图像内容展平后输入到神经元中即可。
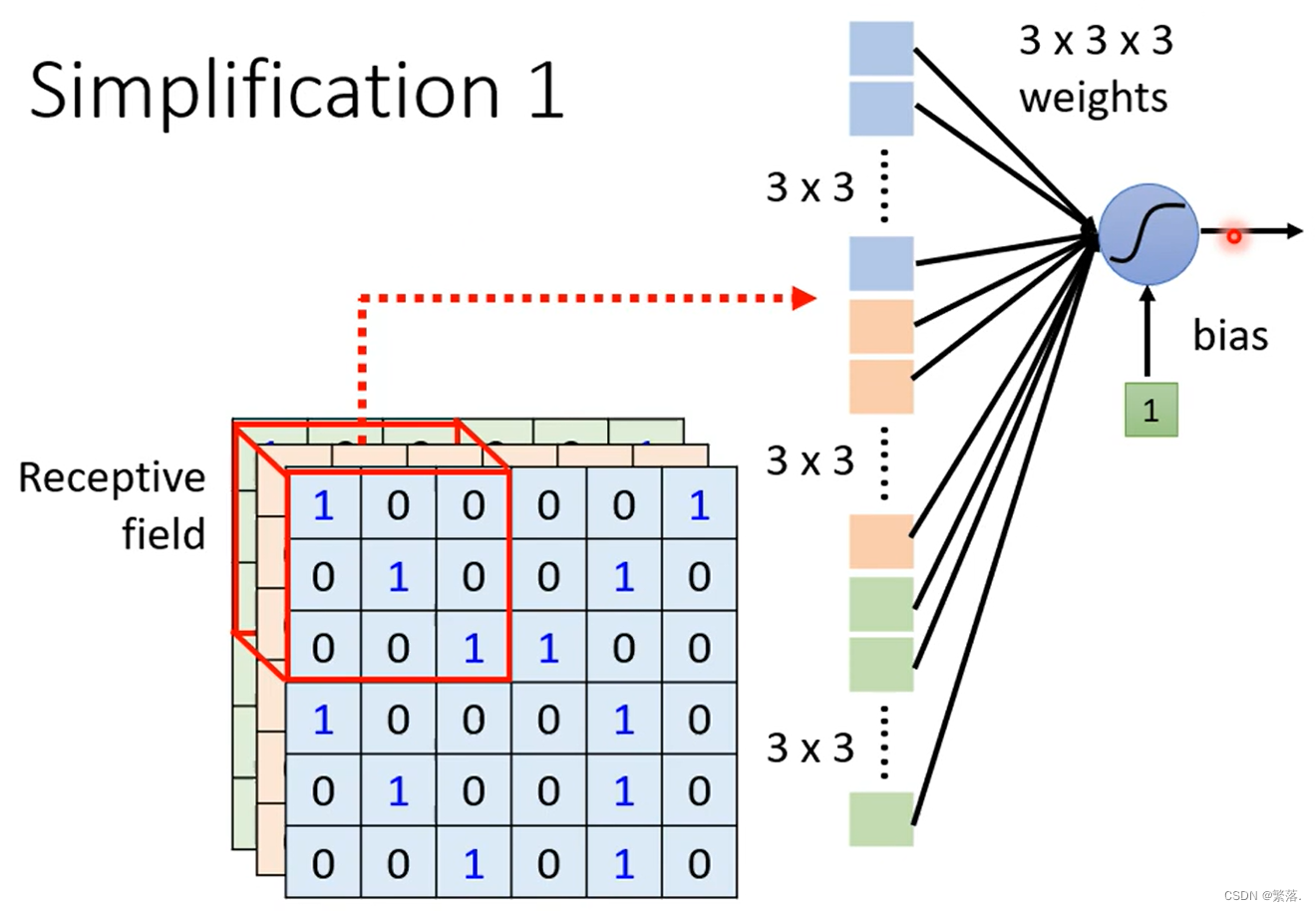
- 感受野之间可以重叠
- 一个感受野可以有多个神经元“守备”
- 感受野大小可以“有大有小”
- 感受野可以只考虑某一些Channel
- 感受野可以是“长方形”的
- 感受野不一定要“相连”
观察二:数据共享

同样的pattern,可能在图像上的不同位置,如果每一个神经元都放一个检测鸟嘴的感受野,所需数据量太大。
简化二:共享参数
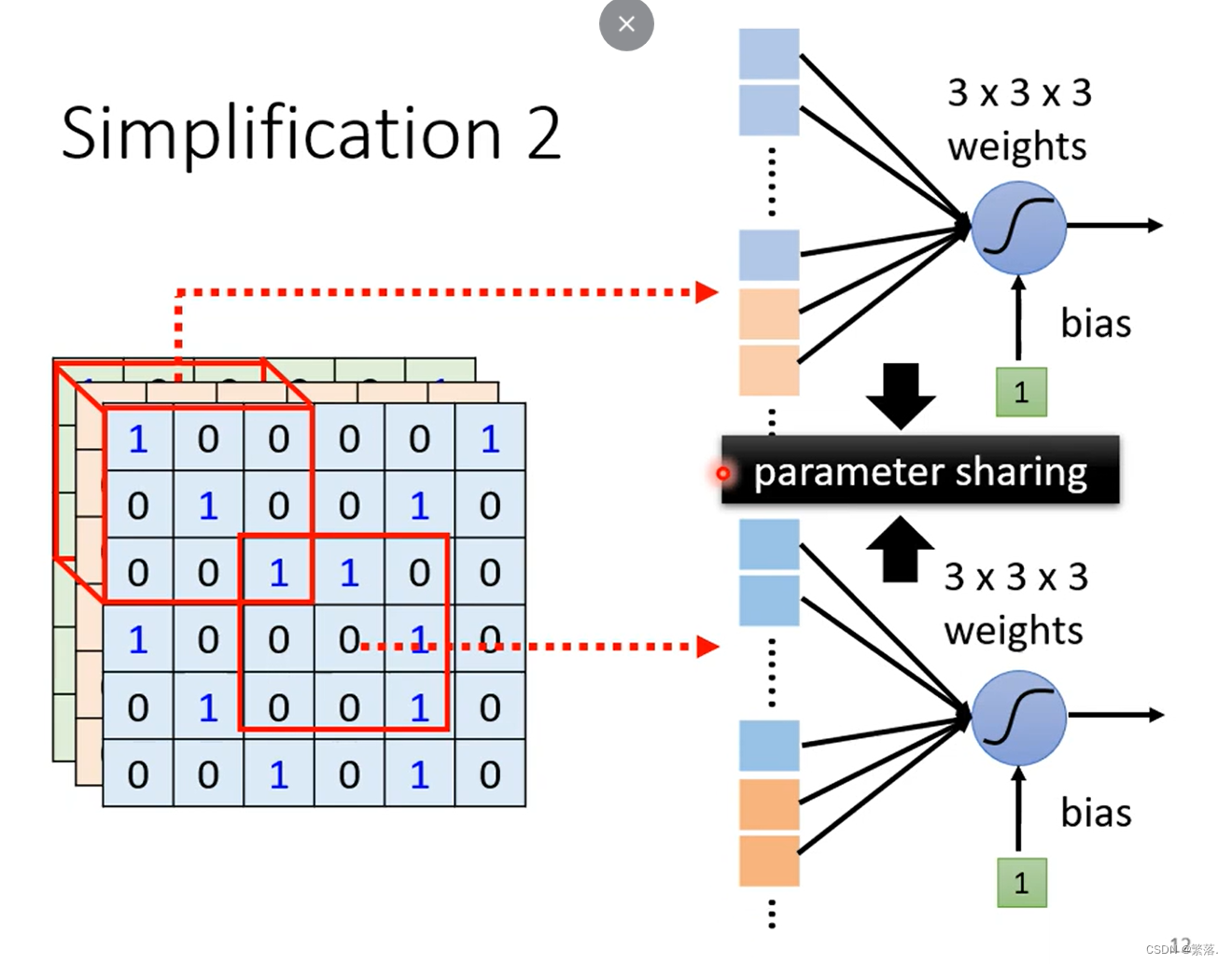
神经元守备的 Receptive Field 不一样,但是它们的参数一模一样。(守备相同感受野的神经元,不希望参数一样,否则无意义)
总之,每一个感受野都由一组相同的神经元守备,由于输入的不同,导致了输出的差异。
卷积层的优势
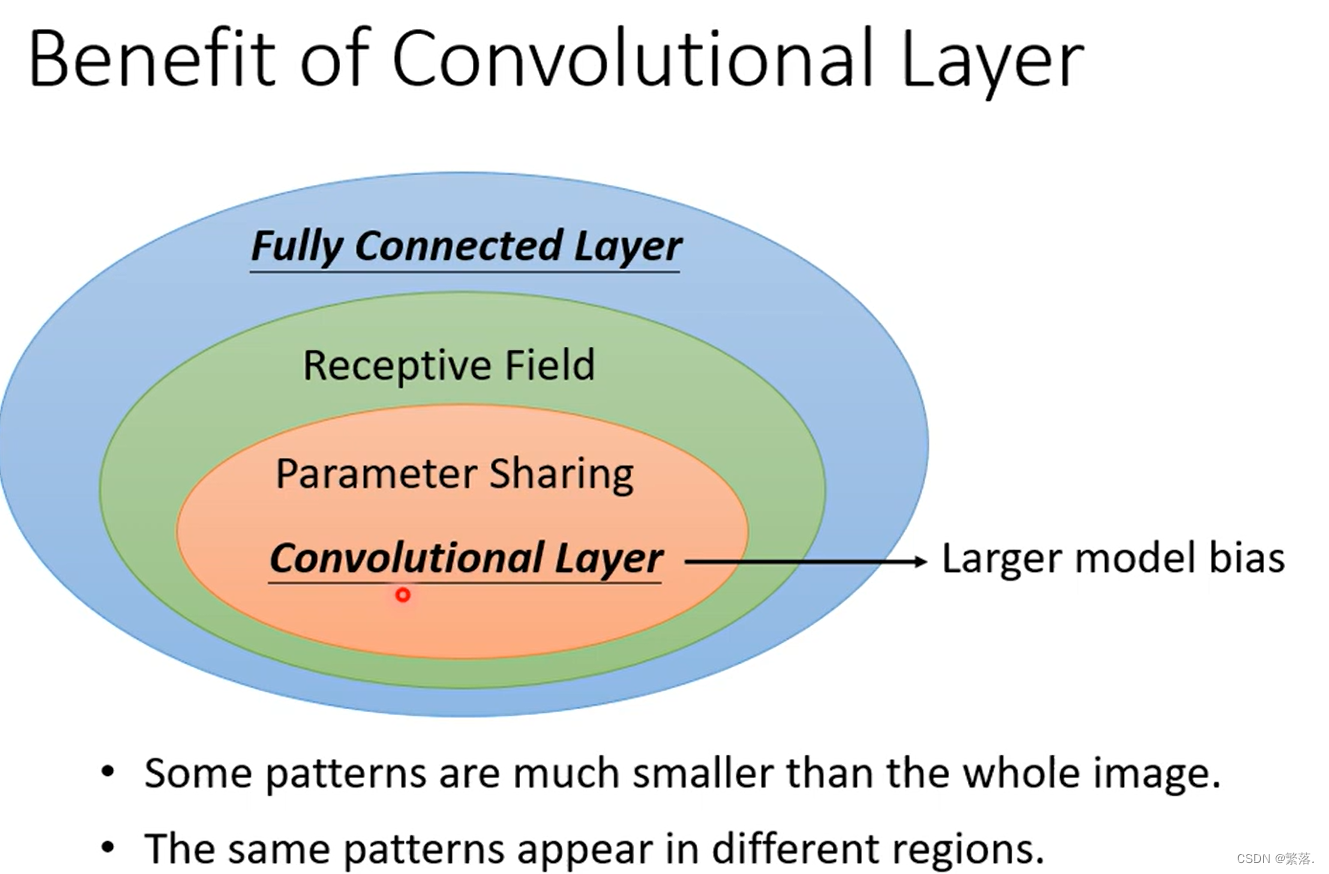
卷积层可以使模型的弹性变小
总结:
- 一般而言,Model Bias 小,Model 的 Flexibility 很高的时候,它比较容易 Overfitting,Fully Connected Layer可以做各式各样的事情,它可以有各式各样的变化,但是它可能没有办法在任何特定的任务上做好
- CNN 的 Bias 比较大,它是专门為影像设计的,所以它在影像上仍然可以做得好。
理解神经元的方式二:Filter(滤波器)角度
卷积层中有若干个filter,每个filter可以用来“抓取”图片中的某一种特征(特征pattern的大小,小于感受野大小)。filter的参数,其实就是神经元中的“权值(weight)”。
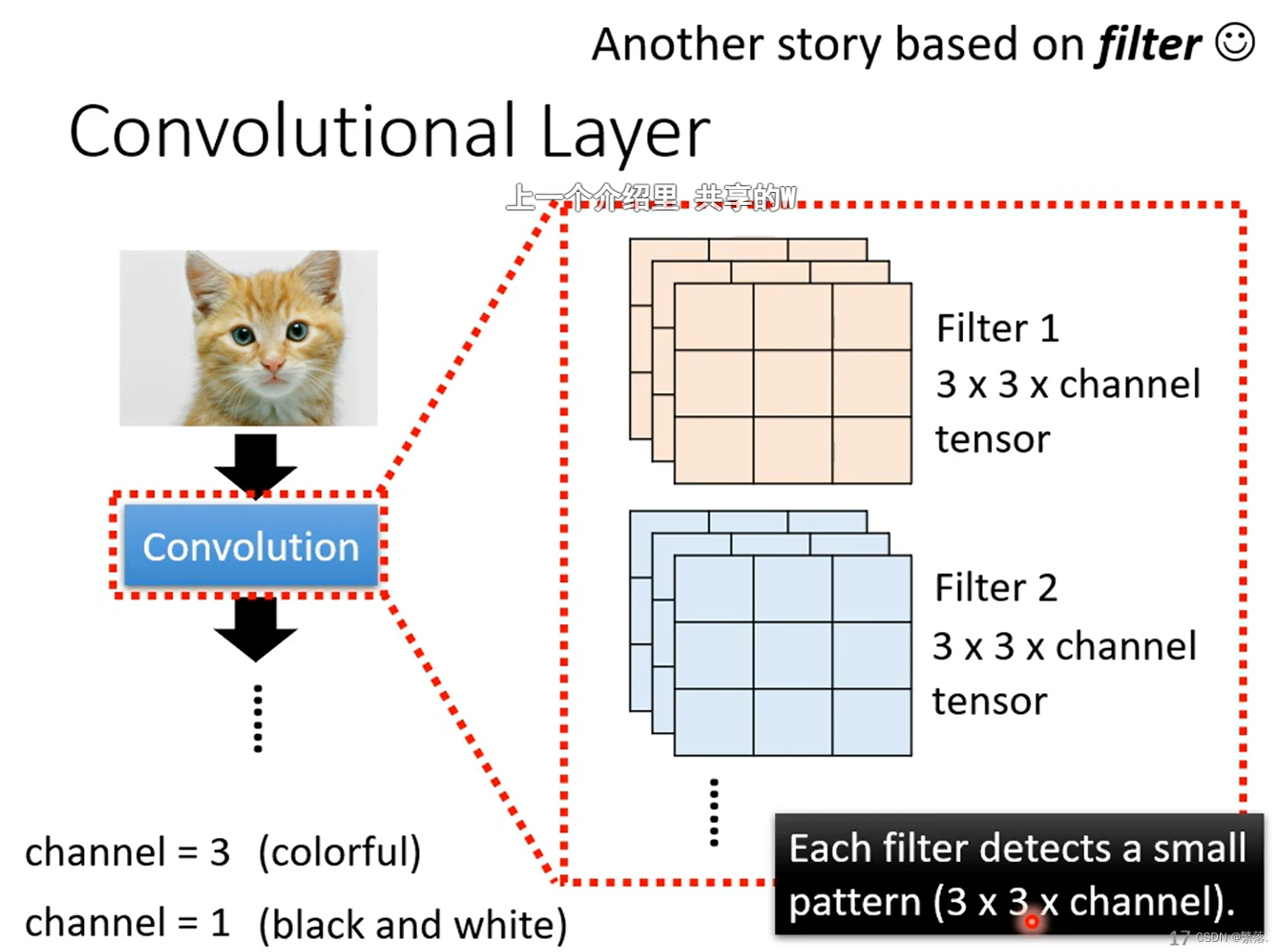
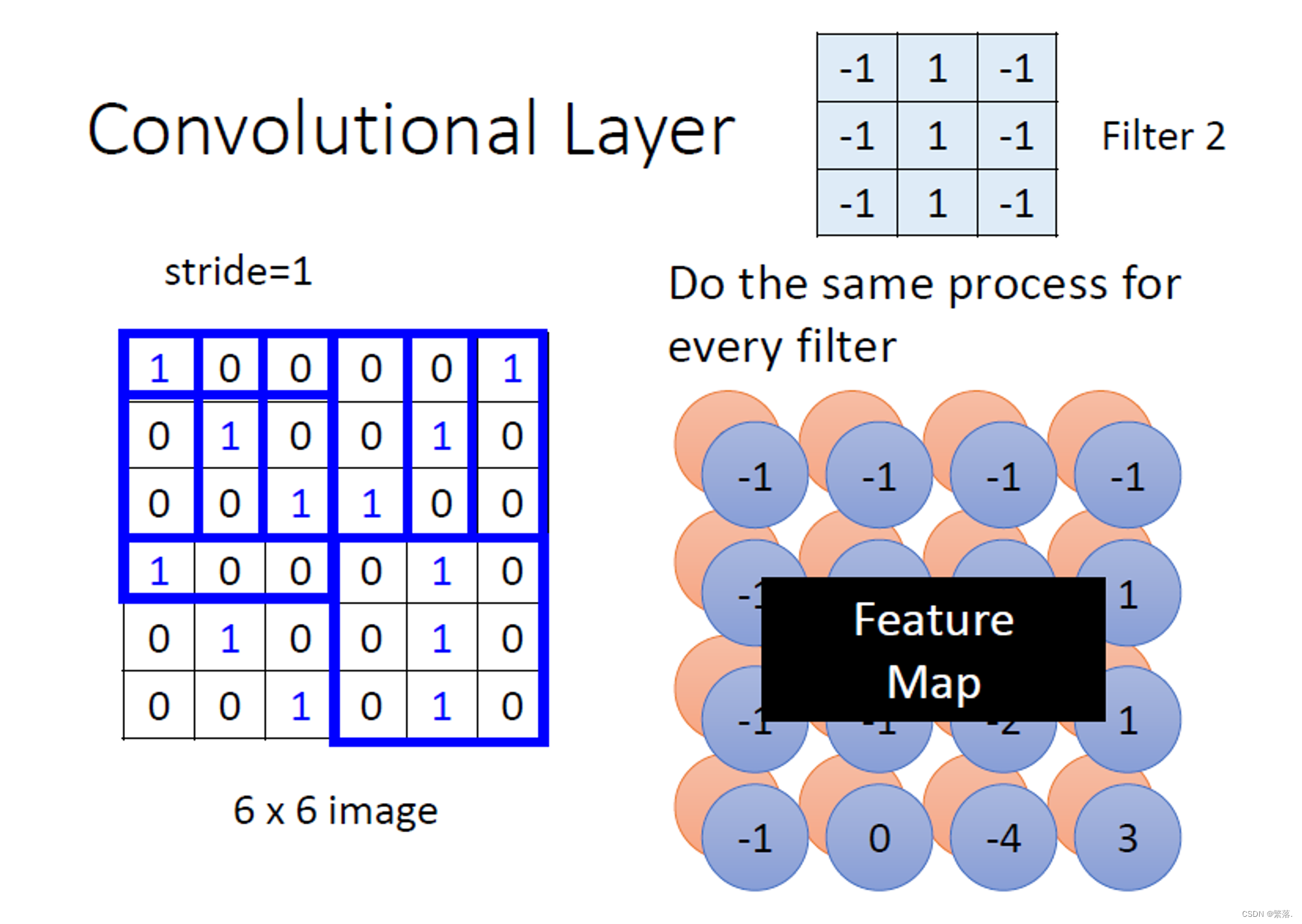
不同的filter扫过一张图片,将会产生“新的图片”,每个filter将会产生图片中的一个channel⇒feature map
filter的计算是**“内积”**:filter跟图片对应位置的数值直接相乘,所有的都乘完以后再相加。
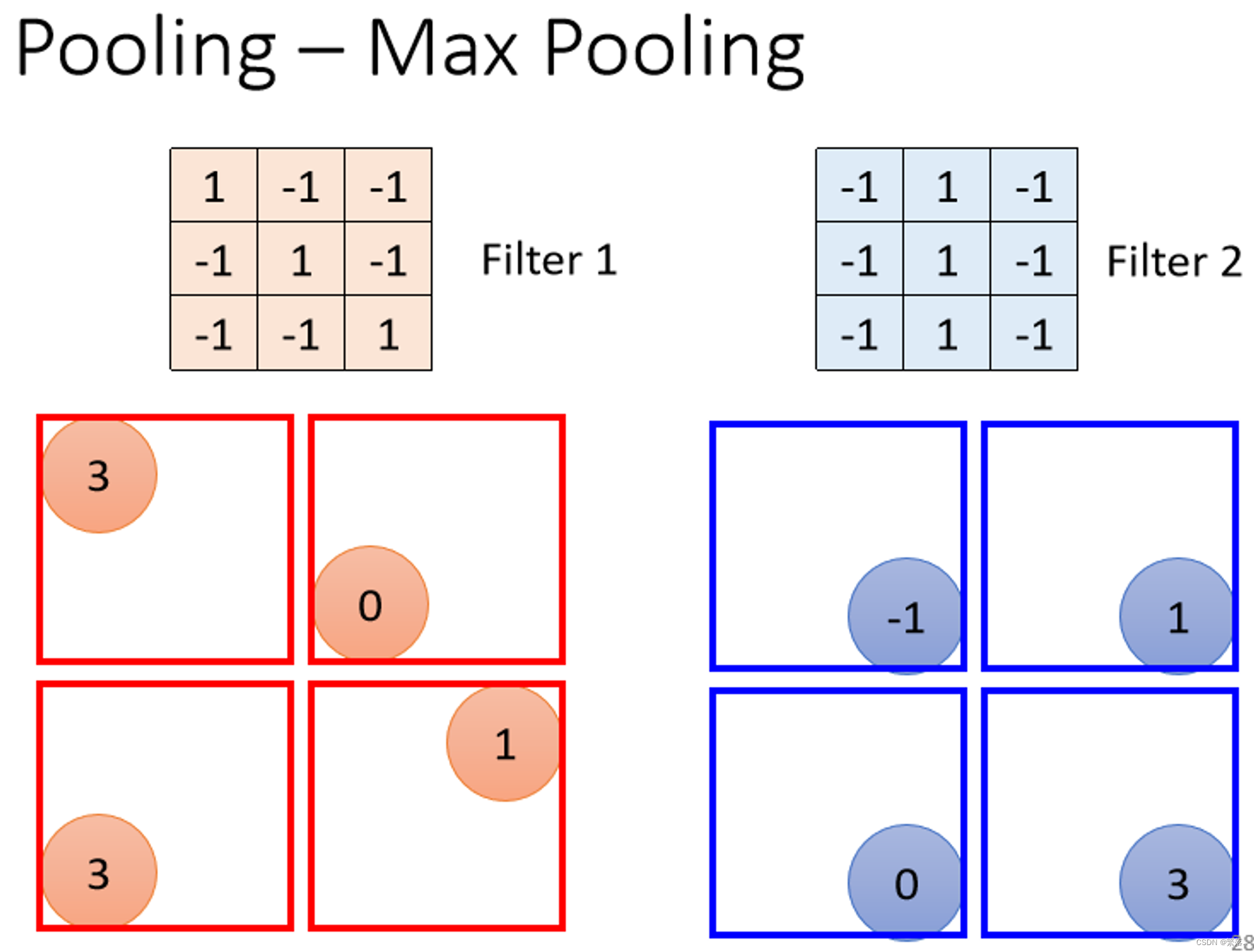
Pooling:池化层
池化的操作,会在保留原始图片特征不变的情况下,将图片尺寸缩小,从而减少整个模型的计算量。

Max pooling
就是将给定范围内最大的数字留下,其余删去

Mean Pooling
就是在给定范围内求平均
一般,卷积和池化都是交替操作的,比如使用两个卷积后使用一个池化
The whole CNN
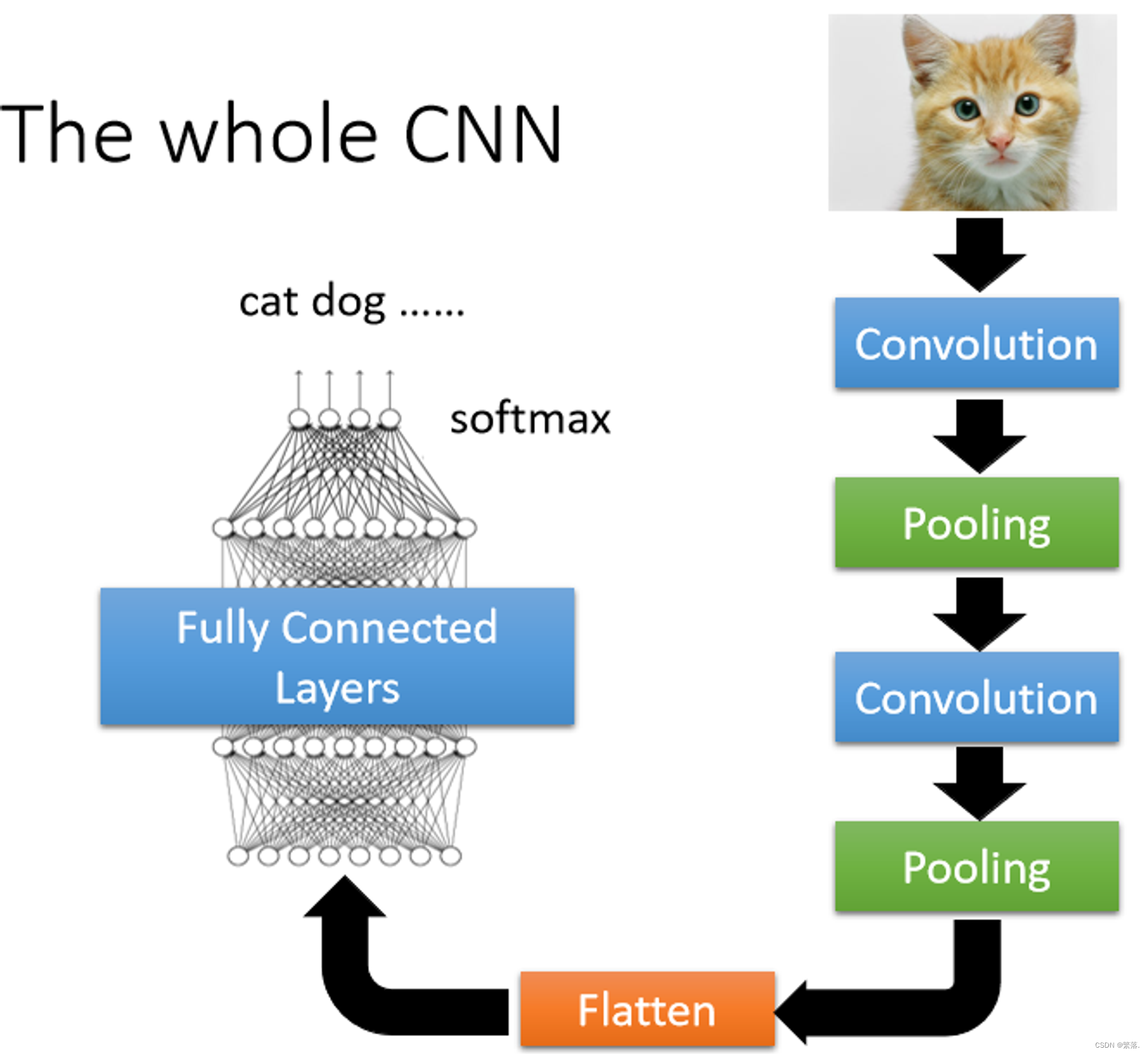
- 首先经过一系列卷积池化操作提取特征
- 经提取的特征矩阵经过Flatten拉直成一个向量
- 将向量输入到全连接网络
- 最后经过一个softmax进行输出















 3985
3985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









