






第1关:Pandas分组聚合
任务描述
本关任务:使用Pandas加载drinks.csv文件中的数据,根据数据信息求每个大洲红酒消耗量的最大值与最小值的差以及啤酒消耗量的和。
相关知识
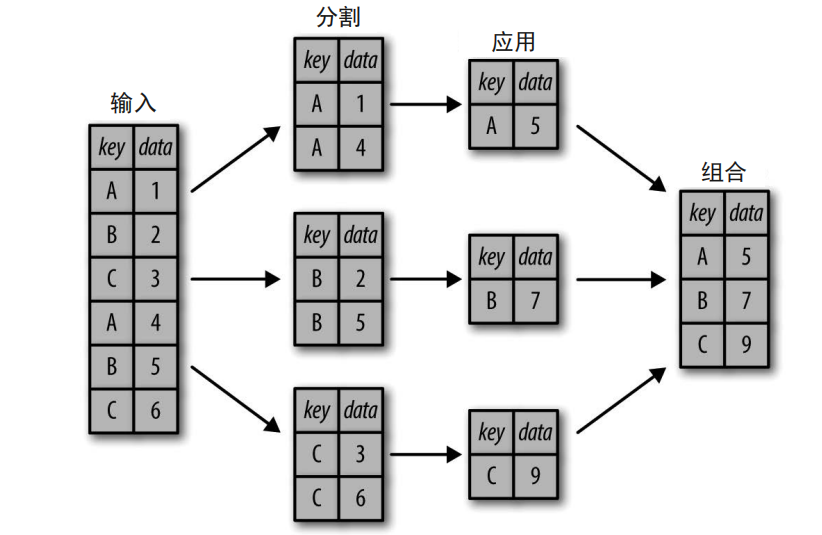
分组聚合的流程主要有三步:
分割步骤将DataFrame按照指定的键分割成若干组;
应用步骤对每个组应用函数,通常是累计、转换或过滤函数;
组合步骤将每一组的结果合并成一个输出数组。
分组
通常我们将数据分成多个集合的操作称之为分组,Pandas中使用groupby()函数来实现分组操作。
单列和多列分组
对分组后的子集进行数值运算时,不是数值的列会自动过滤
import pandas as pd
data = {'A': [1, 2, 2, 3, 2, 4],
'B': [2014, 2015, 2014, 2014, 2015, 2017],
'C': ["a", "b", "c", "d", "e", "f"],
'D': [0.5, 0.9, 2.1, 1.5, 0.5, 0.1]
}
df = pd.DataFrame(data)
df.groupby("B") #单列分组 返回的是一个groupby对象
df.groupby(["B","C"]) #多列分组Series系列分组
选取数据帧中的一列作为index进行分组:
df["A"].groupby(df["B"]) #df的 A 列根据 B 进行分组通过数据类型或者字典分组
数据类型分组:
df.groupby(df.dtypes,axis=1) # axis=1表示按列分组,以数据类型为列名传入字典分组:
dic = {"A": "number", "B": "number", "C": "str", "D": "number"}
df.groupby(dic, axis=1) #按列分组,列名是字典的值获取单个分组
使用get_group()方法可以选择一个组。
df.groupby("A").get_group(2)输出:
A B C D
1 2 2015 b 0.9
2 2 2014 c 2.1
4 2 2015 e 0.5对分组进行迭代
GroupBy对象支持迭代,可以产生一组二元元组(由分组名和数据块组成)。
for name,data in df.groupby("A"):
print(name)
print(data)输出:
1
A B C D
0 1 2014 a 0.5
2
A B C D
1 2 2015 b 0.9
2 2 2014 c 2.1
4 2 2015 e 0.5
3
A B C D
3 3 2014 d 1.5
4
A B C D
5 4 2017 f 0.1聚合
聚合函数为每个组返回单个聚合值。当创建了groupby对象,就可以对分组数据执行多个聚合操作。比较常用的是通过聚合函数或等效的agg方法聚合。常用的聚合函数如下表:
函数名 | 说明 |
count | 分组中非空值的数量 |
sum | 非空值的和 |
mean | 非空值的平均值 |
median | 非空值的中位数 |
std、var | 无偏标准差和方差 |
min、max | 非空值的最小和最大值 |
prod | 非空值的积 |
first、last | 第一个和最后一个非空值 |
应用单个聚合函数
对分组后的子集进行数值运算时,不是数值的列会自动过滤
import pandas as pd
import numpy as np
data = {'A': [1, 2, 2, 3, 2, 4],
'B': [2014, 2015, 2014, 2014, 2015, 2017],
'C': ["a", "b", "c", "d", "e", "f"],
'D': [0.5, 0.9, 2.1, 1.5, 0.5, 0.1]
}
df = pd.DataFrame(data)
df.groupby("B").sum() #对分组进行求和应用多个聚合函数
df.groupby("B").agg([np.sum,np.mean,np.std])自定义函数传入agg()中
def result(df):
return df.max() - df.min()
df.groupby("B").agg(result) #求每一组最大值与最小值的差对不同的列使用不同的聚合函数
mapping = {"A":np.sum,"B":np.mean}
df.groupby("C").agg(mapping)编程要求
使用Pandas中的read_csv()函数读取step1/drinks.csv中的数据,数据的列名如下表所示,请根据continent分组并求每个大洲红酒消耗量的最大值与最小值的差以及啤酒消耗量的和。在右侧编辑器begin-end处补充代码。
列名 | 说明 |
country | 国家名 |
beer_servings | 啤酒消耗量 |
spirit_servings | 白酒消耗量 |
wine_servings | 红酒消耗量 |
total_litres_of_pure_alcohol | 纯酒精总量 |
continent | 大洲名 |
测试说明
平台会对你编写的代码进行测试:
测试输入:预期输出:
wine_servings beer_servings
continent
Africa 233 3258
Asia 123 1630
Europe 370 8720
North America 99 3345
Oceania 212 1435
South America 220 2101import pandas as pd
import numpy as np
#返回最大值与最小值的差
def sub(df):
######## Begin #######
return df.max()-df.min()
######## End #######
def main():
######## Begin #######
data = pd.read_csv("step1/drinks.csv",header = 0)
df = pd.DataFrame(data)
mapping = {"wine_servings":sub,"beer_servings":np.sum}
print(df.groupby("continent").agg(mapping))
######## End #######
if __name__ == '__main__':
main()
第2关:Pandas创建透视表和交叉表
任务描述
本关任务:使用Pandas加载tip.csv文件中的数据集,分别用透视表和交叉表统计顾客在每种用餐时间、每个星期下的小费总和情况。
相关知识
透视表
透视表是各种电子表格程序和其他数据分析软件中一种常见的数据汇总工具。它根据一个或多个键对数据进行聚合,并根据行和列上得分组建将数据分配到各个矩形区域中。在pandas中,可以通过pivot_table函数创建透视表。
pivot_talbe函数的参数:
DataFrame.pivot_table(self, values=None, index=None, columns=None,ggfunc='mean', fill_value=None, .margins=False,dropna=True, margins_name='All')参数名 | 说明 |
values | 待聚合的列的名称。默认聚合所有数值列 |
index | 用于分组的列名或其他分组键,出现在结果透视表的行 |
columns | 用于分组的列名或其他分组键,出现在结果透视表的列 |
aggfunc | 聚合函数或函数列表,默认为mean,可以是任何对groupby有效的函数 |
fill_value | 用于替换结果表中的缺失值 |
dropna | boolean值,默认为True |
margins_name | string,默认为‘ALL’,当参数margins为True时,ALL行和列的名字 |
示例:
data = {'A': [1, 2, 2, 3, 2, 4],
'B': [2014, 2015, 2014, 2014, 2015, 2017],
'C': ["a", "b", "c", "d", "e", "f"],
'D': [0.5, 0.9, 2.1, 1.5, 0.5, 0.1]
}
df = pd.DataFrame(data)
df.pivot_table(index=["B"], columns=["C"], values=["A"], aggfunc=sum, margins=True)输出:
A
C a b c d e f All
B
2014 1.0 NaN 2.0 3.0 NaN NaN 6
2015 NaN 2.0 NaN NaN 2.0 NaN 4
2017 NaN NaN NaN NaN NaN 4.0 4
All 1.0 2.0 2.0 3.0 2.0 4.0 14交叉表
交叉表是一种用于计算分组频率的特殊透视表。通常使用crosstab函数来创建交叉表。
crosstab的参数
pd.crosstab(index,columns,values=None,rownames=None
colnames=None,aggfunc=None,margins=False,dropna=True,normalize=False)其中rownames可以设置行名,colnames可以设置列名,而且前两个参数可以是数组、Series或数组列表。
示例:
data = {'A': [1, 2, 2, 3, 2, 4],
'B': [2014, 2015, 2014, 2014, 2015, 2017],
'C': ["a", "b", "c", "d", "e", "f"],
'D': [0.5, 0.9, 2.1, 1.5, 0.5, 0.1]
}
df = pd.DataFrame(data)
pd.crosstab(index=[df["B"],df["A"]], columns=df["C"], values=df["A"], aggfunc=sum, margins=True)输出:
C a b c d e f All
B A
2014 1 1.0 NaN NaN NaN NaN NaN 1
2 NaN NaN 2.0 NaN NaN NaN 2
3 NaN NaN NaN 3.0 NaN NaN 3
2015 2 NaN 2.0 NaN NaN 2.0 NaN 4
2017 4 NaN NaN NaN NaN NaN 4.0 4
All 1.0 2.0 2.0 3.0 2.0 4.0 14编程要求
使用Pandas中的read_csv函数加载step2/tip.csv文件中的数据集,分别用透视表和交叉表统计顾客在每种用餐时间(time) 、每个星期下(day) 的 小费(tip)总和情况。在右侧编辑器begin-end处补充代码。
数据集列名信息如下表:
列名 | 说明 |
total_bill | 消费总账单 |
tip | 小费金额 |
day | 消费日期(星期几) |
time | 用餐时间段(早、中、晚) |
size | 吸烟数量 |
测试说明
平台会对你编写的代码进行测试:
测试输入:预期输出:
透视表:
tip
time Dinner Lunch All
day
Fri 35.28 16.68 51.96
Sat 260.40 NaN 260.40
Sun 247.39 NaN 247.39
Thur 3.00 168.83 171.83
All 546.07 185.51 731.58
交叉表:
time Dinner Lunch All
day
Fri 35.28 16.68 51.96
Sat 260.40 NaN 260.40
Sun 247.39 NaN 247.39
Thur 3.00 168.83 171.83
All 546.07 185.51 731.58#-*- coding: utf-8 -*-
import pandas as pd
#创建透视表
def create_pivottalbe(data):
###### Begin ######
return data.pivot_table(index = ['day'],columns = ['time'],values = ['tip'],aggfunc = sum , margins = True)
###### End ######
#创建交叉表
def create_crosstab(data):
###### Begin ######
df = pd.DataFrame(data)
y = pd.crosstab(index = df['day'],columns = df['time'],values = df['tip'],aggfunc =sum,margins = True)
return y
###### End ######
def main():
#读取csv文件数据并赋值给data
###### Begin ######
data = pd.read_csv("step2/tip.csv",header = 0)
###### End ######
piv_result = create_pivottalbe(data)
cro_result = create_crosstab(data)
print("透视表:\n{}".format(piv_result))
print("交叉表:\n{}".format(cro_result))
if __name__ == '__main__':
main()
















 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











