






第1关:循环神经网络
任务描述
本关任务:通过学习循环神经网络的相关知识,完成单向循环网络的编写。
相关知识
为了完成本关任务,你需要掌握:
- 循环神经网络概述;
- 一般循环神经网络;
- 单向循环神经网络。
循环神经网络概述
对于我们已经学过的传统神经网络,它们能够实现分类以及标注任务,但一旦处理具有前后遗存关系的数据时,效果就不是十分理想了。这个问题主要由于传统神经网络的结构所导致。这时我们就需要一个不仅仅只依赖当前的输入,还需要结合前一时刻或后一时刻的输入作为参考。 循环神经网络就是根据这样的需求而设计的。循环神经网络的主要用途是处理和预测序列数据。循环神经网络最初就是为了刻画一个序列当前的输出与之前信息的关系。从网络结构上来看,循环神经网络会记忆之前的信息,并利用之前的信息影响后面节点的输出。也就是说,循环神经网络的隐藏层之间的节点是有连接的,隐藏层的输入不仅包含输入层的输出,还包括上一时刻隐藏层的输出。
一般循环神经网络
传统的神经网络结构一般分为三层:输入层、隐藏层、输出层。输入层的输入经过加权计算输出到隐藏层,作为隐藏层的输入。隐藏层再对从输入层得到的输入进行加权计算输入到输出层,最后通过激活函数,由输出层输出最终的结果。循环神经网络的结构与其十分的相似,都是由输入层、隐藏层和输出层构成,最大的区别在于循环神经网络的隐藏层多了一个自身到自身的环形连接,其结构如图 1 所示:
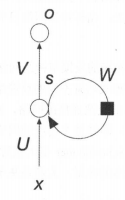
图1 循环神经网络结构示例
其中,x表示输入层,s表示隐藏层的输出,o表示输出层的值。U是输入x特征与隐藏层神经元全连接的权重矩阵,V则是隐藏层与输出层全连接的权值矩阵。o的输出由权值矩阵V和隐藏层输出s决定。s的输出不仅仅由权值矩阵U以及输入x来决定,还要依赖于新的权值矩阵W以及上一次s的输出。其中,W表示上一次隐藏层的输出到这一次隐藏层输入的权值矩阵。该层被称为循环层。
单向循环神经网络
将一般循环神经如图2所示展开便是单向循环神经网络:
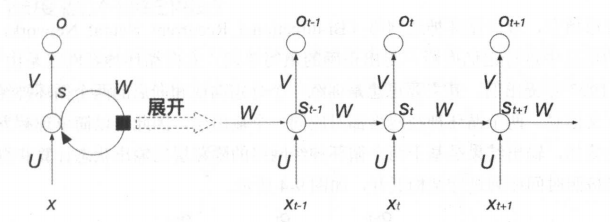
图2 单向循环神经网络结构示例
对于单向循环神经网络的结构,你可以理解为网络的输入通过时间进行向后传播。当前隐藏层的输出st除了取决于当前的输入层的输入向量xt外,还受到上一时刻隐藏层的输出向量st+1的影响,因此,当前时刻隐藏层的输出信息包含了 之前时刻的信息,表现出对之前信息记忆的能力 。 可以采用如下公式对单向循环神经网络进行表示 :
ot=g(Vst)st=f(Uxt+Wst−1)
其中ot表示输出层的结果,g为输出层的激活函数,V为输出层的权值矩阵。st表示隐藏层的结果,它由当前时刻的输入层输入xt以及上一时刻隐藏层输出st−1共同决定,U表示输入层到隐藏层的权值矩阵,W为上一时刻的值st−1到这一次输入的权值矩阵,f为隐藏层的激活函数。循环神经网络的递归数学式如下所示:
ot=g(Vst)=Vf(Uxt+Wst−1)=Vf(Uxt+Wf(Uxt−1+Wst−2))=Vf(Uxt+Wf(Uxt−1+Wf(Uxt−2+⋯)))=…
编程要求
根据提示,在右侧编辑器 Begin-End 区间补充代码,完善循环神经网络的网络模型。
测试说明
平台会对你编写的代码进行测试:
测试输入:无 预期输出: init success! rnn success!
提示:
- 循环神经网络的初始状态全部为零;
- 隐藏层的结果需要经过激活后再传入输出层,本次实训采用
tanh函数作为激活函数,可以使用torch.tanh()函数; - 矩阵相乘可以使用
torch.matmul(a,b)函数。
import torch
def rnn(input,state,params):
"""
循环神经网络的前向传播
:param input: 输入,形状为 [ batch_size,num_inputs ]
:param state: 上一时刻循环神经网络的状态,形状为 [ batch_size,num_hiddens ]
:param params: 循环神经网络的所使用的权重以及偏置
:return: 输出结果和此时刻网络的状态
"""
W_xh,W_hh,b_h,W_hq,b_q = params
"""
W_xh : 输入层到隐藏层的权重
W_hh : 上一时刻状态隐藏层到当前时刻的权重
b_h : 隐藏层偏置
W_hq : 隐藏层到输出层的权重
b_q : 输出层偏置
"""
H = state
########## Begin ##########
# 输入层到隐藏层
H = torch.matmul(input, W_xh) + torch.matmul(H, W_hh) + b_h
H = torch.tanh(H)
# 隐藏层到输出层
Y = torch.matmul(H, W_hq) + b_q
########## End ##########
return Y,H
def init_rnn_state(num_inputs,num_hiddens):
"""
循环神经网络的初始状态的初始化
:param num_inputs: 输入层中神经元的个数
:param num_hiddens: 隐藏层中神经元的个数
:return: 循环神经网络初始状态
"""
########## Begin ##########
init_state = torch.zeros((num_inputs,num_hiddens),dtype=torch.float32)
########## End ##########
return init_state第2关:梯度消失与梯度爆炸
任务描述
本关任务:通过学习梯度消失与梯度爆炸相关知识,实现梯度裁剪法。
相关知识
为了完成本关任务,你需要掌握:
- BPTT算法;
- 梯度消失与梯度爆炸;
- 梯度裁剪法。
BPTT算法
循环神经网络在进行反向传播时,由于循环层包含两部分的输入,即当前时刻的输入与上一时刻循环层的输出,因此循环神经网络的训练算法相比较传统的神经网络训练算法多了 一步向前计算的过程,也被称为 BPTT(back propagation through time)。其基本步骤为:
- 向前计算每个神经元的输出值;
- 反向计算每个神经元的误差项的值;
- 计算每个权值的梯度,并采用梯度下降法更新权值。
可以看出和 BP 算法基本相同。
前向计算
前向计算主要是为了计算时刻t的隐藏层的输出st,其计算公式如下:
st=f(Wst−1+Uxt)
xt表示t时刻的输入,st−1表示t−1时刻的隐藏层输出,即上一时刻的隐藏层输出,W,U表示权值矩阵,f表示激活函数。假设输入x为m维,输出状态为n维,则矩阵U的大小为n×m,矩阵W的大小为n×n,将上式展开:
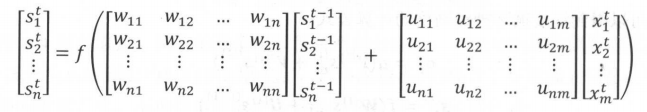
wji表示t−1时刻隐藏层神经元i与t时刻神经元j的连接权值,u表示上一层神经元i与下一层神经元j的连接权值。
误差项计算
循环神经网络隐藏层的输入来于两个方向,所以其误差需要向两个方向传播:一个按照空间结构传递到上一层 ,这一部分的误差主要受到权值矩阵U影响;另一个按照时间方向上传递到上一个时刻,这一部分的误差主要受到权值矩阵W影响。
- 结构方向误差:
(δtl−1)T=(δtl)TU⋅diag[f′l−1(nettl−1)]
δtl−1表示l−1层t时刻误差,nettl−1表示l−1层神经元的加权输入,当前层的误差受到它后面一层町的误差及U的影响。diag[f(x)]表示对角线元素为f(x)的结果[y1,y2,y3,....,yn]的对角矩阵。
- 时间方向误差:
δkT=δtTi=k∏t−1W⋅diag[f′(neti)]
δk为任意时刻k的误差项,neti表示i时刻神经元的加权输入,neti=Wsi−1+Uxi。因此,某一时刻的误差计算依赖之后时刻的误差值以及权值矩阵的值。
权值梯度计算
通过我们得到的时间方向误差项δk和结构方向误差项δtl−1,以及任意时刻的隐藏层输出st,我们可以对权值矩阵W和权值矩阵U的梯度进行计算。 由于权值矩阵U主要影响结构方向的误差,则其梯度为:
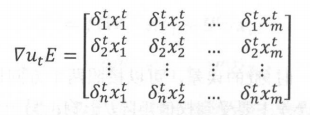
xit表示t时刻输入层第i神经元的输入,δit表示t时刻误差项向量的第i个分量。最终的梯度为所有时刻的误差和:
∇uE=i=1∑t∇uiE
则权值矩阵U的更新为:
U=U+η∇uE
其中η表示学习速率。同理,对于权值矩阵W,其梯度为:

sit−1表示t−1时刻循环层第i个神经元的状态输出值。最终的梯度为:
∇wE=i=1∑t∇wiE
权值矩阵W的更新公式为:
W=W+η∇wE
梯度消失与梯度爆炸
当神经网络的层数较多时,模型的数值稳定性容易变差,梯度消失与梯度下降就是最为典型的问题。这导致循环神经网络的梯度不能够在较长的序列中传递下去,从而无法获得长距离的影响。对于误差公式δkT=δtT∏i=kt−1W⋅diag[f′(neti)],我们可以得到下式:
∥∥∥δkT∥∥∥⩽∥∥∥δtT∥∥∥i=k∏t−1∥W∥⋅∥diag[f′(neti)]∥⩽∥∥∥δkT∥∥∥(βwβf)t−k
上述公式中,β表示矩阵模的上界,整体为一个指数函数,t−k表示从t时刻到k时刻的距离,这个相差越大,误差项的值抖动就越大,从而进一步影响到权值的更新幅度,产生大幅抖动或者无更新,即表现为梯度消失或梯度爆炸问题。这取决于β的值是大于1或者小于1。 与梯度消失问题相比,梯度爆炸问题更容易发现以及解决。梯度爆炸时我们一般会收到NaN这样的错误,我们只需要设置一个阈值,在梯度大于阈值时,我们就将梯度进行裁剪即可,这种方法被称为梯度裁剪法。 梯度消失问题主要采用以下三种方式进行解决:
- 在对权值矩阵进行初始化时,为权值矩阵设置合理的初始化值;
- 使用
ReLU函数来作为激活函数。在正数区间,ReLU函数的梯度恒为1; - 设计使用特殊结构的循环神经网络,如长短时记忆网络(LSTM)或 Gated Recurrent Unit(GRU)。
梯度裁剪法
循环神经网络中较容易出现梯度衰减或梯度爆炸,这会导致网络几乎无法训练。裁剪梯度(clip gradient)是一种应对梯度爆炸的方法。假设我们把所有模型参数的梯度拼接成一个向量 g,并设裁剪的阈值是θ。裁剪后的梯度:
g=min(∥g∥θ,1)g
经过梯度裁剪后的梯度g的L2范数不超过θ。
使用pytorch的实现步骤为:
- 将网络中所有参数的梯度加和。
pytorch中Tensor的梯度可以通过Tensor.grad.data获得; - 求得加和后梯度向量的
L2范数; - 如果
L2范数的值大于阈值,则对每个参数进行裁剪。
gi=gi×(∥g∥θ)
编程要求
根据提示,在右侧编辑器 Begin-End 区间补充代码,编写梯度裁剪方法。
测试说明
平台会对你编写的代码进行测试:
测试输入:无 预期输出: True
import torch
def grad_clipping(params,theta):
"""
梯度裁剪
:param params: 循环神经网络中所有的参数
:param theta: 阈值
"""
########## Begin ##########
norm = torch.tensor([0.0])
for param in params:
norm += (param.grad.data ** 2).sum()
norm = norm.sqrt().item() # 所有参数的L2范数
if norm > theta: # 大于阈值
for param in params:
param.grad.data *= (theta / norm) # 对每个参数的梯度进行裁剪
########## End ##########第3关:长短时记忆网络
任务描述
本关任务:通过学习长短时记忆网络相关知识,编写实现长短时记忆网络。
相关知识
为了完成本关任务,你需要掌握:
- 长短时记忆网络;
- 门结构;
- 长短时记忆网络实现。
长短时记忆网络
传统的循环神经网络受限于梯度爆炸与梯度消失问题,使得网络随着输入序列的增长,抖动变得更为剧烈,导致无法学习 。长短时记忆网络( Long Short Term Memory Network, LSTM )便是为了解决此问题而被设计提出。其核心思想是通过添加一个网络内部状态c来记忆长期信息,这个新的状态我们称之为单元状态(Cell State),主要负责记忆长期信息。
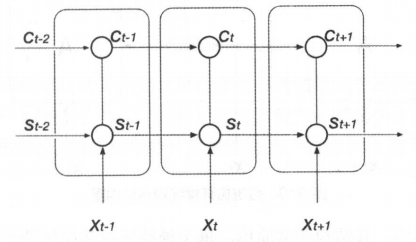
图1 长短时记忆网络结构展开图
图1为 LSTM 结构展开图,在某一时刻t,长短时记忆网络的神经元输入由三部分组成:当前网络的输入Xt、上一时刻的输出st−1以及上一时刻的单元状态ct−1,神经元的输出为当前时刻的输出st,当前时刻的单元状态为ct。 如图2所示, LSTM 的核心是单元状态。单元状态像传送带一样,它贯穿整个网络却只有很少的分支,这样能保证信息不变的流过整个网络。后面会 LSTM 结构进行详细的说明。
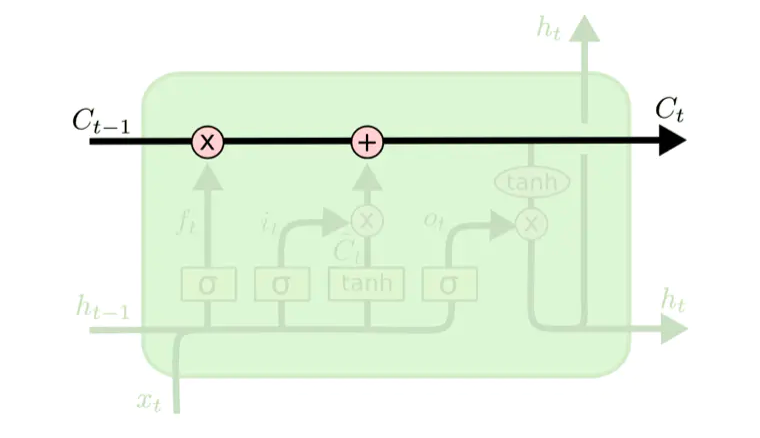
图2 单元状态图
LSTM 能通过一种被称为门的结构对单元状态进行控制,选择性的决定让哪些信息通过。门的结构很简单,由一个 Sigmoid 层和一个点乘操作的组合而成。如图3所示:
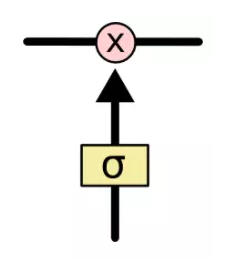
图3 门示意图
其中黄色矩形表示 Sigmoid 层,红色圆圈代表点乘操作。
因为 Sigmoid 层的输出是0或1,这代表有多少信息能够流过Sigmoid 层。0表示都不能通过,1表示都能通过。 其神经元的结构如图4所示:

图4 LSTM 神经元结构示意图
其中的图标的含义如图5所示:
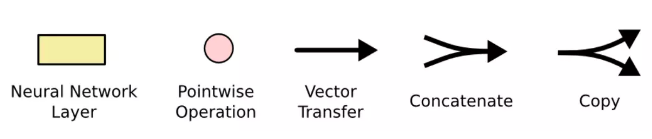
图5 图标示意图
Vector transfer 表示一个向量从一个节点的输出到其他节点的输入。Pointwise Operation 代表按位 Pointwise 的操作,例如向量的和。 Concatenate 表示向量的连接,Copy 表示内容被复制,然后分发到不同的位置。
门结构
一个 LSTM 里面包含三个门来控制单元状态,分别为:遗忘门、输入门和输出门。
遗忘门
LSTM 首先需要决定细胞状态需要留下那些信息,这个功能结构即遗忘门。 它主要决定上一时刻的输出ht−1与ct−1状态是否保留到当前时刻的ct当中。具体是通过一个 Sigmoid 层来实现。它通过查看ht−1和xt信息来输出一个[0,1]之间的向量,该向量的值表示单元状态Ct−1中哪些信息保留或丢弃。如图6所示:

图6 遗忘门示意图
它的输入为上一时刻的输出ht−1与当前时刻的输入xt,经过 Sigmoid 函数变换,得到内部当前时刻输出ft。 具体公式表达如下 :
ft=σ(Wf[ht−1,xt]+bf)
其中,Wf 表示遗忘门的权值矩阵,[ht−1,xt]表示两个向量纵向连接操作,bf表示输入的偏置项。
输入门
通过遗忘门决定神经元中什么信息保留下来后,我们现在需要确定当前的输入xt有多少信息需要保存到当前的单元状态ct中,此功能结构为输入门。这里包含两个部分:第一,Sigmoid 层决定那些输入将要被更新。第二,一个 Tanh 层生成一个新的候选向量C~t。这两部分的输出进行逐点相乘,从而对单元状态ct进行更新。输入门结构如图7所示:
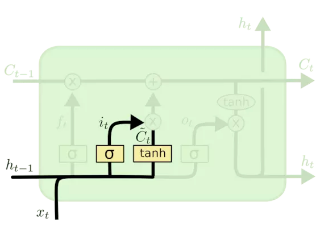
图7 输入门示意图
根据图7所示,输入门的计算公式如下:
it=σ(Wi[st−1,xt]+bi)c~t=tanh(Wc[st−1,xt]+bc)
在计算it与c~t时,它们的权值矩阵是不同的,因此在训练的过程中需要单独训练。 通过遗忘门与输入门的计算后,我们可以对单元状态ct进行更新操作。操作方法如图8所示:
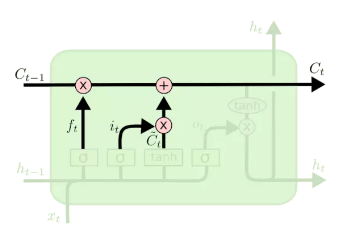
图8 更新单元状态示意图
计算公式如下:
c=ft∘ct−1+it∘c~t
∘表示按元素逐乘操作。
输出门
更新完单元状态后需要根据ht−1和xt来考虑如何将当前的信息进行输出,这部分功能由输出门完成。输出门主要来控制单元状态ct有多少可以输出到长短时记忆网络的当前输出值ht中,如图9所示:
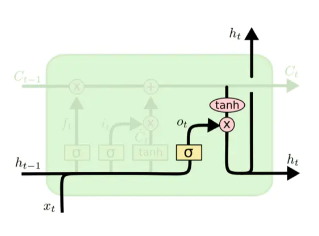
图9 输出门示意图
该单元的输出主要依赖当前的神经元状态ct,不只是单纯依赖单元状态,还需要进行一次信息过滤的处理,即由引入的 Sigmoid 层来完成。这一层将单元状态经过 Tanh 层处理后的数据进行元素相乘操作,将得到的ht有选择地输出到下一时刻和对外输出。具体计算公式如下 :
ot=σ(Wo[st−1,xt]+bo)st=ot∘tanh(ct)
长短时记忆网络实现
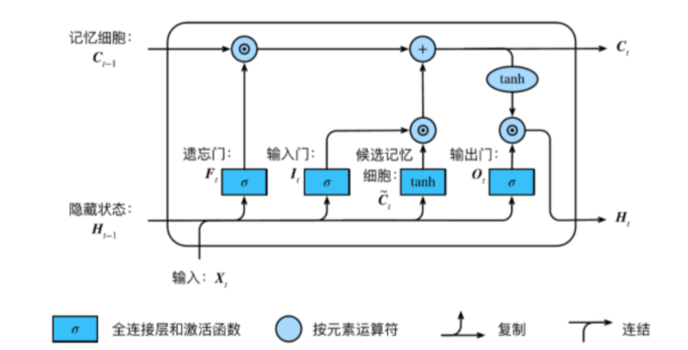
LSTM 的实现步骤:
- 通过遗忘门,计算允许继续通过神经元的信息;
F=sigmoid(WxfX+WhfH+bf)
- 通过输入门,计算当前输入中需要保留到单元状态的信息;
IC~C=sigmoid(WxiX+WhiH+bi)=tanh(WxcX+WhcH+bc)=F∘C+I∘C~
- 通过输出门,计算需要输出的信息;
OHnew=sigmoid(WxoX+WhoH+bo)=O∘tanh(C)
- 通过输出层计算输出。
Y=WhqHnew+bq
编程要求
根据提示,在右侧编辑器 Begin-End 区间补充代码,编写实现 LSTM 的遗忘门、输入门、输出门。
测试说明
平台会对你编写的代码进行测试:
测试输入:无 预期输出: True
import torch
def lstm(X,state,params):
"""
LSTM
:param X: 输入
:param state: 上一时刻的单元状态和输出
:param params: LSTM 中所有的权值矩阵以及偏置
:return: 当前时刻的单元状态和输出
"""
W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q = params
"""
W_xi,W_hi,b_i : 输入门中计算i的权值矩阵和偏置
W_xf,W_hf,b_f : 遗忘门的权值矩阵和偏置
W_xo,W_ho,b_o : 输出门的权值矩阵和偏置
W_xc,W_hc,b_c : 输入门中计算c_tilde的权值矩阵和偏置
W_hq,b_q : 输出层的权值矩阵和偏置
"""
#上一时刻的输出 H 和 单元状态 C。
(H,C) = state
########## Begin ##########
# 遗忘门
F = torch.matmul(X, W_xf) + torch.matmul(H, W_hf) + b_f
F = torch.sigmoid(F)
# 输入门
I = torch.sigmoid(torch.matmul(X,W_xi)+torch.matmul(H,W_hi) + b_i)
C_tilde = torch.tanh(torch.matmul(X, W_xc) + torch.matmul(H, W_hc) + b_c)
C = F * C + I * C_tilde
# 输出门
O = torch.sigmoid(torch.matmul(X,W_xo)+torch.matmul(H,W_ho) + b_o)
H = O * C.tanh()
# 输出层
Y = torch.matmul(H,W_hq) + b_q
########## End ##########
return Y,(H,C)















 1402
1402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











