






本文转载自 支持向量机 - 模树科技
(我不知道为什么有些latex语法无法识别,只能截图了,如果影响观感建议大家还是直接移步 数模百科)
优化问题可以分成两个角度:原始问题和对偶问题。
原始问题通常是指最初的优化问题,它是我们想要直接解决的问题。而对偶问题是原始问题的一种变换形式,它在数学上与原始问题密切相关,但可能具有不同的结构和性质。在某些情况下,解决对偶问题可能更为简便,或者能提供关于原始问题解的全新视角。
双十一购物节到了,这就像是一场盛大的战斗,商家和顾客都在为了自己的利益而拼命。商家们打出各种优惠大旗,希望吸引顾客购买更多的商品;而顾客们则是紧紧握着自己的钱包,只想用最少的钱买到最好的东西。
对于顾客来说,目标可能很直接——想要在有限的预算里买到尽可能多的商品。但是优惠活动太花哨,让人眼花缭乱,难以判断如何购买最合算。有的商品满减,有的打折,各种优惠混在一起,让人不知如何是好。
现在,我们可以用一个数学上的思想来简化这个问题,这就是“对偶问题”。原本的问题是在一定金额的预算下,如何买到最多的商品。那么,对偶问题就是:如果我们有固定想要买到的商品数量,我们应该怎么买才能花费最少的钱?这两个问题看似不同,但实际上是互为镜像的,在数学上我们称这种关系为“对偶性”。
在数学中,对偶问题通常能够给我们提供不同的视角来看待原问题,有时候解决对偶问题会更加容易一些。而回到双十一的购物,如果我们能够理解了这种对偶关系,也许就能更清晰地制定我们的购物策略,从而在疯狂的购物节中占据优势,不至于被复杂的优惠政策弄得晕头转向。
定义与详解
对偶问题(dual problem)是优化理论中的一个重要概念。原始问题(primal problem)在满足一定条件时,通过一系列变换和处理,可以生成一个与之相关的对偶问题。对偶问题和原始问题是等价的,对偶问题的解就是原始问题的解。在一些具体的优化问题中,尤其是约束优化问题中,对偶问题往往更容易求解。
为了构造对偶问题,我们通常首先定义待优化的目标函数和一组约束条件,也就是原始问题。然后,我们引入一套新的变量(对偶变量或拉格朗日乘数),每一个变量对应一个原始问题中的约束条件。我们将这些变量乘以相应的约束条件,把结果加上原始的目标函数,构造新的目标函数(称为拉格朗日函数)。最后,我们将拉格朗日函数最大化或者最小化,得到的优化问题就是对偶问题。
对偶问题的目标函数是原始目标函数和约束条件的“结合体”,因此,对偶问题的解相当于同时满足了原始的目标函数和约束条件。
值得注意的是,原始问题和对偶问题常常是反向的:如果原始问题是求最小值,那么对偶问题就是求相应的最大值。
在支持向量机(SVM)中,我们利用对偶问题来求解分类的最优决策边界。SVM的原始问题是一个具有约束的二次优化问题,我们通过构造其对偶问题,将它转化为一个更容易解决的无约束优化问题。
对偶性
对偶性是指原始问题和对应的对偶问题之间的关系。
当原始问题是一个求最小值的优化问题时,其对偶问题就是一个求最大值的优化问题。在这个情况下:
-
弱对偶性:对偶问题的解是原始问题解的下界,而原始问题的解是对偶问题解的上界。也就是说,解对偶问题得到的结果总是小于或等于解原始问题得到的结果。这是所有优化问题都满足的一个特性,这就是所谓的"弱对偶性"。
-
对偶间隙:在一般情况下,原始问题和对偶问题的最优解并不一定相等。它们之间的差值被称为"对偶间隙"。如果对偶间隙为零,那么就意味着原始问题和对偶问题的最优解是相等的。
-
强对偶性:对于凸优化问题,在满足某些约束条件的情况下,对偶间隙是零。也就是说,对于这类问题,原始问题和对偶问题的最优解实际上是相等的。
拉格朗日乘数法
拉格朗日乘数法能够将含有约束的优化问题转化为无约束的优化问题。在实际问题中,我们经常使用拉格朗日乘数法来求解对偶问题。
以下面的优化问题为例:
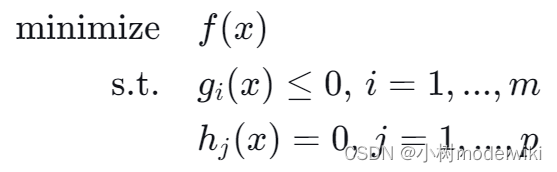
我们首先构建拉格朗日函数,将约束条件融入到目标函数中:
其中, 是关联到不等式约束的拉格朗日乘数,
是关联到等式约束的拉格朗日乘数。
对偶函数定义为拉格朗日函数的最小值:
最后,构建对偶问题,目标是最大化这个对偶函数:
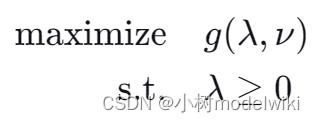
由强对偶性可知,我们知道当原问题是凸优化问题,并且满足一定的条件(如斯莱特条件)时,原问题和对偶问题的最优解是相等的。因此,我们可以利用拉格朗日乘数法构建对偶问题,然后求解对偶问题以得到原问题的最优解。
拉格朗日乘数法的思路是引入一些新的变量,这些变量我们称为拉格朗日乘数,分别对应每一个约束条件。对于不等式约束,我们引入 (要求
),对于等式约束,我们引入
。然后,我们构建一个新的函数,这个函数不仅包含了原来的目标函数
,还包含了所有的约束条件,乘以对应的拉格朗日乘数。这个函数叫做拉格朗日函数:
下一步,我们定义所谓的对偶函数 ,这个函数是拉格朗日函数在所有可能的 x 值上的最小值:
然后,我们构建一个新的优化问题,叫做对偶问题,目的是要最大化这个对偶函数 ,同时要满足
:
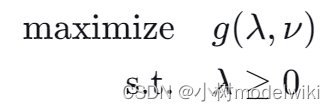
由强对偶性可知,我们知道当原问题是凸优化问题,并且满足一定的条件(如斯莱特条件)时,原问题和对偶问题的最优解是相等的。因此,我们可以利用拉格朗日乘数法构建对偶问题,然后求解对偶问题(相对来说更容易解决)以得到原问题的最优解。
斯莱特条件
在优化问题中,斯莱特条件(Slater's condition)是判断一个问题是否满足强对偶性的一个充分条件。
对于一个凸优化问题,形式如
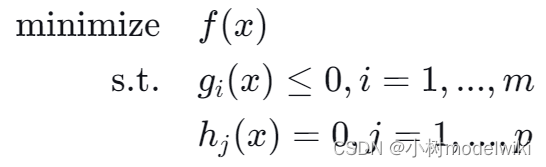
其中, 和
是凸函数,
是线性函数。如果存在一个点 x,它满足:
-
所有的不等式约束严格:
-
所有的等式约束:
则原问题满足斯莱特条件。
满足斯莱特条件的重要性在于,如果原优化问题满足斯莱特条件,那么原问题与对偶问题的最优值相等,即存在零对偶间隙,这大大帮助我们寻找并理解原问题和对偶问题之间的关系。
二次规划
二次规划的特点是目标函数为二次形式,而约束条件则是线性的,SVM在解决问题时通常会构造二次规划问题。
一个标准的二次规划问题可以写成如下形式:
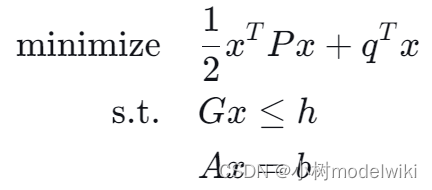
其中:
-
x 是一个我们需要找到的解向量,它属于 n 维实数空间,也就是说
。
-
P 是一个
维的矩阵,并且它是半正定的(记作
)。半正定意味着对于任意的向量 z ,都有
。这个性质保证了我们的目标函数是凸的,也就是说,函数图形是一个向上的碗状,这样我们就可以找到一个全局最小值。
-
q 是一个向量,它和 x 一样维度都是 n 。
-
G 和 h 分别是一个
维的矩阵和一个 m 维的向量,它们定义了 m 个线性不等式约束。不等式约束意味着解向量 x 必须位于由
定义的区域内部或边界上。
-
A 和 b 分别是一个
维的矩阵和一个 p 维的向量,它们定义了 p 个线性等式约束。等式约束意味着解向量 x 必须精确地位于由
定义的超平面上。
在SVM的对偶问题中,我们需要最大化一个对偶函数,这个函数是关于对偶变量的二次函数,同时还要满足一些关于对偶变量和分类标签的线性约束。这个对偶问题正好可以用二次规划的框架来描述和求解。
总结一下,二次规划问题就是要在满足一系列线性等式和不等式约束的条件下,找到一个向量 x ,使得二次目标函数 的值最小。解决这样的问题可以帮助我们在给定的约束下找到最优的决策或预测结果。
KKT条件
KKT条件,即Karush-Kuhn-Tucker条件,是解决非线性规划问题中的一个非常重要的工具。它提供了一种方法,用来判断一个解是否能够成为某个优化问题的最优解。
考虑一个非线性规划问题,我们的目标是找到一个解 x,使得目标函数 f(x) 最小化,同时要满足一些不等式约束 和等式约束
。数学上,我们可以这样表示这个问题:
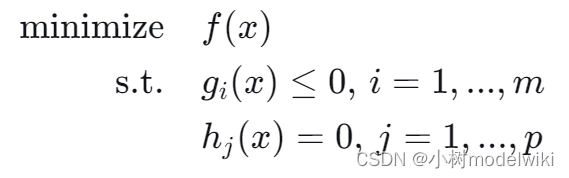
这里, 是我们要最小化的目标函数,
是不等式约束,
是等式约束。
KKT条件是由以下几个部分组成的:
-
梯度条件:拉格朗日函数
关于变量 x 的梯度应该为零。拉格朗日函数是将原问题的约束整合进目标函数的一种方法。梯度条件可以用下面的数学公式表示:
-
原始可行性条件:解必须满足原始问题的所有约束条件。这意味着对于所有的不等式约束和等式约束,解 x 都必须满足以下条件:
-
对偶可行性条件:拉格朗日乘子
必须非负。这表示对于所有的 i,我们都有:
-
互补松弛条件:对于每个不等式约束,要么约束是紧的(即
),要么对应的拉格朗日乘子
当我们面对一个凸优化问题时,如果满足一定条件(比如解在内点,满足斯莱特条件等),KKT条件不仅是最优解的必要条件,同时也是充分条件。这意味着,如果一个解满足了KKT条件,那么它就是问题的最优解。
在实际应用中,比如支持向量机(SVM)和神经网络训练,KKT条件经常被用来验证一个解是否是最优解。通过检查一个解是否满足所有的KKT条件,我们可以确定它是否能最小化目标函数,同时满足所有的约束条件。
本篇文章摘录自 数模百科 —— SVM模型。
数模百科是一个由一群数模爱好者搭建的数学建模知识平台。我们想让大家只通过一个网站,就能解决自己在数学建模上的难题,把搜索和筛选的时间节省下来,投入到真正的学习当中。
我们团队目前正在努力为大家创建最好的信息集合,从用最简单易懂的话语和生动形象的例子帮助大家理解模型,到用科学严谨的语言讲解模型原理,再到提供参考代码。我们努力为数学建模的学习者和参赛者提供一站式学习平台,目前网站已上线,期待大家的反馈。
如果你想和我们的团队成员进行更深入的学习和交流,你可以通过公众号数模百科找到我们,我们会在这里发布更多资讯,也欢迎你来找我们唠嗑。

















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









