






一、下载ChatGLM3-6B
测试模型:
新建文件predict.py。运行下面测试代码。建议这里的transformers包最好和LLaMA-Factory环境的transformers包版本保持一致或者直接用LLaMA-Factory的环境。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("./models/chatglm3-6b",torch_dtype=torch.float16,trust_remote_code=True).half().cuda()
tokenizer = AutoTokenizer.from_pretrained("./models/chatglm3-6b",trust_remote_code=True)
model.to(device)
model = model.eval()
# response, history = model.chat(tokenizer, """ 你是谁""", history=[])
response, history = model.chat(tokenizer, """ 从给定文本中提取医疗程序、疾病、症状、肌体、药品、体检项目、微生物、医疗器械、科室这几类的实体名,用字典格式返回。文本:房内折返性心动过速,每年发作1至3次,需药物干预。""", history=[])
print(response)问题:你是谁
答:我是一个名为 ChatGLM3-6B 的人工智能助手,是基于清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型开发的。我的任务是针对用户的问题和要求提供适当的答复和支持。
问题:从给定文本中提取医疗程序、疾病、症状、肌体、药品、体检项目、微生物、医疗器械、科室这几类的实体名,用字典格式返回。文本:房内折返性心动过速,每年发作1至3次,需药物干预。
答:
{
"医疗程序": [],
"疾病": [],
"症状": [],
"肌体": [],
"药品": [],
"体检项目": [],
"微生物": [],
"医疗器械": [],
"科室": []
}
模型在微调前几乎提取不了医学中的专业名词 。
问题中的文本来自CMeEE-V2_dev.json中最后一句。

二、部署LLaMA-Factory
按照LLaMA-Factory项目中的要求创建好LLaMA-Factory的环境。有问题请放评论。
启动命令:llamafactory-cli webui
打开:本地启动打开: http://0.0.0.0:7860
或 服务器启动 服务器地址:7860
如果出现 :尚不支持多 GPU 训练。
切换为单卡启动:CUDA_VISIBLE_DEVICES=0 llamafactory-cli webui
三、数据集格式转换
将医学数据集CMeEE制作为ChatGLM3-6B的训练数据集。转换代码如下:修改file_path为要转换的医学数据集CMeEE的json文件地址,修改倒数第二行的保存位置。本次实验只选择前200个进行操作,if index==200: break 。 想全部进行转换请注释掉这句。instruction中可自行修改指令。
import json
# 指定JSON文件的路径
file_path = r'CMeEE-V2_dev.json'
# 读取JSON文件
with open(file_path, 'r', encoding='utf-8') as file:
datasets = json.load(file)
# print(datasets)
# 定义类型映射
type_mapping = {
"pro": "医疗程序",
"dis": "疾病",
"sym": "症状",
"bod": "肌体",
"dru": "药品",
"ite": "体检项目",
"mic": "微生物",
"equ": "医疗器械",
"dep": "科室"
}
llf_data = []
for index,data in enumerate(datasets):
# 创建一个包含所有类型的字典,初始值为空列表
entities_by_type = {value: [] for key, value in type_mapping.items()}
# 遍历所有实体,将它们按类型分类
for entity in data["entities"]:
entity_type = entity["type"]
if entity_type in type_mapping:
entities_by_type[type_mapping[entity_type]].append(entity["entity"])
# 创建输出数据
txt = data["text"]
output_data = {
"instruction": f"从给定文本中提取医疗程序、疾病、症状、肌体、药品、体检项目、微生物、医疗器械、科室这几类的实体名,用字典格式返回。文本:{txt}",
"input": "",
"output": f"{entities_by_type}",
"history": []
}
llf_data.append(output_data)
if index==200:
break
llf_data = json.dumps(llf_data, ensure_ascii=False, indent=2)
print(llf_data)
with open(r'chatglm3_finetune_data.json', 'w', encoding='utf-8') as f:
f.write(llf_data)请注意instruction、input、output对应的值全部都要是字符串形式。history的值为列表。否则后续微调时可能会报错:
raise RuntimeError("Cannot find valid samples, check `data/README.md` for the data format.")
RuntimeError: Cannot find valid samples, check `data/README.md` for the data format.
转换完毕后如下形式:
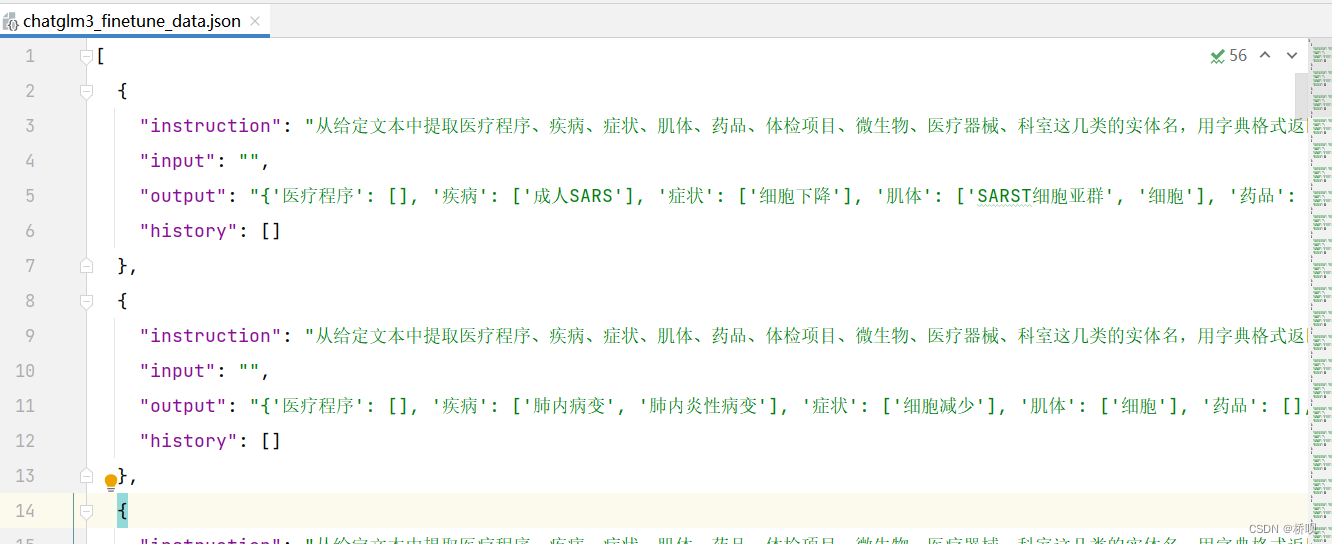
制作好的训练集放在目录LLaMA-Factory/data下,也可以在其他目录下 。然后修改dataset_info.json文件。如果在其他目录,chatglm3_finetune_data.json需改为对应的绝对地址
{"chatglm3_finetune_data":{"file_name":"chatglm3_finetune_data.json"}}

四、Lora训练
打开llamafactory的webui。
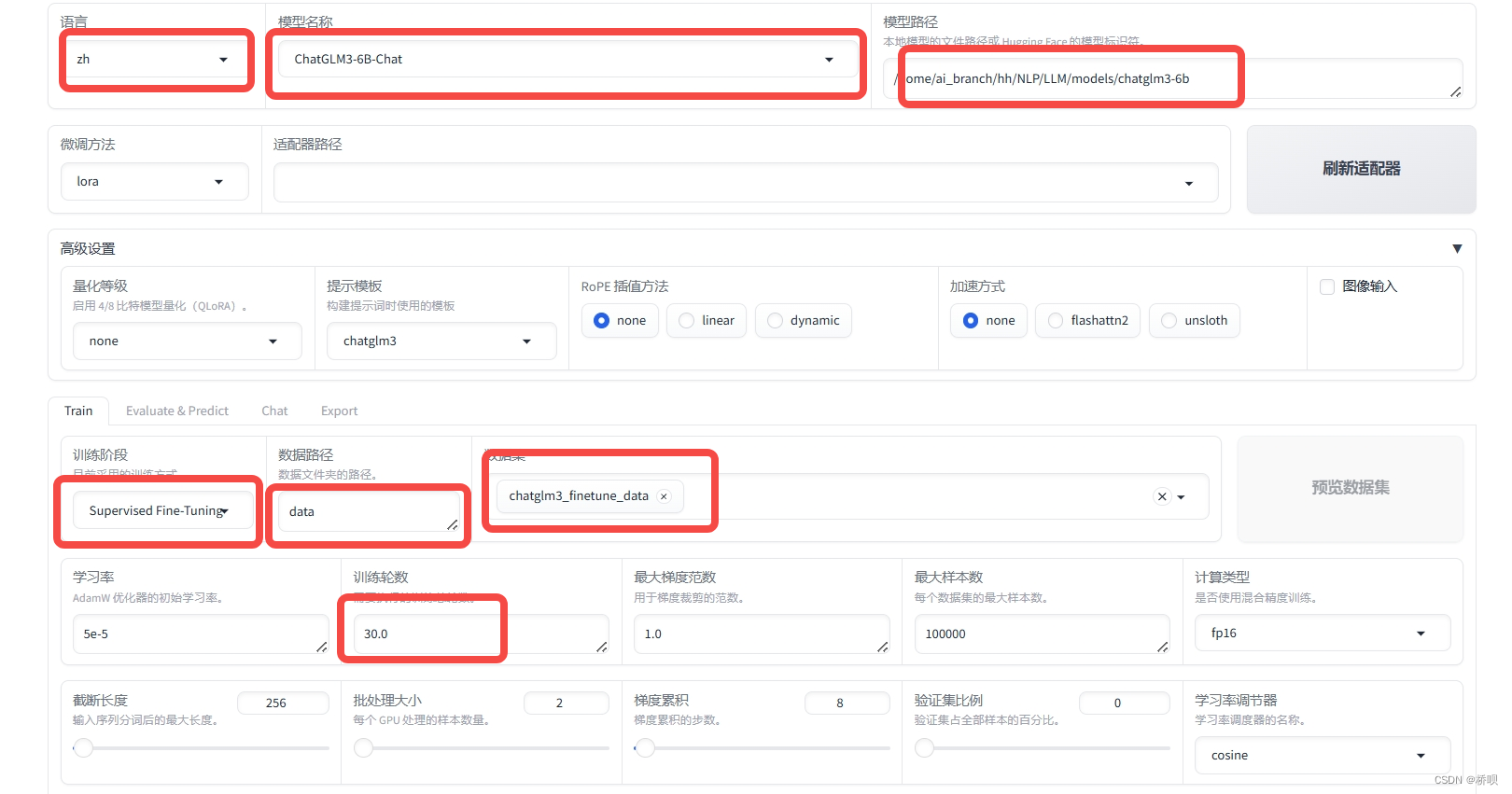
设置好基本参数。训练30个epoch。如果你的显存较小batchsize无法调大,可以调大梯度累计的值来模拟大的batchsize。
设置好lora参数为32,秩设置越大、参数更新的数量越多、训练越慢。

设置保存名称

点击开始训练,等待训练结束。
结果位于saves/ChatGLM3-6B-Chat/lora下。
五、微调模型测试
新建文件predict_lora.py。运行下面测试代码。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from peft import PeftModel
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("./models/chatglm3-6b",torch_dtype=torch.float16,trust_remote_code=True).half().cuda()
tokenizer = AutoTokenizer.from_pretrained("./models/chatglm3-6b",trust_remote_code=True)
p_model = PeftModel.from_pretrained(model, model_id="/LLaMA-Factory/saves/ChatGLM3-6B-Chat/lora/train_2024-06-17-16-55-15") # 将训练所得的LoRa权重加载起来
#
p_model.to(device)
p_model = p_model.eval()
response, history = p_model.chat(tokenizer, """ 从给定文本中提取医疗程序、疾病、症状、肌体、药品、体检项目、微生物、医疗器械、科室这几类的实体名,用字典格式返回。文本:房内折返性心动过速,每年发作1至3次,需药物干预。""", history=[])
print(response)
PeftModel.from_pretrained(model, model_id)中的model_id填入训练好的LORA模型绝对地址
运行结果:{'医疗程序': [], '疾病': ['房内折返性心动过速'], '症状': [], '肌体': [], '药品': [], '体检项目': [], '微生物': [], '医疗器械': [], '科室': []}
微调后,已经可以提取出疾病的实体名称了。
合并使用模型时可能发生如下报错:
config = config_cls(**kwargs)
TypeError: LoraConfig.__init__() got an unexpected keyword argument 'layer_replication'
解决方法:将测试文件中的transformers包和peft包的版本与训练时LLaMA-Factory环境中的transformers包和peft包版本保持一致。
有问题放评论,有用请点赞!















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









