









1. 什么是TOPSIS法
❑ TOPSIS(Technique for Order Preference by Similarity to Ideal Solution)方法是一种多属性决策方法,通过比较备选解与理想解之间的距离来确定最佳的排序顺序。正理想解是在每个属性上都达到最佳值的解,而负理想解则是在每个属性上都达到最差值的解。
❑ 为了确定备选解与理想解的距离,首先计算每个备选解与理想解之间的欧式距离或其他合适的距离度量。然后,计算备选解与理想解之间的正标准化距离和负标准化距离。正标准化距离反映了备选解与正理想解的接近程度,而负标准化距离反映了备选解与负理想解的接近程度。
❑ 最佳的排序顺序是备选解与正理想解的距离最短,与负理想解的距离最远的顺序。备选解越接近正理想解,其得分越高,越接近负理想解,其得分越低。这可以帮助决策者确定最佳的备选解,以达到多属性决策的目标。
2. TOPSIS法的基本步骤
Step1 正向化与标准化处理
假设有m个评价对象,每个评价对象有n个评价指标,对其进行综合评价得到的原始矩阵 X 为:

❑ 正向化处理
指标的正向化是指将所有指标转化为极大型指标,即其值越大越优。这样之后的计算和代码就可以更统一简洁。
指标的类型有:极大型指标、极小型指标、中间型指标、区间型指标。转化方法如下:
- 极小型指标 → 极大型指标

若所有元素均为正数,也可以直接取倒数:
![]()
- 中间型指标 → 极大型指标

其中,为该指标最佳的数值。
- 区间型指标 → 极大型指标
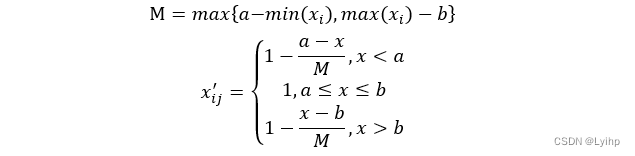
其中,a和b是该指标最佳区间的上下限。
❑ 标准化处理
进行标准化处理是为了平衡指标之间的差异或量纲带来的误差。可采用以下两种方法(注如果在正向化处理的同时也进行了标准化,就可以不用再进行标准化处理):
- Zscore标准化
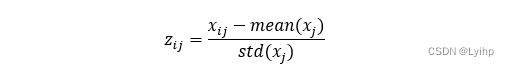
- Mapminmax标准化

正向化和标准化处理后得到规范矩阵 Z :

Step2 计算加权规范矩阵

这里的权重 W 可以由其他方法确定,例如熵权法等。
Step3 计算正负理想解
正理想解为:
![]()
负理想解为:
![]()
Step4 计算与正负理想解的距离
计算目标值与正负理想解之间的欧式距离,其中目标到正理想解的距离:
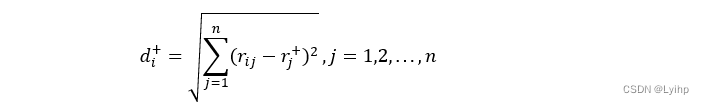
到负理想解的距离:

Step5 计算与理想解的贴近度
其中,当
时,表示该目标为最劣目标;当
时表示该目标为最优目标。在实际的多目标决策中,最优目标和最劣目标存在的可能性很小。

Step6 对目标优劣性进行排序
根据 的值按从小到大的顺序对个评价目标进行排列排序,
值越大,该目标越优。
3. TOPSIS法的MATLAB代码
clc;clear;
% X = [2.5 2.0 140 10 10 7
% 3.0 2.1 100 4 8 5
% 1.8 1.8 120 20 6 8
% 2.2 2.4 90 12 9 8
% 1.9 1.6 115 18 9 9
% 2.0 2.1 96 15 7 8];
% w = [0.25 0.1 0.15 0.2 0.2 0.1]; %指标权重
X = [89 2
60 0
74 1
99 3];
%Step1数据预处理-指标正向化
[n,m] = size(X);
disp(['共有' num2str(n) '个评价对象' num2str(m) '个评价指标']);
Judge = input(['这' num2str(m) '个指标是否需要经过正向化处理,需要请输入1,不需要输入0:']);
if Judge == 1
zhibiao_label = input(['请输入需要各指标的类型,其中极大型指标输入1/2,极小型指标输入3/4/5,' ...
'中间型指标输入6,区间型指标输入7,例如[1,3,3,3,1,1]:']);
X = preprocess(X,zhibiao_label);
end
disp('正向化后的矩阵 X =');
disp(X);
%Step1数据预处理-标准化
Z = X./repmat(sum(X.*X).^0.5,n,1);
disp('标准化后的矩阵 Z =');
disp(Z);
%Step2计算加权规范矩阵
disp("有多少指标就有多少个权重数(权重和为1),如[0.25 0.1 0.15 0.2 0.2 0.1]");
w = input(['请输入' num2str(m) '个权重:']);
if abs(sum(w)-1)<0.000001 && size(w,1) ==1 && size(w,2) == m
else
w = input('你输入的有误,请重新输入权重行向量:');
end
%Step3计算正负理想解
%Step4计算与正负理想解的距离
D_P = sum(w.*(Z-repmat(max(Z),n,1)).^2,2).^0.5; %最优距离
D_N = sum(w.*(Z-repmat(min(Z),n,1)).^2,2).^0.5; %最劣距离
% D_P = sum(((Z - repmat(max(Z),n,1)) .^ 2 ) .* repmat(w,n,1) ,2) .^ 0.5;
% D_N = sum(((Z - repmat(min(Z),n,1)) .^ 2 ) .* repmat(w,n,1) ,2) .^ 0.5;
%Step5计算与理想解的贴近度
S = D_P./(D_P+D_N);
%Step6对目标优劣性进行排序
disp("最后归一化后的得分为和排名:");
std_S = S./sum(S); %归一化得分
[sorted_S,index] = sort(std_S,'descend')正向化处理和标准化处理函数(即上面原理公式的复现):
function data_ok=preprocess(data,zhibiao_label)
%正向化处理/+标准化处理
%行是对象,列是指标
for i=1:length(zhibiao_label)
if (zhibiao_label(i)==1)
data_ok(:,i)=zheng1(data(:,i));
elseif (zhibiao_label(i)==2)
data_ok(:,i)=zheng2(data(:,i));
elseif (zhibiao_label(i)==3)
data_ok(:,i)=fu3(data(:,i));
elseif (zhibiao_label(i)==4)
data_ok(:,i)=fu4(data(:,i));
elseif (zhibiao_label(i)==5)
data_ok(:,i)=fu5(data(:,i));
elseif (zhibiao_label(i)==6)
prompt = '这是中间型指标,请输入该指标的最优值: ';
a = input(prompt);
data_ok(:,i)=dan6(data(:,i),a);
elseif (zhibiao_label(i)==7)
prompt = '这是区间型指标,请输入该指标的最佳区间如[5,10]:';
aa=input(prompt);
data_ok(:,i)=qu7(data(:,i),aa(1),aa(2));
end
end
end
%正向指标法1--填1的时候选择
function data1=zheng1(data)
data1=(data-min(data))./(max(data)-min(data)); %标准化处理
end
%正向指标法2--填2的时候选择
function data2=zheng2(data)
data2=data; %不处理
end
%负向指标法1--填3的时候选择
function data3=fu3(data)
data3=(max(data)-data)./(max(data)-min(data));
end
%负向指标法2--填4的时候选择
function data4=fu4(data)
data4=(max(data)-data);
end
%负向指标法3--填5的时候选择
function data5=fu5(data)
data5=1./(max(abs(data))+data);
end
%某点最优--填6的时候选择
function data6=dan6(data,best)
data6=1-(abs(data-best)./max(abs(data-best)));
end
%区间指标--填7的时候选择
function data7=qu7(data,a,b)
if ((a-min(data))>=(max(data)-b))
M=a-min(data);
else
M=max(data)-b;
end
for i=1:length(data)
if (data(i)<a)
data7(i)=1-(a-data)./M;
elseif (data(i)>=a)&&(data(i)<=b)
data7(i)=1;
elseif (data(i)>b)
data7(i)=1-(x-b)./M;
end
end
end














 1353
1353











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









