







为什么要有哨兵?
Redis 在 2.8 版本以后提供的哨兵(Sentinel)机制,它的作用是实现主从节点故障转移。它会监测主节点是否存活,如果发现主节点挂了,它就会选举一个从节点切换为主节点,并且把新主节点的相关信息通知给从节点和客户端。
哨兵其实是一个运行在特殊模式下的 Redis 进程,所以它也是一个节点。从“哨兵”这个名字也可以看得出来,它相当于是“观察者节点”,观察的对象是主从节点。
当然,它不仅仅是观察那么简单,在它观察到有异常的状况下,会做出一些“动作”,来修复异常状态。
哨兵节点主要负责三件事情:监控、选主、通知。
关注的问题:
- 哨兵节点是如何监控节点的?又是如何判断主节点是否真的故障了?
- 根据什么规则选择一个从节点切换为主节点?
- 怎么把新主节点的相关信息通知给从节点和客户端呢?
哨兵是如何监控节点的?主观下线和客观下线是什么?
哨兵会每隔 1 秒给所有主从节点发送 PING 命令,当主从节点收到 PING 命令后,会发送一个响应命令给哨兵,这样就可以判断它们是否在正常运行。
如果主节点或者从节点没有在规定的时间内响应哨兵的 PING 命令,哨兵就会将它们标记为「主观下线」。这个「规定的时间」是配置项 down-after-milliseconds 参数设定的,单位是毫秒。
- 主观下线,是站在哨兵的角度来看。如果没有响应PONG,哨兵就认为节点下线了。
如果只是因为主节点的系统压力比较大或者网络发送了拥塞,导致主节点没有在规定时间内响应哨兵的 PING 命令。这种情况下,该怎么解决呢?(客观下线)
所以,为了减少误判的情况,哨兵在部署的时候不会只部署一个节点,而是用多个节点部署成哨兵集群(最少需要三台机器来部署哨兵集群),通过多个哨兵节点一起判断,就可以就可以避免单个哨兵因为自身网络状况不好,而误判主节点下线的情况。同时,多个哨兵的网络同时不稳定的概率较小,由它们一起做决策,误判率也能降低。
当一个哨兵判断主节点为「主观下线」后,就会向其他哨兵发起命令,其他哨兵收到这个命令后,就会根据自身和主节点的网络状况,做出赞成投票或者拒绝投票的响应。当这个哨兵的赞同票数达到哨兵配置文件中的 quorum(法定人数)配置项设定的值后,这时主节点就会被该哨兵标记为「客观下线」。
-
由哪个哨兵进行主从故障转移?
判断主节点为客观下线的哨兵就是候选者,候选者中会选出一个leader,让leader来执行主从切换。选举leader的过程是一个投票的过程。
那么在投票过程中,任何一个「候选者」,要满足两个条件:
- 第一,拿到半数以上的赞成票;
- 第二,拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值。
为什么哨兵节点至少要有 3 个?
-
如果哨兵集群中只有 2 个哨兵节点,此时如果一个哨兵想要成功成为 Leader,必须获得 2 票,而不是 1 票。
所以,如果哨兵集群中有个哨兵挂掉了,那么就只剩一个哨兵了,如果这个哨兵想要成为 Leader,这时票数就没办法达到 2 票,就无法成功成为 Leader,这时是无法进行主从节点切换的。
因此,通常我们至少会配置 3 个哨兵节点。这时,如果哨兵集群中有个哨兵挂掉了,那么还剩下两个个哨兵,如果这个哨兵想要成为 Leader,这时还是有机会达到 2 票的,所以还是可以选举成功的,不会导致无法进行主从节点切换。
-
主从故障转移的过程是怎样的?
在哨兵集群中通过投票的方式,选举出了哨兵 leader 后,就可以进行主从故障转移的过程了
主从故障转移操作包含以下四个步骤:
- 第一步:在已下线主节点(旧主节点)属下的所有「从节点」里面,挑选出一个从节点,并将其转换为主节点。
- 节点优先级高胜出—>复制进度靠前节点胜出—>从节点ID号小的胜出
- 第二步:让已下线主节点属下的所有「从节点」修改复制目标,修改为复制「新主节点」;
- 哨兵 leader会让已下线主节点属下的所有「从节点」指向「新主节点」,这一动作可以通过向「从节点」发送
SLAVEOF命令来实现。
- 哨兵 leader会让已下线主节点属下的所有「从节点」指向「新主节点」,这一动作可以通过向「从节点」发送
- 第三步:将新主节点的 IP 地址和信息,通过「发布者/订阅者机制」通知给客户端;
- 客户端和哨兵建立连接后,客户端会订阅哨兵提供的频道。主从切换完成后,哨兵就会向
+switch-master频道(代表新主库切换)发布新主节点的 IP 地址和端口的消息,这个时候客户端就可以收到这条信息,然后用这里面的新主节点的 IP 地址和端口进行通信了。
- 客户端和哨兵建立连接后,客户端会订阅哨兵提供的频道。主从切换完成后,哨兵就会向
- 第四步:继续监视旧主节点,当这个旧主节点重新上线时,将它设置为新主节点的从节点;
- 故障转移操作最后要做的是,继续监视旧主节点,当旧主节点重新上线时,哨兵集群就会向它发送
SLAVEOF命令,让它成为新主节点的从节点。
- 故障转移操作最后要做的是,继续监视旧主节点,当旧主节点重新上线时,哨兵集群就会向它发送
- 第一步:在已下线主节点(旧主节点)属下的所有「从节点」里面,挑选出一个从节点,并将其转换为主节点。
-
哨兵集群是如何组成的?
通过 Redis 的发布者/订阅者机制,哨兵之间可以相互感知,然后组成集群,同时,哨兵给主节点发送INFO命令,可以从主节点里获得所有从节点连接信息,于是就能和从节点建立连接,并进行监控了。
6. 缓存篇
什么是缓存雪崩、击穿、穿透?
Redis是内存数据库,我们经常将MySQL中的数据缓存在Redis中,这样可以提高读写性能。
缓存异常的三个问题就是:缓存雪崩、击穿、穿透。
缓存雪崩(无缓存,但大量请求)
当大量缓存数据在同一时间过期(失效)或者Redis宕机,此时有大量的用户请求都无法在Redis中处理,请求直接访问数据库,导致数据库压力剧增,可能造成数据库宕机、等一系列连锁反应,最终整个系统崩溃,这就是缓存雪崩的问题。
针对大量数据同时过期而引发的缓存雪崩问题,常见的应对方法有下面这几种:
-
均匀设置过期时间;
给这些数据的过期时间加上一个随机数,这样就保证数据不会在同一时间过期。
-
互斥锁;
如果发现访问的数据不在 Redis 里,就加个互斥锁,保证同一时间内只有一个请求来构建缓存。注意,实现互斥锁的时候,最好设置超时时间,让请求即使阻塞也能及时释放锁。
-
双 key 策略;
主key设置过期时间、备用key不设置过期时间。访问不到主key时,访问备用key的数据。
-
后台更新缓存;
业务线程不再负责更新缓存,缓存也不设置有效期,而是让缓存“永久有效”,并将更新缓存的工作交由后台线程定时更新。
事实上,缓存数据不设置有效期,并不是意味着数据一直能在内存里,因为当系统内存紧张的时候,有些缓存数据会被“淘汰”,而在缓存被“淘汰”到下一次后台定时更新缓存的这段时间内,业务线程读取缓存失败就返回空值,业务的视角就以为是数据丢失了。
- 可以在业务线程发现缓存数据失效后(缓存数据被淘汰),通过消息队列发送一条消息通知后台线程更新缓存,后台线程收到消息后,在更新缓存前可以判断缓存是否存在,存在就不执行更新缓存操作;不存在就读取数据库数据,并将数据加载到缓存。
针对 Redis 故障宕机而引发的缓存雪崩问题,常见的应对方法有下面这几种:
-
服务熔断或请求限流机制;
Redis故障宕机时,启动服务熔断机制,暂停业务应用对缓存服务的访问,直接返回错误。
启用请求限流机制,只将少部分请求发送到数据库进行处理,再多的请求就在入口直接拒绝服务
-
构建 Redis 缓存高可靠集群;
通过主从节点的方式构建 Redis 缓存高可靠集群。
缓存击穿(热点数据过期,大量请求访问),可以认为是缓存雪崩的子集。
缓存穿透(数据不存在,大量请求访问)
当用户访问的数据,既不在缓存中,也不在数据库中,导致请求在访问缓存时,发现缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据,没办法构建缓存数据,来服务后续的请求。那么当有大量这样的请求到来时,数据库的压力骤增,这就是缓存穿透的问题。
应对缓存穿透的方案,常见的方案有三种。
第一种方案,非法请求的限制
在 API 入口处我们要判断求请求参数是否合理,避免进一步访问缓存和数据库。
第二种方案,缓存空值或者默认值
当我们线上业务发现缓存穿透的现象时,可以针对查询的数据,在缓存中设置一个空值或者默认值,这样后续请求就可以从缓存中读取到空值或者默认值,返回给应用,而不会继续查询数据库。
第三种方案,使用布隆过滤器快速判断数据是否存在,避免通过查询数据库来判断数据是否存在。
我们可以在写入数据库数据时,使用布隆过滤器做个标记,然后在用户请求到来时,业务线程确认缓存失效后,可以通过查询布隆过滤器快速判断数据是否存在,如果不存在,就不用通过查询数据库来判断数据是否存在。
即使发生了缓存穿透,大量请求只会查询 Redis 和布隆过滤器,而不会查询数据库,保证了数据库能正常运行,Redis 自身也是支持布隆过滤器的。
数据库和缓存如何保证一致性?
-
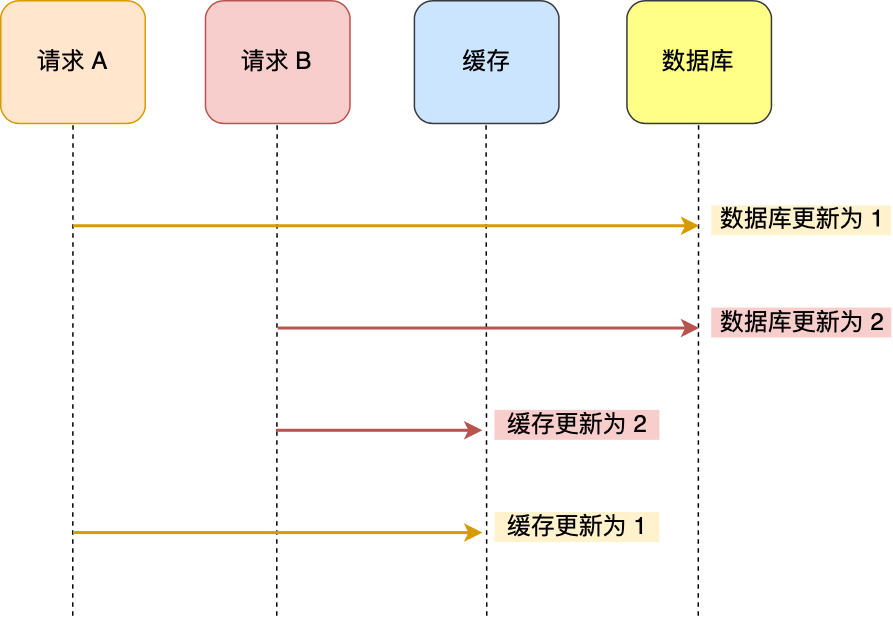
先更新数据库,再更新缓存,会出现数据库和缓存不一致的现象。
-
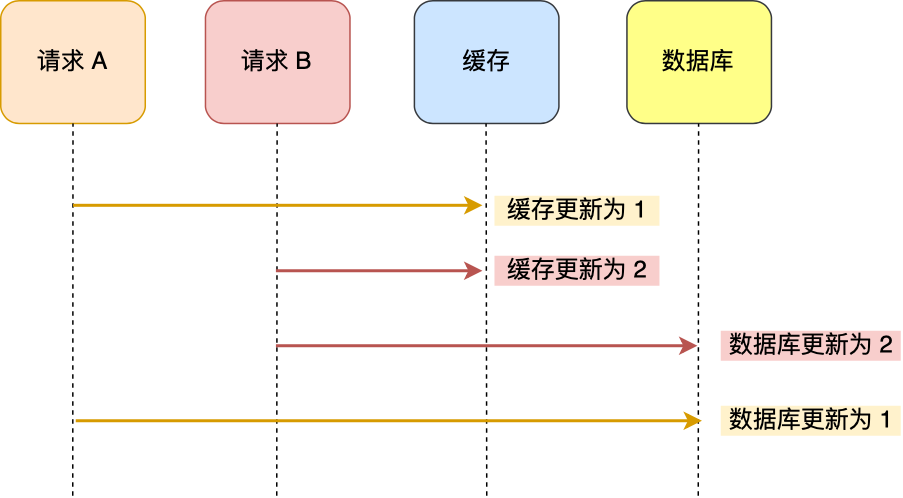
先更新缓存,再更新数据库,也会出现同样的问题。
-
先更新数据库,再删除缓存,可以保证数据一致性。但是每次更新数据的时候,缓存的数据都会被删除,这样会对缓存的命中率带来影响。如果我们的业务对缓存命中率有很高的要求,我们可以采用「更新数据库 + 更新缓存」的方案,因为更新缓存并不会出现缓存未命中的情况。
-
「更新数据库 + 更新缓存」的方案会出现数据不一致,防止数据不一致,可以做以下两个操作:
- 在更新缓存前先加个分布式锁,保证同一时间只运行一个请求更新缓存,就会不会产生并发问题了,当然引入了锁后,对于写入的性能就会带来影响。
- 在更新完缓存时,给缓存加上较短的过期时间,这样即时出现缓存不一致的情况,缓存的数据也会很快过期,对业务还是能接受的。
-
怎样保证更新数据库和删除缓存两个操作都能成功?
-
重试机制
我们可以引入消息队列,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
- 如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
- 如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
-
订阅MySQL binlog ,再操作缓存
「先更新数据库,再删缓存」的策略的第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。
于是我们就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除,阿里巴巴开源的 Canal 中间件就是基于这个实现的。
-
8. 网络系统
什么是零拷贝?
磁盘可以说是计算机系统最慢的硬件之一,读写速度相差内存 10 倍以上,所以针对优化磁盘的技术非常的多,比如零拷贝、直接 I/O、异步 I/O 等等,这些优化的目的就是为了提高系统的吞吐量,另外操作系统内核中的磁盘高速缓存区,可以有效的减少磁盘的访问次数。
使用DMA技术,在进行I/O设备与内存的数据传输时,数据搬运的工作交给DMA控制器,而CPU不再参与数据搬运相关的事情,这样CPU可以处理别的事务。
使用DMA技术的具体执行流程:
-
用户进程调用 read 方法,向操作系统发出 I/O 请求,请求读取数据到自己的内存缓冲区/用户空间中,进程进入阻塞状态;
-
用户缓存区:用户缓冲区的目的是为了减少系统调用次数,从而降低操作系统在用户态与核心态切换所耗费的时间。
一些程序在读取文件时,会先申请一块内存数组,称为buffer,然后每次调用read,读取设定字节长度的数据,写入buffer。(用较小的次数填满buffer)。之后的程序都是从buffer中获取数据,当buffer使用完后,在进行下一次调用,填充buffer。【缓冲区就可以理解为内存数组,在当前进程中开辟一段虚拟内存空间,并且映射到物理内存中,实际上存储在物理内存中】
-
-
操作系统收到请求后,进一步将 I/O 请求发送 DMA,然后让 CPU 执行其他任务;
-
DMA 进一步将 I/O 请求发送给磁盘;
-
磁盘收到 DMA 的 I/O 请求,把数据从磁盘读取到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被读满后,向 DMA 发起中断信号,告知自己缓冲区已满;
-
DMA 收到磁盘的信号,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用 CPU,CPU 可以执行其他任务;
-
当 DMA 读取了足够多的数据,就会发送中断信号给 CPU;
-
CPU 收到 DMA 的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回;
-
传统的文件传输有多糟糕?
如果服务端要提供文件传输的功能,我们能想到的最简单的方式是:将磁盘上的文件读取出来,然后通过网络协议发送给客户端。传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
read(file, tmp_buf, len); write(socket, tmp_buf, len);首先,期间发生了 4 次用户态和内核态的上下文切换,每次read()和write()都要从用户态切换到内核态,等内核态完成任务后,再从内核态切换到用户态。上下文切换到成本并不小,在高并发的场景下,这类时间容易被累积和放大,影响系统性能。
其次,期间还发生了 4 次数据拷贝,两次是DMA的拷贝,两次是CPU的拷贝。
- 第一次拷贝,磁盘文件—>内核缓存区,这个拷贝的过程是通过 DMA 搬运的。
- 第二次拷贝,内核缓存区—>用户缓存区,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由 CPU 完成的。
- 第三次拷贝,用户缓存区—>socket缓存区,这个过程依然还是由 CPU 搬运的。
- 第四次拷贝,socket缓存区—>网卡的缓冲区,这个过程又是由 DMA 搬运的。
所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。
-
如何优化文件传输性能?
减少用户态和内核态的上下文切换次数:减少系统调用的次数。
- 一次系统调用,必然会发生 2 次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行。
减少数据拷贝的次数:用户的缓冲区是没有必要存在。
- 因为文件传输的应用场景中,在用户空间我们并不会对数据「再加工」,所以数据实际上可以不用搬运到用户空间。
-
如何实现零拷贝?
零拷贝技术实现的方式通常有 2 种:mmap + write、sendfile
mmap + write
在前面我们知道,
read()系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了减少这一步开销,我们可以用mmap()替换read()系统调用函数。mmap()系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,应用进程与操作系统内核共享这个缓冲区。这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。但这还不是最理想的零拷贝,只是减少了一次数据拷贝的过程,但仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,而且仍然需要 4 次上下文切换,因为系统调用还是 2 次。
sendfile
Linux内核版本 2.1 中,提供了一个专门发送文件的系统调用函数
sendfile()。#include <sys/socket.h> ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
首先,它可以替代前面的
read()和write()这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。
但是这还不是真正的零拷贝技术,如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术(和普通的 DMA 有所不同),我们可以进一步减少通过 CPU 把内核缓冲区里的数据拷贝到 socket 缓冲区的过程。
于是,从 Linux 内核
2.4版本开始起,对于支持网卡支持 SG-DMA 技术的情况下,sendfile()系统调用的过程发生了点变化,具体过程如下:- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
所以,总体来看,零拷贝技术可以把文件传输的性能提高至少一倍以上。
Kafufa、Nginx都使用了零拷贝技术。
-
PageCache 有什么用?
上文提到的内核缓冲区,实际就是磁盘高速缓存(PageCache)。零拷贝就使用了Page Cache技术。通过 DMA 把磁盘里的数据搬运到内存里,这样就可以用读内存替换读磁盘。
根据局部性原理,我们可以用PageCache缓存最近被访问的数据,并且使用预读功能,提高磁盘的性能。
但是,在传输大文件(GB级别)的时候,PageCache不会起作用,就浪费了DMA多做的一次数据拷贝,此时,即使使用PageCache零拷贝,也会损失性能。
- 这是因为如果你有很多 GB 级别文件需要传输,每当用户访问这些大文件的时候,内核就会把它们载入 PageCache 中,于是 PageCache 空间很快被这些大文件占满。但是可能占满的部分不会被经常访问
所以,针对大文件的传输,不应该使用PageCache零拷贝技术。
-
大文件传输用什么方式实现?
在高并发的场景下,针对大文件的传输的方式,应该使用「异步 I/O + 直接 I/O」来替代零拷贝技术。
异步I/O把读操作分为两部分:
- 前半部分,内核向磁盘发起读请求,但是可以不等待数据就位就可以返回,于是进程此时可以处理其他任务;
- 后半部分,当内核将磁盘中的数据拷贝到进程缓冲区后,进程将接收到内核的通知,再去处理数据;
大文件的传输不应该使用PageCache,绕过PageCache的I/O叫直接I/O。通常对于磁盘,异步I/O只支持直接I/O。
直接I/O的应用场景有两种:
- 应用程序已经实现了磁盘数据的缓存。比如MySQL中可以开启直接I/O。
- 传输大文件时。
但是,由于直接I/O绕开了PageCache,也无法享受内核的优化:
-
内核I/O的调度算法会缓存尽可能多的I/O请求在PageCache中,最终合并更大的I/O请求再发给磁盘。
-
内核也会预读I/O请求,减少磁盘操作次数。
- 内核的预读关键在于预测能力,可以对顺序读进行预读,保证高命中率。
I/O多路复用:select/poll/epoll
-
最基本的Socket模型
要建立网络连接,服务器的程序要先跑起来,等待客户端的连接和数据。需要一个Socket,才可以实现跨主机之间的通信。Socket的本质是对TCP/IP的封装。服务器端的Socket编程过程如下:
服务器先调用socket()函数,创建网络协议IPv4,传输协议为TCP的Socket。调用bind()函数,给Socket绑定IP地址和端口。
- IP地址:识别网络上的设备。
- 端口号:表示TCP协议应该把报文发送给哪个应用程序。
之后调用listen()函数进行监听,如果要判断服务器中一个网络程序有没有启动,可以通过netstat 命令查看对应端口号是否被监听。
服务端进入了监听状态后,通过调用 accept() 函数,来从内核获取客户端的连接,如果没有客户端连接,则会阻塞等待客户端连接的到来。
回到客户端,客户端在创建好Socket后,调用connect()函数发起连接,指明服务器端IP地址和端口号,随后进行TCP三次握手。
在 TCP 连接的过程中,服务器的内核实际上为每个 Socket 维护了两个队列:
-
一个是「还没完全建立」连接的队列,称为 TCP 半连接队列,这个队列都是没有完成三次握手的连接,此时服务端处于
syn_rcvd的状态; -
一个是「已经建立」连接的队列,称为 TCP 全连接队列,这个队列都是完成了三次握手的连接,此时服务端处于
established状态;
当TCP全连接队列不为空,服务器端使用accept()函数,从内核中的TCP全连接队列中拿出已经完成连接的Socket返回应用程序,后序使用这个Socket传输数据。
建立连接后,客户端和服务端就开始相互传输数据了,双方都可以通过 read() 和 write() 函数来读写数据。
在内核中,Socket是以文件的形式存在的,也有对应的文件描述符。
-
C10K
TCP 连接是四元组唯一确认的:本机IP、本机端口、对端IP、对端端口。
服务器作为服务方,通常会在本地固定监听一个端口,等待客户端的连接。因此服务器的本地 IP 和端口是固定的,于是对于服务端 TCP 连接的四元组只有对端 IP 和端口是会变化的,所以最大 TCP 连接数 = 客户端 IP 数×客户端端口数。
对于 IPv4,客户端的 IP 数最多为 2 的 32 次方,客户端的端口数最多为 2 的 16 次方,也就是服务端单机最大 TCP 连接数约为 2 的 48 次方。
但是实际上,服务器无法承载那么大的连接数,主要受两个方面的限制:
- 文件描述符:Socket 实际上是一个文件,也就会对应一个文件描述符。在 Linux 下,单个进程打开的文件描述符数是有限制的,没有经过修改的值一般都是 1024。
- 系统内存:每个 TCP 连接在内核中都有对应的数据结构,意味着每个连接都是会占用一定内存的;
服务器的内存只有 2 GB,网卡是千兆的,能支持并发 1 万请求吗?
并发 1 万请求,也就是经典的 C10K 问题 ,C 是 Client 单词首字母缩写,C10K 就是单机同时处理 1 万个请求的问题。
从硬件资源角度看,对于 2GB 内存千兆网卡的服务器,如果每个请求处理占用不到 200KB 的内存和 100Kbit 的网络带宽就可以满足并发 1 万个请求。
不过,要想真正实现 C10K 的服务器,要考虑的地方在于服务器的网络 I/O 模型,效率低的模型,会加重系统开销,从而会离 C10K 的目标越来越远。
-
如何服务更多的用户?
TCP Socket使用的是最简单、基本的一对一通信方式。因为使用的是同步阻塞的方式,当服务端还没处理完一个客户端的网络 I/O 时,不会有其他连接占用。
如果要支持多个客户端,可以使用多进程模型,为每个客户端分配一个进程来处理请求。也就是一旦与客户端连接完成,accept() 函数就会返回一个「已连接 Socket」,这时就通过 fork() 函数创建一个子进程,实际上就把父进程所有相关的东西都复制一份,包括文件描述符、内存地址空间、程序计数器、执行的代码等。
但是,如果客户端数量很多,每个进程都会占据一定的系统资源,并且进行上下文切换,很消耗资源。此时可以考虑使用多线程模型。
线程是运行在进程中的一个“逻辑流”,单进程中可以运行多个线程,同进程里的线程可以共享进程的部分资源,比如文件描述符列表、进程空间、代码、全局数据、堆、共享库等,这些共享些资源在上下文切换时不需要切换,而只需要切换线程的私有数据、寄存器等不共享的数据,因此同一个进程下的线程上下文切换的开销要比进程小得多。
当服务器与客户端 TCP 完成连接后,通过
pthread_create()函数创建线程,然后将「已连接 Socket」的文件描述符传递给线程函数,接着在线程里和客户端进行通信,从而达到并发处理的目的。但是想要达到C10K,一台机器就要维护1万个连接,相当于维护1万个进程/线程。这种方式不合适。
既然为每个请求分配一个进程/线程的方式不合适,那有没有可能只使用一个进程来维护多个 Socket 呢?答案是有的,那就是 I/O 多路复用技术。
-
I/O多路复用
虽然同一时刻一个进程只能处理一个请求,但是处理每个请求时,耗时控制在很短的时间内,把时间拉长来看,多个请求复用了一个进程,这就是多路复用,这种思想很类似一个 CPU 并发多个进程,所以也叫做时分多路复用。
Linux 下有三种提供 I/O 多路复用的 API,分别是:select、poll、epoll。进程可以通过一个系统调用函数从内核中获取多个事件。
select/poll/epoll 是如何获取网络事件的呢?在获取事件时,先把所有连接(文件描述符)传给内核,再由内核返回产生了事件的连接,然后在用户态中再处理这些连接对应的请求即可。
-
select/poll
select 实现多路复用的方式是,将已连接的 Socket 都放到一个文件描述符集合,然后调用 select 函数将文件描述符集合拷贝到内核里,让内核来检查是否有网络事件产生,检查的方式很粗暴,就是通过遍历文件描述符集合的方式,当检查到有事件产生后,将此 Socket 标记为可读或可写, 接着再把整个文件描述符集合拷贝回用户态里,然后用户态还需要再通过遍历的方法找到可读或可写的 Socket,然后再对其处理。
所以,对于 select 这种方式,需要进行 2 次「遍历」文件描述符集合,一次是在内核态里,一个次是在用户态里 ,而且还会发生 2 次「拷贝」文件描述符集合,先从用户空间传入内核空间,由内核修改后,再传出到用户空间中。
select 使用固定长度的 BitsMap,表示文件描述符集合,而且所支持的文件描述符的个数是有限制的。而poll 用动态数组,以链表形式来组织,突破了 select 的文件描述符个数限制,当然还会受到系统文件描述符限制。
但是 poll 和 select 并没有太大的本质区别,都是使用「线性结构」存储进程关注的 Socket 集合,因此都需要遍历文件描述符集合来找到可读或可写的 Socket,时间复杂度为 O(n),而且也需要在用户态与内核态之间拷贝文件描述符集合,这种方式随着并发数上来,性能的损耗会呈指数级增长。
-
epoll
int s = socket(AF_INET, SOCK_STREAM, 0); bind(s, ...); listen(s, ...) int epfd = epoll_create(...); epoll_ctl(epfd, ...); //将所有需要监听的socket添加到epfd中 while(1) { int n = epoll_wait(...); for(接收到数据的socket){ //处理 } }epoll 通过两个方面,很好解决了 select/poll 的问题。
第一点,epoll 在内核里使用红黑树来跟踪进程所有待检测的Socket,把需要监控的 socket 通过
epoll_ctl()函数加入内核中的红黑树里,红黑树是个高效的数据结构,增删改一般时间复杂度是O(logn)。而 select/poll 内核里没有类似 epoll 红黑树这种保存所有待检测的 socket 的数据结构,所以 select/poll 每次操作时都传入整个 socket 集合给内核,而 epoll 因为在内核维护了红黑树,可以保存所有待检测的 socket ,所以只需要传入一个待检测的 socket,减少了内核和用户空间大量的数据拷贝和内存分配。第二点, epoll 使用事件驱动的机制,内核里维护了一个链表来记录就绪事件,当某个 socket 有事件发生时,通过回调函数,内核会将其加入到这个就绪事件列表中,当用户调用
epoll_wait()函数时,只会返回有事件发生的文件描述符的个数,不需要像 select/poll 那样轮询扫描整个 socket 集合,大大提高了检测的效率。epoll 的方式即使监听的 Socket 数量越多的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了,上限就为系统定义的进程打开的最大文件描述符个数。因而,epoll 被称为解决 C10K 问题的利器。
-
epoll的边缘触发和水平触发
- 使用边缘触发模式时,当被监控的 Socket 描述符上有可读事件发生时,服务器端只会从 epoll_wait 中苏醒一次,即使进程没有调用 read 函数从内核读取数据,也依然只苏醒一次,因此我们程序要保证一次性将内核缓冲区的数据读取完;
- 如果使用边缘触发模式,I/O 事件发生时只会通知一次,而且我们不知道到底能读写多少数据,所以在收到通知后应尽可能地读写数据,以免错失读写的机会。因此,我们会循环从文件描述符读写数据,那么如果文件描述符是阻塞的,没有数据可读写时,进程会阻塞在读写函数那里,程序就没办法继续往下执行。所以,边缘触发模式一般和非阻塞 I/O 搭配使用。
- 使用水平触发模式时,当被监控的 Socket 上有可读事件发生时,服务器端不断地从 epoll_wait 中苏醒,直到内核缓冲区数据被 read 函数读完才结束,目的是告诉我们有数据需要读取;
- 如果使用水平触发模式,当内核通知文件描述符可读写时,接下来还可以继续去检测它的状态,看它是否依然可读或可写。所以在收到通知后,没必要一次执行尽可能多的读写操作。
一般来说,边缘触发的效率比水平触发的效率要高,因为边缘触发可以减少 epoll_wait 的系统调用次数,系统调用也是有一定的开销的,毕竟也存在上下文的切换。
select/poll 只有水平触发模式,epoll 默认的触发模式是水平触发,但是可以根据应用场景设置为边缘触发模式。
- 使用边缘触发模式时,当被监控的 Socket 描述符上有可读事件发生时,服务器端只会从 epoll_wait 中苏醒一次,即使进程没有调用 read 函数从内核读取数据,也依然只苏醒一次,因此我们程序要保证一次性将内核缓冲区的数据读取完;
简单介绍:
-
高性能网络模式:Reactor和Proactor
-
简单介绍
当下开源软件能做到网络高性能的原因就是基于I/O多路复用,Reactor模式是对I/O多路复用的封装,让使用者不用考虑底层网络 API 的细节,只需要关注应用代码的编写。
这里的Reactor指的是「对事件反应」,也就是来了一个事件,Reactor 就有相对应的反应/响应。
事实上,Reactor 模式也叫
Dispatcher模式,即 I/O 多路复用监听事件,收到事件后,根据事件类型分配(Dispatch)给某个进程 / 线程。无论是 Reactor,还是 Proactor,都是一种基于「事件分发」的网络编程模式。Redis、Netty、Memcache、Mginx都使用了这种高性能的网络模式。
-
-
什么是一致性哈希?
大多数网站背后肯定不是只有一台服务器提供服务,因为单机的并发量和数据量都是有限的,所以都会用多台服务器构成集群来对外提供服务。如此多的节点,如何处理大量的请求呢?每个节点处理多少请求?这类问题就是负载均衡问题。
当我们想提高系统的容量,就会将数据水平切分到不同的节点来存储,也就是将数据分布到了不同的节点。比如一个分布式 KV(key-value) 缓存系统,某个 key 应该到哪个或者哪些节点上获得,应该是确定的。
不同的负载均衡算法适用的业务场景不同。
轮询这类的策略只能适用与每个节点的数据都是相同的场景,访问任意节点都能请求到数据。但是不适用分布式系统,因为分布式系统意味着数据水平切分到了不同的节点上,访问数据的时候,一定要寻址存储该数据的节点。
哈希算法虽然能建立数据和节点的映射关系,但是每次在节点数量发生变化的时候,最坏情况下所有数据都需要迁移,这样太麻烦了,所以不适用节点数量变化的场景。
为了减少迁移的数据量,就出现了一致性哈希算法。
一致性哈希是指将「存储节点」和「数据」都映射到一个首尾相连的哈希环上,如果增加或者移除一个节点,仅影响该节点在哈希环上顺时针相邻的后继节点,其它数据也不会受到影响。
但是一致性哈希算法不能够均匀的分布节点,会出现大量请求都集中在一个节点的情况,在这种情况下进行容灾与扩容时,容易出现雪崩的连锁反应。
为了解决一致性哈希算法不能够均匀的分布节点的问题,就需要引入虚拟节点,对一个真实节点做多个副本。不再将真实节点映射到哈希环上,而是将虚拟节点映射到哈希环上,并将虚拟节点映射到实际节点,所以这里有「两层」映射关系。
引入虚拟节点后,可以会提高节点的均衡度,还会提高系统的稳定性。所以,带虚拟节点的一致性哈希方法不仅适合硬件配置不同的节点的场景,而且适合节点规模会发生变化的场景。
-
class Solution { public boolean isSymmetric(TreeNode root) { if(root == null) return true; return compare(root.left , root.right); } boolean compare(TreeNode left , TreeNode right){ //判断空节点的情况。 if(left == null && right != null){ return false; }else if(left != null && right == null){ return false; }else if(left == null && right == null){ return true; }else if(left.val != right.val){ return false; } //比较外侧 boolean isOut = compare(left.left , right.right); //比较内侧 boolean isIn = compare(left.right , right.left); return isOut && isIn; } } -
思路一:通过遍历一遍二叉树得到答案。在刚进入节点时depth++,即将出节点时depth–,并且更新答案。
class Solution { int ans = 0; int depth = 0; public int maxDepth(TreeNode root) { dep(root); return ans; } void dep(TreeNode root){ if(root == null){ return; } depth ++; dep(root.left); dep(root.right); ans = Math.max(ans , depth); depth--; } }思路二:通过分解问题的方式得到答案。
class Solution { //定义函数:返回返回子树的最大深度。 public int maxDepth(TreeNode root) { if(root == null) return 0; int leftmax = maxDepth(root.left); int rightmax = maxDepth(root.right); int ret = Math.max(leftmax , rightmax) + 1; return ret; } }思路三:(迭代法)使用二叉树的层序遍历模板。
-
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。所以加一个判断叶子节点的条件,只有在叶子节点的时候,才更新节点即可。
class Solution { int depth = 0; int ans = Integer.MAX_VALUE; public int minDepth(TreeNode root) { dep(root); return ans == Integer.MAX_VALUE ? 0 : ans; } void dep(TreeNode root){ if(root == null) return ; depth++; dep(root.left); dep(root.right); if(root.left == null && root.right == null) ans = Math.min(ans , depth); depth--; } } -
222. 完全二叉树的节点个数 - 力扣(LeetCode)
完全二叉树:除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2^(h-1) 个节点。
这里给出只针对完全二叉树的解法:如果左外侧深度 == 右外侧深度,说明是满二叉树,直接用2^depth - 1即可。
class Solution { public int countNodes(TreeNode root) { if(root == null) return 0; TreeNode left = root.left; TreeNode right = root.right; int leftDepth = 0 , rightDepth = 0; while(left != null){ left = left.left; leftDepth ++; } while(right != null){ right = right.right; rightDepth ++; } if(leftDepth == rightDepth){ return (2 << leftDepth) - 1; //2 << 1 = 2 ^ 2。所以初始化为0 } return countNodes(root.left) + countNodes(root.right) + 1; } }















 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











