







 本文通过掷硬币的实例解释了KL散度的概念,它是衡量两个概率分布相似性的工具,常用于机器学习中的模型训练。KL散度通过比较两个分布产生相同序列的概率来度量距离,是深度学习中优化模型的重要手段,如PPO算法和StableDiffusion模型。
本文通过掷硬币的实例解释了KL散度的概念,它是衡量两个概率分布相似性的工具,常用于机器学习中的模型训练。KL散度通过比较两个分布产生相同序列的概率来度量距离,是深度学习中优化模型的重要手段,如PPO算法和StableDiffusion模型。
转载:一篇能给老奶奶讲明白KL散度的文章
原文链接:一篇能给老奶奶讲明白KL散度的文章
本文是《推荐武器库系列》的第一篇文章。讲得非常清楚,仅用以学习记录
学过机器学习的同学都知道,KL散度是一个距离度量函数,用于衡量两个分布的近似程度,其定义式我们也都很熟悉:
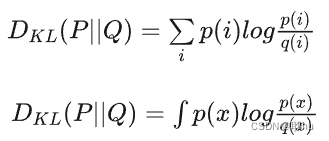
包括离散和连续两种形式。然而,我们并不能直观地看出来上式为什么就能反映两个分布的距离大小。本文从一个简单的例子出发,力图说清楚KL散度究竟干了一件什么事情。
假设有两枚硬币,第一枚材质均匀,也就是投掷一次,其正反两面出现的概率均为0.5,另一枚硬币未知,其正反两面的概率记为
我们怎么判断这两枚硬币是否相似呢?很自然地,我们可以根据 值来判断,例如 的硬币要比 的硬币更接近硬币1。这样判断的依据是:当我们投掷一定次数时, 的硬币得到正反序列(记为序列1,另一个记为序列2)和硬币一的结果(记为序列0)相比,更难区分:


图中左侧均是序列0(硬币1),右侧分别是序列1(p = 0.45)和序列2(p=0.95)
上述例子中,我们判断序列1更接近序列0的依据是这两个序列更容易混淆,这也是建模两个分布距离的依据,即区分这两个分布的难易程度,KL散度便是一种经典的建模方式。
下一步,如何量化这种“难易程度”呢?直观的思路是,比较这两枚硬币产生同样投掷序列的概率,如果他们产生这个序列的概率接近,则两枚硬币比较相似,否则不相似。接下来,我们来实施这个思路:

如上图(图有点错,概率第一行最后红色的p1应该为p2),我们以硬币1作为基准,产生一个正反序列,并计算硬币2产生该序列的概率,比较两个概率(用除法),即可判断二者的相似性。由于投掷硬币是独立同分布事件,综合概率为每次投掷概率的累乘(如上图),用数学公式表示为:
其实,到这里建模已经完成了,这就是KL散度了,只是这个形式不好看,计算也不方便且不能一般化,我们对公式做一些等价转化:
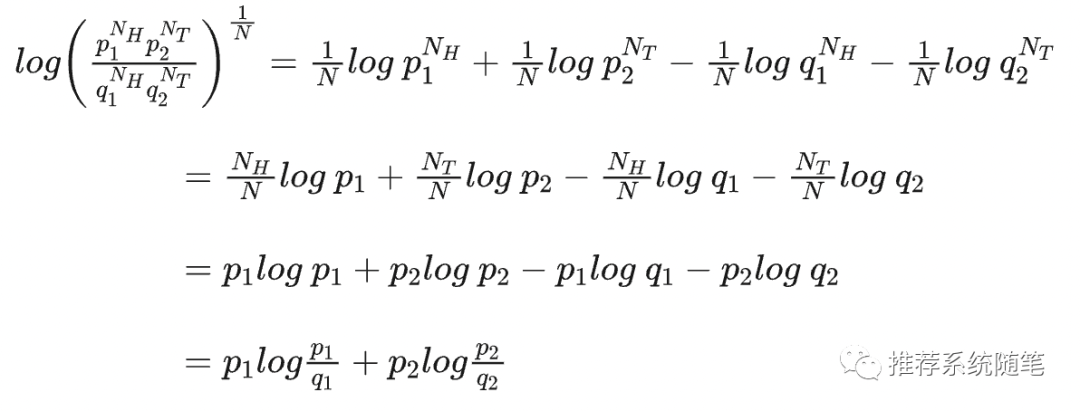
公式2:数学推导
式子中等号左边是公式1归一化后取对数,这是极大似然法的常规操作;等号右边第1、2行是log计算法则;第2行中,当N趋于无穷大时,根据大数定理 ,即可得到第3行,第4行同样是根据log计算法则。
至此,来回顾总结下,我们干了一件什么事呢?我们比较抛硬币1、2产生同一个序列分布的概率,其计算式如下:
其含义可以总结为:分布1(真实分布)似然函数除以分布2(目标分布)似然函数的归一化对数概率。上述公式是从抛硬币事件(即 )中得到的,然而,所有的过程涉及到的内容均为基础的数学过程,因此,可以推广到有N种结果的事件中,即:
于是,我们便得到了KL散度的定义。下面的视频展示了KL散度随着分布变化而带来的差异,具体地,固定分布1(红色曲线),改变分布2(蓝色曲线),可以直观地看到,两个分布差异越小,其KL散度(阴影区域面积)越小。
视频在原文链接
KL散度在机器学习中是一个利器,本公众号前两篇文章中,ChatGPT的RLHF过程用到了强化学习PPO算法,其建模过程就包含了KL散度,而Stable Diffusion模型中的反转过程核心就是KL散度。那么,为什么KL散度在机器/深度学习中如此重要呢,我们可以简单总结下:
KL散度是一个衡量不同概率分布距离的度量函数,其本质是度量第二个分布产生(第一个分布采样得到的)某个序列的可能性大小;而绝大部分深度学习都是通过建模真实数据分布来学习得到预估概率分布,即最小化KL散度,让学习到的概率分布尽可能接近真实数据分布,这便是极大似然的思想。因此,KL散度是深度学习里的一个重要的手段,事实上,深度学习中常用的交叉熵损失函数就等价于KL散度,这个我们将在后续文章中给出说明。
下面是给老奶奶讲的版本:
“奶奶,我左手里有一个硬币,右手一堆硬币,这些硬币外观、重量均一样,但材质不一样均匀,你有什么办法能找出右手中的哪个硬币和左手中的硬币最接近?”
“俺知不道”
“很简单,我把左手的硬币抛一万次,记录正反两面出现的次数,然后右手中的每个硬币都抛一万次,看哪个结果和左手的结果类似,它就最相近,这其实就是数学中的KL……”
“什么哎呦不哎呦的,赶紧吃饭吧,抛这么多次硬币累不累呀?”
于是,老奶奶轻轻松松就学会了KL散度。















 699
699











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









