







学习自用笔记
深度学习预备知识
损失函数
梯度下降
softmax
知识蒸馏概述
概述
Geoffrey Hinton的这篇论文是知识蒸馏的开山之作,具有重要的学习和借鉴意义。类似于我们高中所学的蒸馏,通过沸点不同将不同的物质分离提取。传统的知识蒸馏就是把一个大的训练好的教师模型的知识萃取出来,“教授”给轻量级的学生模型,完成知识的“迁移”。教师模型通常更加复杂,可能有着更高数量级的超参数,更复杂或更多的处理模型。学生模型可以被认作是教师模型压缩后得到的模型,使之能够适应算力更小的系统。
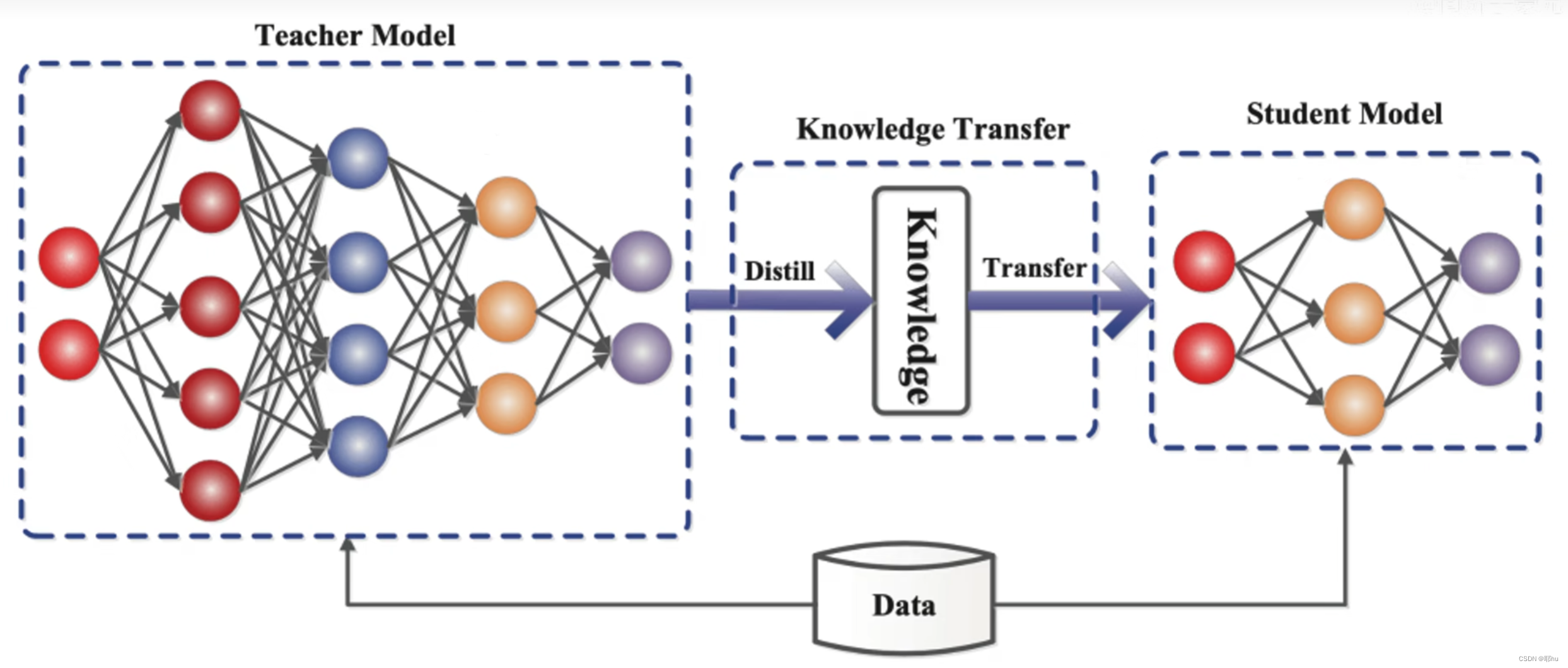
轻量化神经网络
- 压缩已经训练好的神经网络模型:知识蒸馏,权值量化,剪枝(1.权重剪枝 2.通道剪枝),注意力迁移
- 直接训练轻量化网络
- 加速卷积网络
- 硬件部署
论文阅读
介绍
在机器学习领域中,训练的目标和部署的目标是不同的。在训练时可以不计成本地砸钱砸计算资源,但是部署时,需要迅速且准确。
于是就诞生一种想法:将大模型学习得到的“知识”迁移到更容易部署的小模型中。Rich Caruana和他的同事在之前的研究中已经证实,多个模型学习的知识可以迁移到单一的小模型中。该思路存在一个难题:如何定义“知识”?通常认为,模型学习得到的参数代表“知识”,但是这些参数无法直接从大模型复制到小模型中(很明显的一点是,大模型和小模型结构不一致,参数数量不同),很难在不改变“知识”的情况下,将大模型的参数调整为小模型的参数。文中提出,换一种定义“知识”的方法:从输入向量到输出概率大小的一个映射,即教师网络预测结果中各类别概率的相对大小也包含隐式知识。

在训练神经网络时,采用多分类交叉熵损失函数。原理是最大化训练样本结果的似然概率。下面显示了一个例子,假若所有样本预测结果用独热向量表示。

一个明显的方式是用教师网络训练得到的类别概率"soft targets"去训练学生网络。在transfer阶段,我们用相同的“transfer”数据集喂给教师模型和学生模型,用教师模型得到的软分类结果作为学生模型的label进行训练。如果教师模型是多个模型的组合,软分类结果就取平均数。当soft targets的熵越高(各类别相对大小越接近,不确定程度越高,信息量越大),那么就可以提供比hard targets更多的信息。
解释:在训练教师模型时,只保留hard target作为输出,那么该图片对于其他类的相似度信息就被掩盖了,而soft target能够包含更多的信息。由于soft target包含了对不同类的相似度信息(即“知识”,特别是非正确类别概率的相对大小),所以可用教师网络的soft target输出作为训练学生模型的标签,这样就可以完成“知识”的迁移。
但是该输出包含的信息还不够暴露。文中也提到,非正确类别的概率非常接近零,它对交叉熵损失函数提供的影响太小了。为了能够把类别信息更充分地暴露出来(即希望它的熵更高),Hinton团队提出引入蒸馏温度。蒸馏温度越高,输出暴露的信息就更多。
神经网络通常通过使用一个转换logit的“softmax”输出层来获得类概率。在实际操作中,该文更改了多分类输出层的softmax函数:。当
时为softmax函数。随着
的增加,正确类别的概率变低,非正确类别的概率升高,但是各个类别概率的相对大小不变。当
变得非常大时,各类别的概率基本相同。
知识蒸馏的过程
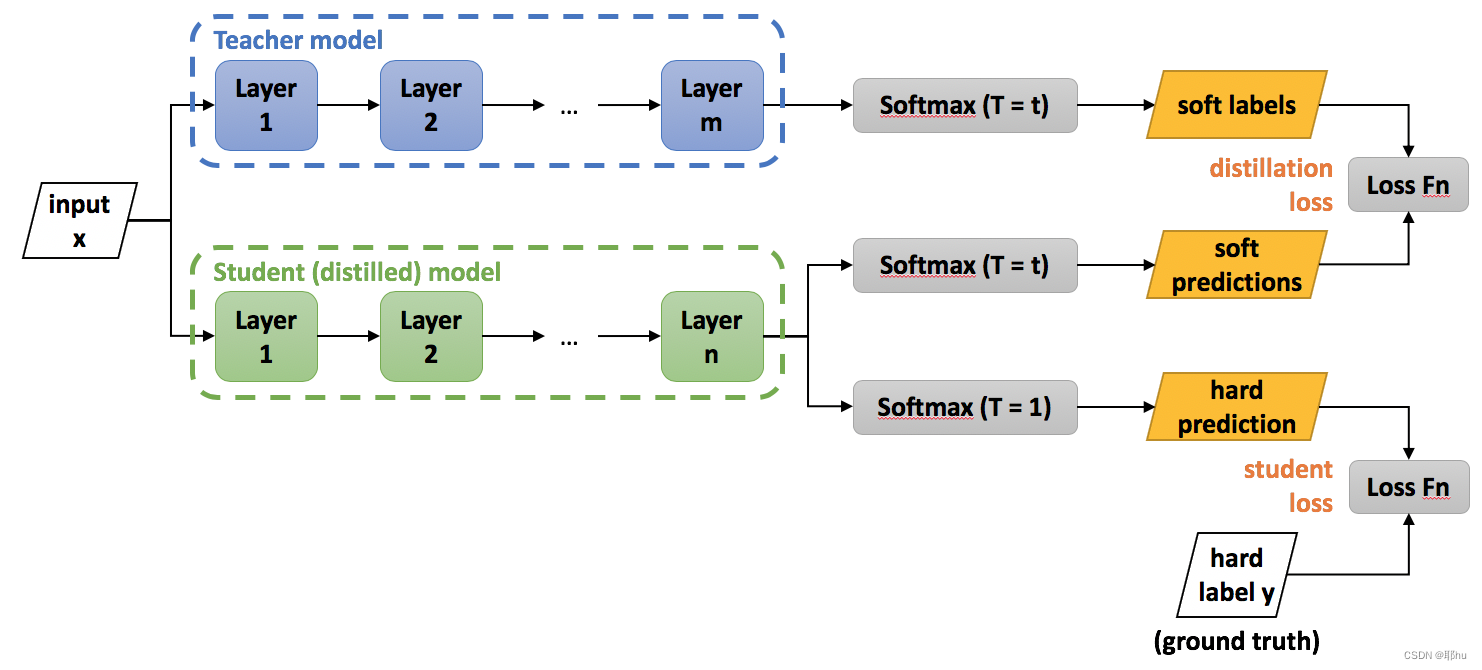
Step1: 将数据喂给温度为的教师网络和温度为
的学生网络,计算它们之间的蒸馏损失(distillation loss),让蒸馏损失越低越好。用教师网络与学生网络相同温度的softmax层(0-1之间)的输出,计算的交叉熵作为损失函数。
是教师网络的预测结果,表示第i个样本属于第j类的概率,作为学生网络的soft target.
是学生网络预测的结果,经过温度为t的softmax层。
Step2: 计算学生网络训练输出的hard prediction(softmax层的输出)和hard label之间的差距(student loss),使之越低越好。用学生网络T=1时的soft层的输出(0-1之间)和标签(非0即1),计算的交叉熵作为损失函数。
Step3: 对两个损失函数进行加权求和,作为总的损失函数进行训练。
目标:微调学生网络的参数,使得总loss最小。具体:梯度下降方法、反向传播方法。
用全样本来训练教师模型,由于教师模型把所有类的知识都传递给了学生模型,尽管训练学生模型时某个类别的样本为0,但是其依然具有对确实类别的分类能力。
知识蒸馏的优化
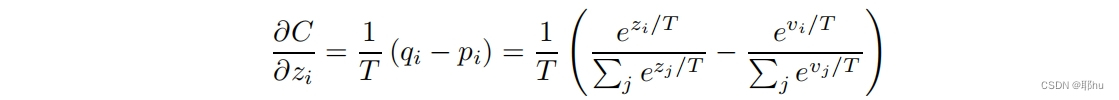
在Matching logits is a special case of distillation这一节中,说明了知识蒸馏相比于前期文献有了什么进步,对soft loss做了一个交叉熵梯度(????不知道这部分怎么求导求出来的,先保留问题,后续再学习。学习Logisitic函数和Softmax函数)。是学生模型的logit输出,
是教师模型的logit输出。对对数项进行泰勒展开。
假设蒸馏温度T足够大,并且logit均值为0时,知识蒸馏就等价于最小均方误差(先前的损失函数)。也就是说,早先的研究是知识蒸馏的极端形式的特例。如果蒸馏温度很低时,蒸馏就没有效果了;如果蒸馏温度很高,soft target过软,可能带来噪音。
实验结果
在MNIST数据集上的初步实验
教师网络:两层隐藏层,1200个ReLU单元,在60000训练集上训练,Dropout防止过拟合(没学过,记录一下),正则化
学生网络:两层隐藏层,800个ReLU,原来犯了147个错误,知识蒸馏后只犯了74个错误。
温度的选择:每个隐藏层300以上个单元,温度应当在8以上更好。若下降到每层30个神经元,2.5~4的温度更好。
零样本学习:如果将学生网络中类别为3的训练样本去除(删去transfer set中的数字“3”),经过教师网络的知识传递后,学生网络仍然能够辨别“3”这个数字。在1010张“3”中,仅仅犯了133个错误。这些错误可以调节偏置项来改善。因为学生网络并没有见过某些数字,导致在这些数字上的学习到的偏置较低,手动调高后可降低在测试集集上的错误率。
语音识别上的实验
在集成DNN的语音模型上进行知识蒸馏。
教师网络:8个隐藏层,每个隐藏层包括2560个ReLUs,随后一层为softmax,训练模型有14000个标签纸。用10个这样的baseline集成在一起,比单个模型提升了性能。
专才模型集成
本节展示了如何训练specialist models,每个专才模型都专攻训练大数据集的不可重叠子集,从而减少训练一个集成模型的计算量。主要的问题是它们很容易过拟合,接下来展示了用soft targets解决过拟合。
在JFT数据集上(Google内部数据集)训练的模型用了两种并行策略:1. 将集成神经网络模型的各模型分配给不同的GPU核心集合,每个集合处理不同的mini-batch,将下降的梯度传递给一个共享参数服务器,然后该服务器给组成神经网络返回新的参数,继续训练;2. 在每个核心上放置不同的神经元子集,实现一个组成模型分布在不同核心上,进行并行。
专才模型
为了减少训练量,实验训练多个专才模型。每一个模型都是经过数据训练的,这些数据是来自一个非常混乱的类子集(比如不同类型的蘑菇)。专才模型的softmax可以变得非常小,当对于其他不是该模型主要判别的图像时,模型都将之视为垃圾类别。
如何分配训练样本:类别的共线性、协方差矩阵
训练过程
基础太差,KL散度、数值解啥的都没学会,后续再补
Soft Target的正则化作用
知识蒸馏的应用场景
- 模型压缩
- 优化训练,防止过拟合(潜在的正则化)
- 对无限大、无监督数据集的数据挖掘:可以把自主爬取的无限大的图片喂给教师网络进行学习,学生模型可以学习到教师模型训练到的结果。
- 少样本、零样本学习
- 区分:迁移学习——把一个领域训练的模型泛化到识别另一个领域的学习















 4887
4887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









