







目录
首先分各个模块列出string类的模拟实现,最后会有统一的汇总代码
一、深浅拷贝
浅拷贝:也称位拷贝,编译器只是将对象中的值拷贝过来。如果对象中管理资源,最后就会导致多个对象共享同一份资源,当一个对象销毁时就会将该资源释放掉,而此时另一些对象不知道该资源已经被释放,以为还有效,所以当继续对资源进项操作时,就会发生发生了访问违规。
可以采用深拷贝解决浅拷贝问题,即:每个对象都有一份独立的资源,不要和其他对象共享。父母给每个孩子都买一份玩具,各自玩各自的就不会有问题了。
二、String类的定义
为了防止调用库中的string,我们自定义了烛渊的命名空间
#pragma once
#include <iostream>
#include <assert.h>
namespace zhuyuan
{
class string
{
public:
//析构函数的定义
~string()
{
//分别将字符串中的字符串数组销毁,并且将指向字符串数组的指针置空
delete[] _str;
_str= nullptr;
//这里的_size指的是当前存储的字符个数
//这里的_capacity指的是开辟的空间最大存储的空间大小
_size=0;
_capacity=0;
}
private:
char* _str;
size_t _size;
size_t _capacity;
//c++的特例,const静态可以在类里面直接声明和定义。
//语法特殊处理,直接可以当成初始化。
public:
const static size_t npos=-1;
};
//当然也可以放在类外面初始化
// size_t string::npos=-1; 
一个size_t的大小是8 ,64位平台下的指针大小为8个字节,一个我们写的string的大小就是24个字节
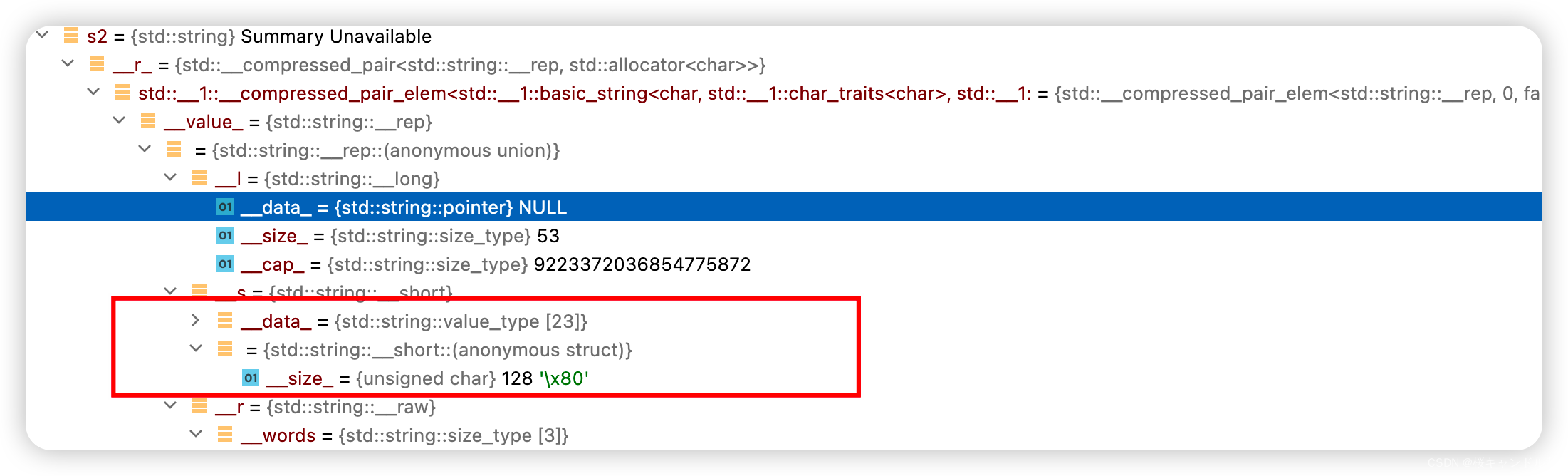
但是实际上我们的编译器可能会给我们开辟一个类似于缓冲池之类的结构让我们的数据到了一定的数量才拷贝到我们的string中。
三、string类的构造函数
由于当前我们的String类还没有显式定义其拷贝构造函数与赋值运算符重载,此时编译器会合成默认的,当用s1构造s2时,编译器会调用默认的拷贝构造。最终导致的问题是,s1、s2共用同一块内存空间,在释放时同一块空间被释放多次而引起程序崩溃,这种拷贝方式,称为浅拷贝。
在“四”中有我们的显式拷贝构造函数,写了“四”中的函数就不会报错了
string(const char* str="")
{
_size=strlen(str);
_capacity=_size;
_str=new char[_capacity+1];
strcpy(_str,str);
}
string s1("hello world");
string s2(s1);s2需要调用string类的拷贝构造函数来创建,但是该类没有显式定义,则使用系统合成的默认拷贝构造函数,Test函数结束时,需要将s1和s2销毁掉。先销毁s2,s2将其__str所指向的空间释放掉,s2对象成功销毁,但是s1中_str成为野指针,当销毁s1时出错。
当然也可以使用初始化列表的形式,但是需要注意的是,在我们下面这个版本的写法中,_size
声明得需要比_capacity更早一些,但是初始化列表的定义的顺序不是按照初始化列表中的顺序来的,而是按照类中声明和定义的顺序来的

string(const char* str = "")
: _size(strlen(str))
, _capacity(_size)
, _str(new char[_capacity + 1])
{
strcpy(_str, str);
}四、string的拷贝构造
1.传统写法
传统写法就是定义一个初始化列表,将我们传入的要拷贝的string类中的参数一一复制。
//s2(s1)
//传统写法
string (const string& s)
:_str(new char[s._capacity+1])
,_size(s._size)
,_capacity(s._capacity)
{
strcpy(_str,s._str);
}2.现代写法
1)定义一个string类定制的swap函数
//现代写法--老板思维
//s2(s1)
//这里写的是针对于string类型的swap,直接交换内部的成员变量
void swap(string &tmp)
{
//::表示调用的是全局的swap函数,跟我们上面那个swap不是同一个。
::swap(_str,tmp._str);
::swap(_size,tmp._size);
::swap(_capacity,tmp._capacity);
}2)定义我们基于交换的拷贝构造
这里我们的现代写法就是老板式思维,也就是要剥削员工。这里我们就是调用构造函数。因为我们的string tmp(s._str)也就是调用了我们上面“三”中的构造函数,所以会将我们传入的s._str作为新的string中的字符串值生成一个新的string,然后拷贝给tmp,而我们所需要做的就是将我们的tmp和我们的this进行交换。但是由于我们原来的this所指向的对象并没有初始化,所以交换给tmp的是一堆随机值,在tmp调用析构函数的时候,这些随机值会导致程序崩溃,所以我们需要给this所指向的对象使用初始化列表初始化一下。
string (const string& s)
//如果下面将随机值换给tmp,然后tmp在调用析构函数的时候会崩溃的。
:_str(nullptr)
,_size(0)
,_capacity(0)
{
//调用构造函数
string tmp(s._str);
//本质是this->swap(tmp)
swap(tmp);
}测试代码
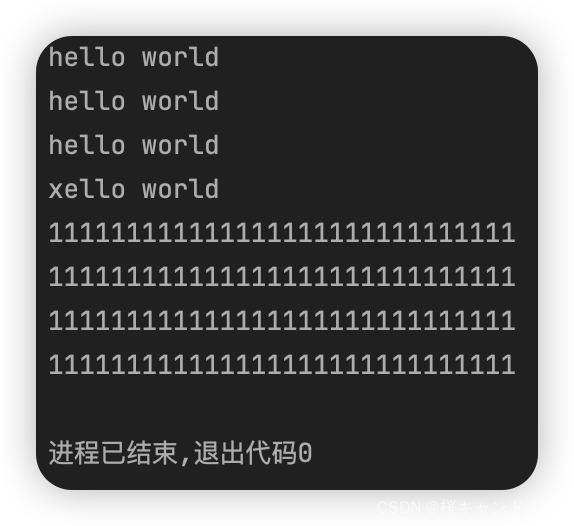
void test_string3()
{
string s1("hello world");
string s2(s1);
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
s2[0] = 'x';
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
string s3("111111111111111111111111111111");
s1 = s3;
cout << s1.c_str() << endl;
cout << s3.c_str() << endl;
s1 = s1;
cout << s1.c_str() << endl;
cout << s3.c_str() << endl;
}
void test_string4()
{
string s1("hello world");
string s2("xxxxxxx");
s1.swap(s2);
cout<<s1.c_str()<<endl;
cout<<s2.c_str()<<endl;
swap(s1, s2);
cout<<s1.c_str()<<endl;
cout<<s2.c_str()<<endl;
}
五、string类的迭代器
对于string类来说迭代器就像是指针一样,所以我们可以采用下面这种写法。我们是定义了一个char*类型的指针iterator和常量指针const_iterator。
begin()就是返回字符串数组的首元素的地址位置。
end()就是返回字符串数组尾元素的地址位置,只要首元素再加上数组的元素的个数就可以了。
typedef char* iterator;
typedef const char *const_iterator;
iterator begin()
{
return _str;
}
const_iterator begin() const
{
return _str;
}
iterator end()
{
return _str+_size;
}
const_iterator end() const
{
return _str+_size;
}测试代码
void test_string2()
{
string s1("hello world");
string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
++it;
}
cout << endl;
it = s1.begin();
while (it != s1.end())
{
*it += 1;
++it;
}
cout << endl;
for (auto ch : s1)
{
cout << ch << " ";
}
cout << endl;
}
六、对string类中私有类成员的获取
c_str()就是将字符串中的字符串数组返回,也就是我们c语言中的字符串数组
size()就是将我们字符串数组中的当前存储的元素个数返回。
capacity就是将我们字符串数组中的最大开辟的元素的个数返回。
const char*c_str() const
{
return _str;
}
size_t size() const
{
return _size;
}
size_t capacity() const
{
return _capacity;
}测试代码
void test_string5()
{
string s1("hello");
cout << s1.c_str() << endl;
s1.push_back('x');
cout << s1.c_str() << endl;
cout << s1.capacity() << endl;
}
七、像字符串数组一档读取string类中的元素
首先我们需要判断这个传入的下标索引是否越界,如果越界,就直接assert断言抛出。
同时我们提供const类型和非const类型的两个版本。
char& operator[](size_t pos)
{
assert(pos<_size);
return _str[pos];
}
const char& operator[](size_t pos) const
{
assert(pos<_size);
return _str[pos];
}测试代码
void test_string1()
{
/*std::string s1("hello world");
std::string s2;*/
string s1("hello world");
string s2;
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
for (size_t i = 0; i < s1.size(); ++i)
{
cout << s1[i] << " ";
}
cout << endl;
for (size_t i = 0; i < s1.size(); ++i)
{
s1[i]++;
}
for (size_t i = 0; i < s1.size(); ++i)
{
cout << s1[i] << " ";
}
cout << endl;
}
八、赋值等于=
1.传统写法
对于赋值等于,我们需要将被赋值的string类中原来的_str字符串析构掉。同时将新的string中的参数拷贝给我们旧的string。
//s1=s3
string &operator=(const string&s)
{
//防止自己跟自己赋值
if(this !=&s)
{
//要多开一个给\0
//如果开辟空间失败会直接抛异常
char *tmp=new char[s._capacity+1];
strcpy(tmp,s._str);
delete[] _str;
_str=tmp;
_size=s._size;
_capacity=s._capacity;
}
return *this;
}2.现代写法
现代写法同样也是我们的老板式写法。也就是拷贝构造生成一个新的string类,然后将这个string类和我们的this指针指向的string对象中的参数进行交换。
//s1=s3
//operator赋值的现代写法
string& operator=(const string& s)
{
if(this !=&s)
{
//这两个都可以,因为我们之前的构造和拷贝构造都写了。
//string tmp(s._str);
string tmp(s);
//不能使用swap(s1,s2),因为库函数中的swap会调用=,
//也就是我们现在正在写的这个函数
//跟这个代码形成循环拷贝,形成栈溢出
swap(tmp);//this->swap(tmp)
}
return *this;
}3.终极写法
//s1=s3
//s1顶替tmp做打工人
//之前我们operator=右边写的参数都是const string& s
//但是现在我们写的参数是string s,也就是说我们并不是引用s3
//而是编译器会帮助我们构造一个新的s3,然后再用拷贝swap交换给我们的s1。
string& operator=(string s)
{
// this->swap(s);
swap(s);
return *this;
}九、string的扩容函数
1.reserve
reverse所需要做的就是开辟一块新的字符串数组,然后将我们旧的字符串数组中的数据拷贝到新的字符串中,然后析构旧的字符串数组。同时更新_capacity参数。
void reserve(size_t n)
{
if(n>_capacity)
{
//开辟一块新的空间
//+1是为了留给\0
char *tmp=new char[n+1];
//将原来的空间中的数据拷贝到新的
strcpy(tmp,_str);
delete[] _str;
_str=tmp;
_capacity=n;
}
}2.resize
void resize(size_t n ,char ch='\0')
{
//如果大于了我们当前的_size就扩容,如果小了就删数据
if(n>_size)
{
//插入数据
reserve(n);
for(size_t i=_size;i<n;++i)
{
_str[i]=ch;
}
_str[n]='\0';
_size=n;
}
else
{
//删除数据
_str[n]='\0';
_size=n;
}
}测试代码
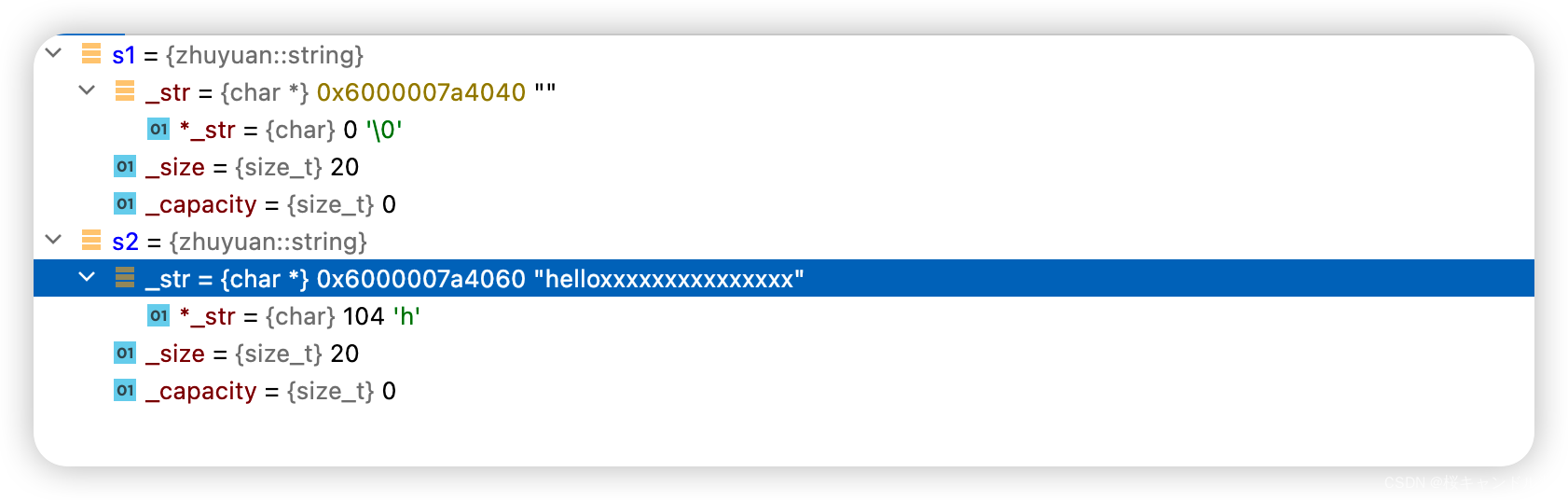
void test12()
{
string s1;
s1.resize(20);
cout<<s1.size()<<endl;
string s2("hello");
s2.resize(20,'x');
cout<<s2.size()<<endl;
}
十、追加函数的实现
1.push_back
push_back就是追加一个字符,然后再追加之前需要判断是不是满了,满了就要扩容,同时调用我们的reserve函数开辟一块新的空间。最后不要忘记要加上\0。
void push_back(char ch)
{
//满了就扩容
if(_size==_capacity)
{
reserve(_capacity==0 ? 4:_capacity*2);
}
_str[_size]=ch;
++_size;
_str[_size]='\0';
}2.append
append所追加的是一整个字符串,或者是一个string。
1)追加一个字符串
//append是添加一个字符串
void append(const char* str)
{
//len是需要加入的字符串的长度
size_t len=strlen(str);
//满了就扩容
if(_size+len>_capacity)
{
reserve(_size+len);
}
//初始位置再加上我们原有的长度就是我们目标的拷贝位置。
strcpy(_str+_size,str);
// strcat没有strcpy好,因为strcat需要先找到'\0'才会追加,
// 但是遍历查找'\0'的方式速度太慢了,不如strcpy直接指定追加的位置。
// strcat(_str,str);
_size+=len;
}2)追加一个string
void append(const string &s)
{
append(s._str);
}
3)追加n个相同的字符ch
void append(size_t n ,char ch)
{
reserve(_size+n);
for(size_t i=0;i<n;++i)
{
push_back(ch);
}
}3.加等操作
1)使用+=追加一个字符
一般我们都是使用+=而不使用append的。
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
2)使用+=追加一个字符串
string& operator+=(const char* str)
{
append(str);
return *this;
}测试代码
void test_string5()
{
string s1("hello");
cout << s1.c_str() << endl;
s1.push_back('x');
cout << s1.c_str() << endl;
cout << s1.capacity() << endl;
s1 += 'y';
s1 += 'z';
s1 += 'z';
s1 += 'z';
s1 += 'z';
s1 += 'z';
s1 += 'z';
cout << s1.c_str() << endl;
cout << s1.capacity() << endl;
}
十一、在指定位置插入insert
1.在指定位置插入一个字符
string& insert(size_t pos,char ch)
{
assert(pos<_size);
//满了就扩容
if(_size==_capacity)
{
reserve(_capacity==0 ? 4:_capacity*2);
}
//
// size_t end=_size;
//这样的话会出问题,因为end要小于pos才会结束,而如果pos等于0的话,我们的end就要是-1才能结束
//而我们的pos由于是end由于是size_t类型也就是无符号整型,是没办法表示负数的,所以会陷入死循环!
//
// while(end>=(int)pos)
// {
// _str[end+1]=_str[end];
// --end;
// }
// _str[pos]=ch;
// ++_size;
//可以将end相比于上面+1,然后将跳出循环条件改成>来杜绝上面那种死循环的情况
size_t end=_size+1;
while(end>pos)
{
_str[end]=_str[end-1];
--end;
}
_str[pos]=ch;
++_size;
return *this;
}2.在指定位置插入一个字符串
//在指定位置插入一整个字符串
string& insert(size_t pos,const char* ch)
{
assert(pos<=_size);
size_t len= strlen(ch);
if(_size+len>_capacity)
{
reserve(_size+len);
}
//挪动数据
size_t end=_size+len;
while(end>=pos+len)
{
_str[end]=_str[end-len];
--end;
}
strncpy(_str+pos,ch,len);
_size+=len;
return *this;
}测试程序
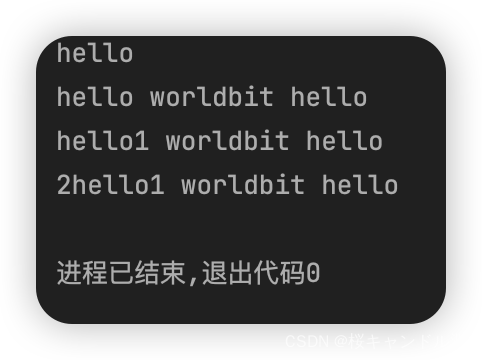
void test_string6()
{
string s1("hello");
cout << s1.c_str() << endl;
s1 += ' ';
s1.append("world");
s1 += "bit hello";
cout << s1.c_str() << endl;
s1.insert(5,'1');
cout << s1.c_str() << endl;
s1.insert(0, '2');
cout << s1.c_str() << endl;
}
void test_string7()
{
string s1("hello");
cout << s1.c_str() << endl;
s1.insert(2, "world");
cout << s1.c_str() << endl;
s1.insert(0, "world ");
cout << s1.c_str() << endl;
}
十二、擦除指定位置的数据erase
erase是擦除指定位置pos的len个数据。如果我们pos位置越界了就直接断言派出异常,如果我们的len越界或者是len+pos月季的话就就在pos的位置截断
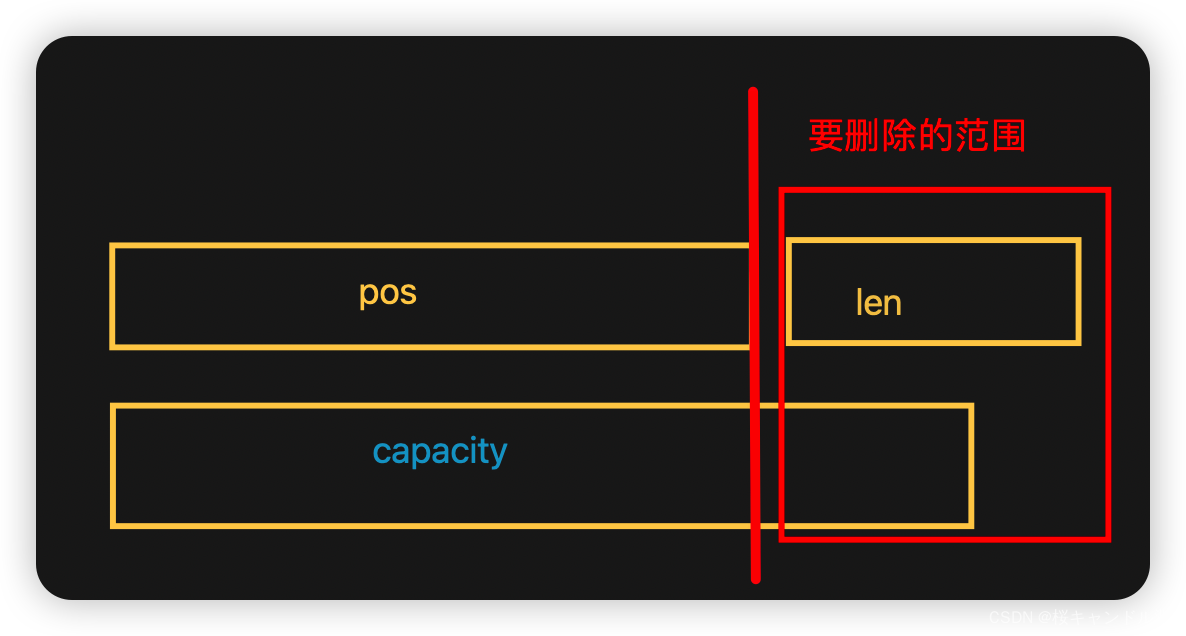
其他正常情况的话就将要删除部分后面的数据拷贝到前面来覆盖掉,然后更新我们的_size数据。
void erase(size_t pos,size_t len=npos)
{
assert(pos<_size);
if(len==npos||pos+len>=_size)
{
_str[pos]='\0';
_size=pos;
}
else
{
strcpy(_str+pos,_str+pos+len);
_size-=len;
}
}测试程序
void test_string8()
{
string s1("hello");
s1.erase(1, 10);
cout << s1.c_str() << endl;
string s2("hello");
s2.erase(1);
cout << s2.c_str() << endl;
string s3("hello");
s3.erase(1, 2);
cout << s3.c_str() << endl;
}
十三、查找指定的字符
1)find一个字符
查找从指定位置开始匹配得上的第一个字符
size_t find(char ch,size_t pos=0)
{
assert(pos<_size);
for (int i=pos;i<_size;i++)
{
if (_str[i]==ch)
{
return i;
}
}
}2)find一个字符串
从指定位置查找第一个匹配的上的字符串。使用strstr可以很方便地完成。
size_t find(const char*str,size_t pos=0)
{
assert(pos<_size);
//strstr如果查找成功会返回对应的起始位置的地址
const char*ret=strstr(_str+pos,str);
//如果查找到了这个地址,就将地址相减,得出相对距离
if(ret)
{
return (ret-_str);
}
else
{
return npos;
}
}测试程序
string s16="made in China";
cout<<s16.find("China",3)<<endl;
cout<<s16.find('i',2)<<endl; 
3)提取指定位置pos开始的n个字符substr
//"ko no dio da"
string substr(size_t pos,size_t len=npos) const
{
assert(pos< _size);
size_t reallen=len;
if(len==npos||pos+len>_size)
{
reallen =_size-pos;
}
string sub;
for(size_t i=0;i<reallen;++i)
{
sub+= _str[pos+i];
}
return sub;
}测试程序
void test11()
{
string s19="ko no dio da";
cout<<s19.substr(4,10)<<endl;
}
十四、布尔判等操作
对于字符串之间的比较可以调用strcmp来辅助完成。
bool operator==(const string&s) const
{
return (strcmp(c_str(),s.c_str())==0) ? true: false;
};
bool operator>=(const string&s) const
{
return (strcmp(c_str(),s.c_str())>=0) ? true: false;
};
bool operator<=(const string&s) const
{
return (strcmp(c_str(),s.c_str())<=0) ? true: false;
};
bool operator>(const string&s) const
{
return (strcmp(c_str(),s.c_str())>0) ? true: false;
};
bool operator<(const string&s) const
{
return (strcmp(c_str(),s.c_str())<0) ? true: false;
};
bool operator!=(const string&s) const
{
return (strcmp(c_str(),s.c_str())!=0) ? true: false;
};
//或者是像这种进行复用,注意不要循环复用,一般写三个就可以用复用表示出所有的
// bool operator>=(const string&s) const
// {
// return *this>s ||*this==s;
// };
测试程序
string s13="konodioda";
string s14="konokimojogada";
string s15="konodioda";
cout<<(s13==s14)<<endl;
cout<<(s13==s15)<<endl;
cout<<(s13>=s14)<<endl;
cout<<(s14>=s13)<<endl;
cout<<(s13<=s14)<<endl;
cout<<(s14<=s13)<<endl;
cout<<(s13>s14)<<endl;
cout<<(s14>s13)<<endl;
cout<<(s13<s14)<<endl;
cout<<(s14<s13)<<endl;
cout<<(s13!=s14)<<endl;
cout<<(s13>s14)<<endl;
cout<<(s13!=s15)<<endl;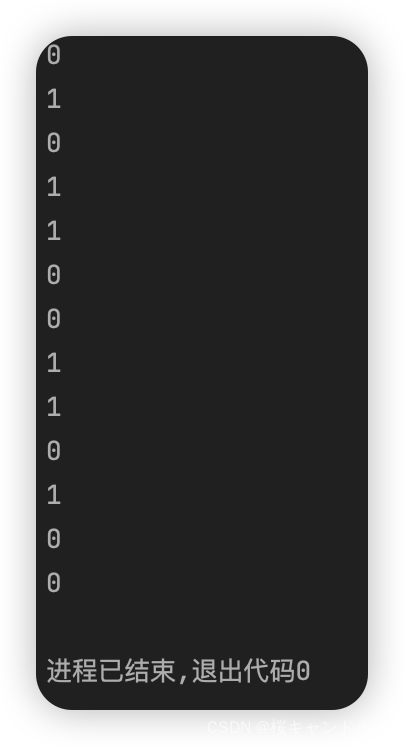
十五、流插入和流提取操作
1.流插入
//流插入
ostream &operator<<(ostream& out ,const string&s)
{
for(size_t i=0;i<s.size();++i)
{
//将我们的数组中的元素一个个传给out,由于缓冲池的存在,速度不会特别慢
out<<s[i];
}
return out;
}
优化
可以先清空一下当前的输入缓冲区
void clear()
{
_size = 0;
_str[_size] = '\0';
}
//流插入
ostream &operator<<(ostream& out ,const string&s)
{
out.clear();
for(size_t i=0;i<s.size();++i)
{
out<<s[i];
}
return out;
}2.流提取
//流提取
istream & operator>>(istream& in,string&s)
{
//如果输入字符串很长,不断+=需要频繁扩容,效率很低
char ch;
//cin默认空格或者换行是分隔符,默认忽略,所以无法结束输入,
//一定要使用get()方法
//in>>ch
ch=in.get();
while(ch!=' '&&ch!='\n')
{
s+=ch;
//cin默认空格或者换行是分隔符,默认忽略,所以要使用get()方法
ch=in.get();
}
return in;
}优化
为了减少上面频繁开辟空间的情况,我们可以用一个定长的临时数组来存储我们的输入,也就是充当缓冲区的作用,当填充结束或者超出了临时定长数组的长度就需要将其拷贝给我们的string对象。
istream & operator>>(istream& in,string&s)
{
//如果输入字符串很长,不断+=需要频繁扩容,效率很低
char ch;
//in>>ch
ch=in.get();
const size_t N=32;
//给\0留一个位置
char buff[N+1];
size_t i=0;
while(ch!=' '&&ch!='\n')
{
buff[i++]=ch;
if(i==N-1)
{
buff[i]='\0';
s+=buff;
i=0;
}
ch=in.get();
}
buff[i]='\0';
s+=buff;
return in;
}测试程序
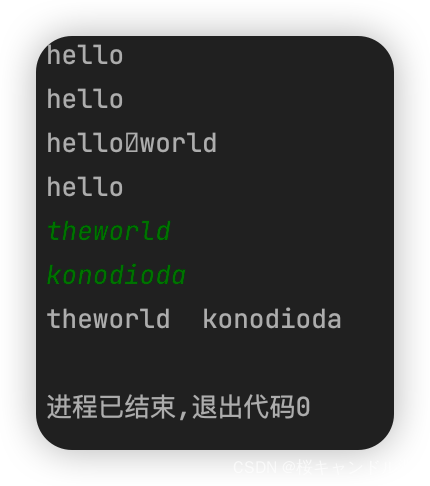
void test_string9()
{
/* string s1;
cin >> s1;
cout << s1 << endl;*/
string s1("hello");
cout << s1 << endl;
cout << s1.c_str() << endl;
s1 += '\0';
s1 += "world";
cout << s1 << endl;
cout << s1.c_str() << endl;
string s3, s4;
cin >> s3 >> s4;
cout << s3<<" "<< s4 << endl;
}
void test10()
{
string s18;
cin>>s18;
cout<<s18.c_str()<<endl;
} 
十六、主程序合集
由于有些代码有好几个版本,所以注释到只剩下一个
#pragma once
#include <iostream>
#include <assert.h>
namespace zhuyuan
{
class string
{
public:
typedef char* iterator;
typedef const char *const_iterator;
iterator begin()
{
return _str;
}
const_iterator begin() const
{
return _str;
}
iterator end()
{
return _str+_size;
}
const_iterator end() const
{
return _str+_size;
}
// string(const char*str)
// :_str(new char[strlen(str)+1])
// //存储的有效字符个数
// ,_size(strlen(str))
// ,_capacity(strlen(str))
// {
// strcpy(_str,str);
// }
//string(const char* str = "\0")
/*string(const char* str = "")
:_str(new char[strlen(str)+1])
, _size(strlen(str))
, _capacity(strlen(str))
{
strcpy(_str, str);
}*/
// string(const char* str = "")
// : _size(strlen(str))
// , _capacity(_size)
// , _str(new char[_capacity + 1])
// {
// strcpy(_str, str);
// }
string(const char* str="")
{
_size=strlen(str);
_capacity=_size;
_str=new char[_capacity+1];
strcpy(_str,str);
}
~string()
{
delete[] _str;
_str= nullptr;
_size=0;
_capacity=0;
}
const char*c_str() const
{
return _str;
}
size_t size() const
{
return _size;
}
size_t capacity() const
{
return _capacity;
}
char& operator[](size_t pos)
{
assert(pos<_size);
return _str[pos];
}
const char& operator[](size_t pos) const
{
assert(pos<_size);
return _str[pos];
}
// string (const char* str = "")
// {
构造String类对象时,如果传递nullptr指针,可以认为程序非
// if (nullptr == str)
// {
// assert(false);
// return;
// }
// _str = new char[strlen(str) + 1];
// strcpy(_str, str);
// cout<<&_str<<endl;
// cout<<&str<<endl;
// }
//s2(s1)
//传统写法
//如果是浅拷贝的话,析构的时候会析构两次,程序会崩溃
// string (const string& s)
// :_str(new char[s._capacity+1])
// ,_size(s._size)
// ,_capacity(s._capacity)
// {
// strcpy(_str,s._str);
// }
//现代写法--老板思维
//s2(s1)
//这里写的是针对于string类型的swap,直接交换内部的成员变量
void swap(string &tmp)
{
//::表示调用的是全局的swap函数,跟我们上面那个swap不是同一个。
::swap(_str,tmp._str);
::swap(_size,tmp._size);
::swap(_capacity,tmp._capacity);
}
string (const string& s)
//如果下面将随机值换给tmp,然后tmp在调用析构函数的时候会崩溃的。
:_str(nullptr)
,_size(0)
,_capacity(0)
{
//调用构造函数
string tmp(s._str);
//本质是this->swap(tmp)
swap(tmp);
}
// //s1=s3
// string &operator=(const string&s)
// {
// //防止自己跟自己赋值
// if(this !=&s)
// {
// //要多开一个给\0
// //如果开辟空间失败会直接抛异常
// char *tmp=new char[s._capacity+1];
// strcpy(tmp,s._str);
//
// delete[] _str;
//
// _str=tmp;
// _size=s._size;
// _capacity=s._capacity;
// }
// return *this;
// }
// //s1=s3
// //operator赋值的现代写法
// string& operator=(const string& s)
// {
// if(this !=&s)
// {
// //这两个都可以,因为我们之前的构造和拷贝构造都写了。
// //string tmp(s._str);
// string tmp(s);
// //不能使用swap(s1,s2),因为库函数中的swap会调用=,跟这个代码形成循环拷贝,形成栈溢出
// swap(tmp);//this->swap(tmp)
// }
// return *this;
// }
//s1=s3
//s1顶替tmp做打工人
//之前我们operator=右边写的参数都是const string& s
//但是现在我们写的参数是string s,也就是说我们并不是引用s3
//而是编译器会帮助我们构造一个新的s3,然后再用拷贝swap交换给我们的s1。
string& operator=(string s)
{
// this->swap(s);
swap(s);
return *this;
}
void reserve(size_t n)
{
if(n>_capacity)
{
//开辟一块新的空间
char *tmp=new char[n+1];
//将原来的空间中的数据拷贝到新的
strcpy(tmp,_str);
delete[] _str;
_str=tmp;
_capacity=n;
}
}
void resize(size_t n ,char ch='\0')
{
//如果大于了我们当前的_size就扩容,如果小了就删数据
if(n>_size)
{
//插入数据
reserve(n);
for(size_t i=_size;i<n;++i)
{
_str[i]=ch;
}
_str[n]='\0';
_size=n;
}
else
{
//删除数据
_str[n]='\0';
_size=n;
}
}
void push_back(char ch)
{
//满了就扩容
if(_size==_capacity)
{
reserve(_capacity==0 ? 4:_capacity*2);
}
_str[_size]=ch;
++_size;
_str[_size]='\0';
}
//append是添加一个字符串
void append(const char* str)
{
//len是需要加入的字符串的长度
size_t len=strlen(str);
//满了就扩容
if(_size+len>_capacity)
{
reserve(_size+len);
}
//初始位置再加上我们原有的长度就是我们目标的拷贝位置。
strcpy(_str+_size,str);
// strcat没有strcpy好,因为strcat需要先找到'\0'才会追加,
// 但是遍历查找'\0'的方式速度太慢了,不如strcpy直接指定追加的位置。
// strcat(_str,str);
_size+=len;
}
void append(const string &s)
{
append(s._str);
}
void append(size_t n ,char ch)
{
reserve(_size+n);
for(size_t i=0;i<n;++i)
{
push_back(ch);
}
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
string& operator+=(const char* str)
{
append(str);
return *this;
}
string& insert(size_t pos,char ch)
{
assert(pos<_size);
//满了就扩容
if(_size==_capacity)
{
reserve(_capacity==0 ? 4:_capacity*2);
}
//
// size_t end=_size;
// while(end>=(int)pos)
// {
// _str[end+1]=_str[end];
// --end;
// }
// _str[pos]=ch;
// ++_size;
size_t end=_size+1;
while(end>pos)
{
_str[end]=_str[end-1];
--end;
}
_str[pos]=ch;
++_size;
return *this;
}
//在指定位置插入一整个字符串
string& insert(size_t pos,const char* ch)
{
assert(pos<=_size);
size_t len= strlen(ch);
if(_size+len>_capacity)
{
reserve(_size+len);
}
//挪动数据
size_t end=_size+len;
while(end>=pos+len)
{
_str[end]=_str[end-len];
--end;
}
strncpy(_str+pos,ch,len);
_size+=len;
return *this;
}
void erase(size_t pos,size_t len=npos)
{
assert(pos<_size);
if(len==npos||pos+len>=_size)
{
_str[pos]='\0';
_size=pos;
}
else
{
strcpy(_str+pos,_str+pos+len);
_size-=len;
}
}
size_t find(char ch,size_t pos=0)
{
assert(pos<_size);
for (int i=pos;i<_size;i++)
{
if (_str[i]==ch)
{
return i;
}
}
}
size_t find(const char*str,size_t pos=0)
{
assert(pos<_size);
const char*ret=strstr(_str+pos,str);
if(ret)
{
return (ret-_str);
}
else
{
return npos;
}
}
void clear()
{
_size = 0;
_str[_size] = '\0';
}
//"ko no dio da"
string substr(size_t pos,size_t len=npos) const
{
assert(pos< _size);
size_t reallen=len;
if(len==npos||pos+len>_size)
{
reallen =_size-pos;
}
string sub;
for(size_t i=0;i<reallen;++i)
{
sub+= _str[pos+i];
}
return sub;
}
bool operator==(const string&s) const
{
return (strcmp(c_str(),s.c_str())==0) ? true: false;
};
bool operator>=(const string&s) const
{
return (strcmp(c_str(),s.c_str())>=0) ? true: false;
};
// bool operator>=(const string&s) const
// {
// return *this>s ||*this==s;
// };
// bool operator<=(const string&s) const
// {
// return (strcmp(c_str(),s.c_str())<=0) ? true: false;
// };
bool operator<=(const string&s) const
{
return !(*this>s);
};
// bool operator>(const string&s) const
// {
// return (strcmp(c_str(),s.c_str())>0) ? true: false;
// };
bool operator>(const string&s) const
{
return (strcmp(c_str(),s.c_str())>0) ? true: false;
};
bool operator<(const string&s) const
{
return (strcmp(c_str(),s.c_str())<0) ? true: false;
};
bool operator!=(const string&s) const
{
return (strcmp(c_str(),s.c_str())!=0) ? true: false;
};
private:
char* _str;
size_t _size;
size_t _capacity;
//c++的特例,const静态可以在类里面直接声明和定义。
//语法特殊处理,直接可以当成初始化。
public:const static size_t npos=-1;
};
// size_t string::npos=-1;
//流插入
ostream &operator<<(ostream& out ,const string&s)
{
out.clear();
for(size_t i=0;i<s.size();++i)
{
out<<s[i];
}
return out;
}
// istream & operator>>(istream& in,string&s)
// {
// //如果输入字符串很长,不断+=需要频繁扩容,效率很低
// char ch;
// //in>>ch
// ch=in.get();
// while(ch!=' '&&ch!='\n')
// {
// s+=ch;
// //cin默认空格或者换行是分隔符,默认忽略
// ch=in.get();
// }
// return in;
// }
istream & operator>>(istream& in,string&s)
{
//如果输入字符串很长,不断+=需要频繁扩容,效率很低
char ch;
//in>>ch
ch=in.get();
const size_t N=32;
//给\0留一个位置
char buff[N+1];
size_t i=0;
while(ch!=' '&&ch!='\n')
{
buff[i++]=ch;
if(i==N-1)
{
buff[i]='\0';
s+=buff;
i=0;
}
ch=in.get();
}
buff[i]='\0';
s+=buff;
return in;
}十七、测试程序合集
1.定义在主程序中的调用测试程序
#include <iostream>
using namespace std;
#include <assert.h>
#include "string.h"
int main() {
try
{
zhuyuan::test_string0();
}
catch(std::exception&e)
{
std::cout<<e.what()<<std::endl;
}
return 0;
}2.测试程序
// void test_string0()
// {
// string s1("hello world");
// string s2(s1);
// std::cout<<s1.c_str()<<std::endl;
// std::cout<<s2.c_str()<<std::endl;
// string::iterator it;
//
// string s3("sikoni hi teyazida");
// s1=s3;
// std::cout<<s1.c_str()<<std::endl;
// std::cout<<s3.c_str()<<std::endl;
// while(it!=s1.end())
// {
// std::cout<<*it<<" ";
// it++;
// }
// std::cout<<std::endl;
// //范围for
// for(auto ch :s1)
// {
// std::cout<<ch<<" ";
// }
// std::cout<<std::endl;
// string s4="ko no dio ";
// s4.push_back('d');
// s4.push_back('a');
// cout<<s4.c_str()<<endl;
//
// string s5="ko no ki mo";
// s5+='j';
// s5+='o';
// s5+='g';
// s5+='a';
// s5+='d';
// s5+='a';
// cout<<s5.c_str()<<endl;
// string s6="砸 ";
// string s7="瓦鲁多!!";
// s6.append("瓦鲁多!!");
// cout<<s6.c_str()<<endl;
// s6.append(s7);
// cout<<s6.c_str()<<endl;
//
// string s5="ko no ki mo";
// s5+="jo ga da";
// cout<<s5.c_str()<<endl;
//
// string s7("helo");
// s7.insert(3,'l');
// cout<<s7.c_str()<<endl;
//
// string s8("what up");
// s8.insert(4,"'s");
// cout<<s8.c_str()<<endl;
//
// string s9("ji ni tai mei");
// s9.erase(3,4);
// cout<<s9.c_str()<<endl;
//
// string s10("三点几嘞,饮茶先啦!");
// std::cout<<s10<<endl;
//
// string s11;
// cin>>s11;
// cout<<s11;
//
// string s12("hewlloworld");
// //查找从第三个位置后面的w的位置。
// cout<<s12.find('w',3)<<endl;
//
// string s13="konodioda";
// string s14="konokimojogada";
// string s15="konodioda";
// cout<<(s13==s14)<<endl;
// cout<<(s13==s15)<<endl;
// cout<<(s13>=s14)<<endl;
// cout<<(s14>=s13)<<endl;
// cout<<(s13<=s14)<<endl;
// cout<<(s14<=s13)<<endl;
// cout<<(s13>s14)<<endl;
// cout<<(s14>s13)<<endl;
// cout<<(s13<s14)<<endl;
// cout<<(s14<s13)<<endl;
// cout<<(s13!=s14)<<endl;
// cout<<(s13>s14)<<endl;
// cout<<(s13!=s15)<<endl;
//
// string s16="made in China";
// cout<<s16.find("China",3)<<endl;
// cout<<s16.find('i',2)<<endl;
//
//
// }
// void test_string1()
// {
// /*std::string s1("hello world");
// std::string s2;*/
// string s1("hello world");
// string s2;
//
// cout << s1.c_str() << endl;
// cout << s2.c_str() << endl;
//
// for (size_t i = 0; i < s1.size(); ++i)
// {
// cout << s1[i] << " ";
// }
// cout << endl;
//
// for (size_t i = 0; i < s1.size(); ++i)
// {
// s1[i]++;
// }
//
// for (size_t i = 0; i < s1.size(); ++i)
// {
// cout << s1[i] << " ";
// }
// cout << endl;
// }
void test_string2()
{
string s1("hello world");
string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it << " ";
++it;
}
cout << endl;
it = s1.begin();
while (it != s1.end())
{
*it += 1;
++it;
}
cout << endl;
for (auto ch : s1)
{
cout << ch << " ";
}
cout << endl;
}
void test_string3()
{
string s1("hello world");
string s2(s1);
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
s2[0] = 'x';
cout << s1.c_str() << endl;
cout << s2.c_str() << endl;
string s3("111111111111111111111111111111");
s1 = s3;
cout << s1.c_str() << endl;
cout << s3.c_str() << endl;
s1 = s1;
cout << s1.c_str() << endl;
cout << s3.c_str() << endl;
}
void test_string4()
{
string s1("hello world");
string s2("xxxxxxx");
s1.swap(s2);
cout<<s1.c_str()<<endl;
cout<<s2.c_str()<<endl;
swap(s1, s2);
cout<<s1.c_str()<<endl;
cout<<s2.c_str()<<endl;
}
void test_string5()
{
string s1("hello");
cout << s1.c_str() << endl;
s1.push_back('x');
cout << s1.c_str() << endl;
cout << s1.capacity() << endl;
s1 += 'y';
s1 += 'z';
s1 += 'z';
s1 += 'z';
s1 += 'z';
s1 += 'z';
s1 += 'z';
cout << s1.c_str() << endl;
cout << s1.capacity() << endl;
}
void test_string6()
{
string s1("hello");
cout << s1.c_str() << endl;
s1 += ' ';
s1.append("world");
s1 += "bit hello";
cout << s1.c_str() << endl;
s1.insert(5,'1');
cout << s1.c_str() << endl;
s1.insert(0, '2');
cout << s1.c_str() << endl;
}
void test_string7()
{
string s1("hello");
cout << s1.c_str() << endl;
s1.insert(2, "world");
cout << s1.c_str() << endl;
s1.insert(0, "world ");
cout << s1.c_str() << endl;
}
void test_string8()
{
string s1("hello");
s1.erase(1, 10);
cout << s1.c_str() << endl;
string s2("hello");
s2.erase(1);
cout << s2.c_str() << endl;
string s3("hello");
s3.erase(1, 2);
cout << s3.c_str() << endl;
}
void test_string9()
{
/* string s1;
cin >> s1;
cout << s1 << endl;*/
string s1("hello");
cout << s1 << endl;
cout << s1.c_str() << endl;
s1 += '\0';
s1 += "world";
cout << s1 << endl;
cout << s1.c_str() << endl;
string s3, s4;
cin >> s3 >> s4;
cout << s3<<" "<< s4 << endl;
}
void test10()
{
string s18;
cin>>s18;
cout<<s18.c_str()<<endl;
}
void test11()
{
string s19="ko no dio da";
cout<<s19.substr(4,10)<<endl;
}
void test12()
{
string s1;
s1.resize(20);
cout<<s1.size()<<endl;
string s2("hello");
s2.resize(20,'x');
cout<<s2.size()<<endl;
}
void test13()
{
std::string s0;
std::string s1("1111");
std::string s2("11111111111111111111111111111111111111111111111111111");
cout<<sizeof(s0)<<sizeof(s1)<<sizeof (s2)<<endl;
cout<<sizeof(size_t)<<endl;
}
}















 2062
2062











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











