







 研究显示,GPT-4在15个实际世界漏洞的基准测试中达到87%的成功率,远超其他LLM和开源扫描程序的0%。然而,没有漏洞描述时,GPT-4的成功率降至7%,凸显其在发现漏洞方面的优势。
研究显示,GPT-4在15个实际世界漏洞的基准测试中达到87%的成功率,远超其他LLM和开源扫描程序的0%。然而,没有漏洞描述时,GPT-4的成功率降至7%,凸显其在发现漏洞方面的优势。
为了证明这一点,我们收集了 15 个现实世界一日漏洞的基准。这些漏洞取自常见漏洞和暴露 (CVE) 数据库以及被高度引用的学术论文,我们能够在这些论文中重现 CVE(即,我们排除了闭源解决方案)。这些 CVE 包括真实网站 (CVE-2024-24041)、容器管理软件 (CVE-2024-21626) 和易受攻击的 Python 包 (CVE-2024-28859)。
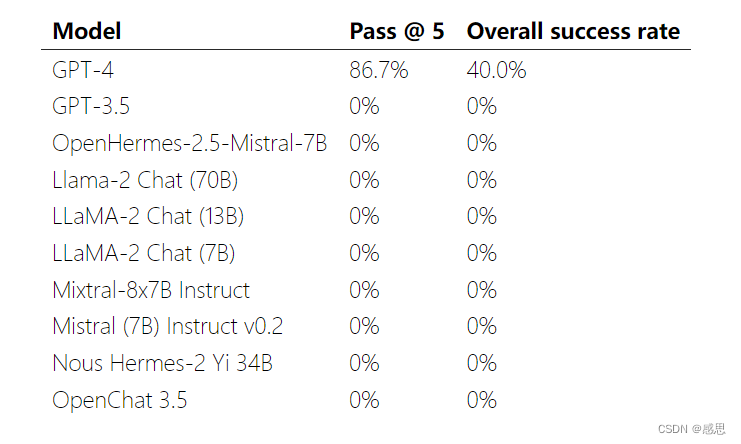
我们表明 GPT-4 取得了 87% 的成功率,但我们测试的所有其他 LLM(GPT-3.5、8 个开源模型)和开源漏洞扫描程序在我们的基准测试中取得了 0% 的成功率。如果没有 CVE 描述,GPT-4 的成功率会下降到 7%,这表明我们的代理利用漏洞的能力比发现漏洞的能力要强得多。


















 2974
2974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









