






论文名称:An Image is Worth 16x16 Words:Transformers for Image Recognition at Scale
[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (arxiv.org)
相关优化:
[2112.11010] MPViT: Multi-Path Vision Transformer for Dense Prediction (arxiv.org)
参考博客与视频:
Vision Transformer 超详细解读 (原理分析+代码解读) (二) - 知乎 (zhihu.com)
11.1 Vision Transformer(vit)网络详解_哔哩哔哩_bilibili
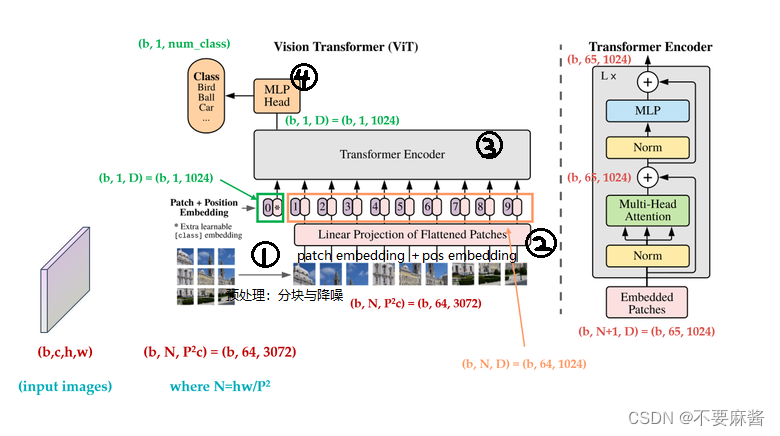
一、图片预处理:分块与降噪
先把图片展平成由若干块组成的2D序列,每个块的维度为(P1 x P2, C),其中 P 是块大小,块大小为 P1 x P2,C 是 channel 数。
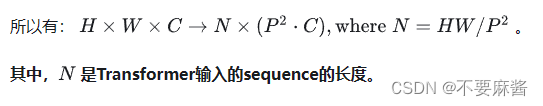
故有 n 个 token。
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1=p, p2=p)二、patch embedding + class_token
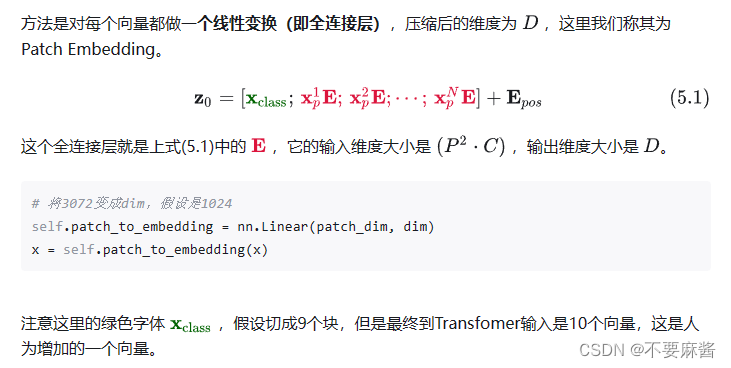
法1.使用全连接层的patch embedding
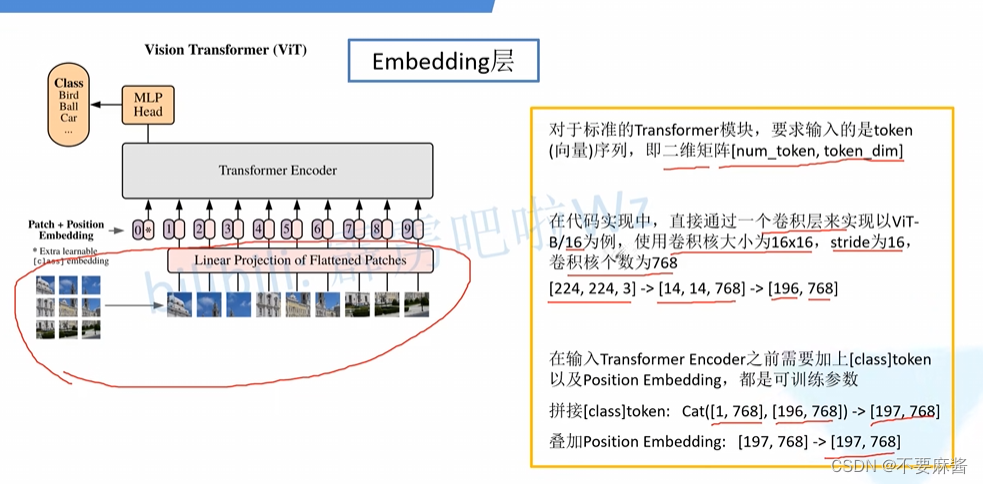
法2.卷积 + flattening(剩去分块)


















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









