










前言
来吧,继续CherryStudio的实践,前边给Cherry Studio添加知识库,对接思源笔记,但美中不足,思源笔记得导出再导入知识库,本文看一下obsidian笔记,笔记内容直接被知识库使用,免去导出导入的环节😄😄😄
准备
CherryStudio安装配置,请参考前期文档:
【AI入门】Cherry入门1:Cherry Studio的安装及配置-CSDN博客
选看内容:
【AI入门】CherryStudio入门2:配置及使用 MCP-CSDN博客
【AI入门】CherryStudio入门3:结合FastMCP创建自己的MCP服务,实现哔哩视频查询-CSDN博客
【AI入门】CherryStudio入门4:创建知识库,对接思源笔记-CSDN博客
设置Cherry Studio知识库
模型准备,知识库需要嵌入模型,及重排模型,我们现在模型服务中添加上,后面备用:
需要硅基流动免费tocken的,可以参考我之前的文档:【AI入门】硅基流动:获得DeepSeek免费token(含其他大模型)-CSDN博客
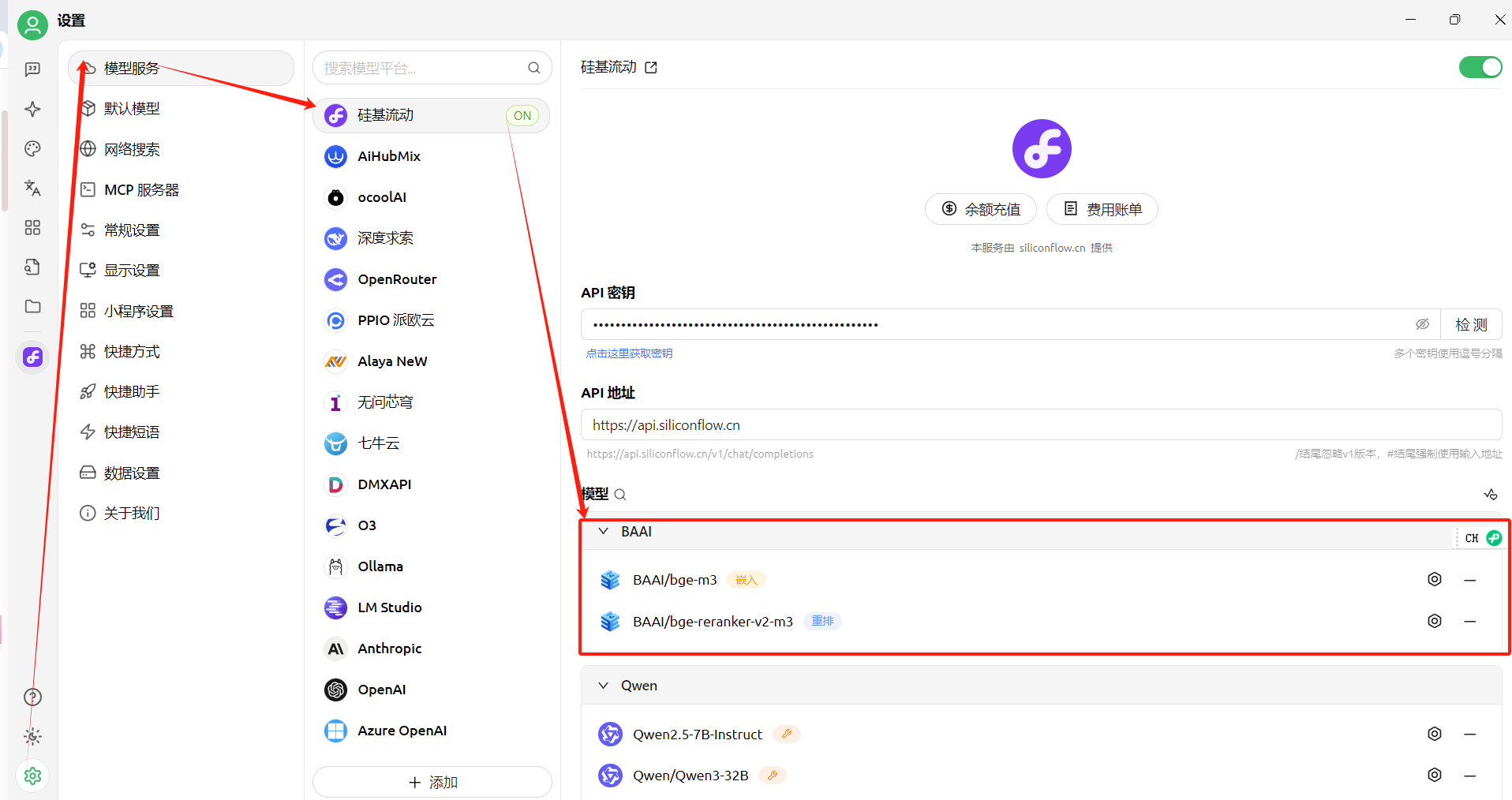
然后创建知识库:
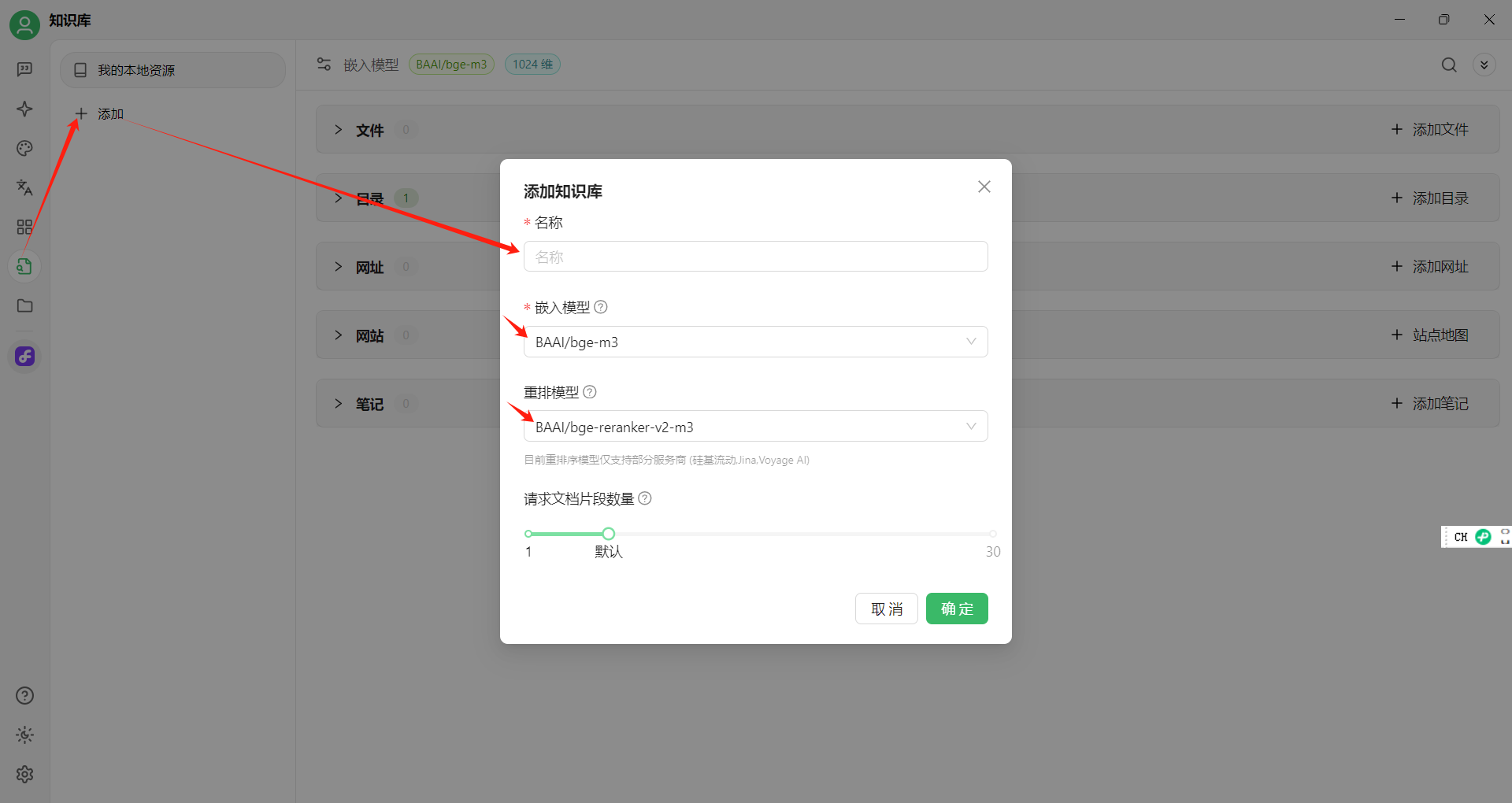
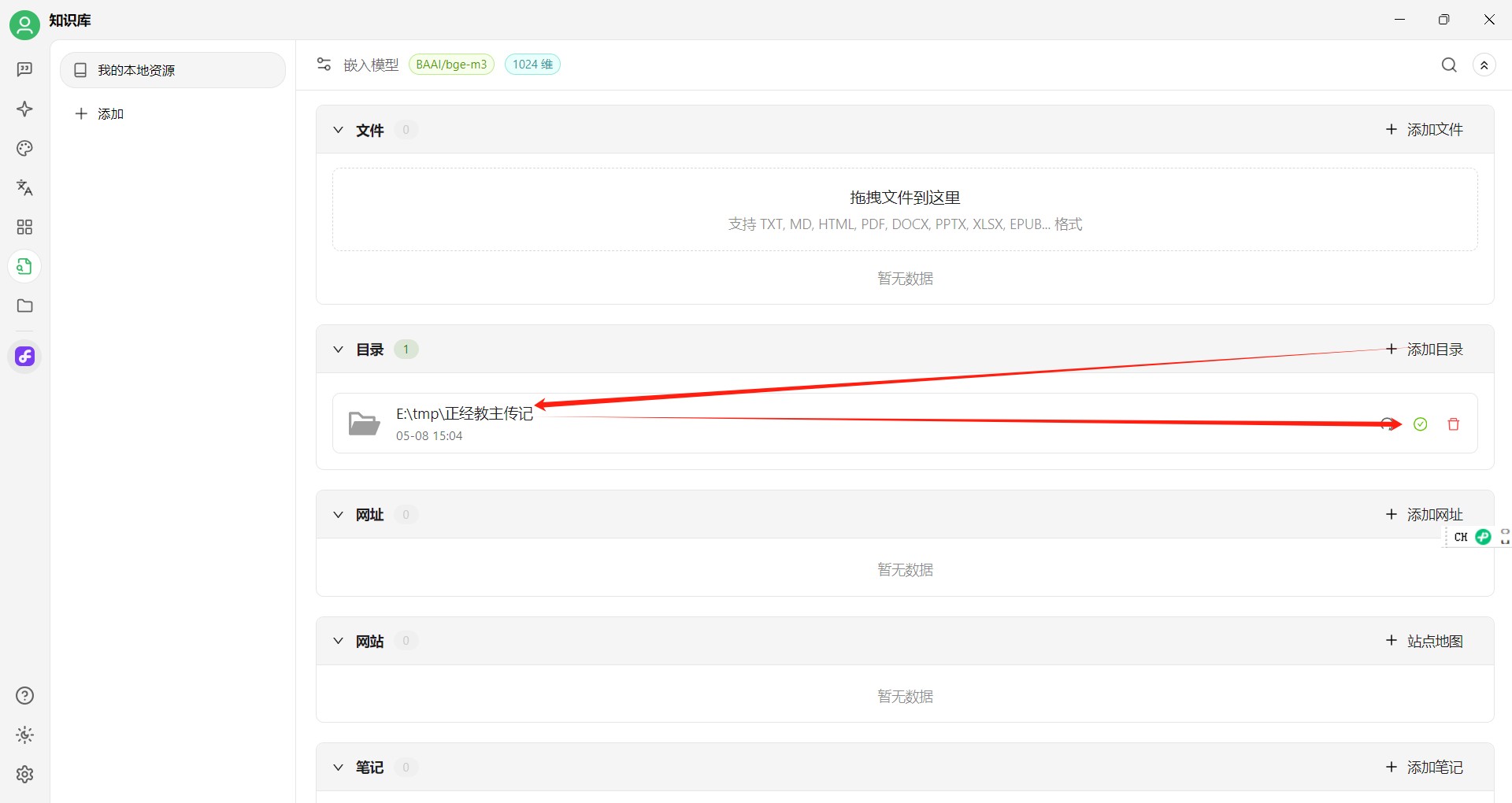
然后添加知识目录,把Obsidian的文件目录(后面介绍步骤),添加过来,等大模型解析完(图标变绿)就可以用了:
使用测试
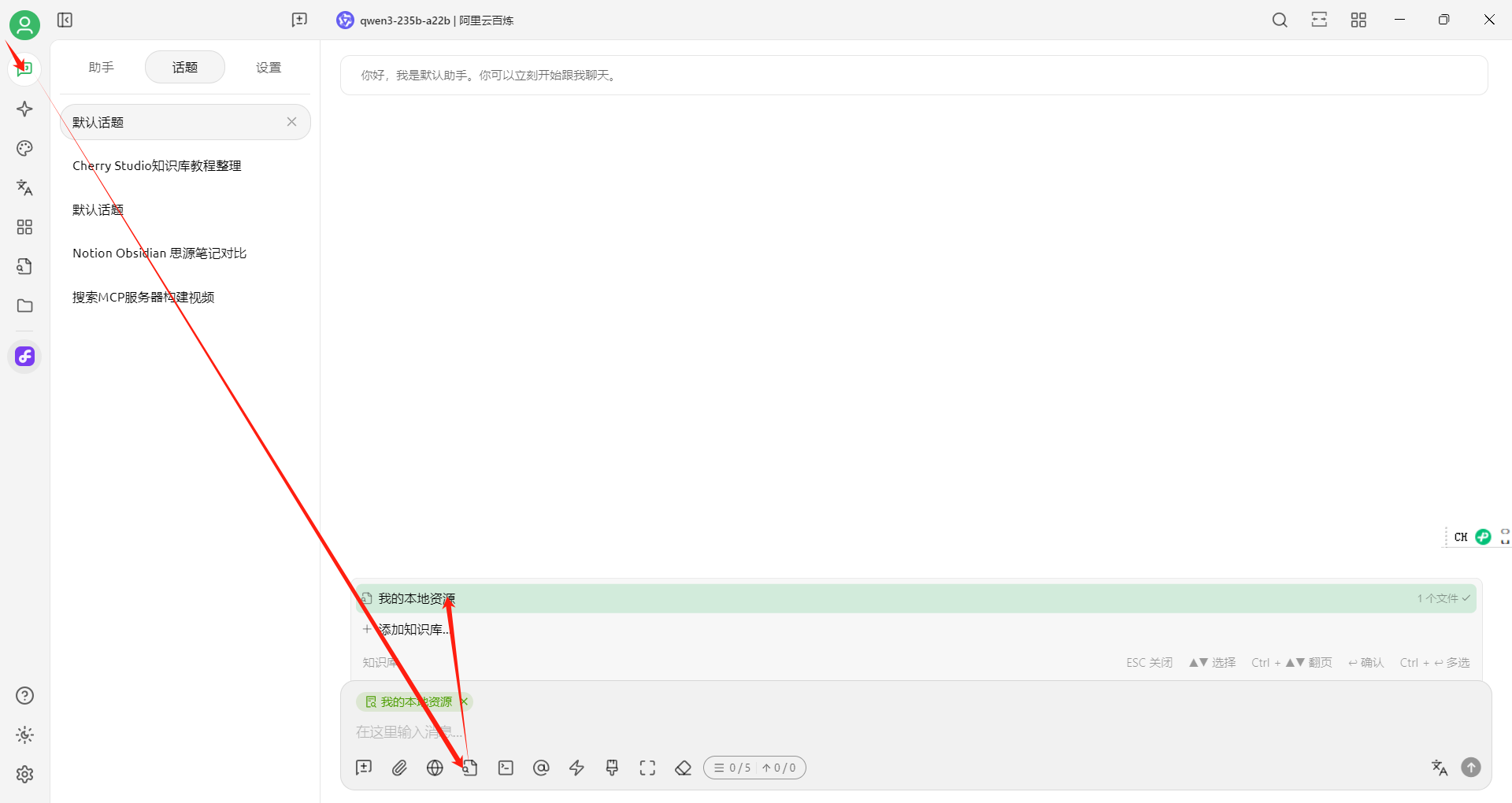
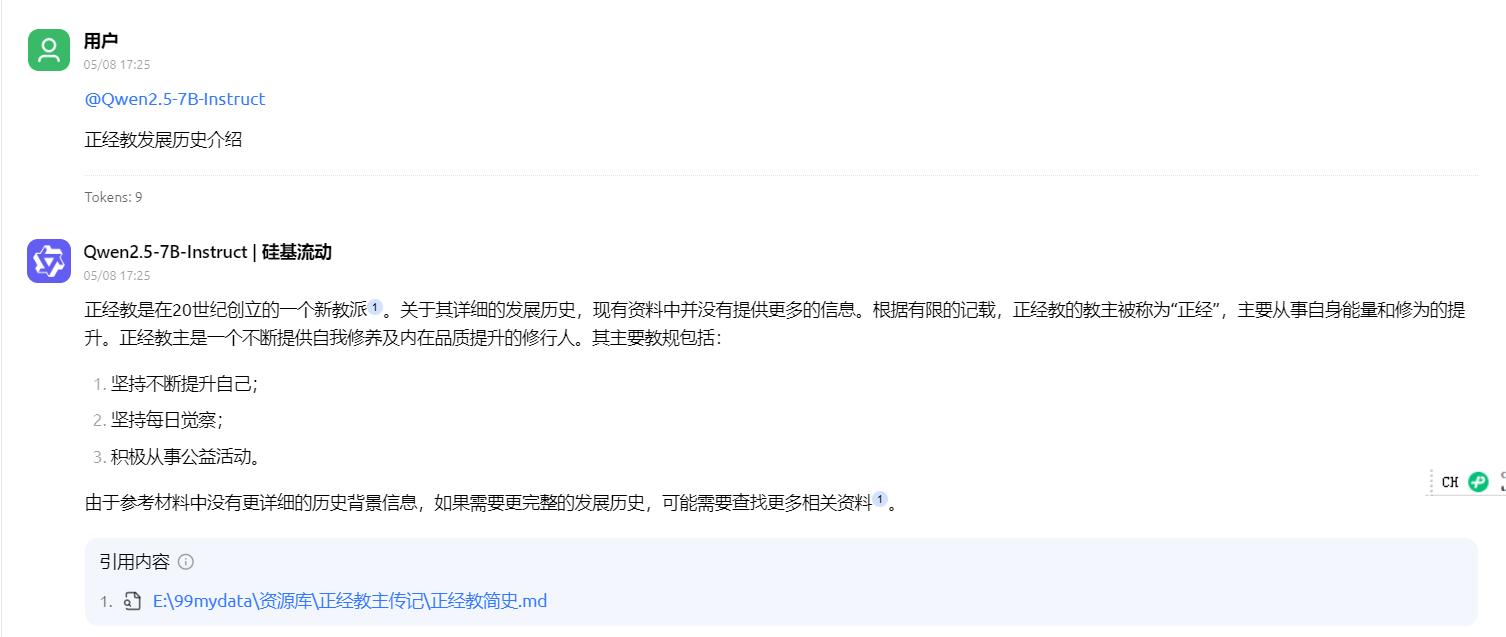
测试结果,很神奇,不同大模型对知识库的态度不一样:
大模型一:
qwen3,貌似完全没理知识库,看这回答就知道:
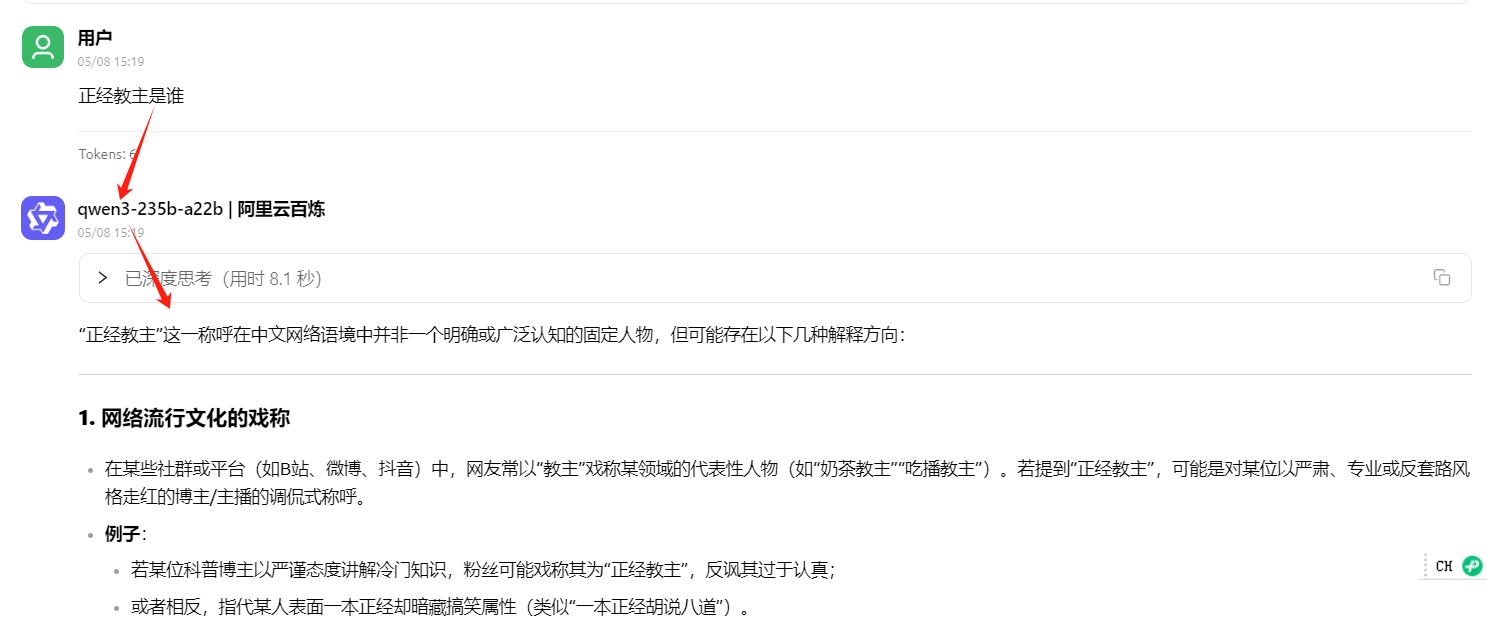
大模型二:
DeepSeek R1貌似也是:
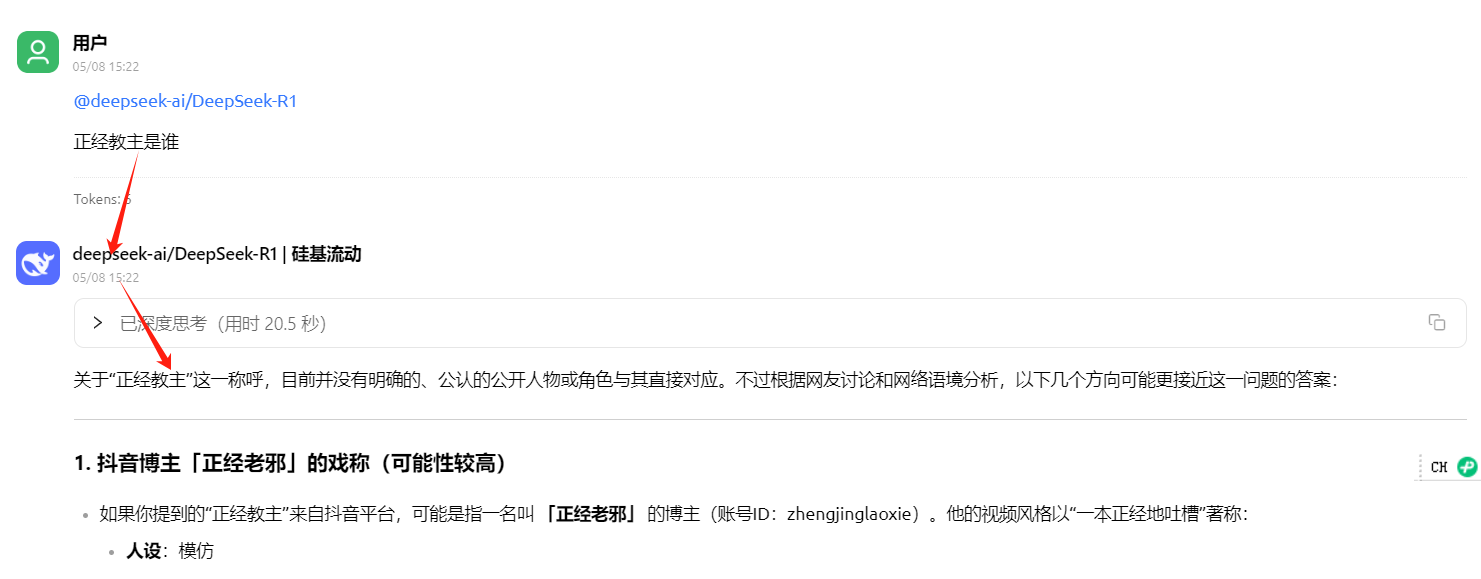
小模型 :ok
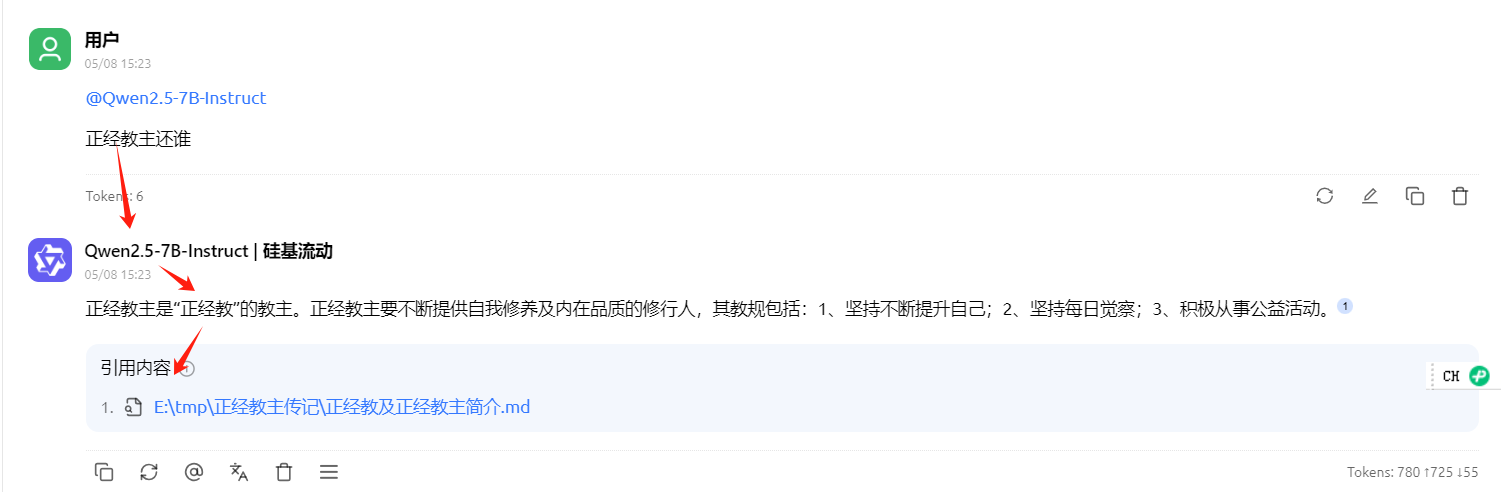
大模型三:ok
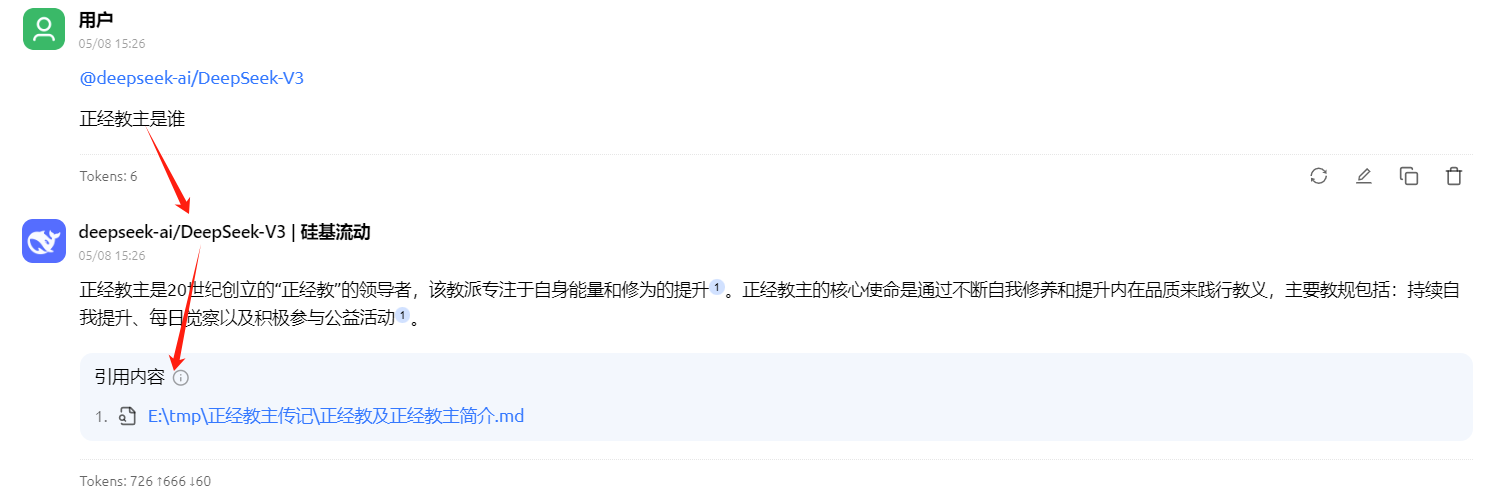
说实在的:没有发现其中的奥秘😕。
定制助手
根据上面测试的情况,不同模型对知识库支持情况不同,可以设置一个专门的助手,固定大模型和关联的知识库,用于进行本地知识的查询。具体设置如下。
创建一个助手:
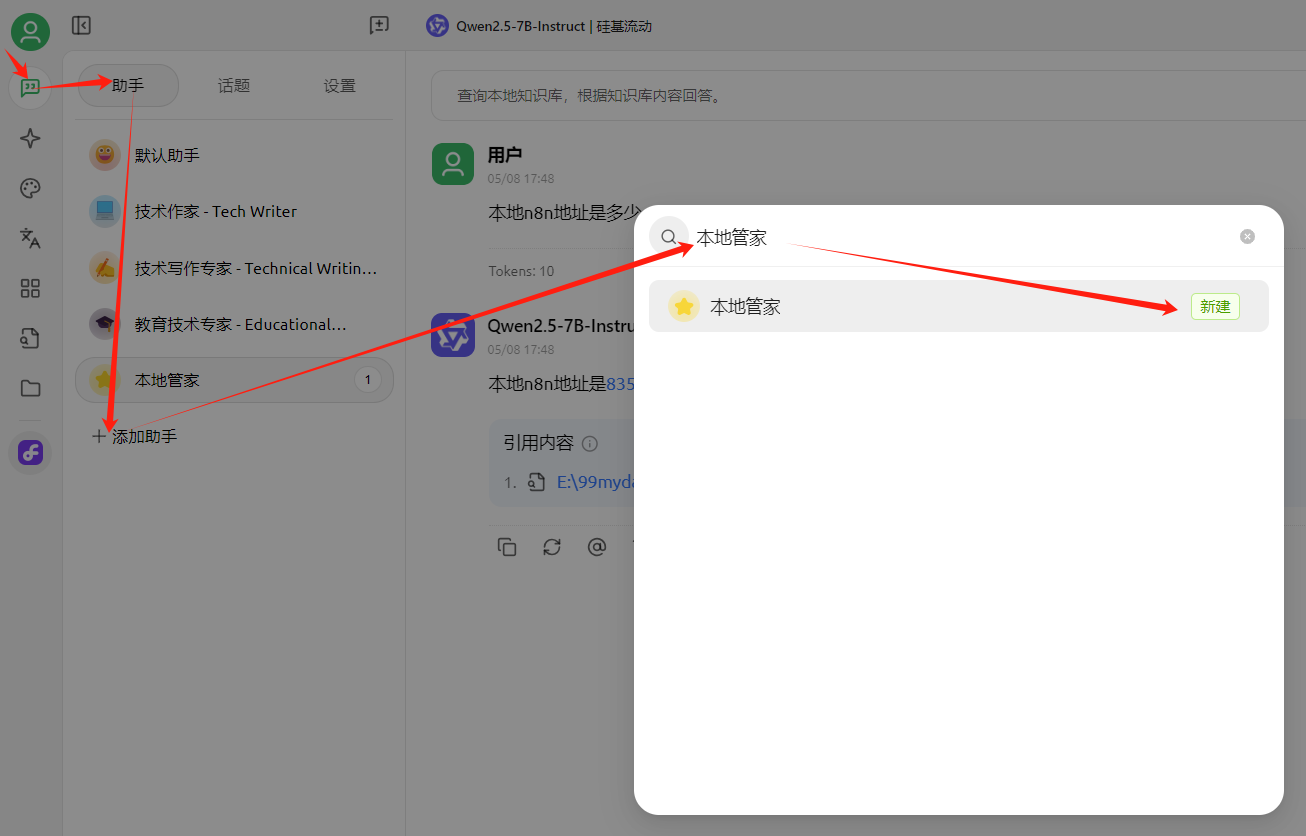
创建助手后,选择助手,进入其设置界面:
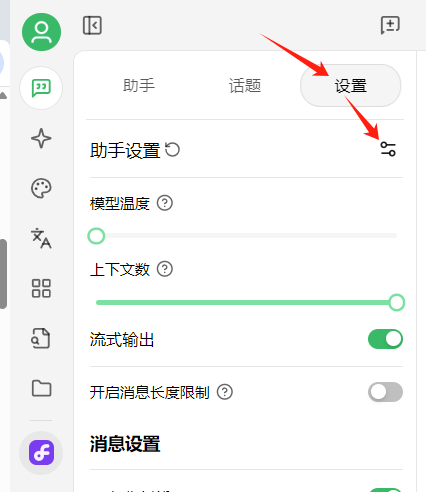
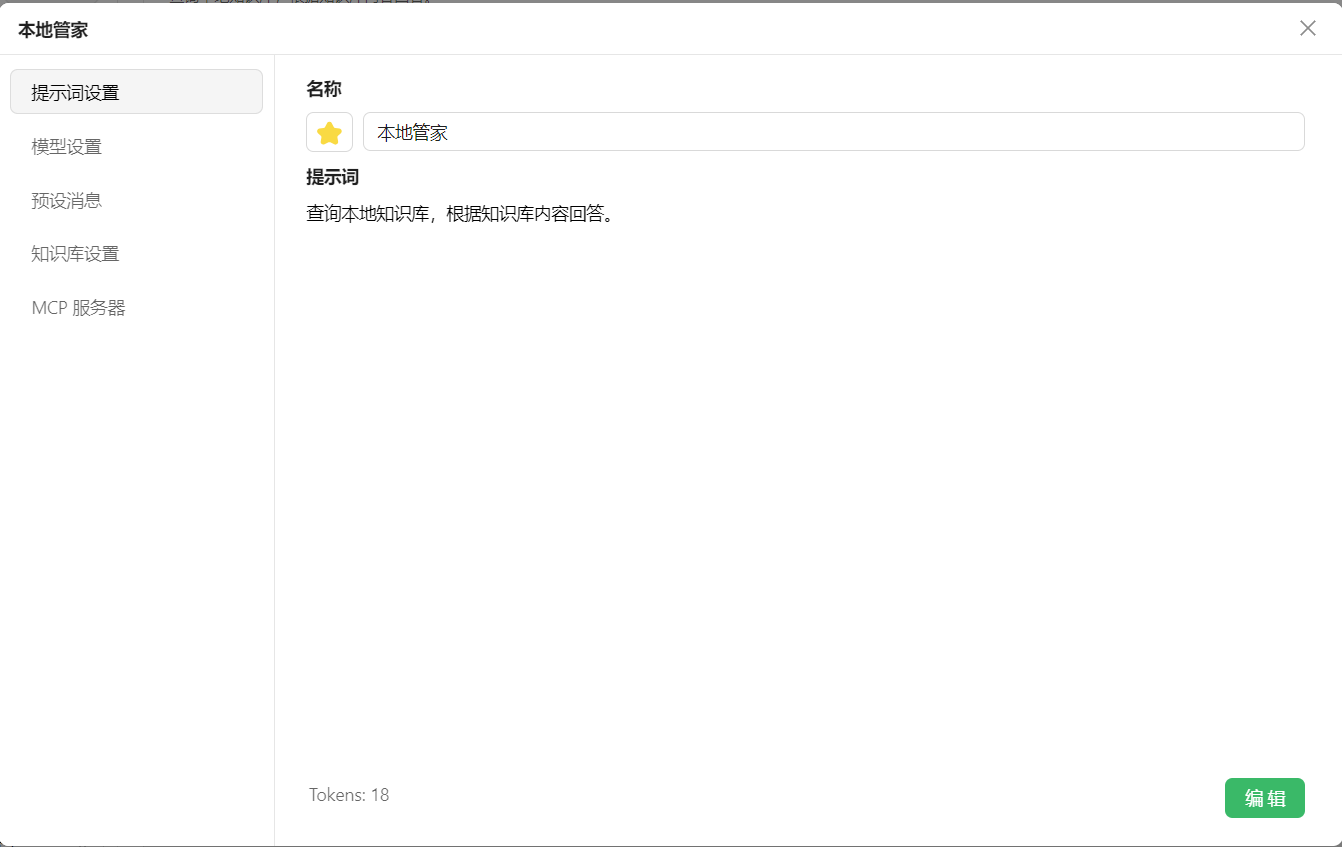
设置提示词,确保对知识库的搜索:
选择大模型,查找本地知识库,就不用庞大的模型了,模型温度调到最小,不需要大模型发挥想象力,推理能力,据实回答就好:
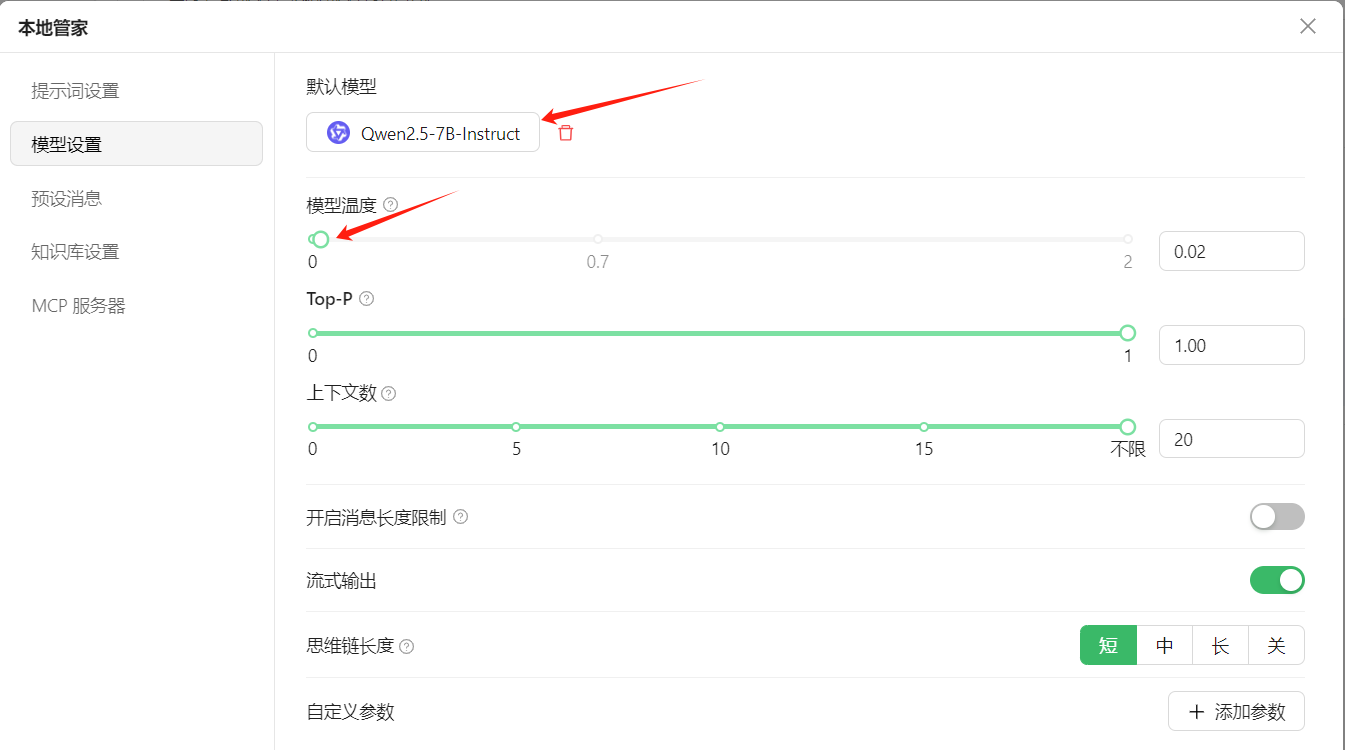
然后,绑定知识库,不用每次都选:
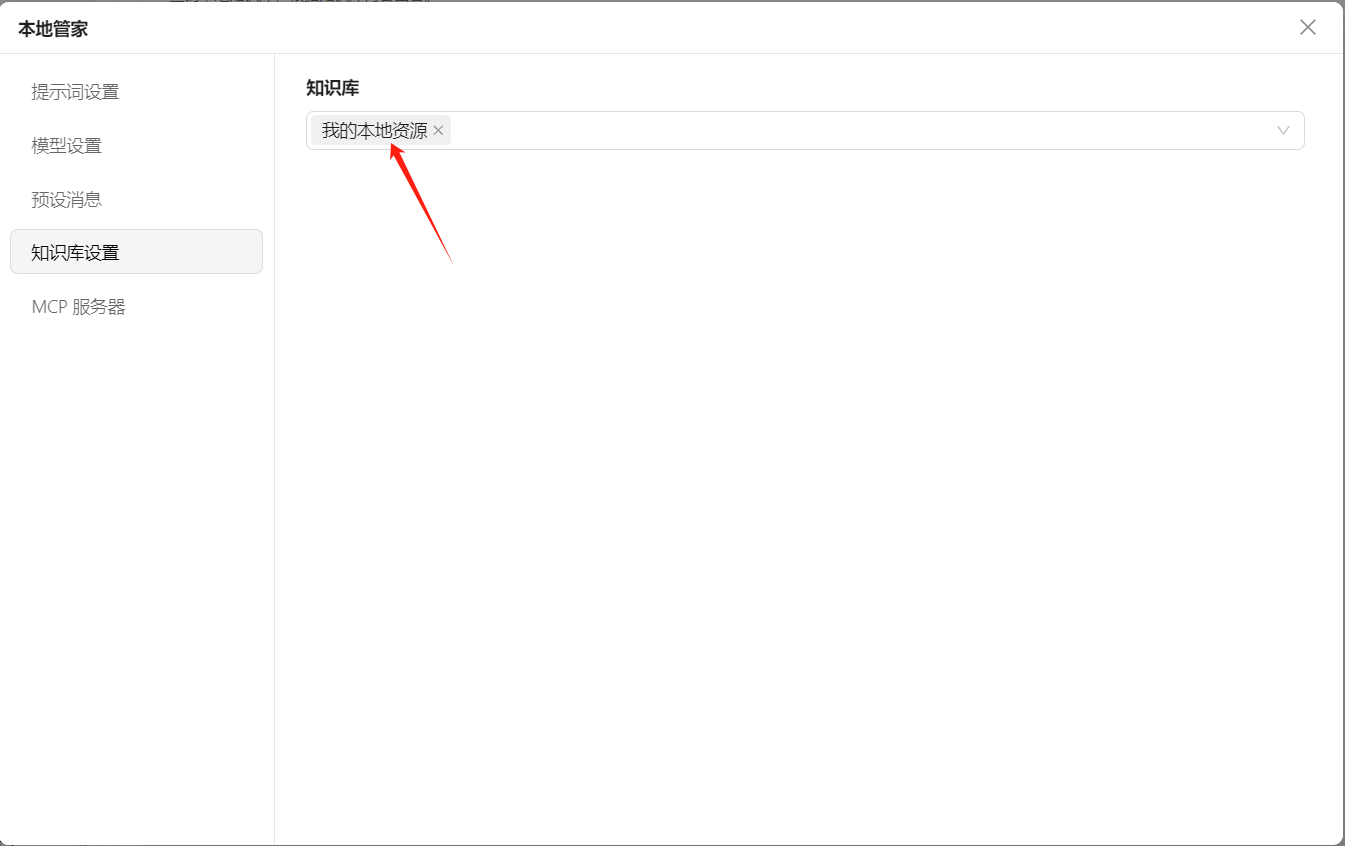
然后,就可以用这个助手来回到本地知识相关问题了。
Obsidian设置
安装
官网地址:https://obsidian.md/download

设置
安装过程简单,完成进入如下界面:
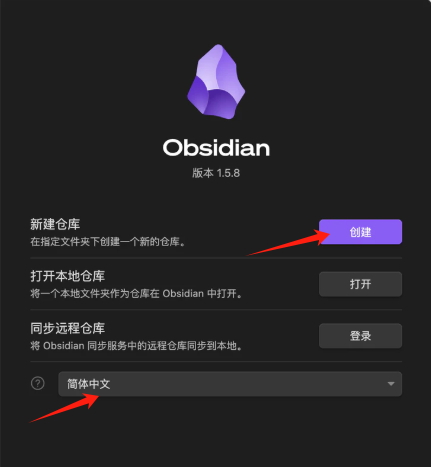
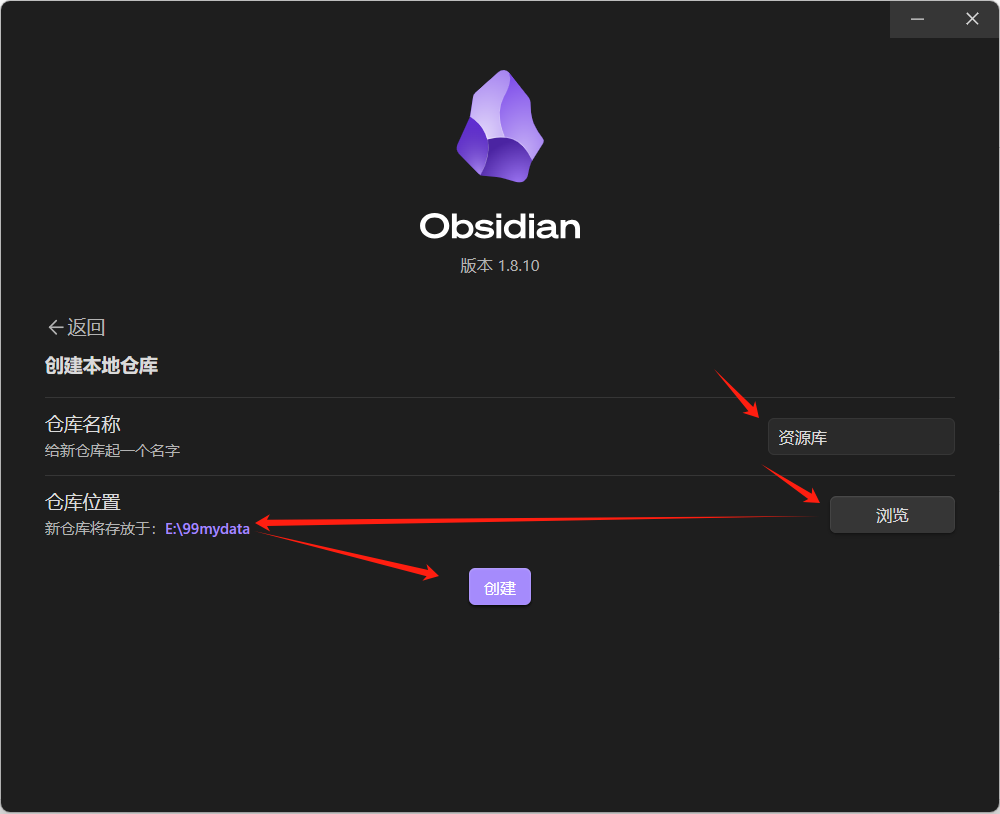
创建文件
创建文件夹和文件,后面测试用:
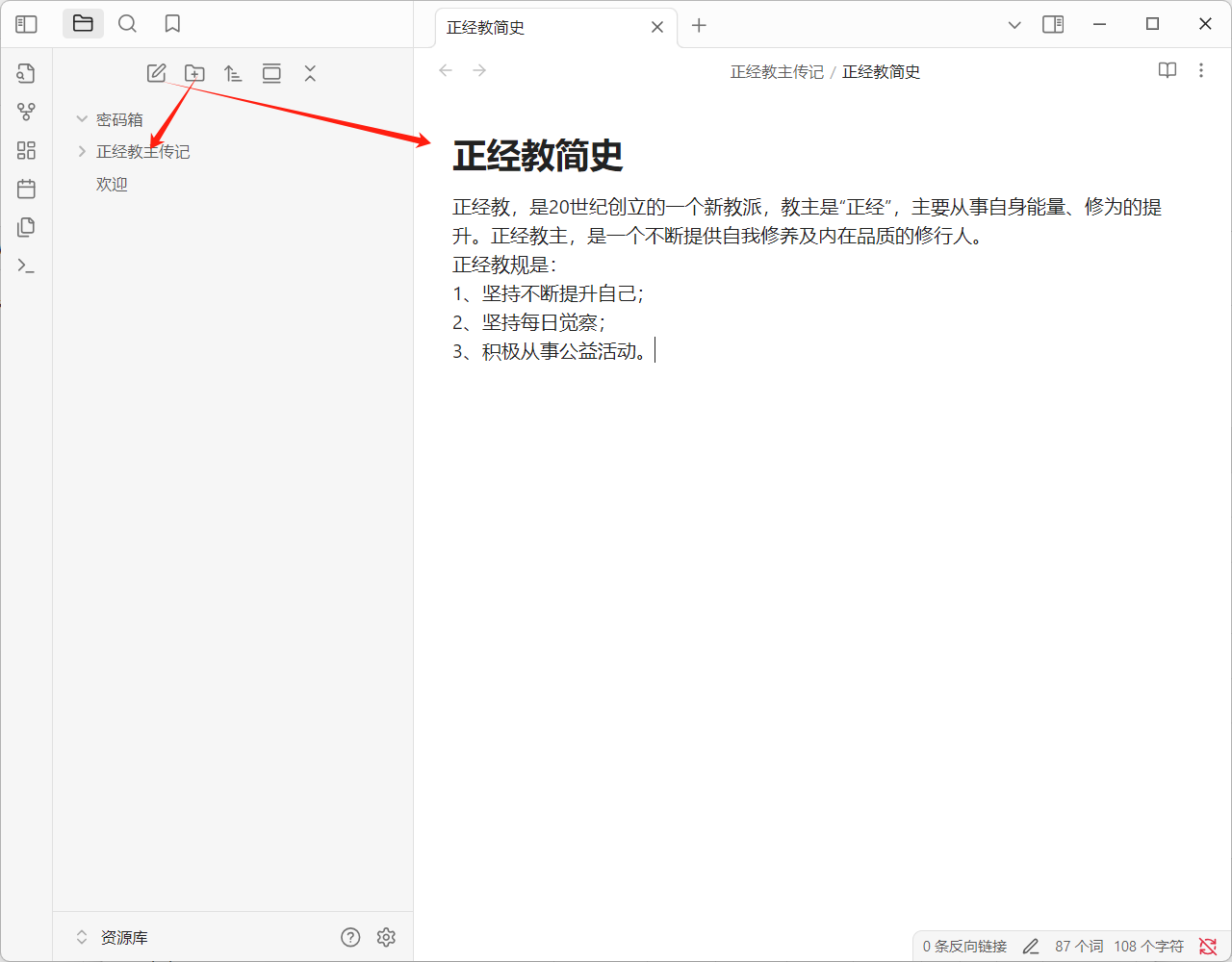
查看笔记的物理地址:
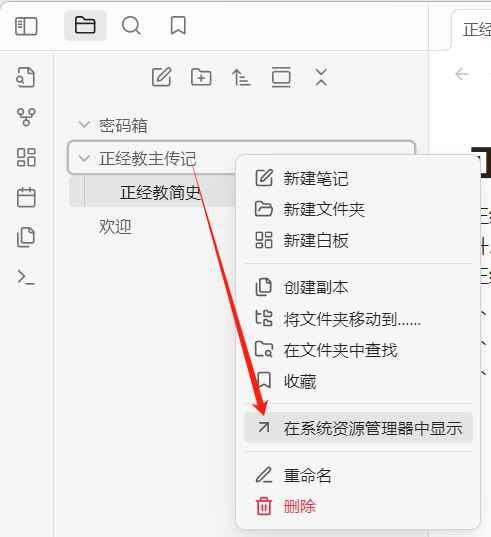
加入知识库
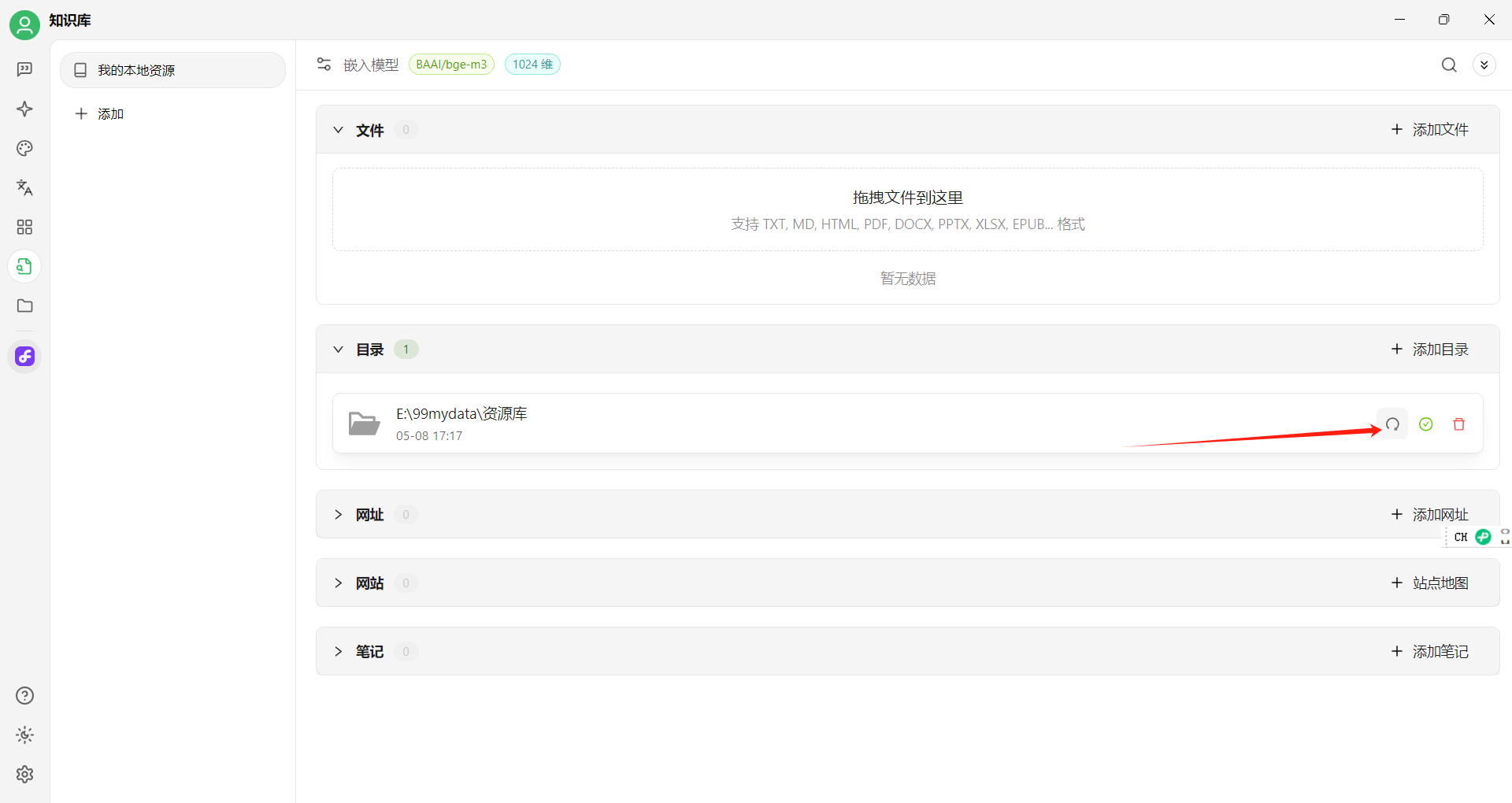
Obsidian的笔记都是以md文件存储在本地,笔记中的文件夹和物理磁盘上的文件夹是对应的,把Obsidian对应的物理目录添加到Cherry Studio的知识库文件夹中,如同即可:
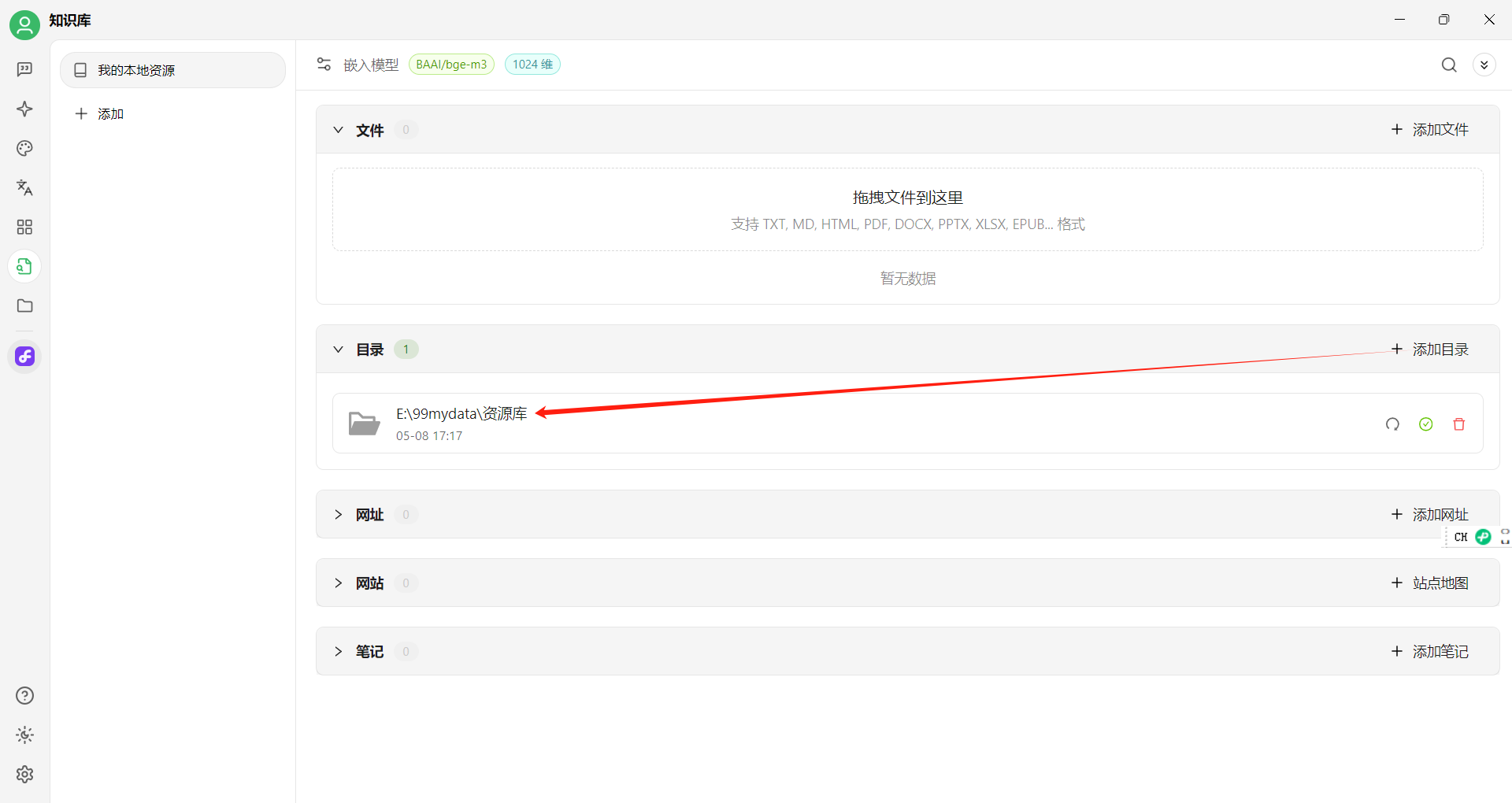
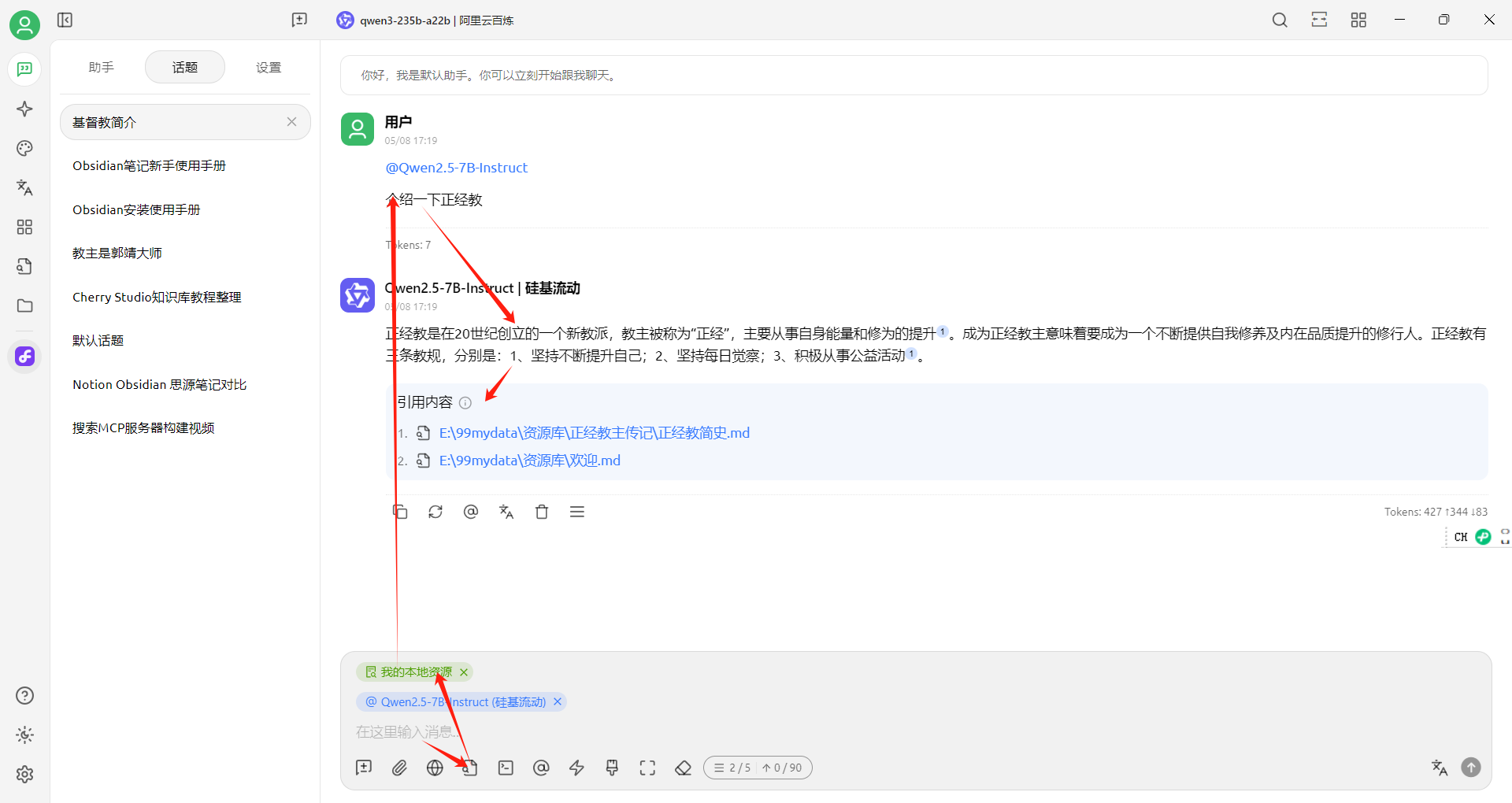
然后使用测试:
知识库刷新
如果Obsidian的笔记内容更改了,需要刷新知识库才行,我的测试记录如下:
我这里增加了新内容:
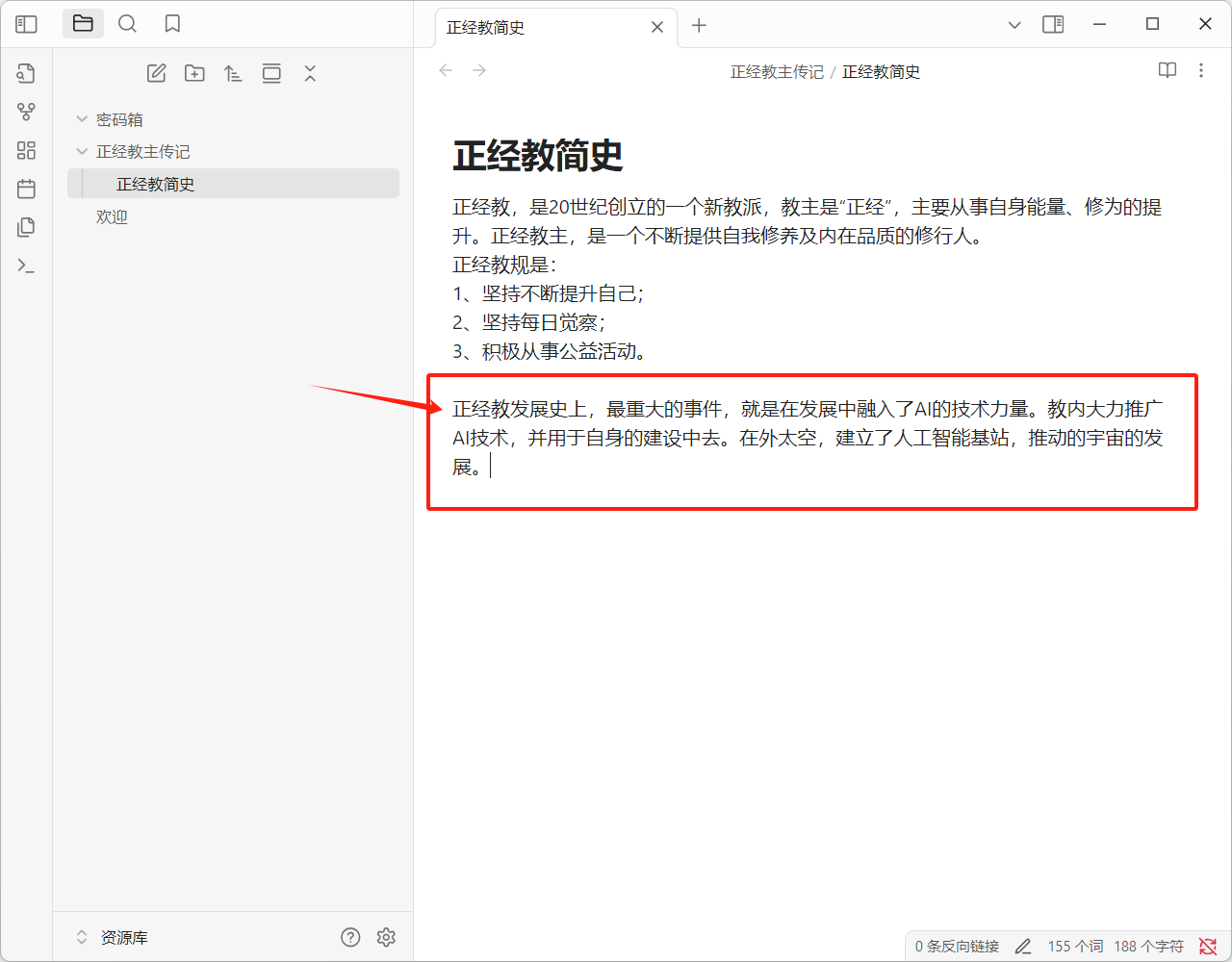
Cherrystudio是查询不到的:
需要刷新知识库:
然后,可以测试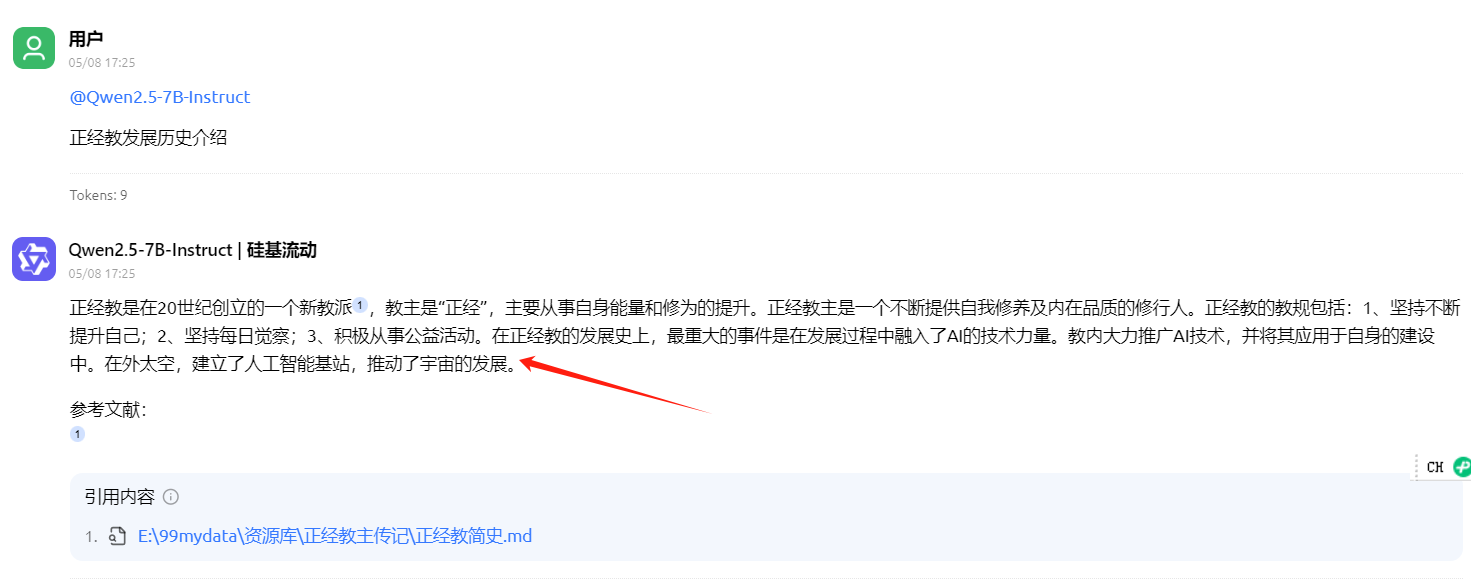
Obsidian学习资源推荐
Obsidian还有很多功能,可以参考下面文档学习。
- 官方文档:Obsidian 中文帮助
- 进阶教程:
结尾
Obsidian单就和CherryStudio的知识库进行直接衔接,这一点来说,还是很nice的,如果内容变更,不需要刷新就更棒了,以后总会有办法的吧,期待明天更美好😁😁😁


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











