







目录
7.2.4 Vector部分源码分析
jdk1.8.0_271中:
//属性
protected Object[] elementData;
protected int elementCount;
//构造器
public Vector() {
this(10); //指定初始容量initialCapacity为10
}
public Vector(int initialCapacity) {
this(initialCapacity, 0); //指定capacityIncrement增量为0
}
public Vector(int initialCapacity, int capacityIncrement) {
super();
//判断了形参初始容量initialCapacity的合法性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
//创建了一个Object[]类型的数组
this.elementData = new Object[initialCapacity];
//增量,默认是0,如果是0,后面就按照2倍增加,如果不是0,后面就按照你指定的增量进行增量
this.capacityIncrement = capacityIncrement;
}
//方法:add()相关方法
//synchronized意味着线程安全的
public synchronized boolean add(E e) {
modCount++;
//看是否需要扩容
ensureCapacityHelper(elementCount + 1);
//把新的元素存入[elementCount],存入后,elementCount元素的个数增1
elementData[elementCount++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity) {
//看是否超过了当前数组的容量
if (minCapacity - elementData.length > 0)
grow(minCapacity); //扩容
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length; //获取目前数组的长度
//如果capacityIncrement增量是0,新容量 = oldCapacity的2倍
//如果capacityIncrement增量是不是0,新容量 = oldCapacity + capacityIncrement增量;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
//如果按照上面计算的新容量还不够,就按照你指定的需要的最小容量来扩容minCapacity
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//如果新容量超过了最大数组限制,那么单独处理
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
//把旧数组中的数据复制到新数组中,新数组的长度为newCapacity
elementData = Arrays.copyOf(elementData, newCapacity);
}
//方法:remove()相关方法
public boolean remove(Object o) {
return removeElement(o);
}
public synchronized boolean removeElement(Object obj) {
modCount++;
//查找obj在当前Vector中的下标
int i = indexOf(obj);
//如果i>=0,说明存在,删除[i]位置的元素
if (i >= 0) {
removeElementAt(i);
return true;
}
return false;
}
//方法:indexOf()
public int indexOf(Object o) {
return indexOf(o, 0);
}
public synchronized int indexOf(Object o, int index) {
if (o == null) {//要查找的元素是null值
for (int i = index ; i < elementCount ; i++)
if (elementData[i]==null)//如果是null值,用==null判断
return i;
} else {//要查找的元素是非null值
for (int i = index ; i < elementCount ; i++)
if (o.equals(elementData[i]))//如果是非null值,用equals判断
return i;
}
return -1;
}
//方法:removeElementAt()
public synchronized void removeElementAt(int index) {
modCount++;
//判断下标的合法性
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
//j是要移动的元素的个数
int j = elementCount - index - 1;
//如果需要移动元素,就调用System.arraycopy进行移动
if (j > 0) {
//把index+1位置以及后面的元素往前移动
//index+1的位置的元素移动到index位置,依次类推
//一共移动j个
System.arraycopy(elementData, index + 1, elementData, index, j);
}
//元素的总个数减少
elementCount--;
//将elementData[elementCount]这个位置置空,用来添加新元素,位置的元素等着被GC回收
elementData[elementCount] = null; /* to let gc do its work */
}7.3 链表LinkedList
Java中有双链表的实现:LinkedList,它是List接口的实现类。
LinkedList是一个双向链表,如图所示:
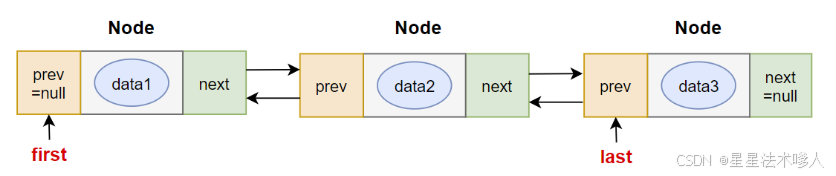
7.3.1 链表与动态数组的区别
动态数组底层的物理结构是数组,因此根据索引访问的效率非常高。但是非末尾位置的插入和删除效率不高,因为涉及到移动元素。另外添加操作时涉及到扩容问题,就会增加时空消耗。
链表底层的物理结构是链表,因此根据索引访问的效率不高,即查找元素慢。但是插入和删除不需要移动元素,只需要修改前后元素的指向关系即可,所以插入、删除元素快。而且链表的添加不会涉及到扩容问题。
7.3.2 LinkedList源码分析
jdk1.8.0_271中:
//属性
transient Node<E> first; //记录第一个结点的位置
transient Node<E> last; //记录当前链表的尾元素
transient int size = 0; //记录最后一个结点的位置
//构造器
public LinkedList() {
}
//方法:add()相关方法
public boolean add(E e) {
linkLast(e); //默认把新元素链接到链表尾部
return true;
}
void linkLast(E e) {
final Node<E> l = last; //用 l 记录原来的最后一个结点
//创建新结点
final Node<E> newNode = new Node<>(l, e, null);
//现在的新结点是最后一个结点了
last = newNode;
//如果l==null,说明原来的链表是空的
if (l == null)
//那么新结点同时也是第一个结点
first = newNode;
else
//否则把新结点链接到原来的最后一个结点的next中
l.next = newNode;
//元素个数增加
size++;
//修改次数增加
modCount++;
}
//其中,Node类定义如下
private static class Node<E> {
E item; //元素数据
Node<E> next; //下一个结点
Node<E> prev; //前一个结点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
//方法:获取get()相关方法
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
//方法:插入add()相关方法
public void add(int index, E element) {
checkPositionIndex(index);//检查index范围
if (index == size)//如果index==size,连接到当前链表的尾部
linkLast(element);
else
linkBefore(element, node(index));
}
Node<E> node(int index) {
// assert isElementIndex(index);
/*
index < (size >> 1)采用二分思想,先将index与长度size的一半比较,如果index<size/2,就只从位置0
往后遍历到位置index处,而如果index>size/2,就只从位置size往前遍历到位置index处。这样可以减少一部
分不必要的遍历。
*/
//如果index<size/2,就从前往后找目标结点
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {//否则从后往前找目标结点
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
//把新结点插入到[index]位置的结点succ前面
void linkBefore(E e, Node<E> succ) {//succ是[index]位置对应的结点
// assert succ != null;
final Node<E> pred = succ.prev; //[index]位置的前一个结点
//新结点的prev是原来[index]位置的前一个结点
//新结点的next是原来[index]位置的结点
final Node<E> newNode = new Node<>(pred, e, succ);
//[index]位置对应的结点的prev指向新结点
succ.prev = newNode;
//如果原来[index]位置对应的结点是第一个结点,那么现在新结点是第一个结点
if (pred == null)
first = newNode;
else
pred.next = newNode;//原来[index]位置的前一个结点的next指向新结点
size++;
modCount++;
}
//方法:remove()相关方法
public boolean remove(Object o) {
//分o是否为空两种情况
if (o == null) {
//找到o对应的结点x
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);//删除x结点
return true;
}
}
} else {
//找到o对应的结点x
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);//删除x结点
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {//x是要被删除的结点
// assert x != null;
final E element = x.item;//被删除结点的数据
final Node<E> next = x.next;//被删除结点的下一个结点
final Node<E> prev = x.prev;//被删除结点的上一个结点
//如果被删除结点的前面没有结点,说明被删除结点是第一个结点
if (prev == null) {
//那么被删除结点的下一个结点变为第一个结点
first = next;
} else {//被删除结点不是第一个结点
//被删除结点的上一个结点的next指向被删除结点的下一个结点
prev.next = next;
//断开被删除结点与上一个结点的链接
x.prev = null;//使得GC回收
}
//如果被删除结点的后面没有结点,说明被删除结点是最后一个结点
if (next == null) {
//那么被删除结点的上一个结点变为最后一个结点
last = prev;
} else {//被删除结点不是最后一个结点
//被删除结点的下一个结点的prev执行被删除结点的上一个结点
next.prev = prev;
//断开被删除结点与下一个结点的连接
x.next = null;//使得GC回收
}
//把被删除结点的数据也置空,使得GC回收
x.item = null;
//元素个数减少
size--;
//修改次数增加
modCount++;
//返回被删除结点的数据
return element;
}
public E remove(int index) { //index是要删除元素的索引位置
checkElementIndex(index);
return unlink(node(index));
}启示与开发建议
1、Vector基本不使用了
2、ArrayList底层使用数组结构:查找和添加(尾部添加)操作效率高,时间复杂度为O(1)。
删除和插入操作效率低,时间复杂度 为O(n)。
LinkedList底层使用双向链表结构:删除和插入操作效率高,时间复杂度为O(1)。
查找和添加(尾部添加)操作效率高,时间复杂度为O(n)(有可能添加操作是O(1))
3、在选择了ArrayList的前提下:new ArrayList():底层创建长度为10的数组。
如果开发中,大体确认数组的长度,则推荐使用ArrayList(int capacity)这个构造器,避免底层的扩容、复制数组的操作。















 449
449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









