







笔者最近使用了PaddleX工具中的文字识别,也就是通用OCR,参考的教程都已不是最新版本,走了很多弯路,故整理了一份完整的教程。
注意:本方案基于PaddlePaddle3.0.0rc0,PaddleX3.0.0rc0,cuda11.8,python3.8.10实现
一、背景介绍
文字识别需要使用到PaddleX中的PaddleOCR工具,该工具的作用是识别图片中的文本。更具体地说,该工具由文本检测模型和文本识别模型组成,前者负责寻找图片中的文本框,后者负责识别文本框的内容,二者有一个效果较差就会使得最终结果较差。识别效果请参考官方文档PaddleOCR 文档。
二、制作数据集
1.制作文本检测数据集
由于模型分为文本检测模型和文本识别模型,故我们要训练自己的模型,需要准备两种数据集,这里参考官方给出的示例数据集。

图2-1 文本检测数据集的文件
下载链接:https://paddle-model-ecology.bj.bcebos.com/paddlex/data/ocr_det_dataset_examples.tar
(1)images文件夹包括所有检测数据集
(2)train.txt是训练集的标签
单个标签格式:图片image1的路径 image1的所有文本框 所有文本框的逆时针四个点的x、y坐标。
如果使用repr函数查看,jpg后面是\t,最后一个符号]接了一个\n,其余分割均为空格,jpg后面是一个列表,每个列表是一个字典,字典的transcription的值对应文本内容,points的值是一个列表,这个列表包含四个值,是文本框逆时针顺序的x、y坐标值。
如果你需要制作自己数据集标签,可以参考这个代码。
s1是图片名字,s2是文本框文本内容,s3是文本框坐标列表。
f'{s1}\t[{{"transcription": "{s2}", "points": {s3}}}]\n'
图2-2 官方文本检测数据集的标签文件
(3)val.txt是验证集的标签,格式类似。
2.制作文本识别数据集

图2-3 官方文本识别数据集的文件
下载链接:https://paddle-model-ecology.bj.bcebos.com/paddlex/data/ocr_rec_dataset_examples.tar
(1)images文件夹包括所有文本检测数据集。
(2)dict.txt是字典,路径为paddleocr\ppocr\utils\dict中的一个字典,这个路径是安装虚拟环境后在iniconda3/envs/ocr/lib/python3.8/site-packages里面找。
(3)train.txt是训练集的标签
单个标签格式:图片image1的路径 image1的文本框内容
如果使用repr函数查看,jpg后面是\t,最后一个符号]接了一个\n
如果你需要制作自己数据集标签,可以参考这个代码
s1是图片名字,s2是文本框文本内容
f'{s1}\t{s2}\n'
图2-4 官方文本检测数据集的标签文件
三、搭建环境
笔者参考了安装PaddlePaddle - PaddleX 文档,选择了CUDA11.8环境
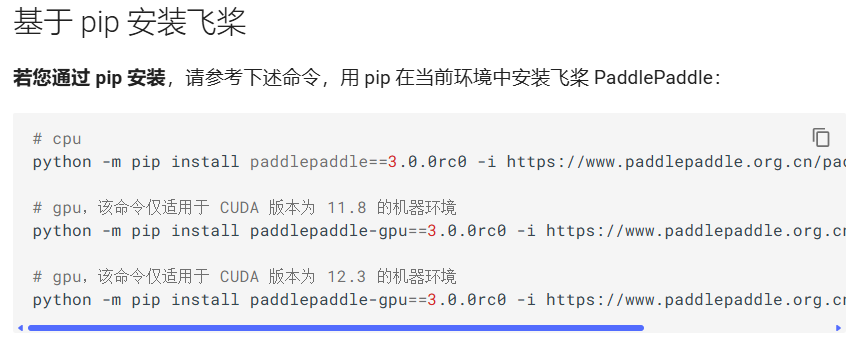
图3-1 官方文档版本参考
在AutoDL平台可以直接构造这个环境,你可以使用在终端中使用以下命令来查看CUDA版本
nvcc --version
图3-2 虚拟环境选择
然后依次输入以下命令
conda init # 输入后重启
conda create --name ocr python==3.8.10 #构造python3.8.10环境
conda activate ocr # 启动虚拟环境
python -m pip install paddlepaddle-gpu==3.0.0rc0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/ # 安装11.8cuda环境的paddlegpu环境
git clone https://github.com/PaddlePaddle/PaddleX.git # 下载git文件
cd PaddleX # 进入下载的文件
pip install -e . # 可编译方式下载PaddleX
paddlex --install PaddleOCR # 利用PaddleX下载PaddleOCR以下是几个可能遇到的问题
1.OSError: cannot load library 'libsndfile.so': libsndfile.so: cannot open shared object file: No such file or directory
省流:
运行以下命令
sudo apt-get update
apt install libsndfile12.ImportError: cannot import name 'preserve_channel_dim' from 'albucore.utils' (/root/miniconda3/envs/ocr/lib/python3.8/site-packages/albucore/utils.py)
参考链接:
cannot import name 'preserve_channel_dim' from 'albucore.utils' · Issue #182 · ostris/ai-toolkit
省流:
运行以下命令
pip install albucore==0.0.16四、训练模型
注意:请自己注意路径,笔者不在路径进行赘述
1、训练文本检测模型
在以下路径PaddleX/paddlex/configs/modules/text_detection随机选取一个yaml文件作为配置文件,笔者选择的是PP-OCRv4_mobile_det.yaml
图4-1 文本检测模型配置文件
标红位置说明:以下(1)代表从上往下第一个红框,(2)代表从上往下第二个红框,以此类推。
(1)数据集位置
(2)gpu:0,1,2,3 改为 gpu:0
(3)(5)(7)分别为模型训练输出路径、评估输出路径、预测数据路径,注意三个都有子字符out,如果你修改了,要全部修改
(4)(6)官方给出的预训练模型链接,建议复制链接在自己电脑上下载,然后上传。
权重路径参考替换"pretrained_model/PP-OCRv4_mobile_det_pretrained.pdparams"
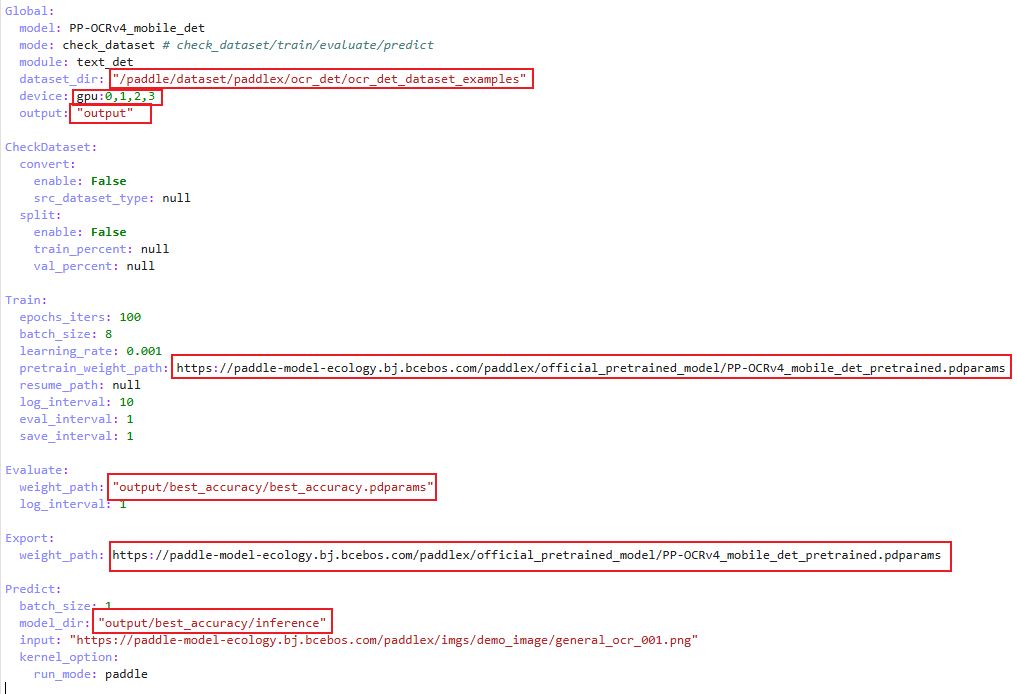 图4-2 文本检测模型配置文件修改
图4-2 文本检测模型配置文件修改
上传按钮在这里
图4-3 上传按钮
除了这个预训练模型文件,还需要上传你自己的文本检测数据集,一定一定注意标签的格式,自己参考上面的。
做完以上工作,在挨个运行以下命令
第一个命令是检查数据集,如果成功会出现一行绿字提示你通过检测,如果失败,请你仔细检查格式。
第二个命令是训练模型,如果提示“超过最大递归深度”的错误,可能是你把“文本识别”数据集当成“文本检测”数据集了,替换一下再试试。训练会产生日志文件,想打印日志中的一些参数,可以考虑用正则表达式和字典键值对的方法。
第三个命令是评估模型,会评估模型。
python main.py -c paddlex/configs/modules/text_detection/PP-OCRv4_mobile_det.yaml -o Global.mode=check_dataset
python main.py -c paddlex/configs/modules/text_detection/PP-OCRv4_mobile_det.yaml -o Global.mode=train
python main.py -c paddlex/configs/modules/text_detection/PP-OCRv4_mobile_det.yaml -o Global.mode=evaluate其实还有个命令,是预测命令,根据你的输入图片输出一些结果,但笔者没尝试。
python main.py -c paddlex/configs/modules/text_detection/PP-OCRv4_mobile_det.yaml -o Global.mode=predict -o Predict.input="image11.jpg"2、训练文本识别模型
在以下路径PaddleX/paddlex/configs/modules/text_recognition随机选取一个yaml文件作为配置文件,笔者由于数据集是日语,选择的是japan_PP-OCRv3_mobile_rec.yaml
修改文件的方法类似,请自己解决。
(4)(6)参考替换:"pretrained_model/japan_PP-OCRv3_mobile_rec_pretrained.pdparams"
这里给出运行命令
python main.py -c paddlex/configs/modules/text_recognition/japan_PP-OCRv3_mobile_rec.yaml -o Global.mode=check_dataset
python main.py -c paddlex/configs/modules/text_recognition/japan_PP-OCRv3_mobile_rec.yaml -o Global.mode=train
python main.py -c paddlex/configs/modules/text_recognition/japan_PP-OCRv3_mobile_rec.yaml -o Global.mode=evaluate 到了这一步,你应该有了两个模型了,接下来就是去替换模型了。
五、通用OCR场景识别
在终端输入以下命令:
paddlex --get_pipeline_config OCR --save_path ./my_path你会在在PaddleX中创建一个my_path文件夹,里面有OCR.yaml文件
修改OCR.yaml文件
(1)文本检测模型名称
(2)文本检测模型路径
(3)文本识别模型名称
(4)文本检测模型路径
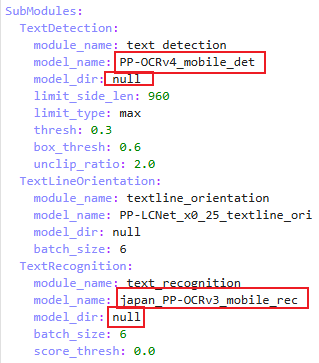
图5-1 OCR产线配置文件
关于两个模型的路径,里面的文件应该是这样的
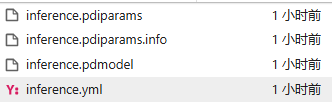
图5-2 训练模型格式参考
关于模型名称,如果不是正确的名称,会报错,你可以在paddlex\inference\models的__init__文件这个函数添加以下代码,来查看具体哪些是正确的名称。
print(official_models)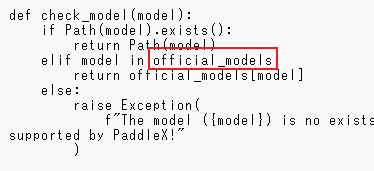
图5-3 查看合法模型名称
在PaddleX文件夹里面,创建一个test.py文件,参考代码:
注意替换pipeline的文件和input就可以了
这样你就利用了自己训练的模型完成了任务。
from paddlex import create_pipeline
pipeline = create_pipeline(pipeline="my_path/OCR.yaml")
output = pipeline.predict(
input="japan_1.jpg",
use_doc_orientation_classify=False,
use_doc_unwarping=False,
use_textline_orientation=False,
)
for res in output:
res.print()
res.save_to_img(save_path="./output/")
res.save_to_json(save_path="./output/")六、总结
整个操作,比较难的是虚拟环境搭建、数据集标签制作、路径问题,其他的都比较简单。如果存在错误,欢迎纠正。如果需要帮助,可以私信哟。

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









