






一、前言
用户购物偏好模型BP(Buyer Preferences Model)旨在通过对用户购物行为的深入分析和建模,以量化用户对不同商品或服务的偏好程度。该模型对于电商平台、零售商以及其他涉及消费者决策的商业实体来说,具有重要的应用价值。
二、推荐系统
概述
推荐系统是一种利用电子商务网站、社交媒体平台等向用户提供个性化商品、内容或服务建议的系统。它通过分析用户的行为、兴趣、历史记录等信息,帮助用户快速找到符合其需求的物品,提高用户体验和满意度。
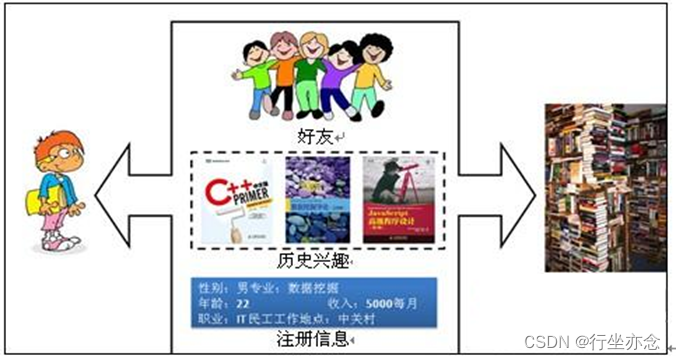
推荐引擎,作为网站不可或缺的后台智能核心,高度依赖用户行为日志。这些日志不仅是用户兴趣与偏好的宝贵记录,更是网站实现个性化服务的关键数据。通过深度分析用户的行为日志,推荐引擎能够精确捕捉每个用户的独特需求,并据此为用户呈现定制化的页面和信息。这种个性化的服务不仅极大地提升了用户的浏览体验,还显著提高了网站的点击率和转化率。

推荐系统原理
数据采集:收集用户的喜好、搜索历史、点击历史、服务偏好等数据,构建用户行为模型。
数据分析:对用户数据进行处理,分析用户之间的关系,建立用户属性档案和潜在需求模型。
内容过滤:从已收集的数据中抽取出与用户行为相关的部分,进行深度分析和统计,计算特征值,滤除不符合用户兴趣的内容。
推荐内容:根据内容过滤结果和相关参数,进行智能化筛选,推荐出最匹配用户兴趣的内容。
分类
推荐系统组成
推荐系统一般都由三个部分组成,前端的交互界面、日志系统以及推荐算法系统。
1.前端的交互界面
- 交互界面是用户与推荐系统直接交互的窗口。
- 它负责展示推荐系统生成的推荐结果,如商品列表、视频推荐、文章推荐等。
- 交互界面还需要收集用户的反馈,如点击、浏览、购买、评分等行为,以便后续对推荐算法进行优化。
2.日志系统
- 日志系统负责记录用户的行为数据,包括用户在网站或应用上的所有活动,如搜索、点击、购买、评价等。
- 这些日志数据是推荐系统的基础,它们提供了关于用户兴趣和偏好的宝贵信息。
- 日志系统还需要对原始数据进行清洗、整合和存储,以便后续的数据分析和推荐算法使用。
3.推荐算法系统
- 推荐算法系统是推荐系统的核心,它负责根据用户的行为数据和其他相关信息,生成个性化的推荐结果。
- 推荐算法可以采用多种技术,如基于内容的推荐、协同过滤推荐、深度学习推荐等。
- 推荐算法系统需要不断地优化和调整,以适应用户兴趣的变化和市场的动态。
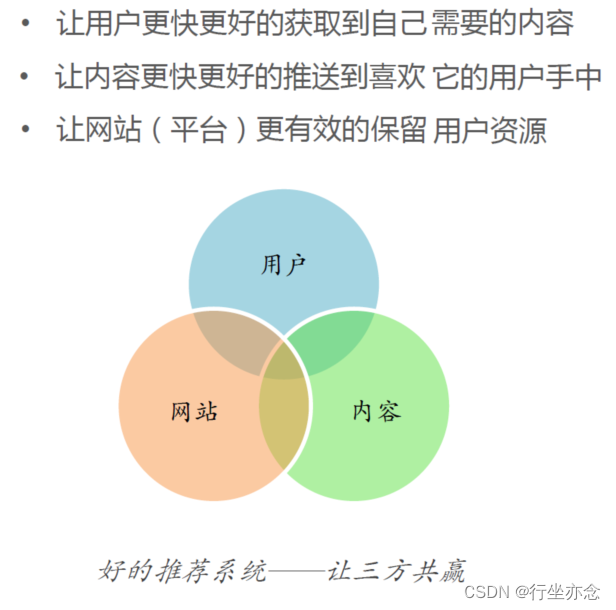
个性化推荐成功的两大关键条件:
-
信息过载:用户面临海量信息,难以快速找到符合自己喜好的物品。
-
需求不明确:用户没有明确的需求时,推荐系统能够预测潜在兴趣,主动推送相关内容。
一个完整的推荐系统一般存在3个参与方: 用户、内容提供方和提供推荐系统的网站。
一个出色的推荐系统不仅能够精准地预测用户的偏好和行为,更能够拓宽用户的视野,引领他们“发现”新奇而有趣的内容。
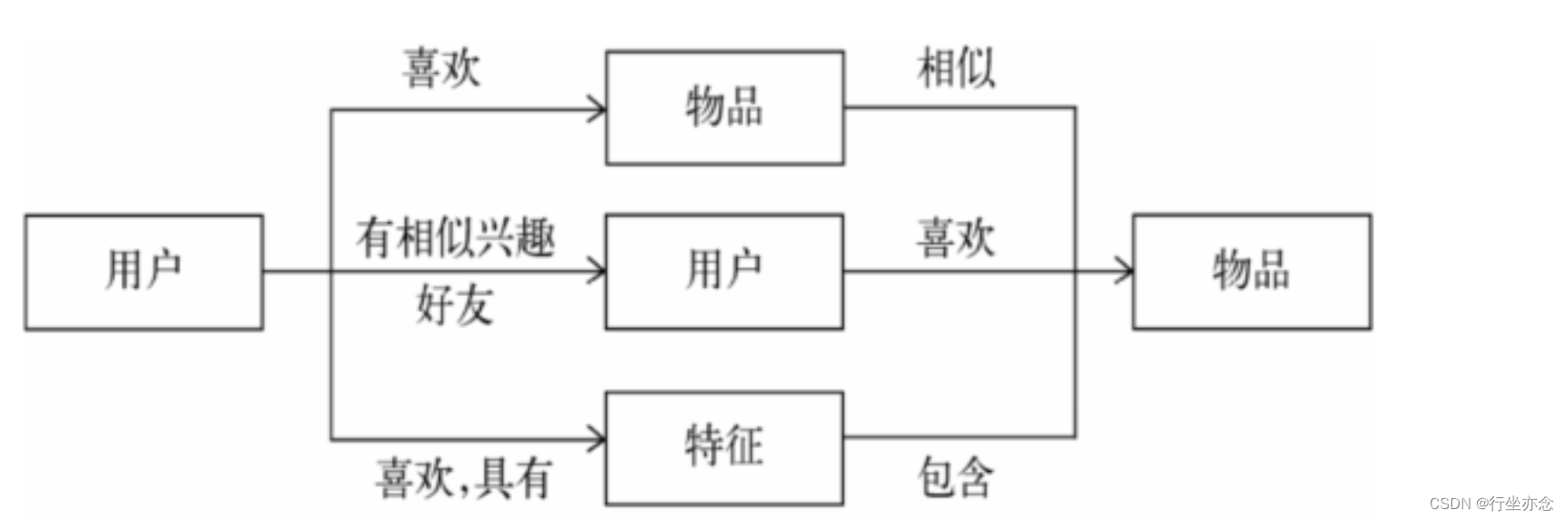
推荐系统基本思想
知你所想,精准推送:
利用用户和物品的特征信息,为用户推荐那些具有用户喜欢的特征的物品。这包括基于用户的历史行为、偏好标签、上下文信息(如浏览记录、购买记录等)来构建用户模型。
同时,对物品进行特征分析,如内容信息、分类标签、关键词等,以匹配用户兴趣。
物以类聚:
利用用户喜欢过的物品,给用户推荐与他喜欢过的物品相似的物品。这通常基于物品的相似性度量,如基于内容的相似性或基于协同过滤的相似性。
人以群分:
利用和用户相似的其他用户,给用户推荐那些和他们兴趣爱好相似的其他用户喜欢的物品。这主要基于社会化推荐或协同过滤推荐,通过分析用户之间的相似性来找到可能感兴趣的物品。
推荐系统数据分析
推荐系统主要由用户数据、物品数据及用户对物品行为数据(评分数据、点击数据、购物数据等)构成
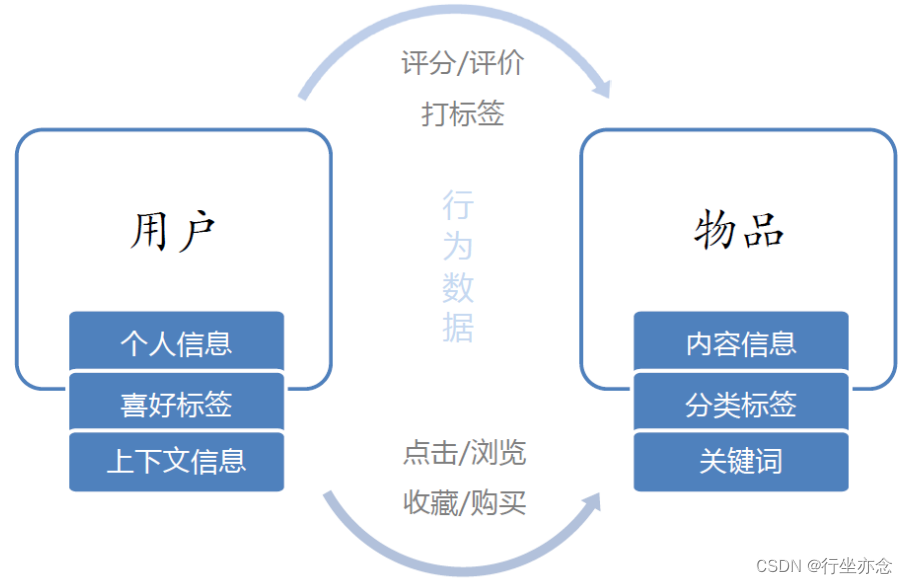
具体如下:
第一:物品的元数据
关键字、分类标签和基因描述(对物品的详细特征的描述,比如钢琴有什么详细特征,音色等)
第二:用户数据
性别、年龄、兴趣标签(构建用户画像,能够通过这些基本信息实现更精准的推送)
第三:用户对物品行为数据(或者说对物品或信息的偏好)
显式反馈:用户主动提供的反馈信息,如评分和评论,它们直接表达了用户对物品的喜好程度。
隐式反馈:用户在使用网站或应用时产生的数据,如浏览记录、购买记录等,它们间接地反映了用户的兴趣。隐式反馈在推荐系统中起着至关重要的作用,因为它们可以被大量获取,并用于实时更新用户模型。
推荐系统分类
推荐系统可以根据其工作原理和算法特点进行分类,主要包括以下几种:
基于内容的推荐:系统为用户推荐与他们过去的兴趣类似的物品,物品间的相似性基于被比较的特征来计算。
协同过滤:找到与用户有相同品味的用户,然后将相似的用户过去喜欢的物品推荐给用户。这种方法是推荐系统中最流行和最广泛实现的技术。
基于人口统计学的推荐:根据用户的人口统计信息(如语言、国籍、年龄等)进行推荐。
基于知识的推荐:根据特定领域的知识推荐物品,这些知识是关于如何确定物品能满足用户需要和偏好的。
基于社区的推荐:依赖用户朋友的偏好进行推荐,通常称为社会化推荐系统。
混合推荐系统:综合以上多种技术的推荐系统,以弥补单一技术的不足。
应用:
亚马逊的个性化推荐系统:通过分析用户的购物历史、搜索记录、点击行为等大数据,利用协同过滤算法和机器学习技术,为用户推荐个性化的商品。
爱奇艺的视频推荐系统:基于用户的观看历史、评分、点赞等数据,利用深度学习和数据挖掘技术,为用推荐系统,又称智能推荐系统,是现代互联网服务中不可或缺的一部分。它利用信息技术、大数据和人工智能等先进技术,在海量信息中为用户提供个性化的内容推荐,极大地提升了用户体验。以下是对推荐系统的详细介绍:
三、标签模型开发
评分数据
在这里我们使用用户对每个物品的点击次数来作为评分的标准:

想要获取点击次数,首先我们得获取物品的编号,也就是ItemId, 而这个编号我们从url中可以获得:
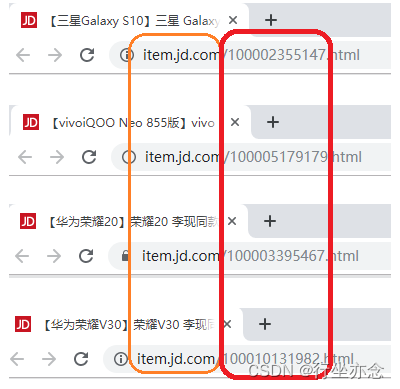
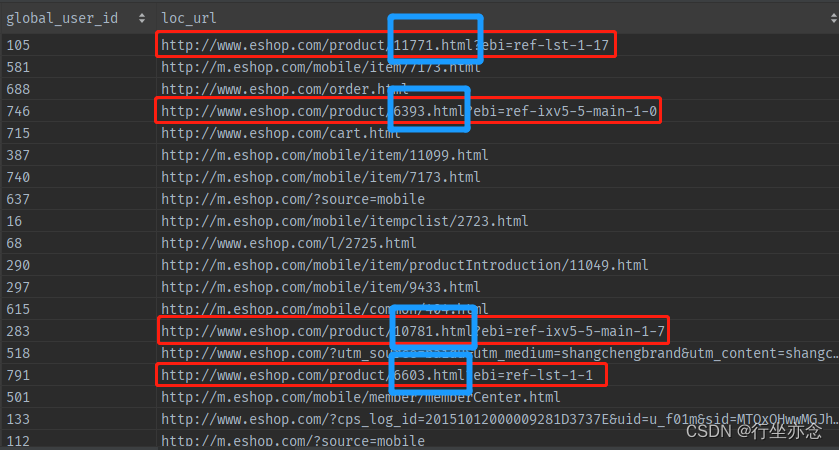
对于这些url我们使用正则匹配解析,具体代码如下:
import scala.util.matching.Regex
object RegexUrlTest {
def main(args: Array[String]): Unit = {
// 访问url
val locUrl = "http://www.eshop.com/product/10781.html?ebi=ref-i5-main-1-7"
// 正则表达式
val regex: Regex = "^.+\\/product\\/(\\d+)\\.html.+$".r
// 正则匹配
val optionMatch: Option[Regex.Match] = regex.findFirstMatchIn(locUrl)
// 获取匹配的值
val productId = optionMatch match {
case None => println("没有匹配成功"); null
case Some(matchValue) => matchValue.group(1)
}
println(s"productId = $productId")
}
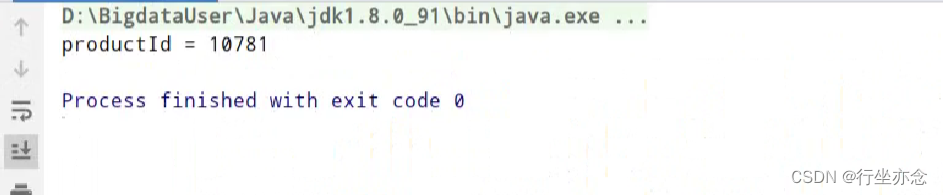
}运行程序输出结果:
新建标签
新建 业务(4级)标签品牌偏好标签 ,相关字段信息如下:
标签名称:用户购物偏好
标签分类:电商-某商城-行为属性
更新周期:1天
业务含义:用户购物偏好
(商品/品牌偏好)
标签规则!
inType=hbase
zkHosts=bigdata-cdh01.itcast.cn
zkPort=2181
hbaseTable=tbl_tag_logs
family=detai1
selectFieldNames=global_user_id,loc_url程序入口:
cn.itcast.tags.models.rmd.BpModel
算法名称:
ALS
算法引擎:
tags-model_2.11.jar
模型参数:
--driver-memory 512m --executor-memory 512m --num-executors 1 --
executor-cores 1
在标签管理平台创建【用户推荐】3级标签及【用户购物偏好】4级标签,用于方便管理模型:
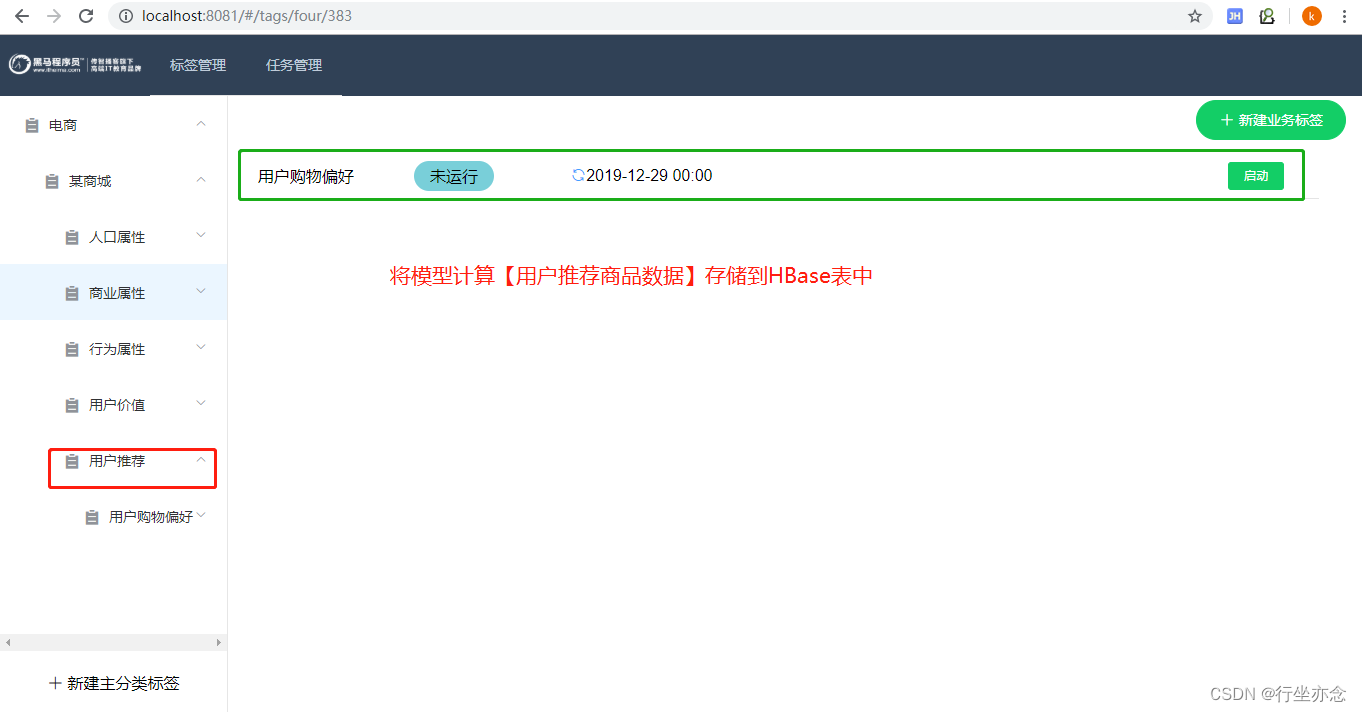
模型开发
开发模型标准流程:继承基类 AbstractModel,实现标签计算方法 doTag
具体在:用户画像——使用模板方法(Template Pattern)构建标签抽象类AbstractModel
这篇文章中有讲到。
算法模型开发步骤:
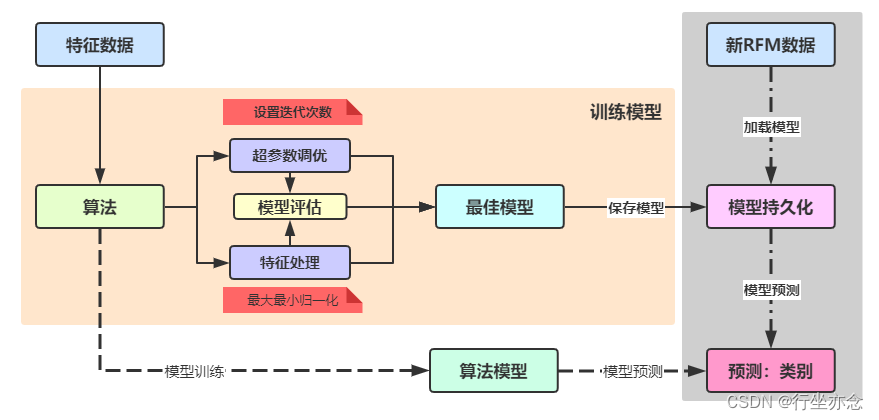
1. 自定义函数,从url中提取出访问商品id
val url_to_product: UserDefinedFunction = udf(
(url: String) => {
// 正则表达式
val regex: Regex = "^.+\\/product\\/(\\d+)\\.html.+$".r
// 正则匹配
val optionMatch: Option[Regex.Match] = regex.findFirstMatchIn(url)
// 获取匹配的值
val productId = optionMatch match {
case Some(matchValue) => matchValue.group(1)
case None => null
}
// 返回productId
productId
}
)
2. 从url中计算商品id
val ratingsDF: Dataset[Row] = businessDF
.filter($"loc_url".isNotNull) // 获取loc_url不为null
.select(
$"global_user_id".as("userId"), //
url_to_product($"loc_url").as("productId") //
)
.filter($"productId".isNotNull) // 过滤不为空的数据
// 统计每个用户点击各个商品的次数
.groupBy($"userId", $"productId")
.count()
// 数据类型转换
.select(
$"userId".cast(DoubleType), //
$"productId".cast(DoubleType), //
$"count".as("rating").cast(DoubleType) //
)3. 使用ALS算法训练模型(评分为隐式评分)
val alsModel: ALSModel = new ALS()
// 设置属性
.setUserCol("userId")
.setItemCol("productId")
.setRatingCol("rating")
.setPredictionCol("prediction")
// 设置算法参数
.setImplicitPrefs(true) // 隐式评分
.setRank(10) // 矩阵因子,rank秩的值
.setMaxIter(10) // 最大迭代次数
.setColdStartStrategy("drop") // 冷启动
.setAlpha(1.0)
.setRegParam(1.0)
// 应用数据集,训练模型
.fit(ratingsDF)
ratingsDF.unpersist()4. 模型评估
import org.apache.spark.ml.evaluation.RegressionEvaluator
val evaluator: RegressionEvaluator = new RegressionEvaluator()
.setLabelCol("rating")
.setPredictionCol("prediction")
.setMetricName("rmse")
val rmse: Double = evaluator.evaluate(alsModel.transform(ratingsDF))
// rmse = 1.0300179222180903
println(s"rmse = $rmse")5.模型推荐
// 5.1 给用户推荐商品: Top5
val rmdItemsDF: DataFrame = alsModel.recommendForAllUsers(5)
// 5.2. 给物品推荐用户
val rmdUsersDF: DataFrame = alsModel.recommendForAllItems(5)四、总结
BP用户偏好购物模型通过交替最小二乘法(ALS)对大量用户-物品评分数据进行模型训练,从而实现给用户推荐商品(或者给物品推荐用户)的功能,在物品信息以及用户数据量大的时候起到了关键作用,但在数据量小的领域不适合构建推荐系统,因为小范围的数据用户不需要推荐也能满足自己高质量的需求。
(以上内容部分来自黑马程序员,侵删。)

















 887
887

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









