






目录
一、图计算:
图(Graph)是用于表示对象之间关联关系的一种抽象数据结构,分为有向图跟无向图,使用节点(Vertex)和边(Edge)进行描述:顶点表示对象,边表示对象之间的关系。可抽象成用图描述的数据即为图数据。图计算,便是以图作为数据模型来表达问题并予以解决的这一过程。以高效解决图计算问题为目标的系统软件称为图计算系统。
大数据时代,数据之间存在关联关系。由于图是表达事物之间复杂关联关系的组织结构,因此现实生活中的诸多应用场景都需要用到图,例如,淘宝用户好友关系图、道路图、电路图、病毒传播网、国家电网、文献网、社交网和知识图谱。 为了从这些数据之间的关联关系中获取有用信息,大量图算法层出不穷。它们通过对大型图数据的迭代处理,获得图数据中隐藏的重要信息。
简单地来讲,在图中最基本的单元是:
1.节点(Vertex)
2.边(Edge)
那什么是节点,什么是边呢?

一位女士在天猫买了一只口红,这位女士、商铺都可以是节点,而购买行为则是边。
图计算起源:
图计算的起源于哥尼斯堡(现俄罗斯的加里宁格勒市)的“七桥问题”。
在18世纪初,哥尼斯堡的一个公园里,有七座桥将普雷格尔河中的两个岛及岛与河岸连接起来。人们提出了一个问题:是否可能从这四块陆地中任一块出发,恰好通过每座桥一次,再回到起点呢?这个问题看似简单,但实际上却引发了一系列关于图论和拓扑学的深入思考。
数学家欧拉(Leonhard Euler)在1736年研究了这个问题,并将它归结为一个图论问题。他把陆地抽象为图中的节点,把桥抽象为图中的边,通过分析和计算,证明了这样的路径是不存在的。欧拉的这项研究被认为是图论和拓扑学的开创性工作之一,也为后来的图计算奠定了重要的理论基础。
图计算特点:
图计算在处理复杂数据上显现出其优异的性能优势,具体表现在以下方面:
1.表达复杂的关联关系: 图计算能够有效地表达和处理有复杂关联关系的数据上,比如说警察办案会在墙上绘制一个关系图(网),也就是将犯罪嫌疑人有关的对象的关系标注出来形成一张关系网,有利于表达犯罪嫌疑人与其他人之间的关联关系,能够进行清晰地思考和判断。而在计算机上的图数据也是如此。这种结构能够清晰地展现事物之间的关联性和交互性。 2.高效存储和处理: 图计算基于节点和边方式存储图数据和进行计算,能够高效以及大规模地处理图数据,并且通过图算法系统能够快速地遍历、分析与查询数据,从而获得想要的结果。 3.迭代计算: 图计算要经过许多轮的迭代,每次迭代则需要重新计算和更新节点和边之间的关系,直到达到收敛值,这种迭代计算的方式以保证图数据的正确性和逐步达到问题的最优解。
图计算的应用:
图计算有着广泛的应用前景:
1.信用卡欺诈:图计算破获银行贷款诈骗 2.新冠肺炎患者溯源:还原确诊病例的轨迹和关联关系 3.识别洗钱账户:结合亲友关系、转账关系、通讯关系等使用挖掘算法分析可疑交易 4.犯罪分子社会关系:犯罪组织内部成员之间的关联关系。 5.推荐系统:用户和物品的表示、特征提取和表示学习、社交关系分析等等 图计算作为下一代人工智能的核心技术,已被广泛应用于医疗、教育、军事、金融等多个领域
Spark GraphX图处理库
GraphX 是 Spark 中用于图形和图形并行计算的新组件。在高层次上, GraphX 通过引入 Spark RDD来扩展 新的图抽象:具有属性的有向多图 附加到每个顶点和边。为了支持图计算,GraphX 公开了一组基本 运算符(例如,subgraph、joinVertics 和 aggregateMessages)以及 Pregel API 的优化变体。此外,GraphX 还包括越来越多的图算法和构建器,以简化图分析任务。
属性图:
属性图是有向多图 将用户定义的对象附加到每个顶点和边。有向多图是有向的 具有可能共享同一源和目标顶点的多个平行边的图形。这 支持并行边的能力简化了可以有多个边的建模方案 相同顶点之间的关系(例如,同事和朋友)。每个顶点都由一个唯一的 64 位长标识符 进行键控。GraphX 不会对 顶点标识符。同样,边具有相应的源顶点和目标顶点 标识符。VertexId
属性图在顶点和边类型上进行参数化。这些 分别是与每个顶点和边关联的对象的类型。VDED
属性图示例:
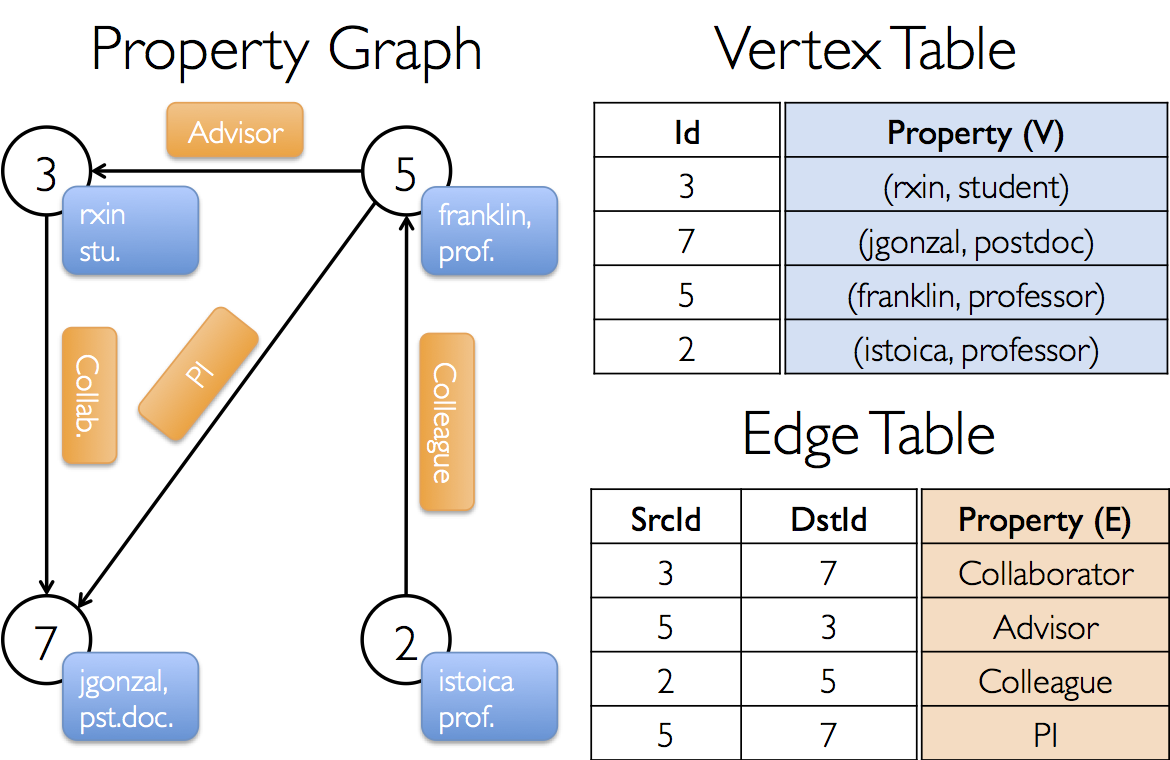
Spark GraphX的主要功能和用途包括: 1、图构建和操作:Spark GraphX允许用户构建和操作大规模图数据结构,包括添加和删除顶点、边,以及遍历图数据。 2、图算法:GraphX提供了一系列图算法,包括最短路径算法、图遍历算法、连通性分析、PageRank、社区检测等,用于解决图相关问题,例如路由规划、社交网络分析、网络拓扑分析等。 3、顶点属性和边属性:用户可以为图的顶点和边附加属性,以存储关于实体的额外信息,例如顶点的属性可以表示用户的属性,边的属性可以表示关系的权重。 4、分布式计算:Spark GraphX利用Spark的分布式计算能力,可以处理大规模的图数据,从而实现高性能的图处理。 5、图切割:Spark GraphX支持将大型图切分成较小的子图,以便更容易处理。 6、可视化工具:可以使用可视化工具来绘制和可视化图,以更好地理解图的结构和特性。 Spark GraphX通常用于处理图数据的大规模分析和挖掘,包括社交网络分析、推荐系统、网络拓扑分析、生物信息学等领域。它为开发人员提供了处理图数据的强大工具和库,可以在分布式Spark集群上进行高性能的图处理。
下面举一个例子如何使用Spark GraphX来加载、处理和分析社交网络图数据,并计算出图中顶点的PageRank值:
import org.apache.spark.graphx.GraphLoader
// 加载用户数据
val users = (sc.textFile("data/graphx/users.txt")
.map(line => line.split(",")).map( parts => (parts.head.toLong, parts.tail) ))
// 加载关注者关系数据
val followerGraph = GraphLoader.edgeListFile(sc, "data/graphx/followers.txt")
// 附加用户属性,对于没有属性的顶点,我们为它们分配一个空数组。
val graph = followerGraph.outerJoinVertices(users) {
case (uid, deg, Some(attrList)) => attrList
case (uid, deg, None) => Array.empty[String]
}
// 限制图到具有特定属性的用户
val subgraph = graph.subgraph(vpred = (vid, attr) => attr.size == 2)
// 计算PageRank,0.01是阻尼因子
val pagerankGraph = subgraph.pageRank(0.001)
// 获取PageRank最高的用户的属性
val userInfoWithPageRank = subgraph.outerJoinVertices(pagerankGraph.vertices) {
case (uid, attrList, Some(pr)) => (pr, attrList.toList)
case (uid, attrList, None) => (0.0, attrList.toList)
}
println(userInfoWithPageRank.vertices.top(5)(Ordering.by(_._2._1)).mkString("\n"))ID-Mapping
在构建精准用户画像时,面临着这样一个问题: 日志采集不能成功地收集用户的所有ID, 且每条业务线有各自定义的UID用来标识用户,从而造成了用户ID的零碎化。所以要使用ID-Mapping进行用户画像的“拼图”。
ID-Mapping主要用于解决用户身份信息的混乱问题,比如说相同设备、不同账号间切换,相同用户、不同渠道下账号不相同等。ID-Mapping通俗地说,就是把几份不同来源的数据,通过各种技术手段识别为同一个对象或主题,例如同一台设备(直接),同一个用户(间接),同一家企业(间接)等等。
ID-Mapping标识符
由于用户的行为信息、属性数据分散在多个不同的数据来源中,假设一个人在手机上使用百度地图, 在ipad上观看百度爱奇艺视频,在第二个手机上使用手机百度app, 在pc电脑上使用百度搜索,那应该如何将这些信息聚合起来呢?答案是标识符。
具体来说,ID-Mapping标识符可以将各种ID(如用户ID、设备ID、账号ID等)进行映射和关联,从而形成一个统一的用户实体数据。通过ID-Mapping,我们可以将用户在不同平台、不同设备、不同渠道下的行为信息进行整合和串联,形成一个完整的用户画像。这个用户画像可以帮助我们更好地了解用户的行为、兴趣、需求等信息,从而提供更加精准的服务和推荐。
标识符的种类也有很多,简单划分为Android 与 ios:

ios设备常见标识符: IMEI:国际移动设备识别码(International Mobile Equipment Identity,IMEI),即通常所说的手机序列号、手机“串号”,用于在移动电话网络中识别每一部独立的手机等移动通信设备,相当于移动电话的身份证。IMEI是写在主板上的,重装APP不会改变IMEI。Android 6.0以上系统需要用户授予read_phone_state权限,如果用户拒绝就无法获得; IDFA:于iOS 6 时面世,可以监控广告效果,同时保证用户设备不被APP追踪的折中方案。可能发生变化,如系统重置、在设置里还原广告标识符。用户可以在设置里打开“限制广告跟踪”; MAC地址:硬件标识符,包括WiFi mac地址和蓝牙mac地址。iOS 7 之后被禁止;OpenUDID:在iOS 5发布时,UDID被弃用了,这引起了广开发者需要寻找一个可以替代 UDID,并且不受苹果控制的方案。由此OpenUDID成为了当时使用最广泛的开源UDID替代方案。OpenUDID在工程中实现起来非常简单,并且还支持一系列的广告提供商;
Android设备常见的标识符: IMEl (International Mobile Equipment ldentity),即通常所说的手机序列号、手机“串号”用于在移动电话网络 中识别每一部独立的手机等行动通讯装置;序列号共有15位数字,前6位(TAC)是型号核准号码,代表手机类型。接 着2位(FAC)是最后装配号,代表产地。后6位(SNR)是串号,代表生产顺序号。最后1位(SP)一般为0,是检验 码,备用。 MAC(Media Access Control)一般代指MAC位址,为网卡的标识,用来定义网络设备的位置。 IMSl(International Mobile Subscriberldentification Number),储存在SIM卡中,可用于区别移动用户的有效信 息;其总长度不超过15位,同样使用0~9的数字。其中MCC是移动用户所属国家代号,占3位数字,中国的MCC规定 为460;MNC是移动网号码,最多由两位数字组成,用于识别移动用户所归属的移动通信网:MSIN是移动用户识别码 用以识别某一移动通信网中的移动用户。 Android_ID:在设备首次启动时,系统会随机生成一个64位的数字,并把这个数字以16进制字符串的形式保存下来,这个16进制的字符串就是Android_ID,当设备被wipe后该值会被重置;
依据标识符可以找出同一用户的标识,从而实现多方面数据的聚合,以达到使用用户使用不同应用或设备数据的目的。
二、总结:
在ID-Mapping的过程中,可以利用图计算技术来找到各种ID标识之间的关联关系,从而识别出哪些ID标识属于同一个人或实体。通过构建包含各种ID的图结构,并应用图算法进行迭代处理,可以获取图数据中隐藏的重要信息,从而实现实现用户画像的构建、精准营销、个性化推荐等功能。
(以上为自学笔记,侵删。)















 2093
2093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









