






一.RFM模型

RFM模型:
-
第一点:衡量客户价值的,以便对客户划分群体
-
第二点:依据用户近期订单数据(近一个月订单数据、近3个月订单数据)计算
-
R:消费周期标签值,最后一次订单距今天数
-
F:最近交易次数
-
M:最近消费金额
-
RFM是 Rencency(最近一次消费),Frequency(消费频率)、Monetary(消费金额) ,三个首字母组合。

-
R:最近一次消费(Recency):指最近一次消费时间与截止时间的间隔。这个指标反映了客户最近一次的交易时间,R值越大表示客户交易距今越久,反之则越近。通常情况下,最近一次消费时间的间隔越短,客户对商品或服务最有可能感兴趣。
-
F:消费频次(Frequency):指客户在某段时间内所消费的次数。这个指标反映了客户的交易频率,F值越大表示客户交易越频繁,反之则不够活跃。消费频次越高的客户也是满意度越高的客户,其忠诚度越高,客户价值越大。
-
M:消费金额(Monetary):指客户在某段时间内所消费的金额。这个指标反映了客户的消费能力,M值越大表示客户价值越高,反之则越低。消费金额越大的客户,消费能力自然也越大。
K-Means 算法
K-Means 是最常用的基于欧式距离的聚类算法,又名K均值算法。、
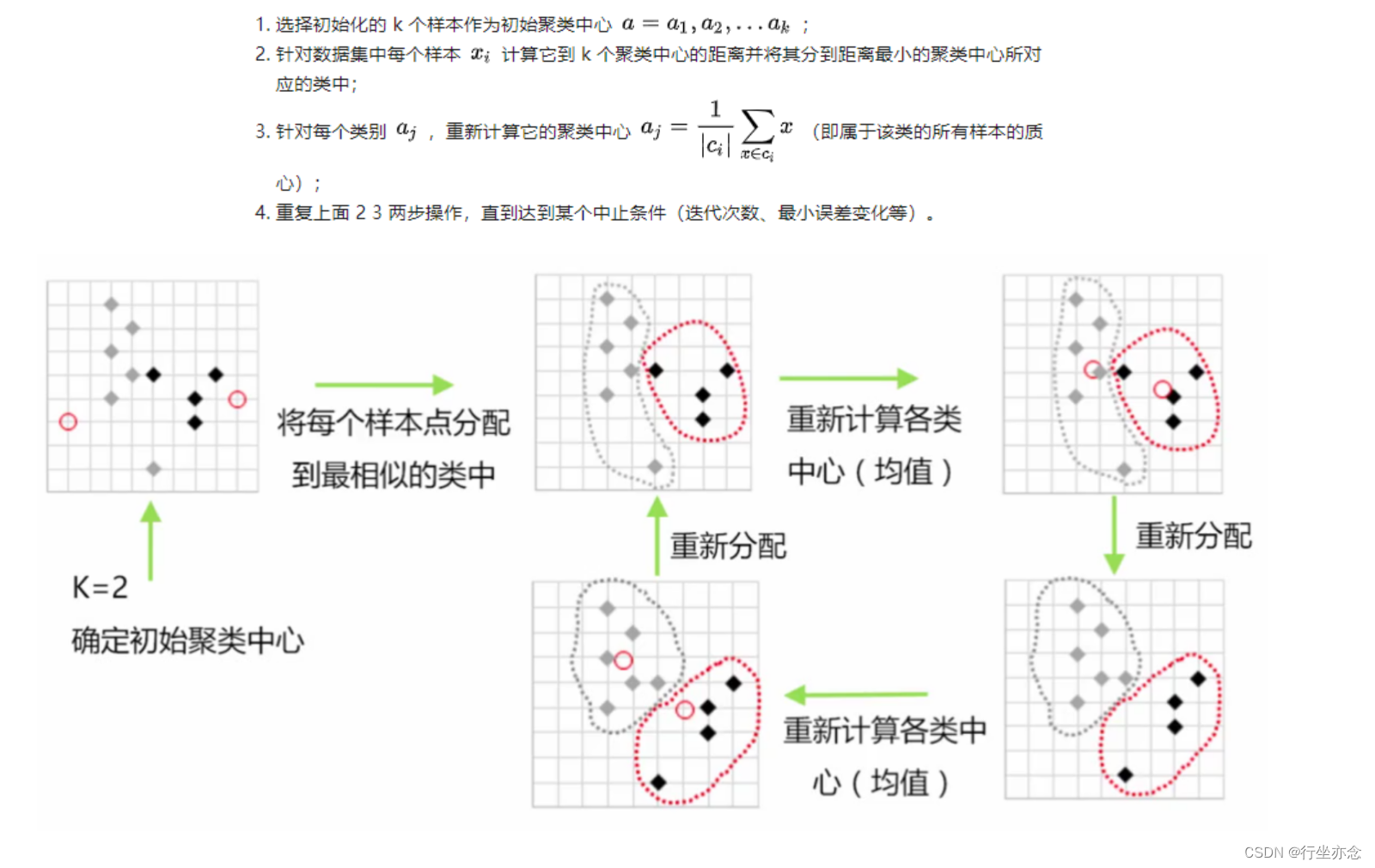
其步骤是
预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
初始随机分配4个中心点:
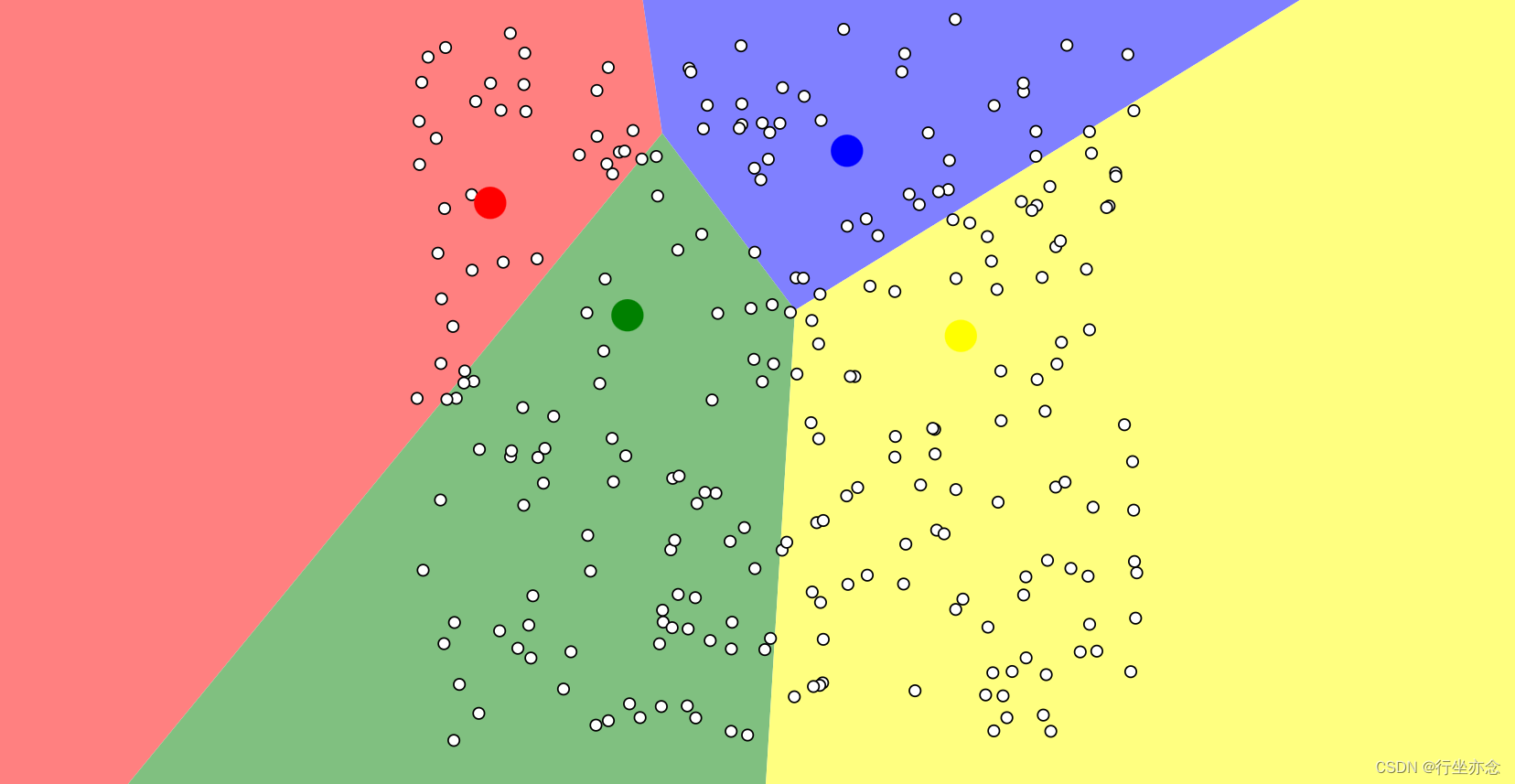
将数据点分配给最近的中心点:
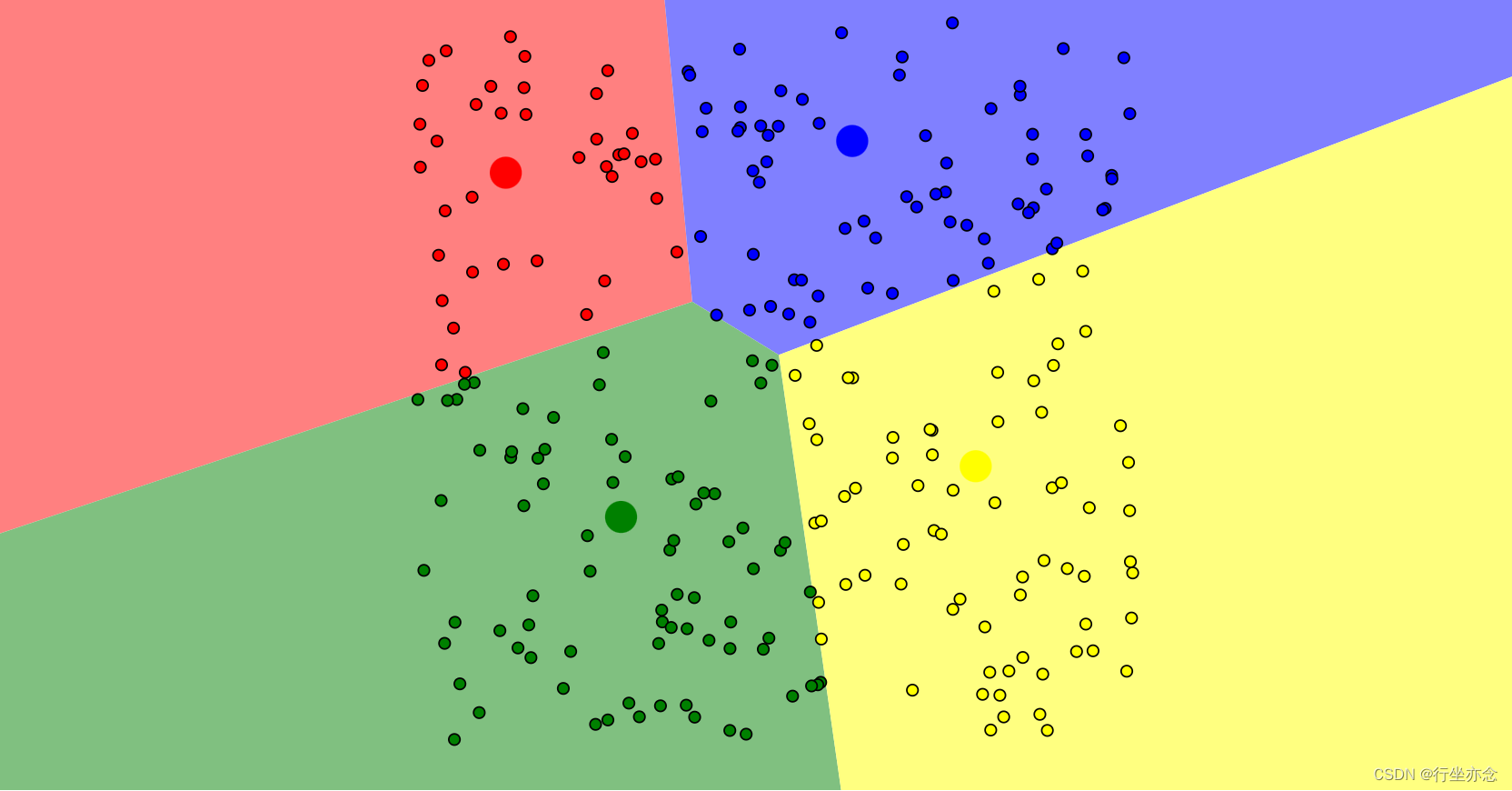
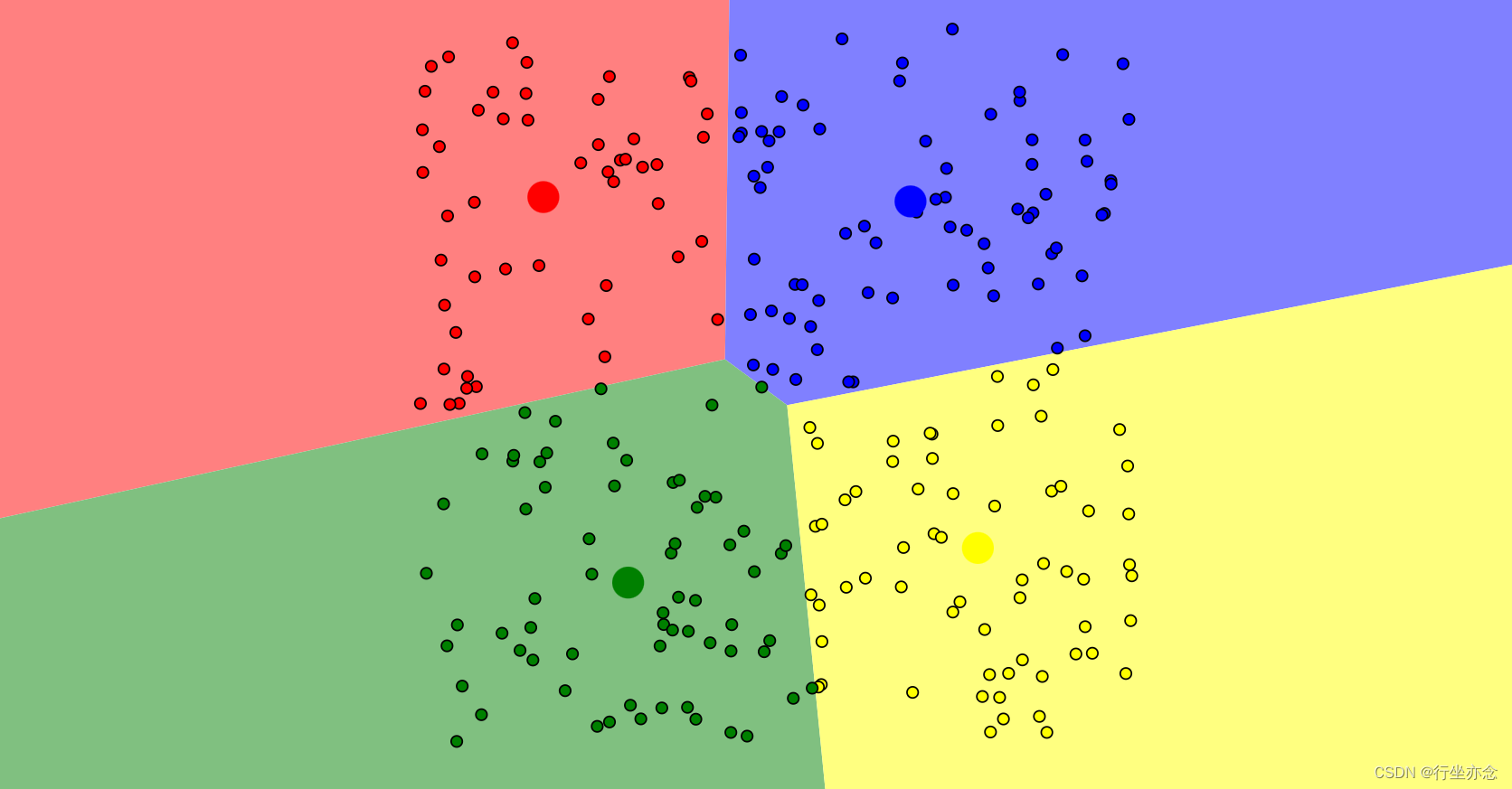
根据每个簇内的数据点,重新计算簇的中心点再分配数据点:
牧师-村民模型
K-Means算法有一个著名的解释,即牧师-村民模型。这个模型描述了四个牧师去郊区布道的过程。一开始,牧师们随意选了几个布道点,并将这些布道点的情况公告给了郊区的所有村民。于是,每个村民都会前往离自己家最近的布道点去听课。
听课之后,如果村民觉得距离太远,每个牧师就会统计一下自己课上所有村民的地址,然后搬到这些地址的中心地带,并在海报上更新自己的布道点位置。然而,牧师每一次移动不可能让所有人都离得更近,有的村民可能会发现A牧师移动后,自己还不如去B牧师处听课更近。于是,每个村民又会选择离自己最近的布道点。
就这样,牧师们每个礼拜都会更新自己的位置,而村民们则根据自己的情况选择布道点,最终这个过程会稳定下来。这个模型的目的是为了让每个村民到其最近中心点的距离和最小,这与K-Means算法的目标是一致的,即找到K个聚类中心点,使得每个数据点到其所属聚类中心点的距离之和最小。
欧式距离
欧几里得距离或欧几里得度量是欧几里得空间中两点间“普通”(即直线)距离。使用这个距离,欧氏空间成为度量空间。相关联的范数·1称为欧几里得范数。
二维空间公式:
![]()
而K-Means算法就是通过中心点到各个点的欧式距离决定哪些点离这个中心点近,就归属于这个中心点。
针对K-Means均值聚类算法来说,把握三个要点即可: 1.K表示类簇个数,一开始随机初始化K个类簇中心点 2.计算所有数据到K个类簇的中心点距离,默认使用欧式距离,归属至距离最近的类簇中心点 3.对每个类簇中计算新的中心点,采用均值Means方式。 KMeans聚类算法构建的模型:K个类簇中心点的坐标
KMeans
优点: 简单直观:算法原理简单,易于实现和理解。 高效性:对于大数据集,它使用迭代方法来优化聚类结果,所以相对高效。 可伸缩性:可以应用于各种规模的数据集,并且可以很容易地增加或减少聚类数量。 适用于不同类型的数据:可以处理不同类型的数据,包括连续型、离散型和二元型数据等。 优化迭代功能:有优化迭代功能,可以在已经求得的聚类上再次进行迭代修正,优化初始监督学习样本分类不合理的地方。 缺点: K值选择困难:K值是事先给定的,但很多时候并不知道数据集应该分成多少个类别才最合适。K值的选择对聚类结果有很大影响,但选择合适的K值往往比较困难。 对初始值敏感:结果可能受到初始聚类中心的影响,不同的初始值可能结果不尽相同。 对非凸形状的类簇识别效果差:假设数据点呈现凸形状分布,对于非凸形状的类簇识别效果可能不佳。 易受噪声、边缘点、孤立点影响:噪声、边缘点和孤立点可能对聚类结果产生较大影响。 可处理的数据类型有限:对于高维数据对象的聚类效果不佳,且可处理的数据类型有限。
K-Means++算法
为了解决K-Means算法对于初始聚类中心的影响,K-Means++算法和K-Means算法的区别主要算法应运而生。K-Means++算法和K-Means算法的区别主要在于那K个中心点的选中,K-Means使用随机的方式给定中心点,而K-Means++先随机选取一个中心点,后面的中心点依赖于前面已知的中心点最远的点作为选取对象。

KMeans ++ 算法,避免K个初始中心点在一起,充分分散开的
缺点: 计算复杂度略高:与K-Means算法相比,K-Means++在选择初始聚类中心时需要额外的计算。虽然这些计算并不复杂,但会增加一定的时间成本。对于非常大的数据集,这种额外的计算可能会更加明显。
K-Means || 算法
解决K-Means++算法缺点而产生的一种算法,主要思路是 改变每次遍历时候的取样规则并非按照K-Means++算法每次遍历只获取一个样本,而是每次获取K个样本,重复该取样操作0(logn)次(n是样本的个数),然后再将这些 抽样出来的样本聚类出K个点 ,最后使用这 K个 点作为K-Means算法的初始聚簇中心点。
KMeans II算法使用两次KMeans算法:
1.第一次,使用原生态KMeans算法找K的点
2.第二次,以找到K个点为初始类簇中心点,使用KMeans算法聚类
RFM模型开发:
标签实现思路分析:
(1)从订单数据获取字段值,计算每个用户RFM值 R:最后一次消费时间距离 今天的天数 越小越好 :消费次数(订单次数) 越大越好 M:消费金额(所有订单总的消费金额) 越大越好
(2)按照规则给RFM进行打分(RFM_SCORE) R: 1-3天=5分,4-6天=4分,7-9天=3分,10-15天=2分,大于16天=1分 F: ≥200=5分,150-199=4分,100-149=3分,50-99=2分,1-49=1分 M: ≥20w=5分,10-19w=4分,5-9w=3分,1-4w=2分,<1w=1分
(3)将RFM数据使用KMeans算法聚类(K=5个) RFM转换为特征features,传入到KMeans算法,训练获取模型KMeansMode1从KMeans中获取出每个用户属于簇 0,1,2,3,4 每个簇的向量Vector中所有特征之和越大客户价值越高
算法实现步骤:
1.继承基类 AbstractModel,实现标签计算方法 doTag。
2.从业务数据中计算R、F、M的值
val rfmDF: DataFrame = businessDF
// a. 按照memberid分组,对每个用户的订单数据句可视化操作
.groupBy($"memberid")
.agg(
max($"finishtime").as("max_finishtime"), //
count($"ordersn").as("frequency"), //
sum(
$"orderamount".cast(DataTypes.createDecimalType(10, 2))
).as("monetary") //
)
// 计算R值
.select(
$"memberid".as("userId"), //
// 计算R值:消费周期
datediff(
current_timestamp(), from_unixtime($"max_finishtime")
).as("recency"), //
$"frequency", //
$"monetary"
)3.给RFM计算的值打分Score
val rWhen = when(col("recency").between(1, 3), 5.0) //
.when(col("recency").between(4, 6), 4.0) //
.when(col("recency").between(7, 9), 3.0) //
.when(col("recency").between(10, 15), 2.0) //
.when(col("recency").geq(16), 1.0) //
// F 打分条件表达式
val fWhen = when(col("frequency").between(1, 49), 1.0) //
.when(col("frequency").between(50, 99), 2.0) //
.when(col("frequency").between(100, 149), 3.0) //
.when(col("frequency").between(150, 199), 4.0) //
.when(col("frequency").geq(200), 5.0) //
// M 打分条件表达式
val mWhen = when(col("monetary").lt(10000), 1.0) //
.when(col("monetary").between(10000, 49999), 2.0) //
.when(col("monetary").between(50000, 99999), 3.0) //
.when(col("monetary").between(100000, 199999), 4.0) //
.when(col("monetary").geq(200000), 5.0) //
val rfmScoreDF: DataFrame = rfmDF.select(
$"userId", //
rWhen.as("r_score"), //
fWhen.as("f_score"), //
mWhen.as("m_score") //
)
//rfmScoreDF.printSchema()
//rfmScoreDF.show(50, truncate = false)4.组合R、F、M称为特征值(特征工程),使用KMeans聚类算法训练模型并做出预测
// 3.1 组合R\F\M列为特征值features
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("r_score", "f_score", "m_score"))
.setOutputCol("features")
val featuresDF: DataFrame = assembler.transform(rfmScoreDF)
// 将训练数据缓存
featuresDF.persist(StorageLevel.MEMORY_AND_DISK)
// 3.2 使用KMeans算法聚类,训练模型
val kMeansModel: KMeansModel = trainModel(featuresDF)
// 3.3. 使用模型预测
val predictionDF: DataFrame = kMeansModel.transform(featuresDF)
/*
root
|-- userId: string (nullable = true)
|-- r_score: double (nullable = true)
|-- f_score: double (nullable = true)
|-- m_score: double (nullable = true)
|-- features: vector (nullable = true)
|-- prediction: integer (nullable = true)
*/
//predictionDF.printSchema()
//predictionDF.show(50, truncate = false)5.获取类簇的中心点,进行数据转换
val centerIndexArray: Array[((Int, Double), Int)] = kMeansModel
.clusterCenters
// 返回值类型:: Array[(linalg.Vector, Int)]
.zipWithIndex // (vector1, 0), (vector2, 1), ....
// TODO: 对每个类簇向量进行累加和:R + F + M
.map{case(clusterVector, clusterIndex) =>
// rfm表示将R + F + M之和,越大表示客户价值越高
val rfm: Double = clusterVector.toArray.sum
clusterIndex -> rfm
}
// 按照rfm值进行降序排序
.sortBy(tuple => - tuple._2)
// 再次进行拉链操作
.zipWithIndex
//centerIndexArray.foreach(println)6.类簇中心点索引数据与标签数据相关联,进行打标签

// 4.1 获取属性标签规则rule和名称tagName,放在Map集合中
val rulesMap: Map[String, String] = TagTools.convertMap(tagDF)
//rulesMap.foreach(println)
// 4.2 聚类类簇关联属性标签数据rule,对应聚类类簇与标签tagName
val indexTagMap: Map[Int, String] = centerIndexArray
.map{case((centerIndex, _), index) =>
val tagName = rulesMap(index.toString)
(centerIndex, tagName)
}
.toMap
//indexTagMap.foreach(println)
// 4.3 使用KMeansModel预测值prediction打标签
// a. 将索引标签Map集合 广播变量广播出去
val indexTagMapBroadcast = session.sparkContext.broadcast(indexTagMap)
// b. 自定义UDF函数,传递预测值prediction,返回标签名称tagName
val index_to_tag: UserDefinedFunction = udf(
(clusterIndex: Int) => indexTagMapBroadcast.value(clusterIndex)
)
// c. 打标签
val modelDF: DataFrame = predictionDF.select(
$"userId", // 用户ID
index_to_tag($"prediction").as("rfm")
)
//modelDF.printSchema()
//modelDF.show(100, truncate = false)
// 返回画像标签数据
modelDF
}完整代码如下:
import cn.itcast.tags.models.{AbstractModel, ModelType}
import cn.itcast.tags.tools.TagTools
import org.apache.spark.ml.clustering.{KMeans, KMeansModel}
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.linalg
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.{Column, DataFrame, SparkSession}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.types.{DataTypes, DecimalType}
import org.apache.spark.storage.StorageLevel
/**
* 挖掘类型标签模型开发:客户价值模型RFM
*/
class RfmModel extends AbstractModel("客户价值RFM", ModelType.ML){
/*
361 客户价值
362 高价值 0
363 中上价值 1
364 中价值 2
365 中下价值 3
366 超低价值 4
*/
override def doTag(businessDF: DataFrame, tagDF: DataFrame): DataFrame = {
val session: SparkSession = businessDF.sparkSession
import session.implicits._
/*
root
|-- memberid: string (nullable = true)
|-- ordersn: string (nullable = true)
|-- orderamount: string (nullable = true)
|-- finishtime: string (nullable = true)
*/
//businessDF.printSchema()
//businessDF.show(10, truncate = false)
/*
root
|-- id: long (nullable = false)
|-- name: string (nullable = true)
|-- rule: string (nullable = true)
|-- level: integer (nullable = true)
*/
//tagDF.printSchema()
/*
|id |name|rule|level|
+---+----+----+-----+
|362|高价值 |0 |5 |
|363|中上价值|1 |5 |
|364|中价值 |2 |5 |
|365|中下价值|3 |5 |
|366|超低价值|4 |5 |
+---+----+----+-----+
*/
//tagDF.filter($"level" === 5).show(10, truncate = false)
val rfmDF: DataFrame = businessDF
// a. 按照memberid分组,对每个用户的订单数据句可视化操作
.groupBy($"memberid")
.agg(
max($"finishtime").as("max_finishtime"), //
count($"ordersn").as("frequency"), //
sum(
$"orderamount".cast(DataTypes.createDecimalType(10, 2))
).as("monetary") //
)
// 计算R值
.select(
$"memberid".as("userId"), //
// 计算R值:消费周期
datediff(
current_timestamp(), from_unixtime($"max_finishtime")
).as("recency"), //
$"frequency", //
$"monetary"
)
//rfmDF.printSchema()
//rfmDF.show(10, truncate = false)
// R 打分条件表达式
val rWhen = when(col("recency").between(1, 3), 5.0) //
.when(col("recency").between(4, 6), 4.0) //
.when(col("recency").between(7, 9), 3.0) //
.when(col("recency").between(10, 15), 2.0) //
.when(col("recency").geq(16), 1.0) //
// F 打分条件表达式
val fWhen = when(col("frequency").between(1, 49), 1.0) //
.when(col("frequency").between(50, 99), 2.0) //
.when(col("frequency").between(100, 149), 3.0) //
.when(col("frequency").between(150, 199), 4.0) //
.when(col("frequency").geq(200), 5.0) //
// M 打分条件表达式
val mWhen = when(col("monetary").lt(10000), 1.0) //
.when(col("monetary").between(10000, 49999), 2.0) //
.when(col("monetary").between(50000, 99999), 3.0) //
.when(col("monetary").between(100000, 199999), 4.0) //
.when(col("monetary").geq(200000), 5.0) //
val rfmScoreDF: DataFrame = rfmDF.select(
$"userId", //
rWhen.as("r_score"), //
fWhen.as("f_score"), //
mWhen.as("m_score") //
)
//rfmScoreDF.printSchema()
//rfmScoreDF.show(50, truncate = false)
// 3.1 组合R\F\M列为特征值features
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("r_score", "f_score", "m_score"))
.setOutputCol("features")
val featuresDF: DataFrame = assembler.transform(rfmScoreDF)
// 将训练数据缓存
featuresDF.persist(StorageLevel.MEMORY_AND_DISK)
// 3.2 使用KMeans算法聚类,训练模型
val kMeansModel: KMeansModel = trainModel(featuresDF)
// 3.3. 使用模型预测
val predictionDF: DataFrame = kMeansModel.transform(featuresDF)
/*
root
|-- userId: string (nullable = true)
|-- r_score: double (nullable = true)
|-- f_score: double (nullable = true)
|-- m_score: double (nullable = true)
|-- features: vector (nullable = true)
|-- prediction: integer (nullable = true)
*/
//predictionDF.printSchema()
//predictionDF.show(50, truncate = false)
// 3.4 获取类簇中心点
val centerIndexArray: Array[((Int, Double), Int)] = kMeansModel
.clusterCenters
// 返回值类型:: Array[(linalg.Vector, Int)]
.zipWithIndex // (vector1, 0), (vector2, 1), ....
// TODO: 对每个类簇向量进行累加和:R + F + M
.map{case(clusterVector, clusterIndex) =>
// rfm表示将R + F + M之和,越大表示客户价值越高
val rfm: Double = clusterVector.toArray.sum
clusterIndex -> rfm
}
// 按照rfm值进行降序排序
.sortBy(tuple => - tuple._2)
// 再次进行拉链操作
.zipWithIndex
//centerIndexArray.foreach(println)
// 4.1 获取属性标签规则rule和名称tagName,放在Map集合中
val rulesMap: Map[String, String] = TagTools.convertMap(tagDF)
//rulesMap.foreach(println)
// 4.2 聚类类簇关联属性标签数据rule,对应聚类类簇与标签tagName
val indexTagMap: Map[Int, String] = centerIndexArray
.map{case((centerIndex, _), index) =>
val tagName = rulesMap(index.toString)
(centerIndex, tagName)
}
.toMap
//indexTagMap.foreach(println)
// 4.3 使用KMeansModel预测值prediction打标签
// a. 将索引标签Map集合 广播变量广播出去
val indexTagMapBroadcast = session.sparkContext.broadcast(indexTagMap)
// b. 自定义UDF函数,传递预测值prediction,返回标签名称tagName
val index_to_tag: UserDefinedFunction = udf(
(clusterIndex: Int) => indexTagMapBroadcast.value(clusterIndex)
)
// c. 打标签
val modelDF: DataFrame = predictionDF.select(
$"userId", // 用户ID
index_to_tag($"prediction").as("rfm")
)
//modelDF.printSchema()
//modelDF.show(100, truncate = false)
// 返回画像标签数据
modelDF
}
/**
* 使用KMeans算法训练模型
* @param dataframe 数据集
* @return KMeansModel模型
*/
def trainModel(dataframe: DataFrame): KMeansModel = {
// 使用KMeans聚类算法模型训练
val kMeansModel: KMeansModel = new KMeans()
.setFeaturesCol("features")
.setPredictionCol("prediction")
.setK(5) // 设置列簇个数:5
.setMaxIter(20) // 设置最大迭代次数
.fit(dataframe)
println(s"WSSSE = ${kMeansModel.computeCost(dataframe)}")
// 返回
kMeansModel
}
}
object RfmModel{
def main(args: Array[String]): Unit = {
val tagModel = new RfmModel()
tagModel.executeModel(361L)
}
}二、总结:
使用KMeans聚类算法构建RFM客户价值模型是一种有效的客户细分方法,可以帮助企业准确识别不同价值的客户群体,并据此制定针对性的营销策略。但是需要人为设置K值,K值的选择又跟预测结果以及组建的模型有着很大的关系,不过在Sprak中KMeans可以设置算法底层实现K-Means || 算法,以便拿到更好的聚簇中心点。
(以上为自用笔记,侵删)

















 1872
1872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









