







 本文详细介绍了K-Means聚类算法,包括聚类的基本概念、类型(划分、层次、基于密度)及其在商业、金融等领域的应用。重点讲解了K-Means的原理、优缺点,并通过电商平台销售实例展示了数据预处理(如数据观察、缺失值处理、异常值处理、重置索引)和Python实现过程,包括特征编码、数据标准化、降维和肘部法则确定最优k值。最后,解释了K-Means聚类结果的含义。
本文详细介绍了K-Means聚类算法,包括聚类的基本概念、类型(划分、层次、基于密度)及其在商业、金融等领域的应用。重点讲解了K-Means的原理、优缺点,并通过电商平台销售实例展示了数据预处理(如数据观察、缺失值处理、异常值处理、重置索引)和Python实现过程,包括特征编码、数据标准化、降维和肘部法则确定最优k值。最后,解释了K-Means聚类结果的含义。
一、聚类
1.什么是聚类
聚类(Clustering)是数据挖掘和机器学习中的一种无监督学习方法,是将对象集合中的对象分类到不同的类或者簇这样的一个过程,使得同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。簇内的相似性越大,簇间差别越大,聚类就越好。
聚类结果的好坏取决于该聚类方法采用的相似性评估方法以及该方法的具体实现,聚类方法的好坏还取决于该方法是能发现某些还是所有的隐含模式。
2.聚类类型
(1)划分聚类
对于给定的数据集,划分聚类方法首先创建一个初始划分,然后采用一种迭代的重定位技术,尝试通过对象在划分间的移动来改进划分,直到使评价聚类性能的评价函数的值达到最优为止。划分聚类方法以距离作为数据集中不同数据间的相似性度量,将数据集划分成多个簇。划分聚类方法是最基本的聚类方法,属于这样的聚类方法有 k 均值((k-means)、k中心点(k-medoids)等。
划分聚类方法的主要思想: 给定一个包含 n个数据对象的数据集,划分聚类方法将数据对象的数据集进行k个划分,每个划分表示一个簇(类),并且k≤n,同时满足下面两个条件:每个簇至少包含一个对象,每个对象属于且仅属于一个簇。对于给定的要构建的划分的数目 k,划分方法首先给出一个初始的划分,然后采用一种迭代的重定位技术,尝试通过对象在划分间移动来改进划分,使得每一次改进之后的划分方案都较前一次更好。好的划分是指同一簇中的对象之间尽可能“接近”,不同簇中的对象之间尽可能“远离”。
划分聚类方法的评价函数:评价划分聚类效果的评价函数着重考虑两方面,即每个簇中的对象应该是紧凑的,各个簇间的对象的距离应该尽可能远。实现这种考虑的一种直接方法就是观察聚类C 的类内差异w(C)和类间差异b(C)。类内差异衡量类内的对象之间的紧凑性,类间差异衡量不同类之间的距离。
类内差异可以用距离函数来表示,最简单的就是计算类内的每个对象点到它所属类的中心的距离的平方和,即
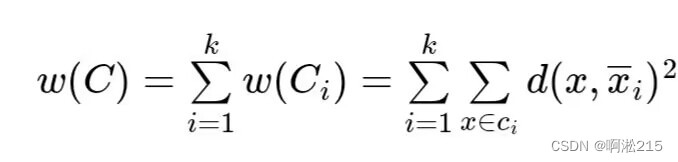
类间差异定义为类中心之间距离的平方和,即
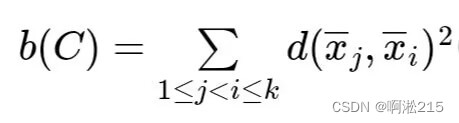
两式中的 ,
分别是类类Cᵢ、Cⱼ的类中心。
聚类C的聚类质量可以用w(C)和b(C)的一个单调组合来表示,如w(C) / b(C)
(2)层次聚类
划分聚类获得的是单级聚类 ,而层次聚类是将数据集分解成多级进行聚类 ,层的分解可以用树状图来表示。根据层次的分解方法不同 ,层次聚类可以分为自底向上凝聚的聚集型(Agglomerative Clustering)和自顶向下分裂的分解型聚类(Divisive Clustering),凝聚型方法一开始就将每个对象作为单独的一簇,然后不断地合并相近的对象或簇。分裂型方法一开始把所有的对象置于一个簇中,在迭代的每一步中 ,一个簇被分裂为更小的簇 ,直到每个对象在一个单独的簇中,或者达到算法终止条件。
(3)基于密度的聚类
绝大多数划分聚类基于对象之间的距离进行聚类 ,这样的方法只能发现球状的类,而在发现任意形状的类上遇到了困难。 基于密度的聚类的主要思想: 只要临近区域的密度(对象或数据点的数目)超过某个阈值就继续聚类。 这样的方法可以用来过滤噪声和孤立点数据,发现任意形状的类。
3.聚类的应用领域
聚类分析的应用领域非常广泛,以下只是其中的一些应用场景。
(1)商业
聚类分析可以用来发现不同的客户群体,并通过用户行为模式刻画不同的客户群特征。聚类是细分市场的常用工具,同时也可以用于研究客户行为,寻找潜在市场。
(2)金融
通过利用客户的财务数据、交易记录等信息进行聚类,可以区分不同信用等级的客户群体;根据资产的风险收益特性将投资产品进行分类,可以优化投资策略
(3)供应链管理
聚类分析可以帮助识别供应链环节中的瓶颈或优化点,例如对运输路线、供应商表现等进行分类。
(4)电子商务
在电商网站中,通过分组聚类出具有相似浏览行为的客户,并分析客户的共同特征,可以更好地电商运营者了解自己的客户,从而提供更合适的服务。
二、K-Means 聚类
1.K-Means 聚类的原理
KMeans聚类算法也被称为k平均聚类算法,是一种广泛使用的聚类算法。k均值用质心来表示一个簇,质心就是一组数据对象点的平均值。k均值算法以k为输入参数,将n个数据对象划分为k个簇,使得簇内数据对象具有较高的相似度。
k均值聚类算法的思想是从包含n个数据对象的数据集中随机地挑选k个对象,每个对象代表一个簇的平均值或质心或中心,其中k是用户指定的参数,即所期望要划分的簇的个数;对剩余的每个数据对象点根据其与各个簇中心的距离,将它指派到最近的簇;然后根据指派到簇的数据对象点,更新每个簇的中心;重复指派和更新的步骤直到簇或中心不发生变化,或度量聚类质量的目标函数收敛。k均值算法的目标函数E如下:
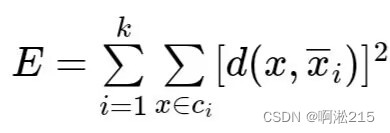
其中X是空间中的点表示给定的数据对象, 是簇 Cᵢ 的数据对象平均值,d(X,
)表示X与
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









