







支持向量机–处理非线性模型
如果样本集不是线性可分的,那么我们就不能像上面的处理方式一样求出 w w w和 b b b。
1.最小化:
{
m
i
n
1
2
∥
W
∥
2
+
C
∑
i
=
1
N
σ
i
⋯
(
1
)
s
.
t
.
y
i
[
W
⊤
X
i
+
b
]
≥
1
−
σ
i
σ
i
≥
0
\left\{\begin{matrix} min\frac{1}{2} \left \| W \right \|^2+C\sum_{i=1}^N \sigma _i \qquad \cdots(1) \\ s.t. \quad y_i[W^{\top} \boldsymbol{X_i}+b] \ge 1-\sigma _i \\ \sigma _i\ge 0 \end{matrix}\right.
⎩
⎨
⎧min21∥W∥2+C∑i=1Nσi⋯(1)s.t.yi[W⊤Xi+b]≥1−σiσi≥0
其中,
σ
i
\sigma _i
σi为松弛变量(Slack variable),C为事先设定的参数,i=1~N。此时,
y
i
y_i
yi和
x
i
x_i
xi是已知的,
W
W
W,
b
b
b,
σ
i
\sigma _i
σi是未知的。
2.高维映射
φ
(
x
)
\varphi (x)
φ(x)
X
低维
→
φ
φ
(
X
)
高维
\underset{低维}{X}\overset{\varphi}{\rightarrow} \underset{高维}{\varphi(X)}
低维X→φ高维φ(X)
例:
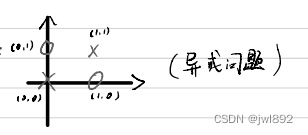
在上图坐标轴中,存在四个点,这四个点分为两类,我们怎么做才能把他们分开呢?
X
1
=
[
0
0
]
∈
C
1
X
2
=
[
1
1
]
∈
C
1
X
3
=
[
1
0
]
∈
C
2
X
4
=
[
0
1
]
∈
C
2
X_1=\begin{bmatrix}0 \\0\end{bmatrix}\in C_1 \qquad X_2=\begin{bmatrix}1\\1\end{bmatrix}\in C_1\\ X_3=\begin{bmatrix}1 \\0\end{bmatrix}\in C_2\qquad X_4=\begin{bmatrix}0 \\1\end{bmatrix}\in C_2
X1=[00]∈C1X2=[11]∈C1X3=[10]∈C2X4=[01]∈C2
下面我们令一种映射方式,至于为什么要这么设置,咱后面谈论
φ
(
x
)
:
X
=
[
a
b
]
→
φ
φ
(
X
)
=
[
a
2
b
2
a
b
a
b
]
\varphi(x):X=\begin{bmatrix}a \\b\end{bmatrix}\overset{\varphi}{\rightarrow} {\varphi(X)}=\begin{bmatrix} a^2\\b^2 \\a\\b\\ab\end{bmatrix}
φ(x):X=[ab]→φφ(X)=
a2b2abab
由此得到:
φ
(
X
1
)
=
[
0
0
0
0
0
]
∈
C
1
φ
(
X
2
)
=
[
1
1
1
1
1
]
∈
C
1
φ
(
X
3
)
=
[
1
0
1
0
0
]
∈
C
2
φ
(
X
4
)
=
[
0
1
0
1
0
]
∈
C
2
{\varphi(X_1)}=\begin{bmatrix} 0\\0 \\0\\0\\0\end{bmatrix}\in C_1 \qquad {\varphi(X_2)}=\begin{bmatrix} 1\\1 \\1\\1\\1\end{bmatrix}\in C_1\\ {\varphi(X_3)}=\begin{bmatrix} 1\\0 \\1\\0\\0\end{bmatrix}\in C_2 \qquad {\varphi(X_4)}=\begin{bmatrix} 0\\1 \\0\\1\\0\end{bmatrix}\in C_2
φ(X1)=
00000
∈C1φ(X2)=
11111
∈C1φ(X3)=
10100
∈C2φ(X4)=
01010
∈C2
规定
W
=
[
−
1
−
1
−
1
−
1
6
]
,
b
=
1
W=\begin{bmatrix}-1\\-1\\-1\\-1\\6\end{bmatrix},b=1
W=
−1−1−1−16
,b=1
此时
W
⊤
φ
(
X
1
)
+
b
=
1
W
⊤
φ
(
X
2
)
+
b
=
3
W
⊤
φ
(
X
3
)
+
b
=
1
W
⊤
φ
(
X
4
)
+
b
=
−
1
W^{\top}\varphi(X_1)+b=1\\ W^{\top}\varphi(X_2)+b=3\\ W^{\top}\varphi(X_3)+b=1\\ W^{\top}\varphi(X_4)+b=-1
W⊤φ(X1)+b=1W⊤φ(X2)+b=3W⊤φ(X3)+b=1W⊤φ(X4)+b=−1
φ
\varphi
φ的选择是无限维
(1) 我们可以不知道无限维映射
φ
(
X
)
\varphi(X)
φ(X)的显示表达,我们只要知道,一个核函数(Kernel Function)
K
(
X
1
,
X
2
)
=
φ
(
X
1
)
⊤
φ
(
X
2
)
K(X_1,X_2)=\varphi(X_1)^{\top}\varphi(X_2)
K(X1,X2)=φ(X1)⊤φ(X2)
则(1)这个优化式仍然可解。
核函数(部分):
①高斯核
K
(
X
1
,
X
2
)
=
e
−
∥
X
1
−
X
2
∥
2
2
σ
2
K(X_1,X_2)=e^{-\frac{\left \| X_1-X_2 \right \|^2 }{2{\sigma}^2} }
K(X1,X2)=e−2σ2∥X1−X2∥2
= φ ( X 1 ) ⊤ φ ( X 2 ) =\varphi(X_1)^{\top}\varphi(X_2) =φ(X1)⊤φ(X2)
②
K
(
X
1
,
X
2
)
=
(
X
1
⊤
X
2
+
1
)
d
K(X_1,X_2)=({X_1}^{\top}X_2+1)^d
K(X1,X2)=(X1⊤X2+1)d
= φ ( X 1 ) ⊤ φ ( X 2 ) =\varphi(X_1)^{\top}\varphi(X_2) =φ(X1)⊤φ(X2)
(2) K ( X 1 , X 2 ) K(X_1,X_2) K(X1,X2)能写成 φ ( X 1 ) ⊤ φ ( X 2 ) \varphi(X_1)^{\top}\varphi(X_2) φ(X1)⊤φ(X2)的充要条件(Mercer’s Theorem):
① K ( X 1 , X 2 ) = K ( X 2 , X 1 ) K(X_1,X_2)=K(X_2,X_1) K(X1,X2)=K(X2,X1);
②对任意
C
i
(
常数
)
,
X
i
(
向量
)
C_i(常数),\boldsymbol{X_i}(向量)
Ci(常数),Xi(向量),
(
i
=
1
∼
N
)
(i=1 \sim N)
(i=1∼N),有(半正定性):
∑
i
=
1
N
∑
j
=
1
N
C
i
C
j
K
(
X
i
,
X
j
)
≥
0
\sum_{i=1}^N \sum_{j=1}^NC_iC_jK(\boldsymbol{X_i},\boldsymbol{X_j})\ge 0
i=1∑Nj=1∑NCiCjK(Xi,Xj)≥0
**优化问题:**训练样本集 { ( X i , y i ) } i = 1 ∼ N \left \{ (\boldsymbol{X_i},y_i) \right \} _{i=1 \sim N} {(Xi,yi)}i=1∼N
(其中
X
i
\boldsymbol{X_i}
Xi为向量,
y
i
y_i
yi为标签)
{
m
i
n
1
2
∥
W
∥
2
+
C
∑
i
=
1
N
σ
i
s
.
t
.
y
i
[
W
⊤
φ
(
X
i
)
+
b
]
≥
1
−
σ
i
K
(
X
1
,
X
2
)
=
φ
(
X
1
)
⊤
φ
(
X
2
)
\left\{\begin{matrix} min\frac{1}{2} \left \| W \right \|^2+C\sum_{i=1}^N \sigma _i \qquad\\ s.t. \quad y_i[W^{\top} \varphi(X_i)+b] \ge 1-\sigma _i\\ \qquad \quad K(X_1,X_2)=\varphi(X_1)^{\top}\varphi(X_2) \end{matrix}\right.
⎩
⎨
⎧min21∥W∥2+C∑i=1Nσis.t.yi[W⊤φ(Xi)+b]≥1−σiK(X1,X2)=φ(X1)⊤φ(X2)
在此之前,简单说一下优化理论–原问题和对偶问题。
(1)原问题(Prime Problem)
m
i
n
f
(
w
)
s
.
t
g
i
(
w
)
≤
0
(
i
=
1
∼
k
)
s
.
t
h
i
(
w
)
=
0
(
i
=
1
∼
m
)
minf(w)\\ s.t \qquad g_i(w)\le 0 \qquad (i=1\sim k)\\ s.t \qquad h_i(w)= 0 \qquad (i=1\sim m)
minf(w)s.tgi(w)≤0(i=1∼k)s.thi(w)=0(i=1∼m)
(2)对偶问题(Dual Problem)
①定义
L
(
w
,
α
,
β
)
=
f
(
w
)
+
∑
i
=
1
k
α
i
g
i
(
w
)
+
∑
i
=
1
m
β
i
h
i
(
w
)
=
f
(
w
)
+
α
⊤
g
(
w
)
+
β
⊤
h
(
w
)
L(w,\alpha,\beta)\\ \qquad\qquad\qquad\qquad\qquad\quad=f(w)+\sum_{i=1}^k\alpha_ig_i(w)+\sum_{i=1}^m\beta_ih_i(w)\\ \qquad\qquad\qquad\qquad=f(w)+\alpha^{\top}g(w)+\beta^{\top}h(w)
L(w,α,β)=f(w)+i=1∑kαigi(w)+i=1∑mβihi(w)=f(w)+α⊤g(w)+β⊤h(w)
②对偶问题定义
m
a
x
Θ
(
α
,
β
)
=
i
n
f
{
L
(
w
,
α
,
β
)
}
s
.
t
α
i
≥
0
(
i
=
1
∼
k
)
max\Theta (\alpha,\beta)=inf\left \{ L(w,\alpha,\beta) \right \}\\ s.t \qquad \alpha_i \ge 0 \qquad (i=1 \sim k)
maxΘ(α,β)=inf{L(w,α,β)}s.tαi≥0(i=1∼k)
(其中
i
n
f
inf
inf为求所有
w
w
w的最小值)
定理:
如果
w
∗
w^*
w∗是原问题的解,而
α
∗
,
β
∗
\alpha^*,\beta^*
α∗,β∗是对偶问题的解,则有:
f
(
w
∗
)
≥
Θ
(
α
∗
,
β
∗
)
f(w^*) \ge \Theta (\alpha^*,\beta^*)
f(w∗)≥Θ(α∗,β∗)
证:
Θ
(
α
∗
,
β
∗
)
=
i
n
f
{
L
(
w
,
α
∗
,
β
∗
)
}
≤
L
(
w
∗
,
α
∗
,
β
∗
)
=
f
(
w
∗
)
+
∑
i
=
1
k
α
i
∗
g
i
(
w
∗
)
+
∑
i
=
1
m
β
i
∗
h
i
(
w
∗
)
≤
f
(
w
∗
)
\Theta (\alpha^*,\beta^*)=inf\left \{ L(w,\alpha^*,\beta^*) \right\}\\ \le L(w^*,\alpha^*,\beta^*) =f(w^*)+\sum_{i=1}^k\alpha_i^*g_i(w^*)+\sum_{i=1}^m\beta_i^*h_i(w^*)\\ \le f(w^*)
Θ(α∗,β∗)=inf{L(w,α∗,β∗)}≤L(w∗,α∗,β∗)=f(w∗)+i=1∑kαi∗gi(w∗)+i=1∑mβi∗hi(w∗)≤f(w∗)
( 其中 α i ∗ ≥ 0 , g i ( w ∗ ) ≤ 0 , h i ( w ∗ ) = 0 ) ,证毕 (其中\alpha_i^*\ge 0,g_i(w^*)\le 0,h_i(w^*)=0),证毕 (其中αi∗≥0,gi(w∗)≤0,hi(w∗)=0),证毕
定义:
G
=
F
(
w
∗
)
−
Θ
(
α
∗
,
β
∗
)
≥
0
G=F(w^*)-\Theta(\alpha^*,\beta^*)\ge 0
G=F(w∗)−Θ(α∗,β∗)≥0
G
G
G叫做原问题与对偶问题的间距(Duality Gap)。(对于某些特定的优化问题,可以证明对偶间距
G
=
0
G=0
G=0。)
强对偶问题:
若
f
(
w
)
f(w)
f(w)为凸函数,且
g
(
w
)
=
A
w
+
b
,
h
(
w
)
=
C
w
+
d
g(w)=Aw+b,h(w)=Cw+d
g(w)=Aw+b,h(w)=Cw+d,则此优化问题的原问题与对偶问题间距为0,即
f
(
w
∗
)
=
Θ
(
α
∗
,
β
∗
)
f(w^*)=\Theta (\alpha^*,\beta^*)
f(w∗)=Θ(α∗,β∗),
对
∀
i
=
1
∼
k
,
α
i
∗
=
0
,
或
g
i
(
w
∗
)
=
0
⏟
K
K
T
条件
对\forall i=1 \sim k,\underbrace{\alpha_i^*=0,或g_i(w^*)=0} _{KKT条件}
对∀i=1∼k,KKT条件
αi∗=0,或gi(w∗)=0
接下来,试着把上述优化问题转化为对偶问题,以便求解
OK,现在把上面说的原对偶问题总结一下:
①原问题:
m
i
n
f
(
w
)
s
.
t
g
i
(
w
)
≤
0
(
i
=
1
∼
k
)
s
.
t
h
i
(
w
)
=
0
(
i
=
1
∼
m
)
minf(w)\\ s.t \qquad g_i(w)\le 0 \qquad (i=1\sim k)\\ s.t \qquad h_i(w)= 0 \qquad (i=1\sim m)
minf(w)s.tgi(w)≤0(i=1∼k)s.thi(w)=0(i=1∼m)
②对偶问题:
L
(
w
,
α
,
β
)
=
f
(
w
)
+
∑
i
=
1
k
α
i
g
i
(
w
)
+
∑
i
=
1
m
β
i
h
i
(
w
)
L(w,\alpha,\beta)=f(w)+\sum_{i=1}^k\alpha_ig_i(w)+\sum_{i=1}^m\beta_ih_i(w)
L(w,α,β)=f(w)+i=1∑kαigi(w)+i=1∑mβihi(w)
m a x Θ ( α , β ) = i n f { L ( w , α , β ) } s . t α i ≥ 0 ( i = 1 ∼ k ) max\Theta (\alpha,\beta)=inf\left \{ L(w,\alpha,\beta) \right \}\\ s.t \qquad \alpha_i \ge 0 \qquad (i=1 \sim k) maxΘ(α,β)=inf{L(w,α,β)}s.tαi≥0(i=1∼k)
③KKT条件:
∀
i
=
1
∼
k
,
有
α
i
∗
=
0
,
或
g
i
(
w
∗
)
=
0
\forall i=1 \sim k,有\alpha_i^*=0,或g_i(w^*)=0
∀i=1∼k,有αi∗=0,或gi(w∗)=0
SVM是这样的:
m
i
n
1
2
∥
W
∥
2
+
C
∑
i
=
1
N
σ
i
(
凸函数
)
⇒
对应原函数的
f
(
w
)
min\frac{1}{2} \left \| W \right \|^2+C\sum_{i=1}^N \sigma _i (凸函数) \Rightarrow 对应原函数的f(w)
min21∥W∥2+Ci=1∑Nσi(凸函数)⇒对应原函数的f(w)
s . t { y i [ W ⊤ φ ( X i ) + b ] ≥ 1 − σ i σ i ≥ 0 ( i = 1 ∼ k ) s.t \left\{\begin{matrix} y_i[W^{\top}\varphi(X_i)+b]\ge 1-\sigma_i \\ \sigma_i \ge 0 \qquad (i=1 \sim k) \end{matrix}\right. s.t{yi[W⊤φ(Xi)+b]≥1−σiσi≥0(i=1∼k)
但是为了对应原问题,我们对他做一些改变:
m
i
n
1
2
∥
W
∥
2
−
C
∑
i
=
1
N
σ
i
min\frac{1}{2} \left \| W \right \|^2-C\sum_{i=1}^N \sigma _i
min21∥W∥2−Ci=1∑Nσi
s . t { 1 + σ i − y i W ⊤ φ ( X i ) − y i b ≤ 0 σ i ≤ 0 ( i = 1 ∼ k ) s.t \left\{\begin{matrix} 1+\sigma_i -y_iW^{\top}\varphi(X_i)-y_ib\le 0 \\ \sigma_i \le 0 \qquad (i=1 \sim k) \end{matrix}\right. s.t{1+σi−yiW⊤φ(Xi)−yib≤0σi≤0(i=1∼k)
对偶问题:
m
a
x
Θ
(
α
,
β
)
=
i
n
f
所有
(
W
,
σ
i
,
b
)
{
1
2
∥
W
∥
2
−
C
∑
i
=
1
N
β
i
σ
i
+
∑
i
=
1
N
α
i
[
1
+
σ
i
−
y
i
W
⊤
φ
(
X
i
)
−
y
i
b
]
}
max\Theta (\alpha,\beta)=\underset{所有(W,\sigma_i,b)}{inf}\left \{ \frac{1}{2} \left \| W \right \|^2-C\sum_{i=1}^N \beta_i\sigma _i +\sum_{i=1}^N \alpha_i\left [ 1+\sigma_i -y_iW^{\top}\varphi(X_i)-y_ib \right ] \right \}
maxΘ(α,β)=所有(W,σi,b)inf{21∥W∥2−Ci=1∑Nβiσi+i=1∑Nαi[1+σi−yiW⊤φ(Xi)−yib]}
s . t { α i ≥ 0 β i ≥ 0 s.t \left\{\begin{matrix} \alpha_i \ge 0\\ \beta_i \ge 0 \end{matrix}\right. s.t{αi≥0βi≥0
令上面问题中大括号内的内容为
L
(
w
,
σ
,
b
)
L(w,\sigma,b)
L(w,σ,b)
∂
L
∂
W
=
0
⇒
W
=
∑
i
=
1
N
α
i
y
i
φ
(
X
i
)
\frac{\partial L}{\partial W} =0\Rightarrow W=\sum_{i=1}^N\alpha_iy_i\varphi(X_i)
∂W∂L=0⇒W=i=1∑Nαiyiφ(Xi)
∂ L ∂ σ i = 0 ⇒ β i + α i = C \frac{\partial L}{\partial \sigma_i} =0\Rightarrow \beta_i+\alpha_i=C ∂σi∂L=0⇒βi+αi=C
∂ L ∂ b = 0 ⇒ ∑ i = 1 N α i y i = 0 \frac{\partial L}{\partial b} =0\Rightarrow \sum_{i=1}^N\alpha_iy_i=0 ∂b∂L=0⇒i=1∑Nαiyi=0
把上面得到的结果带入到对偶问题式子里,得
m
a
x
Θ
(
α
,
β
)
=
∑
i
=
1
N
α
i
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
K
(
X
i
,
X
j
)
s
.
t
{
0
≤
α
i
≤
c
∑
i
=
1
N
α
i
y
i
=
0
max\Theta (\alpha,\beta)=\sum_{i=1}^N\alpha_i-\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_jK(X_i,X_j)\\ s.t\left\{\begin{matrix} 0 \le \alpha_i \le c\\ \sum_{i=1}^N\alpha_iy_i=0 \end{matrix}\right.
maxΘ(α,β)=i=1∑Nαi−21i=1∑Nj=1∑NαiαjyiyjK(Xi,Xj)s.t{0≤αi≤c∑i=1Nαiyi=0
下面是上面求导中的某两步,仅供参考:
1
2
∥
W
∥
2
=
1
2
W
⊤
W
=
1
2
{
∑
i
=
1
N
α
i
y
i
φ
(
X
i
)
}
⊤
{
∑
j
=
1
N
α
j
y
j
φ
(
X
j
)
}
=
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
φ
(
X
i
)
⊤
φ
(
X
j
)
=
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
K
(
X
i
,
X
j
)
\frac{1}{2} \left \| W \right \|^2=\frac{1}{2}W^{\top}W\\ =\frac{1}{2}\left \{ \sum_{i=1}^N\alpha_iy_i\varphi(X_i) \right \} ^{\top}\left \{ \sum_{j=1}^N\alpha_jy_j\varphi(X_j) \right \} \\ =\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\varphi(X_i)^{\top}\varphi(X_j)\\ =\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_jK(X_i,X_j)
21∥W∥2=21W⊤W=21{i=1∑Nαiyiφ(Xi)}⊤{j=1∑Nαjyjφ(Xj)}=21i=1∑Nj=1∑Nαiαjyiyjφ(Xi)⊤φ(Xj)=21i=1∑Nj=1∑NαiαjyiyjK(Xi,Xj)
− ∑ i = 1 N α i y i W ⊤ φ ( X i ) = − ∑ i = 1 N α i y i { ∑ j = 1 N α j y j φ ( X j ) } ⊤ φ ( X i ) = − ∑ i = 1 N ∑ j = 1 N α i α j y i y j φ ( X j ) ⊤ φ ( X i ) = − ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( X i , X j ) -\sum_{i=1}^N\alpha_iy_iW^{\top}\varphi(X_i)\\ =-\sum_{i=1}^N\alpha_iy_i\left \{ \sum_{j=1}^N\alpha_jy_j\varphi(X_j) \right \} ^{\top}\varphi(X_i)\\ =-\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_j\varphi(X_j)^{\top}\varphi(X_i)\\ =-\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_jK(X_i,X_j) −i=1∑NαiyiW⊤φ(Xi)=−i=1∑Nαiyi{j=1∑Nαjyjφ(Xj)}⊤φ(Xi)=−i=1∑Nj=1∑Nαiαjyiyjφ(Xj)⊤φ(Xi)=−i=1∑Nj=1∑NαiαjyiyjK(Xi,Xj)
接下来要求b,要用到KKT条件:
对任意的 i = 1 ∼ N i=1\sim N i=1∼N,
①要么 β i = 0 \beta_i=0 βi=0,要么 σ i = 0 \sigma_i=0 σi=0;
②要么 α i = 0 \alpha_i=0 αi=0,要么 1 + σ i − y i W ⊤ φ ( X i ) − y i b = 0 1+\sigma_i -y_iW^{\top}\varphi(X_i)-y_ib=0 1+σi−yiW⊤φ(Xi)−yib=0。
取一个
α
i
\alpha_i
αi,满足
0
<
α
i
<
c
0< \alpha_i<c
0<αi<c,
⟹
β
i
=
c
−
α
i
>
0
,
此时
{
β
i
≠
0
⇒
σ
i
=
0
α
i
≠
0
⇒
1
+
σ
i
−
y
i
W
⊤
φ
(
X
i
)
−
y
i
b
=
0
\Longrightarrow \beta_i=c-\alpha_i>0,此时\left\{\begin{matrix} \beta_i \ne 0\Rightarrow \sigma_i=0 \\ \alpha_i \ne 0 \Rightarrow 1+\sigma_i -y_iW^{\top}\varphi(X_i)-y_ib =0 \end{matrix}\right.
⟹βi=c−αi>0,此时{βi=0⇒σi=0αi=0⇒1+σi−yiW⊤φ(Xi)−yib=0,
⇒
b
=
1
−
y
i
W
⊤
φ
(
X
i
)
y
i
=
1
−
y
i
∑
j
=
1
N
α
j
y
j
K
(
X
i
,
X
j
)
y
i
\Rightarrow b=\frac{ 1 -y_iW^{\top}\varphi(X_i)}{y_i} =\frac{1 -y_i \sum_{j=1}^N\alpha_jy_jK(X_i,X_j)}{y_i}
⇒b=yi1−yiW⊤φ(Xi)=yi1−yi∑j=1NαjyjK(Xi,Xj)
SVM算法:
①训练流程:
输入 { ( X i , y i ) } i = 1 ∼ N \left \{ (X_i,y_i) \right \} _{i=1\sim N} {(Xi,yi)}i=1∼N
(解优化问题)
最大化: Θ ( α ) = ∑ i = 1 N α i − 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( X i , X j ) \Theta (\alpha)=\sum_{i=1}^N\alpha_i-\frac{1}{2}\sum_{i=1}^N\sum_{j=1}^N\alpha_i\alpha_jy_iy_jK(X_i,X_j) Θ(α)=∑i=1Nαi−21∑i=1N∑j=1NαiαjyiyjK(Xi,Xj)
限制条件: { 0 ≤ α i ≤ c ∑ i = 1 N α i y i = 0 \left\{\begin{matrix} 0 \le \alpha_i \le c\\ \sum_{i=1}^N\alpha_iy_i=0 \end{matrix}\right. {0≤αi≤c∑i=1Nαiyi=0
算b,找一个 0 < α i < c 0<\alpha_i<c 0<αi<c, b = 1 − y i ∑ j = 1 N α j y j K ( X i , X j ) y i b=\frac{1 -y_i \sum_{j=1}^N\alpha_jy_jK(X_i,X_j)}{y_i} b=yi1−yi∑j=1NαjyjK(Xi,Xj)
②测试流程:
测试样本X
若 ∑ i = 1 N α i y i K ( X i , X ) + b ≥ 0 ,则 y = + 1 \sum_{i=1}^N\alpha_iy_iK(X_i,X)+b \ge 0,则y=+1 ∑i=1NαiyiK(Xi,X)+b≥0,则y=+1
若 ∑ i = 1 N α i y i K ( X i , X ) + b < 0 ,则 y = − 1 \sum_{i=1}^N\alpha_iy_iK(X_i,X)+b < 0,则y=-1 ∑i=1NαiyiK(Xi,X)+b<0,则y=−1。
限制条件: { 0 ≤ α i ≤ c ∑ i = 1 N α i y i = 0 \left\{\begin{matrix} 0 \le \alpha_i \le c\\ \sum_{i=1}^N\alpha_iy_i=0 \end{matrix}\right. {0≤αi≤c∑i=1Nαiyi=0
算b,找一个 0 < α i < c 0<\alpha_i<c 0<αi<c, b = 1 − y i ∑ j = 1 N α j y j K ( X i , X j ) y i b=\frac{1 -y_i \sum_{j=1}^N\alpha_jy_jK(X_i,X_j)}{y_i} b=yi1−yi∑j=1NαjyjK(Xi,Xj)
②测试流程:
测试样本X
若 ∑ i = 1 N α i y i K ( X i , X ) + b ≥ 0 ,则 y = + 1 \sum_{i=1}^N\alpha_iy_iK(X_i,X)+b \ge 0,则y=+1 ∑i=1NαiyiK(Xi,X)+b≥0,则y=+1
若 ∑ i = 1 N α i y i K ( X i , X ) + b < 0 ,则 y = − 1 \sum_{i=1}^N\alpha_iy_iK(X_i,X)+b < 0,则y=-1 ∑i=1NαiyiK(Xi,X)+b<0,则y=−1。














 803
803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









