









- 解决的优化问题
无约束非线性规划问题
2. 梯度下降法优化方法
梯度下降法
梯度就是表示某一函数在该点处的方向导数沿着该方向取得最大值。这个概念比较抽象,我们拿下山做比较,一个人站在山上的某个山腰处,想要以最快的速度下山,那么该怎么最快下山呢?他只要每次沿着当前位置最陡峭最易下山的方向前进一小步,然后继续沿下一个位置最陡方向前进一小步。这样一步一步走下去,一直走到觉得我们到了山脚的位置。那么下山最陡的方向就是梯度的负方向,这种方法就是梯度下降法。
如函数:
的梯度就是:
那么对于如何使用梯度下降算法呢?就是先选择一个初始点,计算该点的梯度,然后按照梯度的方向更新自变量,直到函数的值变化很小或者达到最大迭代次数为止。
如函数:
举例,若k次迭代值为
那么
的梯度下降法的应用就是
其中alpha称为步长或者学习率,表示每次迭代更新变化的大小。直到函数值变化非常小或者达到最大迭代次数时停止,此时认为函数达到极小值点。
注意到
有泰勒展开
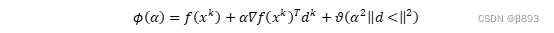
3.梯度下降 方法的实验
(1)实验的结果:
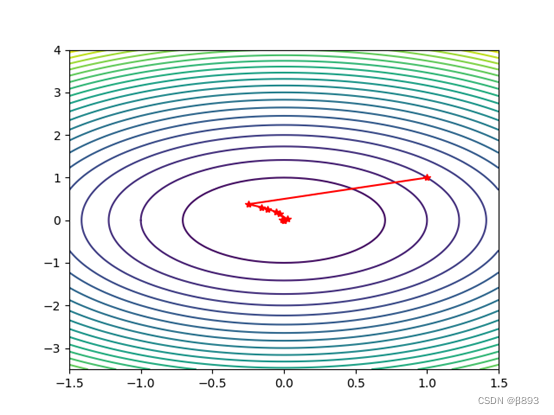
①初始点为:[1 1]
1 [ 1 20]
2 [2. 3.84718175]
3 [3. 0.37130265]
4 [4. 0.21568921]
5 [5.00000000e+00 1.42903966e-03]
6 [6.00000000e+00 6.26255913e-04]
迭代次数为: 7
近似最优解为:[-0.00042867 0.00034431]
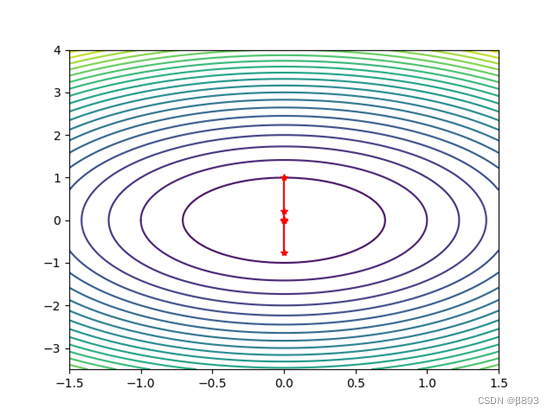
②初始点为:[0 1]
1 [1 4]
2 [2. 1.21662692]
3 [3. 0.6533163]
4 [4. 0.05357185]
5 [5. 0.02861024]
6 [6.00000000e+00 4.29149055e-03]
7 [7.00000000e+00 2.42993682e-04]
迭代次数为: 8
近似最优解为:
[ 0. -0.00068457]
(2)实验的结果分析:


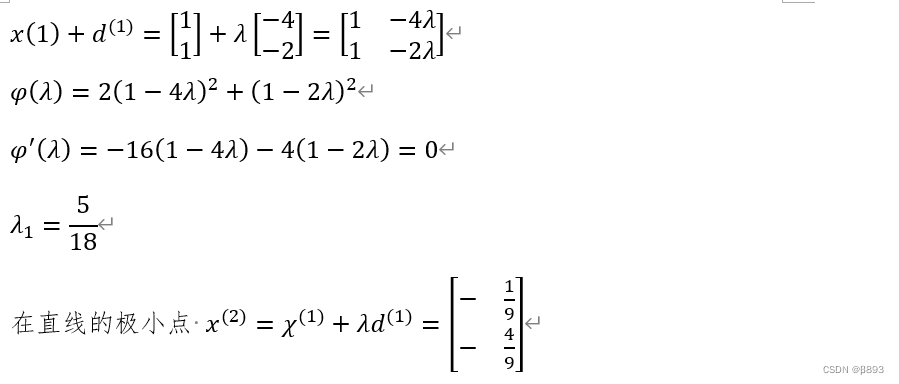

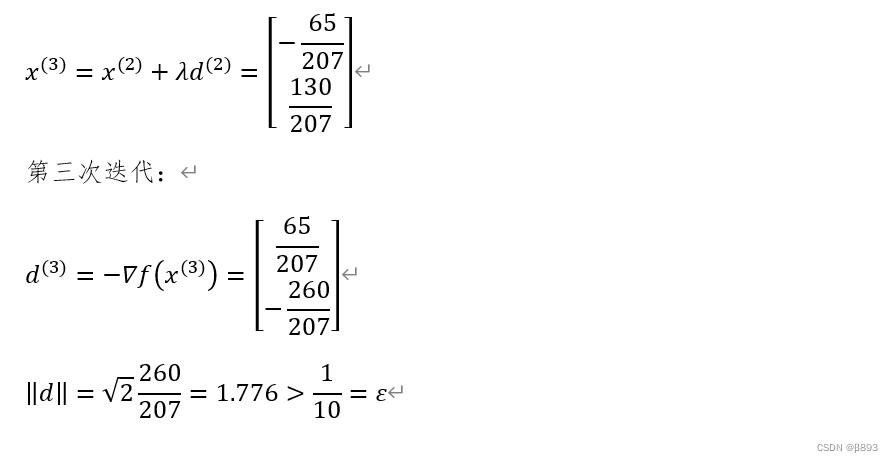
import random
import numpy as np
import matplotlib.pyplot as plt
"""
最速下降法
函数 f(x) = 2*x(1)^2+x(2)^2
梯度 g(x)=(4*x(1)),2*x(2))^(T)
"""
def goldsteinsearch(f, df, d, x, alpham, rho, t):
'''
线性搜索子函数
数f,导数df,当前迭代点x和当前搜索方向d
'''
flag = 0
a = 0
b = alpham
fk = f(x)
gk = df(x)
phi0 = fk
dphi0 = np.dot(gk, d)
# print(dphi0)
alpha = b * random.uniform(0, 1)
while (flag == 0):
newfk = f(x + alpha * d)
phi = newfk
# print(phi,phi0,rho,alpha ,dphi0)
if (phi - phi0) <= (rho * alpha * dphi0):
if (phi - phi0) >= ((1 - rho) * alpha * dphi0):
flag = 1
else:
a = alpha
b = b
if (b < alpham):
alpha = (a + b) / 2
else:
alpha = t * alpha
else:
a = a
b = alpha
alpha = (a + b) / 2
return alpha
def rosenbrock(x):
# 函数:f(x) = 2*x(1)^2+x(2)^2
return 2 * x[0] ** 2 + x[1] ** 2
def jacobian(x):
# 梯度 g(x)=(4*x(1)),2*x(2))^(T)
return np.array([4 * x[0], 2 * x[1]])
def steepest(x0):
print('初始点为:')
print(x0, '\n')
imax = 20000
W = np.zeros((2, imax))
epo = np.zeros((2, imax))
W[:, 0] = x0
i = 1
x = x0
grad = jacobian(x)
delta = sum(grad ** 2) # 初始误差
f = open("最速.txt", 'w')
while i < imax and delta > 10 ** (-5):
p = -jacobian(x)
x0 = x
alpha = goldsteinsearch(rosenbrock, jacobian, p, x, 1, 0.1, 2)
x = x + alpha * p
W[:, i] = x
epo[:, i] = np.array((i, delta))
f.write(str(i) + " " + str(delta) + "\n") #
print(i, np.array((i, delta)))
grad = jacobian(x)
delta = sum(grad ** 2)
i = i + 1
print("迭代次数为:", i)
print("近似最优解为:")
print(x, '\n')
W = W[:, 0:i] # 记录迭代点
return [W, epo]
if __name__ == "__main__":
X1 = np.arange(-1.5, 1.5 + 0.05, 0.05)
X2 = np.arange(-3.5, 4 + 0.05, 0.05)
[x1, x2] = np.meshgrid(X1, X2)
f = 2 * x1 ** 2 + x2 ** 2
plt.contour(x1, x2, f, 20) # 画出函数的20条轮廓线
x0 = np.array([1, 1])
list_out = steepest(x0)
W = list_out[0]
epo = list_out[1]
plt.plot(W[0, :], W[1, :], 'r*-') # 画出迭代点收敛的轨迹
plt.show()
















 2270
2270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











