






一、 梯度下降法的定义
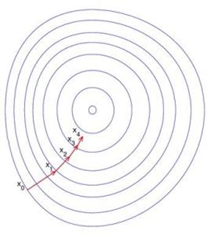
梯度下降法是一个最优化算法,通常也称为最速下降法。最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现在已经不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的。最速下降法是用负梯度方向为搜索方向的,最速下降法越接近目标值,步长越小,前进越慢。可以用于求解非线性方程组。
二、 基础知识解剖
●梯度
以二元函数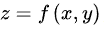 为例,假设其对每个变量都具有连续的一阶偏导数
为例,假设其对每个变量都具有连续的一阶偏导数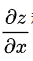 和
和 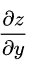 ,则这两个偏导数构成的向量
,则这两个偏导数构成的向量 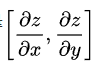 即为该二元函数的梯度向量,一般记作
即为该二元函数的梯度向量,一般记作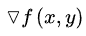 ,其中 读作“Nabla”。根据这个概念,我们来看几个多元函数求梯度的例子:
,其中 读作“Nabla”。根据这个概念,我们来看几个多元函数求梯度的例子:

在一元函数中,梯度其实就是微分,既函数的变化率,而在多元函数中,梯度变为了向量,同样表示函数变化的方向,从几何意义来讲,梯度的方向表示的是函数增加最快的方向,这正是我们下山要找的“最陡峭的方向”的反方向!因此后面要讲到的迭代公式中,梯度前面的符号为“-”,代表梯度方向的反方向。在多元函数中,梯度向量的模(一般指二模)表示函数变化率,同样的,模数值越大,变化率越快。
●学习率
学习率也被称为迭代的步长,优化函数的梯度一般是不断变化的(梯度的方向随梯度的变化而变化),因此需要一个适当的学习率约束着每次下降的距离不会太多也不会太少。
三、 梯度下降算法原理
(1) 梯度下降的分类
在具体使用梯度下降法的过程中,主要有以下几种不同的变种,即:batch、mini-batch、SGD和online。其主要区别是不同的变形在训练数据的选择上。
① batch gradient descent
批梯度下降法(Batch Gradient Descent)针对的是整个数据集,通过对所有的样本的计算来求解梯度的方向。损失函数为:
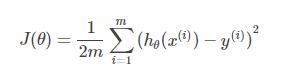

在批梯度的优化过程中,对每一个样本都需要计算其梯度,批梯度的优化过程为:

② mini-batch gradient descent
批梯度方式针对大数据量时,花费时间巨大,所以在每次迭代过程中利用部分样本代替所有的样本。便出现了mini-batch的思想,假设训练集中的样本的个数为n,则每个mini-batch只是其一个子集,假设,每个mini-batch中含有b个样本,这样,整个训练数据集可以分为n/b个mini-batch。
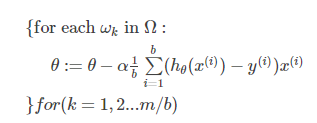
③ stochastic gradient descent
随机梯度下降算法(stochastic gradient descent)可以看成是mini-batch gradient descent的一个特殊的情形,即在随机梯度下降法中每次仅根据一个样本对模型中的参数进行调整,等价于上述的b=1情况下的mini-batch gradient descent,即每个mini-batch中只有一个训练样本。
随机梯度下降法的优化过程为:
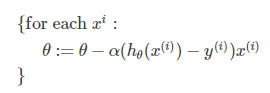
BGD在每次更新模型的时候,都要使用全量样本来计算更新的梯度值。如果有m个样本,迭代n轮,那么需要是m*n的计算复杂度。
SGD在每次更新模型的时候,只要当前遍历到的样本来计算更新的梯度值就行了。如果迭代n轮,则只需要n的计算复杂度,因为每轮只计算一个样本。
以上就是BGD和SGD的区别,容易看出,BGD的优势在于计算的是全局最优解,效果较SGD会好一些,劣势在于计算开销大;SGD则相反,优势在于计算开销减小很多,劣势在于计算的是局部最优解,可能最终达不到全局最优解。在数据量大的时候,SGD是较好的折中选择。
④ online gradient descent
在线梯度下降法(Online gradient descent)对于所有训练数据只用一次,然后丢弃。每次根据实时的数据计算梯度,进而调整模型中的参数。
online learning强调的是学习是实时的,流式的,每次训练不用使用全部样本,而是以之前训练好的模型为基础,每来一个样本就更新一次模型,这种方法叫做OGD(online gradient descent)。这样做的目的是快速地进行模型的更新,提升模型时效性。
online learning其实细分又可以分为batch模式和delta模式。batch模式的时效性比delta模式要低一些。分析一下batch模式,比如昨天及昨天的数据训练成了模型M,那么今天的每一条训练数据在训练过程中都会更新一次模型M,从而生成今天的模型M1。
而batch learning或者叫offline learning强调的是每次训练都需要使用全量的样本,因而可能会面临数据量过大的问题。后面要讨论的批量梯度下降法(BGD)和随机梯度下降法(SGD)都属于batch learning或者offline learning的范畴。
batch learning一般进行多轮迭代来向最优解靠近。online learning没有多轮的概念,如果数据量不够或训练数据不够充分,通过copy多份同样的训练数据来模拟batch learning的多轮训练也是有效的方法。
几种方法优缺点的对比:
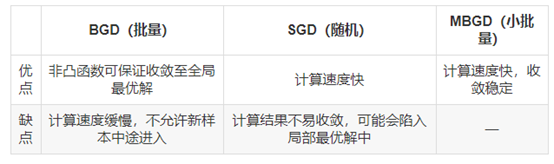
有研究发现,当逐渐减小SGD方法使用的学习率时,可以保证SGD解的收敛性,但不一定保证收敛至全局最优解。此外,许多深度学习方法所使用的求解算法都是基于MBGD的,该方法一个算不上缺点的“缺点”就是需要找到合适的参与梯度计算的样本规模,对于超过2000个样本的较大数据集而言,参与计算的样本规模建议值为2^6至 2^8。
(2) 梯度下降的算法框架
















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









