







Intern-VL
Intern-VL的发布时间晚于BLIP2和LLAVA,因此在表征问题上做了新的创新。
论文动机和做法:
论文指出,现有的视觉对齐文本的方式:Q-former,linear projection(比如MLP) ,在表征上有以下的问题:
(1) 参数尺度的差异。大型 LLM 可以达到几百B个参数,而广泛使用的视觉编码器的参数量(如Vit-Huge)仍然在1B左右,甚至更小。这种差距可能导致 LLM 的能力利用不足。
(2) 表征的不一致性。视觉模型一般是在纯视觉数据上训练或者对齐的,经常表现出与 LLM 的表示不一致。
(3)连接效率低下。仅通过简单的随机初始化的轻量级的层,无法真正的捕获模型交互,无法获取到丰富的信息,影响内容理解和生成的质量。
而Intern-VL将放大的视觉编码器的表示与 LLM 结合起来,并在各种视觉和视觉语言任务中实现最先进的性能。
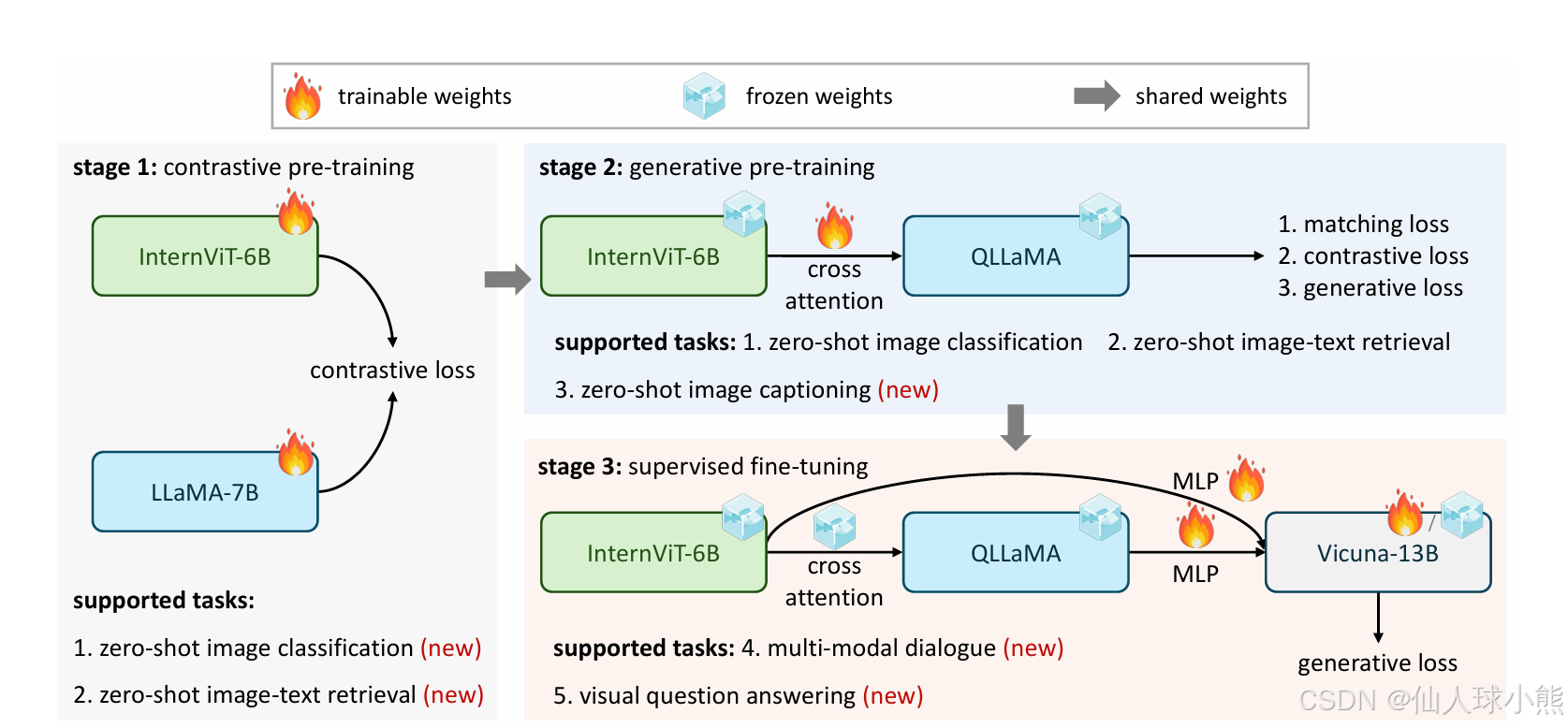
图:InternVL 模型的训练策略。它包括视觉-语言的对比训练、预训练和SFT三个阶段。这些阶段有效地利用了来自不同来源的公共数据,从网络上嘈杂的图像 - 文本对到高质量的标题、 VQA 和多模态对话数据集。
如上图stage3所示,InternVL有三个关键的设计:
(1) 参数平衡的视觉和语言组件:它包括一个6B的视觉编码器和一个具有8B参数的 “LLM 中间件”,其中中间件作为一个 “胶水” 层,重新组织基于用户命令的视觉特性。大尺度的视觉编码器和中间件为对比和生成任务提供了灵活的组合。
(2) 一致的表征: 为了保持视觉编码器和 LLM 之间表征的一致性,我们使用 LLaMA 来初始化中间件并将视觉编码器与其对齐。
(3) 渐进式图文对齐: 我们利用不同来源的图文数据,通过渐进式对齐策略确保训练的稳定性。该策略首先对大规模有噪声的图文数据进行对比学习,然后对细粒度数据进行生成学习。这种方法确保了模型性能和任务范围的一致增强。
QLLAMA(LLM中间件)的详解:
提出了一种语言中间件 QLLaMA 来调整视觉特征和语言特征。
QLLaMA 是基于预训练的多语言LLM: LLaMA(7B参数)开发的,并且随机初始化了 96 个可学习的查询和交叉注意层 (1B参数)。
这种方法使得 QLLaMA 平稳地将可视化元素集成到语言模型中,从而增强了组合特征的一致性和有效性。
与使用轻量级的 “胶水” 层,如 Q-Former 和 线性层 来连接视觉编码器和 LLM,我们的方法有三个优点:
(1) Q-Former和MLP的随机初始化的,而QLLAMA是基于预训练的LLM,因此 QLLaMA 可以将由 InternViT-6B 生成的图像tokens 平滑地转换为与 LLM 对齐的表示。
(2) QLLaMA 具有 80 亿视觉语言对齐参数,其比 QFormer 大 42 倍。因此,即使采用冻结的 LLM 解码器,InternVL 也能在多模态对话任务中取得良好的性能。
(三) QLLaMA也可以被应用于对比学习,为图文对齐任务提供强大的文本表示,如zero-shot 分类 和图像检
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











