







1、主要解决问题:
移动机器人在面对动态障碍物时,环境感知往往面临更大的挑战。如果采用简单传感器(如RGB相机或者2D激光雷达)无法对障碍物运动进行精确感知(图1),因此基于深度强化学习的方法计算出的瞬时机器人速度不能满足动态环境下避障要求。如果采用深度图像或者3D激光雷达等传感器,虽然感知信息更加全面,但是将传感器的高维数据作为输入来检测和观察障碍,会增加了神经网络的训练成本。
动态窗口方法(DWA)是一种经典的导航算法,它考虑了机器人的动力学约束,并保证在一个时间范围内的动态窗口空间中机器人是无碰撞的。然而,DWA的公式只考虑了机器人在当前时刻的传感器数据来进行决策。

图1 Turtlebot在移动人群的真实环境中运行
本文提出了一种混合方法DWA-RL,它结合了DWA和基于DRL的避障方法。我们提出了一种基于DRL的避障策略,该策略设计一种新的观察空间公式和一种新的奖励函数,帮助机器人生成无碰撞的、动态可行的导航速度。
2、研究方法:
首先通过计算机器人在一个时刻的可行速度和在过去n个时刻内使用这些速度所对应的成本来构造观测空间,这种方式构造出的观测空间纬度低,也显著降低训练时间,并且更容易将训练后的策略迁移到真实环境。状态空间包含离散化的机器人速度集合[v,ω],根据障碍物与速度集合中的速度模拟后轨迹的关系计算出的障碍物成本,以及根据速度集合中的速度模拟后位置与目标位置差异计算出的目标对齐成本。然后将障碍物成本和目标对齐成本相加得到总成本,按照总成本升序排列,机器人速度集合会按照与总成本一一对应关系进行排序,将排序后的速度集合作为动作空间(图2)。
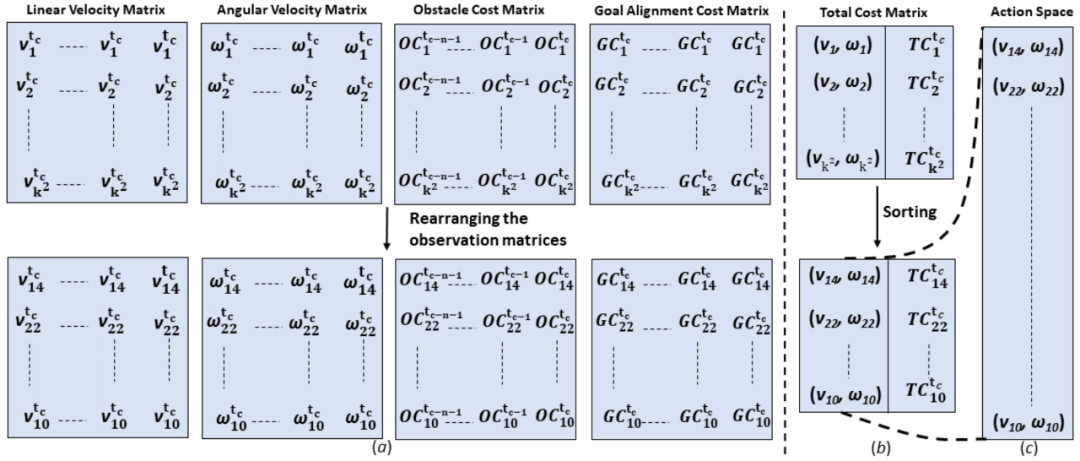
图2 (a)观测空间;(b)根据成本对速度进行排序;(c)动作空间
其次,按照障碍物与机器人位置关系重新设计奖励函数。奖励函数包含按照机器人是否到达目标点和是否碰撞设置的奖惩函数,按照安全区域(如图3所示)划分的奖惩函数,以及按照激光雷达扫描到的障碍物设置的奖惩函数。
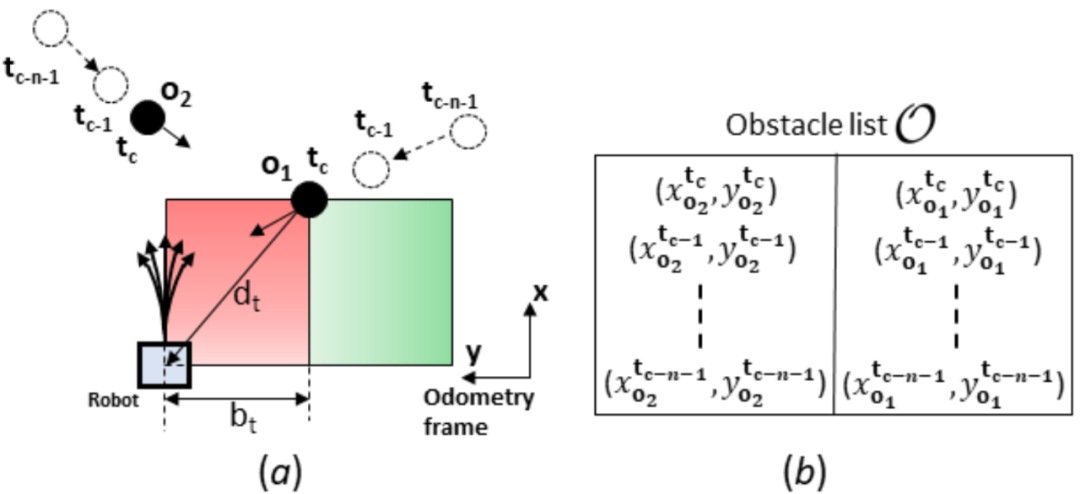
图3 机器人与障碍物位置关系
本文设置了三种评价指标,成功率、平均轨迹长度和平均速度,并且在Gazebo环境下分别设置静态和动态的障碍物训练机器人,最后在四种环境下测试了机器人的三项指标。四种环境分别为锯齿形静态场景、锯齿形动态场景、稀疏动态场景和密集动态场景。
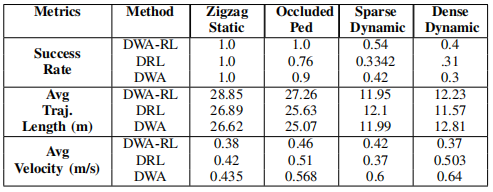
表1 DWA-RL、DWA和DRL在不同场景下的表现
由表1可得,三种方法的成功率在锯齿形静态场景中都表现良好。在有移动障碍物的环境中,DWA-RL发生碰撞的次数明显减少,因为DWA-RL考虑了障碍物随时间的运动,并计算了避开障碍物前面危险区域的速度。并且DWA-RL在实现较高成功率的同时,保持了和其他方法相近的平均轨迹长度和速度。
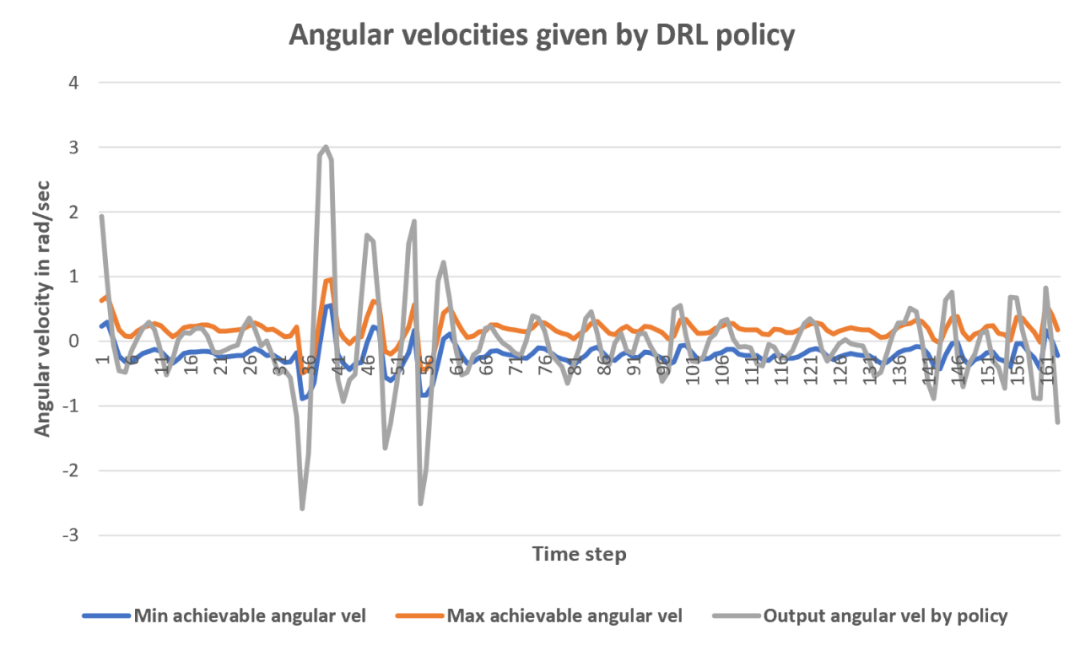
图4 其他方法产生的角速度变化的图表
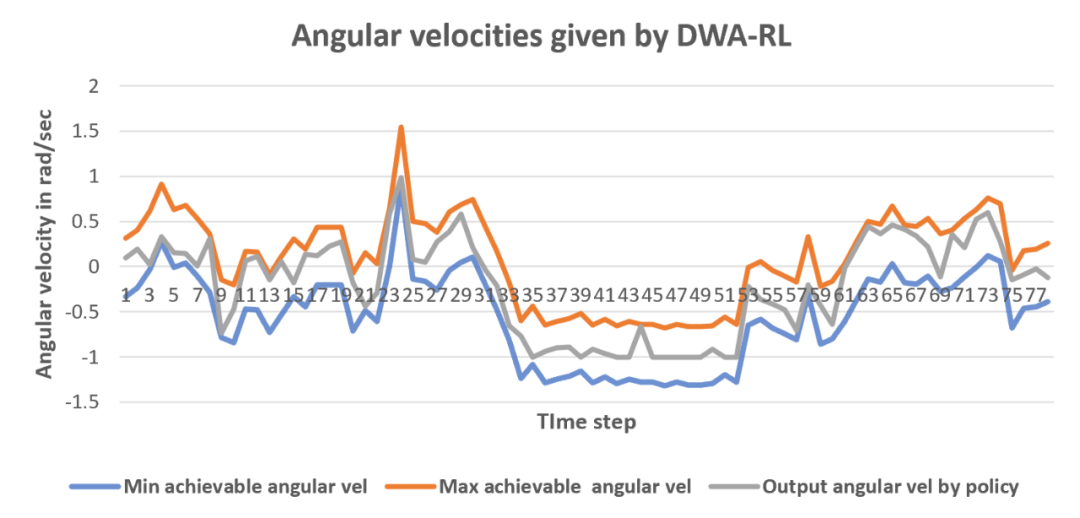
图5 DWA-RL产生的角速度变化的图表
由图4和图5可以看出,其他方法输出角速度有61%超出了机器人最大和最小角速度之外,会导致机器人运动过程中振荡和抖动,DWA-RL产生的角速度总是在可达到的速度范围内。
3、结论:
本文提出了一种基于深度强化学习的策略来计算机器人在移动障碍物中导航的动态可行速度。本文的方法结合了DWA的优点,以满足机器人的动力学约束,结合基于DRL的导航方法,可以很好地处理移动的障碍和行人。首先通过将环境障碍物的运动嵌入到一个新的低维观测空间,降低状态空间维度;其次设计了一种新的奖励函数帮助机器人远离障碍物的前进方向,从而显著减少碰撞次数。本文在三维仿真环境中训练和测试了三种方法,将DWA-RL的方法与其他避障方法进行了比较,并观察到在成功率和运动平滑度方面有显著的改进。

















 4861
4861

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









