







《DRL-based Motion Control for Unmanned Surface Vehicles with Environmental Disturbances》
第六届IEEE国际无人系统大会(ICUS)
该论文主要研究无人船在海上风浪环境的运动控制不够精确的问题,提出了一种基于深度强化学习的运动控制方法。
论文提出了一种基于深度强化学习的运动控制方法(TD3-PI),整体的方法框架如图1所示。本算法在PI控制算法的基础上添加了强化学习的调参机制,首先,无人船控制系统将舵角和基于LOS算法计算出来的航向角偏差作为状态空间输入到深度强化学习算法TD3(Twin Delayed Deep Deterministic Policy Gradient)中。其次,TD3算法输出PI控制器的参数Kp和Ki,实现对PI控制器的实时调参。最后,利用新的控制器参数Kp和Ki计算出新的控制舵角,实现无人船精确控制。

图 1 TD3-PI方法的框架
TD3算法是DDPG算法(Deep Deterministic Policy Gradient)的改进算法,整体的算法框架如图2所示。通过引入双层Q网络、目标策略平滑化和延迟更新网络的机制,有效避免了DDPG算法的过估计和振荡的缺点。

图2 TD3算法框架
TD3算法的状态空间,动作空间和奖励函数的设置如下。其中航向角偏差和控制舵角构成了算法的状态空间,PI控制器的参数Kp和Ki构成了算法的动作空间,根据系统的特性,对动作空间Kp和Ki进行了裁剪。算法的奖励函数与航向角构成指数关系。
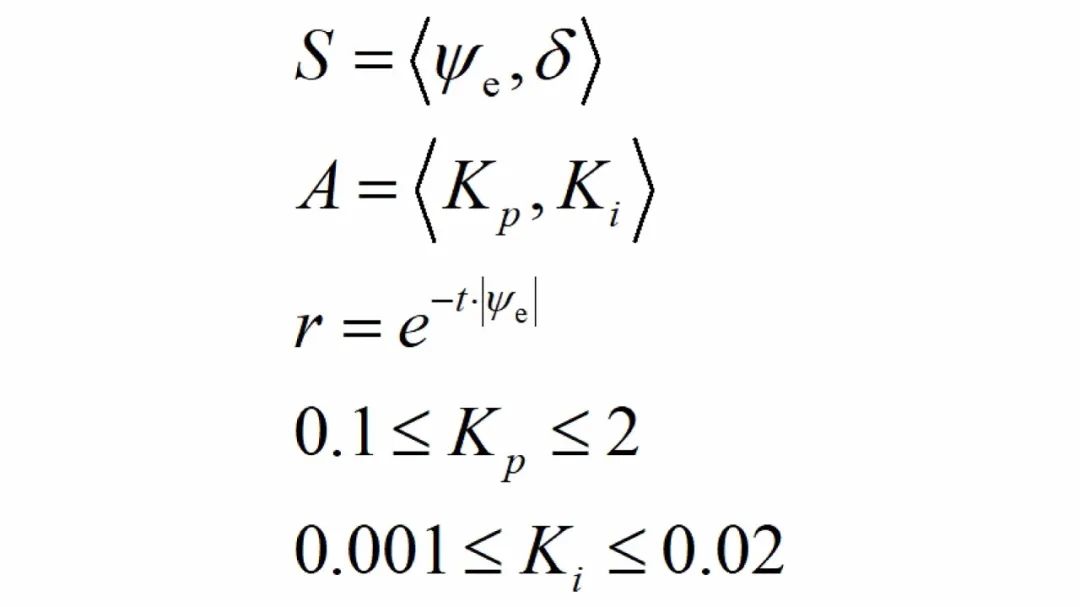
如图3所示,在ROS中搭建了无人船的仿真平台,并加入风浪的环境参数模型(图中可以明显看出浪对无人船的影响),对无人船在风浪环境下进行航向角转角训练。

图3.无人船的仿真环境
训练完成后,设置了航向角实验和轨迹跟踪实验以验证算法的可行性和有效性。在航向角实验中,分别设置了三十度和九十度的期望航向角,得出了两种算法的响应曲线,如图4所示。在没有风浪的环境下,PI算法和TD3-PI方法都实现了航向角的精确控制,然而在添加了风浪模型后,PI和TD3-PI的响应曲线都出现了振荡,但是TD3-PI的振荡幅度和频率比PI低得多,且在超调量和稳态误差这两个指标上也表现得更好。在如图5所示的轨迹跟踪实验中,在风浪环境下PI算法控制的无人船轨迹距离理想路径较TD3-PI方法有着更大的偏差,且在转弯时出现了惯性过大的现象。而TD3-PI算法表现得更好,有着更小的最大跟踪误差和跟踪时间。上述两个实验说明TD3-PI算法相比于PI算法具有更好的环境适应性,更适合在风浪环境下对无人船进行精确控制。

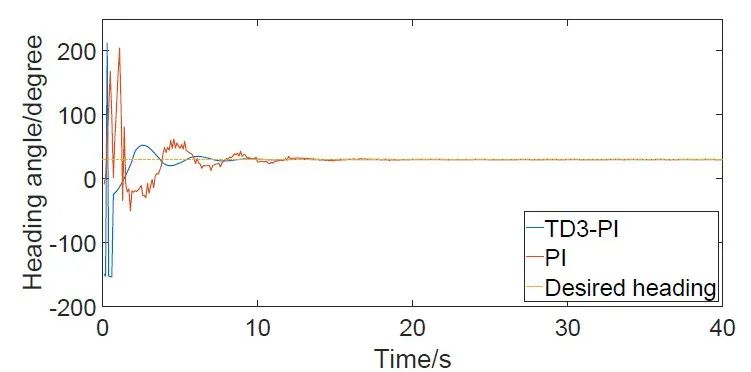
图4 三十度期望航向角实验

图5 轨迹跟踪实验















 1383
1383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









