







本文主要对文章:“CrossLoc: Scalable Aerial Localization Assisted by Multimodal Synthetic Data”中的合成数据生成工具:TOPO-DataGen的学习和记录
topogen示意图
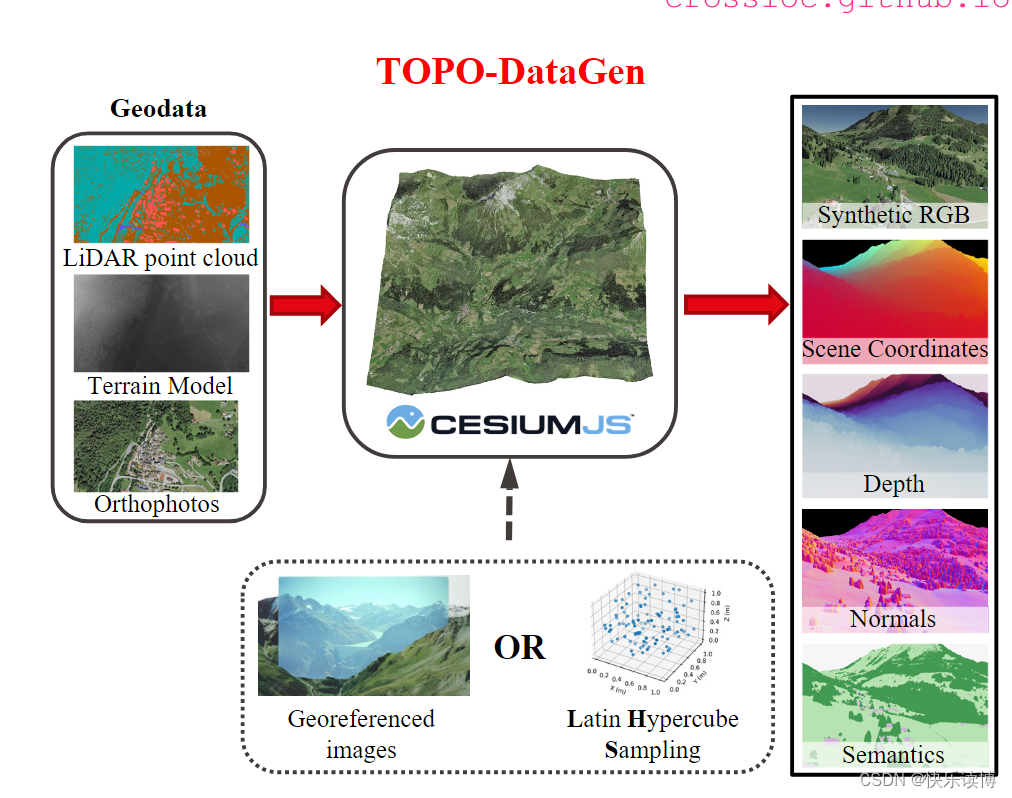
topo-gen论文中描述的工作原理
1.地理数据的预处理:
我们可以通过TOPO-Datagen基于可用的地理数据(分类的雷达点云、正射影像和数字地型模型)在感兴趣区域生成高保真的3D纹理模型。我们对现成的地理数据进行预处理,使其与开源地理空间渲染引擎CesiumJS兼容,这是我们工作的核心。
举个例子:一种常见的做法是将做坐标参考系统从局部系统转化为全局WGS84。来自国家机构的高质量开放地理数据越来越普遍,也更容易获得感兴趣区域的3D模型,并使用我们的方法来进行虚拟数据的合成。而且开源的地理数据大部分来自航天器比如卫星,这样合成的数据更有利于无人机的空中定位和导航。
2.合成数据的生成:
在WGS84参考系统中生成的3D纹理模型是CesiumJS引擎进行合成数据生成的输入。给定虚拟相机视角,我们提出的TOPO-DataGen提供了一系列与视觉定位相关的设计师模式,包括:RGB图像、WGS84参考系统(即地心固定坐标系)中的场景坐标、深度、表面法线和语义。具体来说,通过光线追踪[10],我们的工作流程生成了合成RGB图像和地理参考场景坐标作为原始输出。随后,我们通过将每个像素与其在分类地理数据(即分类的LiDAR点云)中的最近点进行匹配来获取语义地图。我们使用PyTorch[41]框架来加速矩阵计算。最后,基于场景坐标标签,我们生成其他3D模态,即深度和表面法线。遵循[69],我们提供了z缓冲区深度,并使用Open3D[74]计算表面法线。
数据渲染可以在一个大面积上离线进行,其大小受到计算机硬件和可用地理数据的限制。为了从头开始生成合成数据,例如扫描一个特定区域,我们使用LHS(拉丁超立方抽样)[25, 39]来进行尽可能少但高效的相机视角采样。否则,也可以使用任何带有真实地理标签的照片来生成匹配的合成模态,如图2所示(从左到右)。
TOPO-DataGen 生成的合成模式示例。我们的工作流程在真实世界和虚拟世界之间无缝遍历,以相机姿势为条件:从最左边的真实地理标记的照片中,我们可以生成一组丰富的匹配合成模式,包括合成 RGB 图像、场景坐标、深度、表面法线和语义。

3.质量控制:
多模态合成数据的质量本质上取决于三维模型地理参考的精度和图像像素场景坐标射线跟踪的精度。有关提供的基准数据集的详细案例研究,请参阅补充(在第 4 节中介绍)。
4.基准数据集:
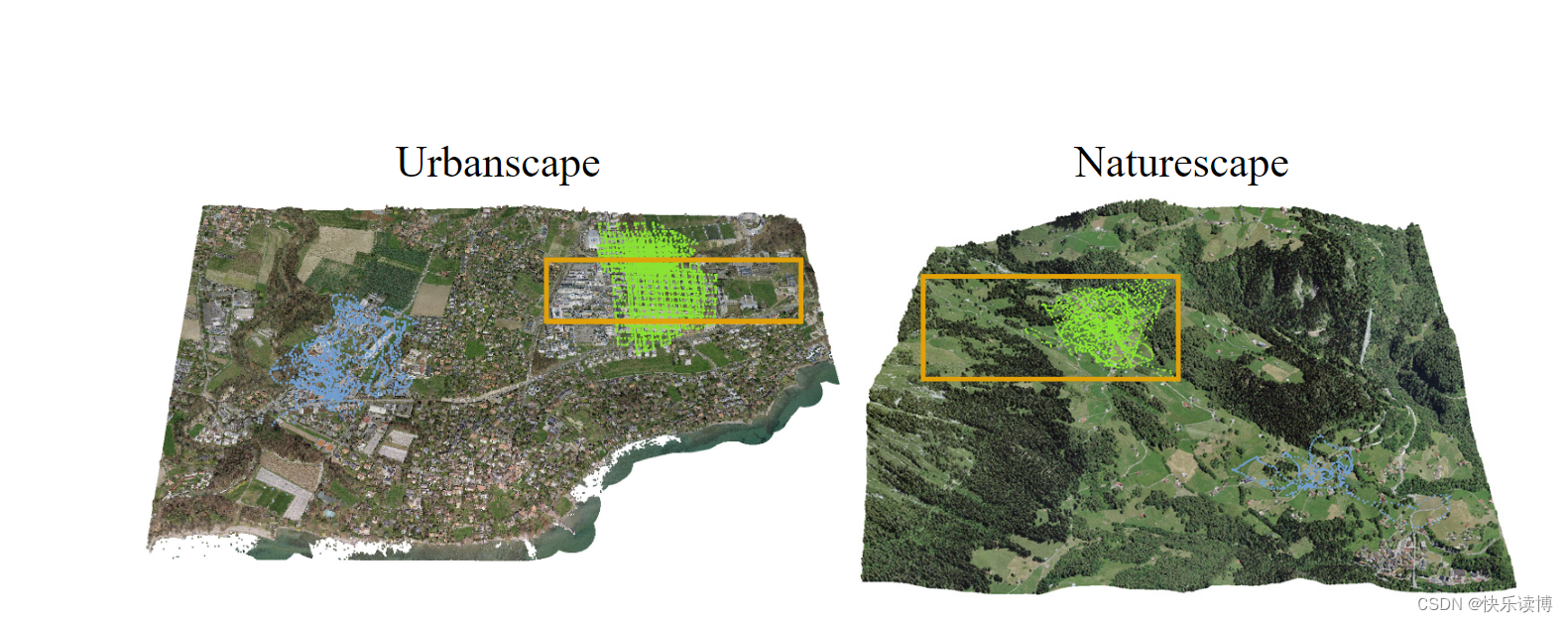
我们引入了两个大规模的模拟到现实基准数据集,以展示TOPO-DataGen数据集统计信息的实用性。表1显示了基准数据集的统计信息,这些统计信息分布在两个不同的景观中:城市景观(Urbanscape)和自然景观(Naturescape)。对于每种景观,我们提供了三个场景的数据:LHS-sim、In-place和Out-of-place,所有这些场景都附带合成2D图像、多模态3D标签和语义地图,如图2所示。特别地,In-place和Out-of-place场景包括通过配备厘米级实时动态(RTK)定位的DJI Phantom 4无人机捕获的精确地理标签的真实照片。[2] In-place场景与LHS-sim场景高度重叠,而Out-of-place场景描述了一个与LHS-sim相邻但非重叠的环境。图3显示了数据集的3D纹理模型和相机位置分布。
在提出的数据集中,所有模态(包括真实和合成图像)的数据分辨率都设置为高度480像素和宽度720像素。语义标签有七个类别:天空、地面、植被、建筑、水体、桥梁和其他。按照[29]的方法,我们通过坐标重投影误差来评估合成3D标签的准确性。城市景观(Urbanscape)和自然景观(Naturescape)数据集的平均绝对重投影误差分别为1.19像素和1.04像素,显示了室外航空数据集的高精度。更多误差分析可以在补充材料中找到。
数据集划分:我们将In-place和Out-of-place场景的数据随机划分为训练集(40%)、验证集(10%)和测试集(50%)。至于LHS-sim场景的数据,它被划分为训练集(90%)和验证集(10%)。我们有意制定了一个具有挑战性的视觉定位任务,即使用比训练集更多的真实数据进行测试,以更好地研究真实数据稀缺性的缓解问题。请注意,表1中所示的真实图像密度低于许多可用的基于室外城市街道的视觉定位数据集,如Cambridge [32]和Aachen [49, 50]。
图3:3D纹理模型用于通过LHS采样或匹配真实飞行轨迹来渲染具有合成模态的基准数据集。In-place数据和Out-of-place数据的相机位置分别用绿色和蓝色表示,LHS合成数据采样边界用橙色框标出。
实验部分:
比较的基线模型:
我们提出的算法与两种最先进的场景坐标回归基线进行了比较:DSAC* [17] 和从 [71] 改编而来的模拟到真实坐标回归DDLoc。我们遵循ARC [71]的架构,以最小的修改来训练一个用于坐标而非深度的回归器;具体细节请参见补充材料。为了公平比较,所有基于坐标回归的方法都使用了DSAC* [17]中的PnP求解器来计算相机姿态。此外,我们的方法还与AtLoc [64]进行了比较,AtLoc是一种最先进的绝对姿态回归(APR)方法。请注意,AtLoc在训练过程中不使用任何3D标签,并且可学习的信息要少得多。
相机定位结果:
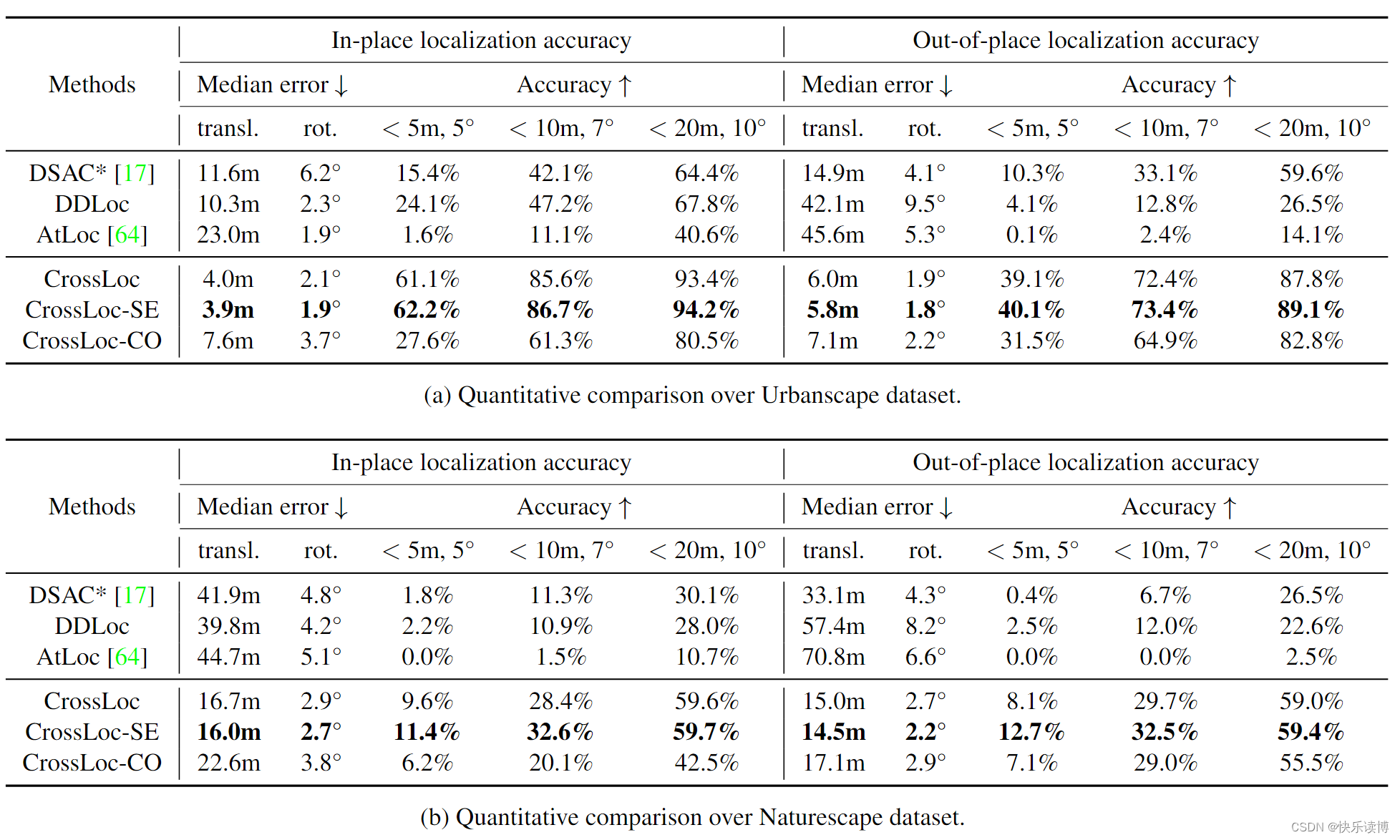
定量结果: 表3列出了在Urbanscape和Naturescape数据集上进行姿态估计的详细比较。CrossLoc算法明显优于其他两种坐标回归方法,这展示了跨模态表示学习的卓越性能。值得注意的是,基于2D图像的APR基线方法AtLoc [64]的性能逊于任何基于结构的方法。这并不令人意外,因为APR在实践中往往从训练数据中泛化得更差[51]。我们还提供了使用不同视觉表示的CrossLoc算法的结果,即仅应用坐标回归特征的CrossLoc-CO和使用额外语义分割特征的CrossLoc-SE(参见表2)。添加辅助的深度和表面法线视觉特征极大地提升了模型性能。然而,与普通的CrossLoc相比,使用外部语义标签的CrossLocSE性能提升有限。这表明引入具有较少几何信息的额外标签可能不会对场景坐标学习产生显著帮助。这一发现也与近期关于多任务学习一致性的研究工作[43, 57, 68, 69]相一致。在Naturescape上的定位精度不如Urbanscape高。我们推测这是由于Naturescape中具有独特几何形状的人造特征(如建筑物)较少。此外,如表1所述,实际训练数据密度的显著降低也使得定位任务变得更加困难。
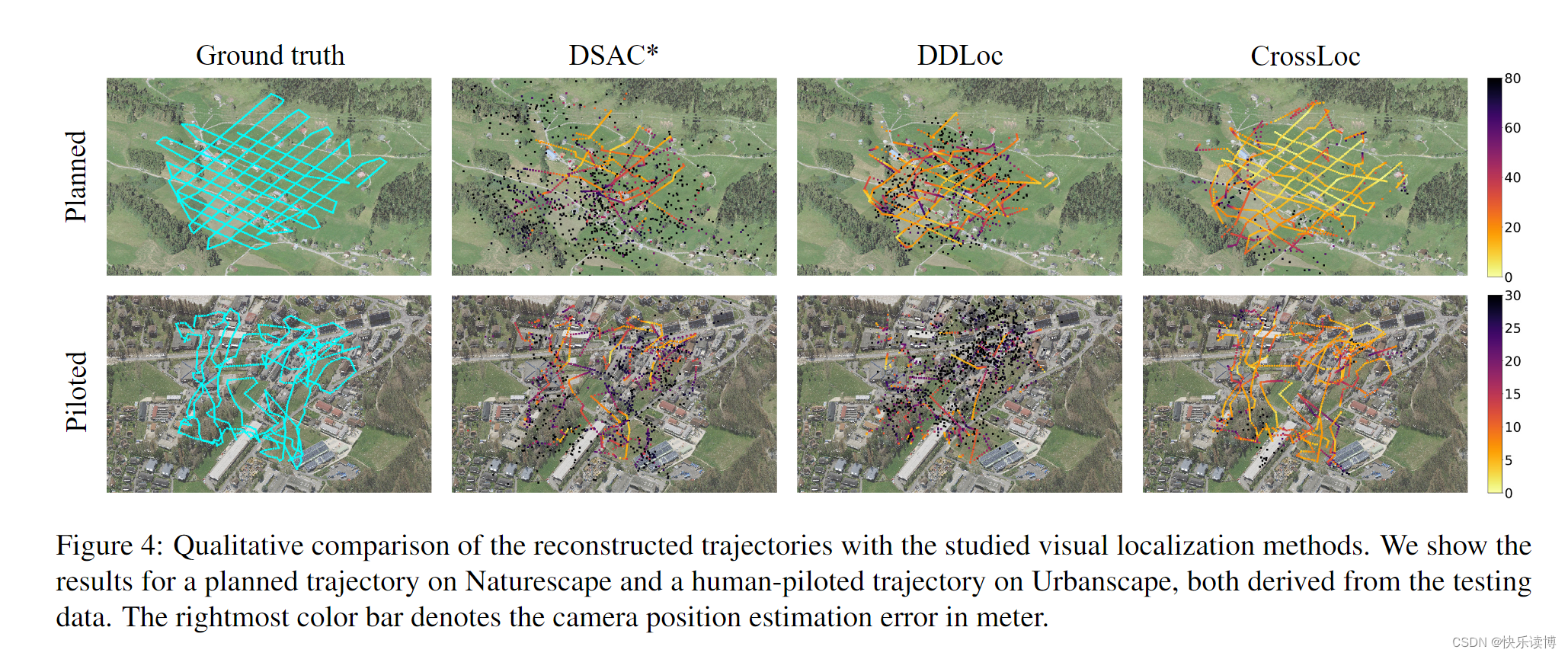
定性结果: 图 4 分别显示了 Naturescape 和 Urbanscape 数据集中两个飞行轨迹的姿态估计结果。我们的 CrossLoc 优于其他定位算法,从而产生更完整的轨迹重建,异常值要少得多。















 377
377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









