







截止到今日,差不多对深度学习有了一定了解了,从图像分类的各种神经网络再到YOLO系列的目标检测,一步一步的逐渐实现相应功能,但对于一些具体的代码细节、部分理论,后期可能还需要加强学习和理解。
但是转眼也快开学了,时间也变得有点紧,所以这一方面的技术学习要先暂停一段时间了,等度过这一段时间,自己会重新拿起,训练出自己所需要的模型。
本篇博文主要解析YoLoV3,自己来来回回看了好几遍才明白个大概,总之,水平菜是本质。。。
YoLoV1~YoLoV2
YoLoV1的主要思想就是,如果将一幅图像分成S*S个网格,如果某个物体的中心落在这个网格中,那么这个网格就负责预测这个物体。其次呢,每个网格还要预测2个bounding box,每个bounding box除了预测位置之外,还要附带一个confidence,就是置信度,每个网格还要预测C个类别的分数,C的数值是类别的总数量。
confidence的值的计算公式就是网格中确实存在目标的概率(一般就是取0或者1)*IOU。
最终的预测的目标概率,是某个目标的概率*IOU(交并比)。
最终经过网络结构之后,输出一个7*7*30的特征矩阵,30这个参数主要包括3部分,第一部分:第一个bounding box的参数值,包括中心坐标x,y和bounding box的高和宽,这几个参数都是相对值,在0和1之间,x,y是相对于那个中心小方格而言的,w,h是相对于整个图片来说的。第二部分和第一部分类似,是第二个bounding box的信息。第三部分是20个类别分数。
损失函数,都是以误差平方和的形式实现,主要有三个,bounding box损失函数,confidence损失函数以及classes损失函数,具体计算方法这里不做详细解释了。
YoLoV2中一个创新点是高层特征和底层特征通过一个passthrough层进行一个融合,主要解决预测小目标的问题。BackBone是一个Darknet-19的结构。
YoLoV3~YoLoV3 SPP
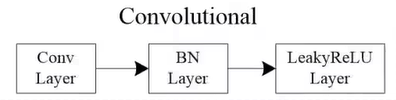
YoLoV3的BackBone改成了Darknet-53的结构,包含一系列残差结构的堆叠,没有最大池化层,而是通过卷积层来进行尺度的压缩,运算参数少。每一个Convolutional卷积层包含一个普通卷积层,一个BN层,没有偏置项,还有一个LeakyReLU激活函数。
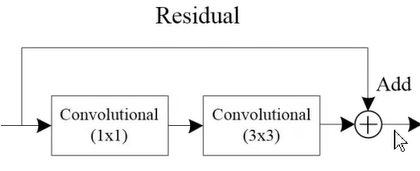
在两个卷积层后接一个残差结构,残差结构中还有两个卷积层结构。
YoLoV3在每个anchor预测三个不同的尺度,最后会得到3个不同的预测特征图输出,用来预测不同大小的目标。
YoLoV3 SPP中也和YoLoV3一样包含Darknet-53的结构,除此之外还应用了Mosaic图像增强,就是把4张图片拼接在一起进行预测,可以增加数据的多样性,增加目标的个数,BN能一次性统计多张图片的参数。
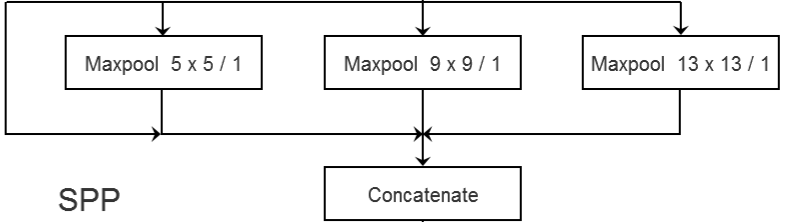
YoLoV3 SPP和YoLoV3网络结构的主要区别在于增加了SPP模块,实现了不同尺度的特征融合。第一个分支直接接到输出,第二个分支为5*5的最大池化下采样层,第三个分支为9*9的最大池化下采样层,第四个分支为13*13的最大池化下采样层,步距都是1,最后各个分支的高和宽以及深度都是一样的,最后通过一个Concatenate进行拼接,拼接之后深度就翻了4倍,实现多尺度的融合。
损失函数的计算:IoU损失,GIoU损失,DIoU损失,CIoU损失。
IoU损失可以更好的反应重合程度,具有尺度不变性,但是当当两个边界框不相交时,loss为0。DIoU可以直接最小化两个boxes之间的距离,因此可以更快的收敛,达到更高的定位精度。CIou效果最好。
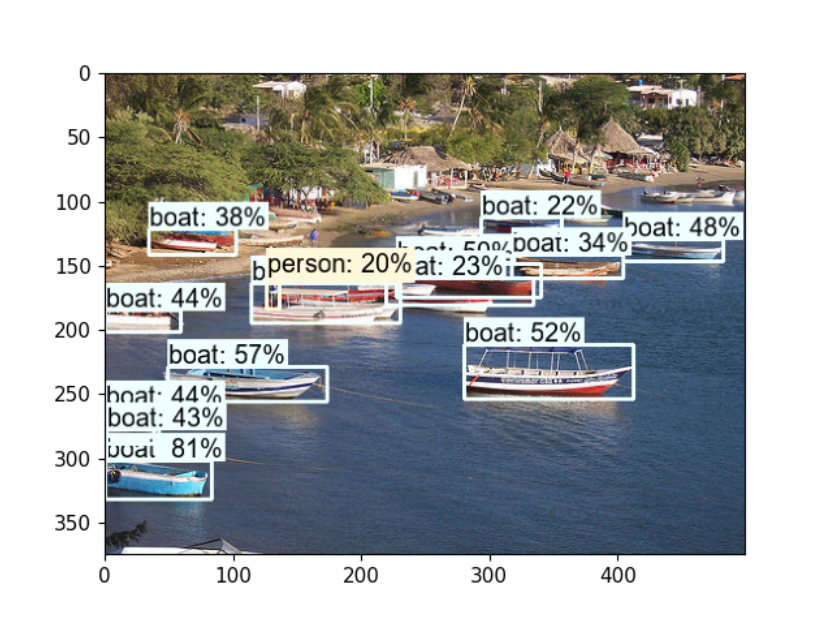
最终训练模型预测结果:
数据集读取以及制作数据集
数据集读取的基本过程:从main中的train.txt中读取每一行的信息,再到xml文件中解析,获取图片的高度宽度以及目标的位置等,再到JPEGImages中载入图片信息。
自己构建数据集,要标注自己的数据集,一般用labelImg一张一张的进行标注,生成xml文件。















 541
541











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











