







在一个网络中联合学习检测和跟踪任务,这会带来性能上的提升。最近不少2D多目标跟踪(Multiple Object Tracking,MOT)的成果表明,使用SOTA检测器加上简单的基于空间运动的帧间关联就可以获得相当不错的跟踪表现,它们的效果优于一些使用外观特征进行重识别丢失轨迹的方法。Uber等最近提出的DEFT(Detection Embeddings for Tracking)是一种联合检测和跟踪的模型,它是一个以检测器为底层在上层构建基于外观的匹配网络的框架设计。在二维跟踪上,它能达到SOTA效果并具有更强的鲁棒性,在三维跟踪上它达到了目前SOTA方法的两倍性能。
demo:
3D
KITT
paper:https://arxiv.org/abs/2102.02267
code:https://github.com/MedChaabane/DEFT
可以假设,一个可学习的目标匹配模块可以添加到主流的CNN检测器中,从而产生高性能的多目标跟踪器,进而通过联合训练检测和跟踪(关联)模块,两个模块彼此适应实现更好的性能。相比于那种将检测作为黑盒模型输入到关联模块中,这种让目标检测和帧间关联共享backbone的思路会有更好的速度和精度。
DEFT中,关联和检测是在一个统一的网络进行学习的的,因此目标关联和检测之间延迟很短。

下面来看整个DEFT的网络设计,总体来说,它是非常类似JDE和FairMOT的一个工作。基于TBD范式,DEFT提出应该使用目标检测器(本文将目标检测器作为backbone)的中间特征图来提取目标的embedding从而用于目标匹配子网络。如下图所示,单看上半部分其实就是整个网络的结构,图像进入上面的Detector分支,同时检测器的不同stage的特征图用于下面的Embedding Extractor模块的外观特征学习,不同帧间的检测目标的外观特征送入Matching Head中获得关联相似度得分矩阵。
在DEFT中检测器和目标匹配网络是联合训练的,训练时,目标匹配网络的损失会反传给检测backbone从而优化外观特征的提取和检测任务的表现。此外,DEFT还在使用了一个低维的LSTM模块来为目标匹配网络提供几何约束,以避免基于外观的但在空间变化上不可能发生的帧间关联。虽说可以基于多个检测器,DEFT在CenterNet上做了主要的工作,获得了SOTA并且比其他类似方法要快,这种速度上的快时来自于在DEFT中,目标关联只是额外的一个小模块,相比于整个检测任务只会有很小的延时。
如果仅仅使用学习到的外观嵌入进行帧间匹配,那么很可能出现两个目标其实真的外观空间上很相似,从而造成匹配上的问题。常见的手段是添加一个几何或者时间约束来限制匹配,常用的是卡尔曼滤波或者LSTM。论文采用的是LSTM设计运动预测模块,该模块会依据过去帧预测未来帧轨迹所在的位置。这个运动预测模块用来约束那些物理上不可能存在的关联,它将距离轨迹预测位置太远的检测框的相似度距离置为 − ∞ 。

数据集使用的是MOT17和KITTI作为2D评估,nuScenes作为3D评估标准数据集。
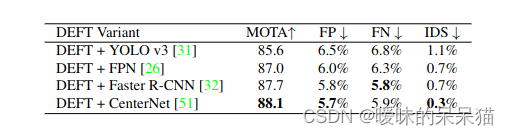
首先是对比多个backbone检测器,效果如下图,发现CenterNet效果最好,所以后面都采用CenterNet作为backbone。
本文提出了一种新的联合检测和跟踪的MOT方法,在多个基准上达到SOTA表现,可以在主流的目标检测器的基础上构建,非常灵活高效,是值得关注的MOT新方法。















 4317
4317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









