






论文:SimpleTrack: Understanding and Rethinking 3D Multi-object Tracking
代码:GitHub - tusen-ai/SimpleTrack
SimpleTrack流程介绍
SimpleTrack主要包括四个组成部分:检测的预处理,数据关联,运动模型和生命周期管理
1、检测的预处理
在当前的检测算法中,通常会输出较多的目标框。但是这些目标框中有一些的检测效果很差,并且有重叠,如果直接使用他们会导致产生错误的轨迹。3D MOT方法通常使用置信度来过滤低质量检测,并提高MOT输入边界框的精度。然而,这种方法可能会对召回造成不利影响,因为会直接丢弃观察结果较差的物体。
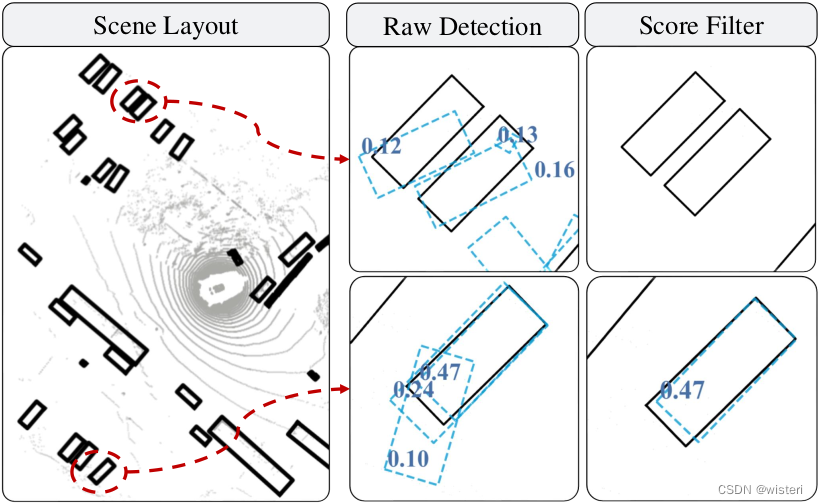
因此将更严格的非最大抑制(non-maximum suppression, NMS)应用于输入检测。仅通过NMS操作,即使在稀疏点或遮挡等区域,也能有效消除重叠的低质量边界框,同时保持不同的低质量观测。因此,通过在预处理模块中增加NMS,可以大致保持召回率,大大提高了精度,有利于MOT。
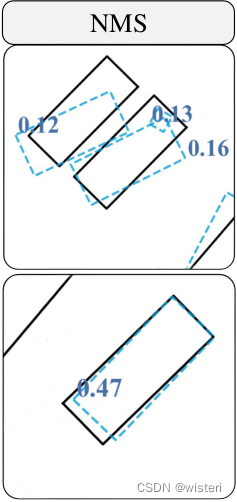
NMS实现代码在mot_3d/preprocessing/nms.py下
def nms(dets, inst_types, threshold_low=0.1, threshold_high=1.0, threshold_yaw=0.3):
""" keep the bboxes with overlap <= threshold
"""
dets_coarse_filter = BBoxCoarseFilter(grid_size=100, scaler=100)
dets_coarse_filter.bboxes2dict(dets)
scores = np.asarray([det.s for det in dets])
yaws = np.asarray([det.o for det in dets])
order = np.argsort(scores)[::-1]
result_indexes = list()
result_types = list()
while order.size > 0:
index = order[0]
if weird_bbox(dets[index]):
order = order[1:]
continue
# locate the related bboxes
filter_indexes = dets_coarse_filter.related_bboxes(dets[index])
in_mask = np.isin(order, filter_indexes)
related_idxes = order[in_mask]
related_idxes = np.asarray([i for i in related_idxes if inst_types[i] == inst_types[index]])
# compute the ious
bbox_num = len(related_idxes)
ious = np.zeros(bbox_num)
for i, idx in enumerate(related_idxes):
ious[i] = utils.iou3d(dets[index], dets[idx])[1]
related_inds = np.where(ious > threshold_low)
related_inds_vote = np.where(ious > threshold_high)
order_vote = related_idxes[related_inds_vote]
if len(order_vote) >= 2:
# keep the bboxes with similar yaw
if order_vote.shape[0] <= 2:
score_index = np.argmax(scores[order_vote])
median_yaw = yaws[order_vote][score_index]
elif order_vote.shape[0] % 2 == 0:
tmp_yaw = yaws[order_vote].copy()
tmp_yaw = np.append(tmp_yaw, yaws[order_vote][0])
median_yaw = np.median(tmp_yaw)
else:
median_yaw = np.median(yaws[order_vote])
yaw_vote = np.where(np.abs(yaws[order_vote] - median_yaw) % (2 * np.pi) < threshold_yaw)[0]
order_vote = order_vote[yaw_vote]
# start weighted voting
vote_score_sum = np.sum(scores[order_vote])
det_arrays = list()
for idx in order_vote:
det_arrays.append(BBox.bbox2array(dets[idx])[np.newaxis, :])
det_arrays = np.vstack(det_arrays)
avg_bbox_array = np.sum(scores[order_vote][:, np.newaxis] * det_arrays, axis=0) / vote_score_sum
bbox = BBox.array2bbox(avg_bbox_array)
bbox.s = scores[index]
result_indexes.append(index)
result_types.append(inst_types[index])
else:
result_indexes.append(index)
result_types.append(inst_types[index])
# delete the overlapped bboxes
delete_idxes = related_idxes[related_inds]
in_mask = np.isin(order, delete_idxes, invert=True)
order = order[in_mask]
return result_indexes, result_types在data_loader文件夹下waymo_loader.py通过frame_nms函数调用NMS对检测进行预处理
def frame_nms(self, dets, det_types, velos, thres):
frame_indexes, frame_types = nms(dets, det_types, thres)
result_dets = [dets[i] for i in frame_indexes]
result_velos = None
if velos is not None:
result_velos = [velos[i] for i in frame_indexes]
return result_dets, frame_types, result_velos数据预处理:由字段中的nms和nms_thres参数控制data_loader。它们指定是否使用 NMS 进行数据预处理以及 NMS 的 IoU 阈值是多少。
self.nms = configs['data_loader']['nms']
self.nms_thres = configs['data_loader']['nms_thres']if self.nms:
result['dets'], result['det_types'], result['aux_info']['velos'] = \
self.frame_nms(result['dets'], result['det_types'], result['aux_info']['velos'], self.nms_thres)2、运动模型
运动预测模块主要根据轨迹预测后续运动,进而实现与检测结果的匹配。3D MOT常用的运动模型有两种:卡尔曼滤波法(Kalman filter, KF)以及利用探测器预测速度的速度预测模型法(constant velocity model, CV)。KF的优点是可以利用多帧信息,并在面对低质量检测时提供更平滑的结果。同时,CV以其明确的速度预测较好地处理突发和不可预测的运动,但其在运动平滑方面的效果有限。
卡尔曼滤波更适合高频情况(高频下运动更可预测),而恒速模型对于具有显式速度预测的低频场景更鲁棒。由于推断速度对于探测器来说还不常见,因此在不损失通用性的情况下SimpleTrack采用卡尔曼滤波器进行简单跟踪。
运动模型可选的配置为: kf和cv(SimpleTrack的运动模型默认为kf)
mot_3d/tracklet/tracklet.py
# 初始化不同类型的运动模型
self.motion_model_type = configs['running']['motion_model'] # motion_model: kf
# simple kalman filter
if self.motion_model_type == 'kf':
self.motion_model = motion_model.KalmanFilterMotionModel(
bbox=bbox, inst_type=self.det_type, time_stamp=time_stamp, covariance=configs['running']['covariance'])def predict(self, time_stamp=None, is_key_frame=True):
""" in the prediction step, the motion model predicts the state of bbox
the other components have to be synced
the result is a BBox
the ussage of time_stamp is optional, only if you use velocities
"""
result = self.motion_model.get_prediction(time_stamp=time_stamp)
self.life_manager.predict(is_key_frame=is_key_frame)
self.latest_score = self.latest_score * 0.01
result.s = self.latest_score
return result3、数据关联
通过将检测和运动模型得到的预测结果进行数据关联
关联模块主要有两种做法,一种是基于IoU的关联方式,一种是基于距离的关联方式。基于IoU的关联方式只要两者的IoU大于一定值就关联上了,反之就没有关联上。基于距离的关联方式一般使用L2范数距离或者马氏距离,两者之间距离小于一定值就关联上。
这两种方法各有优劣,对于基于IoU的方法而言,一旦IoU过小就关联不上。但是这个目标仍然是存在的,这就会导致某些目标的轨迹提前消失。这种提前消失是很大的问题,意味着我们手动给这个目标判了死刑,再也不能和他进行关联了。
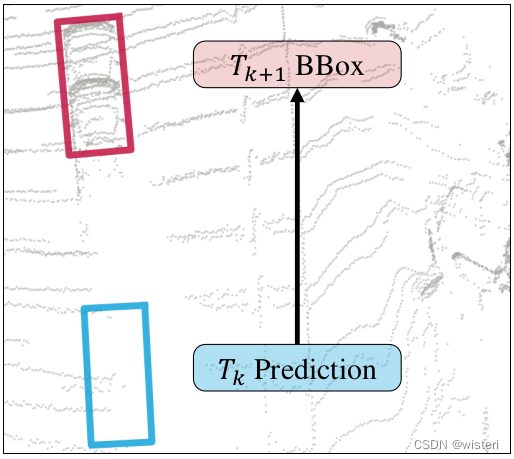
使用IoU匹配失败,IoU=0
对于距离的关联方式而言,可能会导致误检。如图所示,其中红色Box是正确的检测结果,绿色Box是错误的结果,但是绿色Box和预测结果更近。
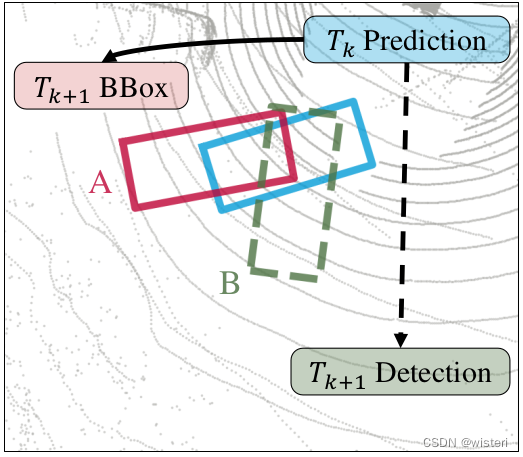
使用距离匹配失败
随着距离阈值的增大,基于距离的关联方式可以处理基于IoU的度量的失效情况,但它们可能对低质量的附近检测不够敏感。基于距离的度量缺乏对方向的区分,这正是基于IOU的度量的优势。为了兼顾这两个领域的优点,提出将Generalized IoU(GIoU)推广到3D进行关联。GIoU的公式如下所示:
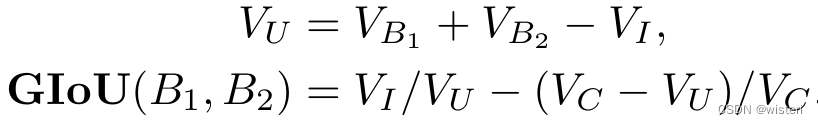
GIoU公式可以写为:GIoU = IoU - (连通域 - 并集) / 连通域。由于Box之间的距离越大,连通域的大小与并集的大小也就差得越大 ,IoU就越小。所以这个GIoU实际上是同时考虑距离和交并比这两个因素,并且将距离量转化为了体积量,消除了量纲之间的差异。设置GIoU >−0.5作为数据集每一类对象的阈值,以进入后续的匹配步骤。
匹配策略:一般有两种方法:1)将问题表述为二分匹配问题,然后使用匈牙利算法求解。2)利用贪心算法迭代关联最近的boundingbox对。
匹配策略的核心点在mot_3d/association.py
def associate_dets_to_tracks(dets, tracks, mode, asso,
dist_threshold=0.9, trk_innovation_matrix=None):
""" associate the tracks with detections
"""
if mode == 'bipartite': # 匈牙利算法
matched_indices, dist_matrix = \
bipartite_matcher(dets, tracks, asso, dist_threshold, trk_innovation_matrix)
elif mode == 'greedy': # 贪婪匹配
matched_indices, dist_matrix = \
greedy_matcher(dets, tracks, asso, dist_threshold, trk_innovation_matrix)
unmatched_dets = list()
for d, det in enumerate(dets):
if d not in matched_indices[:, 0]:
unmatched_dets.append(d)
unmatched_tracks = list()
for t, trk in enumerate(tracks):
if t not in matched_indices[:, 1]:
unmatched_tracks.append(t)
matches = list()
for m in matched_indices:
if dist_matrix[m[0], m[1]] > dist_threshold:
unmatched_dets.append(m[0])
unmatched_tracks.append(m[1])
else:
matches.append(m.reshape(2))
return matches, np.array(unmatched_dets), np.array(unmatched_tracks)下面是匈牙利算法和贪婪匹配算法的实现函数
# 匈牙利算法
def bipartite_matcher(dets, tracks, asso, dist_threshold, trk_innovation_matrix):
# 使用匈牙利关联进行匹配,算出cost矩阵之后直接调用linear_sum_assignment
if asso == 'iou':
dist_matrix = compute_iou_distance(dets, tracks, asso)
elif asso == 'giou':
dist_matrix = compute_iou_distance(dets, tracks, asso)
elif asso == 'm_dis':
dist_matrix = compute_m_distance(dets, tracks, trk_innovation_matrix)
elif asso == 'euler':
dist_matrix = compute_m_distance(dets, tracks, None)
row_ind, col_ind = linear_sum_assignment(dist_matrix)
matched_indices = np.stack([row_ind, col_ind], axis=1)
return matched_indices, dist_matrix# 贪婪匹配
def greedy_matcher(dets, tracks, asso, dist_threshold, trk_innovation_matrix):
""" it's ok to use iou in bipartite
but greedy is only for m_distance
在匈牙利中使用iou是可以的,但贪婪只适用于m_distance
"""
matched_indices = list()
# compute the distance matrix
if asso == 'm_dis':
distance_matrix = compute_m_distance(dets, tracks, trk_innovation_matrix)
elif asso == 'euler':
distance_matrix = compute_m_distance(dets, tracks, None)
elif asso == 'iou':
distance_matrix = compute_iou_distance(dets, tracks, asso)
elif asso == 'giou':
distance_matrix = compute_iou_distance(dets, tracks, asso)
num_dets, num_trks = distance_matrix.shape
# association in the greedy manner
# refer to https://github.com/eddyhkchiu/mahalanobis_3d_multi_object_tracking/blob/master/main.py
# 这里说明了借鉴自AB3D MOT
distance_1d = distance_matrix.reshape(-1)
index_1d = np.argsort(distance_1d)
index_2d = np.stack([index_1d // num_trks, index_1d % num_trks], axis=1)
detection_id_matches_to_tracking_id = [-1] * num_dets
tracking_id_matches_to_detection_id = [-1] * num_trks
for sort_i in range(index_2d.shape[0]):
detection_id = int(index_2d[sort_i][0])
tracking_id = int(index_2d[sort_i][1])
if tracking_id_matches_to_detection_id[tracking_id] == -1 and detection_id_matches_to_tracking_id[detection_id] == -1:
tracking_id_matches_to_detection_id[tracking_id] = detection_id
detection_id_matches_to_tracking_id[detection_id] = tracking_id
matched_indices.append([detection_id, tracking_id])
if len(matched_indices) == 0:
matched_indices = np.empty((0, 2))
else:
matched_indices = np.asarray(matched_indices)
return matched_indices, distance_matrix不管是匈牙利算法,还是贪婪匹配,其关键都在于计算distance。其中匈牙利算法计算iou_distance,贪婪匹配计算m_distance。
计算iou_distance部分,调用mot_3d/utils/geometry.py的iou3d和giou3d
def iou3d(box_a, box_b):
boxa_corners = np.array(BBox.box2corners2d(box_a))
boxb_corners = np.array(BBox.box2corners2d(box_b))[:, :2]
reca, recb = Polygon(boxa_corners), Polygon(boxb_corners)
overlap_area = reca.intersection(recb).area
iou_2d = overlap_area / (reca.area + recb.area - overlap_area)
ha, hb = box_a.h, box_b.h
za, zb = box_a.z, box_b.z
overlap_height = max(0, min((za + ha / 2) - (zb - hb / 2), (zb + hb / 2) - (za - ha / 2)))
overlap_volume = overlap_area * overlap_height
union_volume = box_a.w * box_a.l * ha + box_b.w * box_b.l * hb - overlap_volume
iou_3d = overlap_volume / (union_volume + 1e-5)
return iou_2d, iou_3ddef giou3d(box_a: BBox, box_b: BBox):
boxa_corners = np.array(BBox.box2corners2d(box_a))[:, :2]
boxb_corners = np.array(BBox.box2corners2d(box_b))[:, :2]
reca, recb = Polygon(boxa_corners), Polygon(boxb_corners)
ha, hb = box_a.h, box_b.h
za, zb = box_a.z, box_b.z
overlap_height = max(0, min((za + ha / 2) - (zb - hb / 2), (zb + hb / 2) - (za - ha / 2)))
union_height = max((za + ha / 2) - (zb - hb / 2), (zb + hb / 2) - (za - ha / 2))
# compute intersection and union
I = reca.intersection(recb).area * overlap_height
U = box_a.w * box_a.l * ha + box_b.w * box_b.l * hb - I
# compute the convex area
all_corners = np.vstack((boxa_corners, boxb_corners))
C = ConvexHull(all_corners)
convex_corners = all_corners[C.vertices]
convex_area = PolyArea2D(convex_corners)
C = convex_area * union_height
# compute giou
giou = I / U - (C - U) / C
return giou在匈牙利算法中使用iou是可以的,但贪婪匹配只适用于m_distance。
计算m_distance距离部分:主要是调用geometry.py的m_distance
def m_distance(det, trk, trk_inv_innovation_matrix=None):
det_array = BBox.bbox2array(det)[:7]
trk_array = BBox.bbox2array(trk)[:7]
diff = np.expand_dims(det_array - trk_array, axis=1)
corrected_yaw_diff = diff_orientation_correction(diff[3])
diff[3] = corrected_yaw_diff
if trk_inv_innovation_matrix is not None:
result = \
np.sqrt(np.matmul(np.matmul(diff.T, trk_inv_innovation_matrix), diff)[0][0])
else:
result = np.sqrt(np.dot(diff.T, diff))
return result4、生存周期管理
它控制“出生”、“死亡”和“输出”策略。“Birth”决定是否将检测包围框初始化为一个新的tracklet;当“Death”认为轨迹已移出注意区域时,它会移除轨迹;“Output”决定tracklet是否将输出其状态。该策略由模块max_age_since_update和min_hits_to_birth指定。max_age_since_update表示死亡前的最大丢失数,min_hits_to_birth表示出生前的最小命中数。
mot_3d/life/hit_manager.py
self.max_age = configs['running']['max_age_since_update']
self.min_hits = configs['running']['min_hits_to_birth']def state_transition(self, mode, frame_index):
# if just founded
if self.state == 'birth':
if (self.hits >= self.min_hits) or (frame_index <= self.min_hits):
self.state = 'alive'
self.recent_state = mode
elif self.time_since_update >= self.max_age:
self.state = 'dead'
# already alive
elif self.state == 'alive':
if self.time_since_update >= self.max_age:
self.state = 'dead'在MOT中有一个重要的评价指标ID-Switches,这个指标表示预测的ID与真实的ID不匹配的次数。出现这个错误的原因分为了两种,分别是1)错误关联; 2)提前结束。其中提前结束这种错误占了大多数。提前结束常是因为出现了点云很稀疏、遮挡这样的情况,使得检测结果的置信度分数很低,进而被抛弃了。但是这些物体是实际存在的,不应该被抛弃。
为了解决上述问题,提出了两阶段关联。简单来说就是设置了两个阈值,采用两种不同阈值进行关联,一阶段:和大部分方法一样使用较大阈值(0.5)得分的boundingbox进行轨迹关联。第二阶段:关注一阶段轨迹中未匹配的检测目标,并在阈值大于0.1的boundingbox进行匹配,但是对于低阈值匹配的结果不会输出,只用于保留ID,下一帧的轨迹状态仍然使用运动估计的结果。在使用两阶段关联后,ID-Switch指标得到了明显的提升。
一阶段匹配:
score_threshold表示one-stage匹配时的最小score,mot.py里forward_step_trk函数调用score_threshold,只匹配score >= self.score_threshold的检测目标
self.score_threshold = configs['running']['score_threshold']def forward_step_trk(self, input_data: FrameData):
dets = input_data.dets
# one-stage匹配,只匹配score >= self.score_threshold的检测目标
det_indexes = [i for i, det in enumerate(dets) if det.s >= self.score_threshold]
dets = [dets[i] for i in det_indexes]
# prediction and association
trk_preds = list()
for trk in self.trackers:
trk_preds.append(trk.predict(input_data.time_stamp, input_data.aux_info['is_key_frame']))
# 这里的关键点predict,根据速度模型求取trk_preds
# for m-distance association
trk_innovation_matrix = None
if self.asso == 'm_dis':
trk_innovation_matrix = [trk.compute_innovation_matrix() for trk in self.trackers]
matched, unmatched_dets, unmatched_trks = associate_dets_to_tracks(dets, trk_preds,
self.match_type, self.asso, self.asso_thres, trk_innovation_matrix)
for k in range(len(matched)):
matched[k][0] = det_indexes[matched[k][0]]
for k in range(len(unmatched_dets)):
unmatched_dets[k] = det_indexes[unmatched_dets[k]]
return matched, unmatched_dets, unmatched_trks二阶段匹配:
det_score_threshold表示two-stage匹配时的最小score,redundancy.py里motion_model_redundancy函数调用det_score_threshold进行two-stage匹配。
self.det_score = configs['redundancy']['det_score_threshold'][self.asso]def motion_model_redundancy(self, trk: Tracklet, input_data: FrameData, time_lag):
# get the motion model prediction / current state
# 这个pred_bbox是kf只pred没update的结果。
pred_bbox = trk.get_state()
# associate to low-score detections
dists = list()
dets = input_data.dets
related_indexes = [i for i, det in enumerate(dets) if det.s > self.det_score]
candidate_dets = [dets[i] for i in related_indexes]
# association
for i, det in enumerate(candidate_dets):
pd_det = det
if self.asso == 'iou':
dists.append(utils.iou3d(pd_det, pred_bbox)[1])
elif self.asso == 'giou':
dists.append(utils.giou3d(pd_det, pred_bbox))
elif self.asso == 'm_dis':
trk_innovation_matrix = trk.compute_innovation_matrix()
inv_innovation_matrix = np.linalg.inv(trk_innovation_matrix)
dists.append(utils.m_distance(pd_det, pred_bbox, inv_innovation_matrix))
elif self.asso == 'euler':
dists.append(utils.m_distance(pd_det, pred_bbox))
# 表示two-stage匹配还是没匹配上
if self.asso in ['iou', 'giou'] and (len(dists) == 0 or np.max(dists) < self.det_threshold):
result_bbox = pred_bbox
update_mode = 0 # two-stage not assiciated
elif self.asso in ['m_dis', 'euler'] and (len(dists) == 0 or np.min(dists) > self.det_threshold):
result_bbox = pred_bbox
update_mode = 0 # two-stage not assiciated
# 表示two-stage匹配成功
else:
result_bbox = pred_bbox
update_mode = 3 # two-stage associated
return result_bbox, update_mode, {'velo': np.zeros(2)} 配置文件介绍
配置文件configs/waymo_configs/vc_kf_giou.yaml解释
-
数据预处理 由字段中的
nms和nms_thres参数控制data_loader。它们指定是否使用 NMS 进行数据预处理以及 NMS 的 IoU 阈值是多少。 -
运动模型 默认为卡尔曼滤波器。
-
关联度量 是在运行
running-asso时指定的,目前可以选择 IoU 和 GIoU。为了指定成功关联的阈值,我们将1-IoU或1-GIoU视为距离,并且它必须小于asso_thres中相应的数字。 -
两阶段关联 由模块
redundancy指定。mm表示两级关联,default表示传统的单级关联。
running:
covariance: default # 协方差 不使用
# one-stage匹配时的最小score。
score_threshold: 0.1 # 第一阶段关联和输出的检测分数阈值
max_age_since_update: 4 # 死亡前的最大丢失数,帧数超过该数量则视为death
min_hits_to_birth: 3 # 出生前的最小命中数,帧数超过该数量则视为birth
match_type: bipartite # 使用匈牙利算法(biparitite)或贪婪匹配(greedy)
asso: giou # 关联度量,目前支持GIoU(giou)和IoU(iou)
has_velo: false
motion_model: kf # 卡尔曼滤波器(kf)作为运动模型
# one-stage匹配时的最大距离。即使匹配上,但是匹配距离大于此,也视为没匹配上。
asso_thres:
iou: 0.3 # 关联阈值,1 - IoU必须小于它。
# 1 - giou = 0.5,这是最小匹配度
giou: 1.5 # 关联阈值,1 - GIoU必须小于它
redundancy:
mode: mm # (mm)表示两阶段关联,(default)表示一阶段关联
# two-stage匹配时的最小score
det_score_threshold: # 两阶段关联的检测分数阈值
iou: 0.1
giou: 0.1
# two-stage匹配时的最小匹配度
# 这里用的dist这个值不是距离而是匹配度。匹配度 = 1 - 距离
det_dist_threshold: # 两阶段关联的关联阈值
iou: 0.1 # IoU 必须大于此
giou: -0.5 # GIoU 必须大于此
data_loader:
pc: true # 用于可视化的加载点云
nms: true # 应用NMS进行数据预处理,True or False
nms_thres: 0.25 # NMS的IoU-3D阈值参考文献:
SimpleTrack论文阅读笔记_ng_T的博客-CSDN博客
[3D多目标追踪] SimpleTrack 论文阅读 师姐の登场 - 知乎
















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









