







![[LOGO]:CoreKSets](https://i-blog.csdnimg.cn/direct/731088657ae348d4a1f679ad3008534a.png)
【核知坊】:释放青春想象,码动全新视野。
我们希望使用精简的信息传达知识的骨架,启发创造者开启创造之路!!!
内容摘要:从早期的简单晶体管优化到现代的复杂指令集、缓存技术、流水线设计、多核处理器和超级计算机的出现。这些技术的发展使得处理器不仅速度更快,而且能够执行更复杂的任务。
关键词:CPU缓存 流水并行 多核CPU
其他相关文章:
[计算机科学#7]:CPU的三阶段,取指令、解码、执行-CSDN博客
[计算机科学#6]:从锁存器到内存,计算机存储的构建与原理-CSDN博客
CPU提速方式
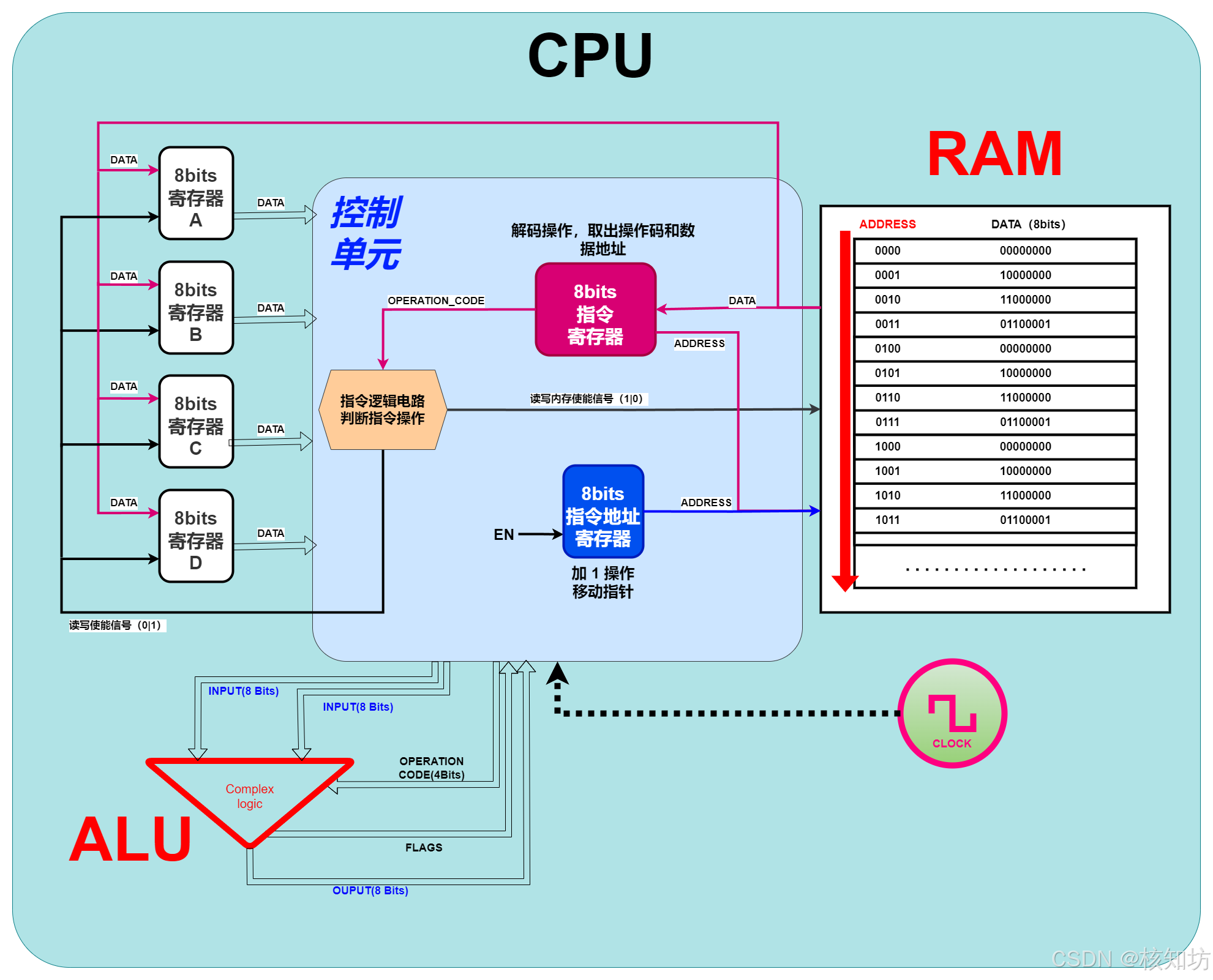
CPU提速可以显著加快程序的执行速度,从而大幅提升工作效率。处理器性能的提升直接影响到程序运行的效率,使得复杂的计算和数据处理能够更快完成。
早期计算机处理器主要通过减少晶体管的切换时间来提高速度。晶体管是构成逻辑门、ALU和其他组件的基础,优化它们的电气性能可以直接提升处理器的速度。具体措施包括改进元器件的制造工艺、选用优质材料以及设计更合理的逻辑电路。然而,单纯提升晶体管的速度和效率最终会遇到瓶颈,因此需要新的技术来进一步提升性能。
现代CPU通过引入复杂的指令集来提升性能。这些指令是专门为一些耗时的复杂操作设计的,使用这些指令可以在硬件上直接进行加速。虽然这些指令的运作方式对人类来说可能难以理解,但它们的效率非常高。例如,现代处理器可以直接在硬件层面执行除法操作,而不需要通过多次减法来模拟。传统方法中,9除以2需要通过多次减法(9-2-2-2-2)来计算结果为4余1。
CPU 缓存
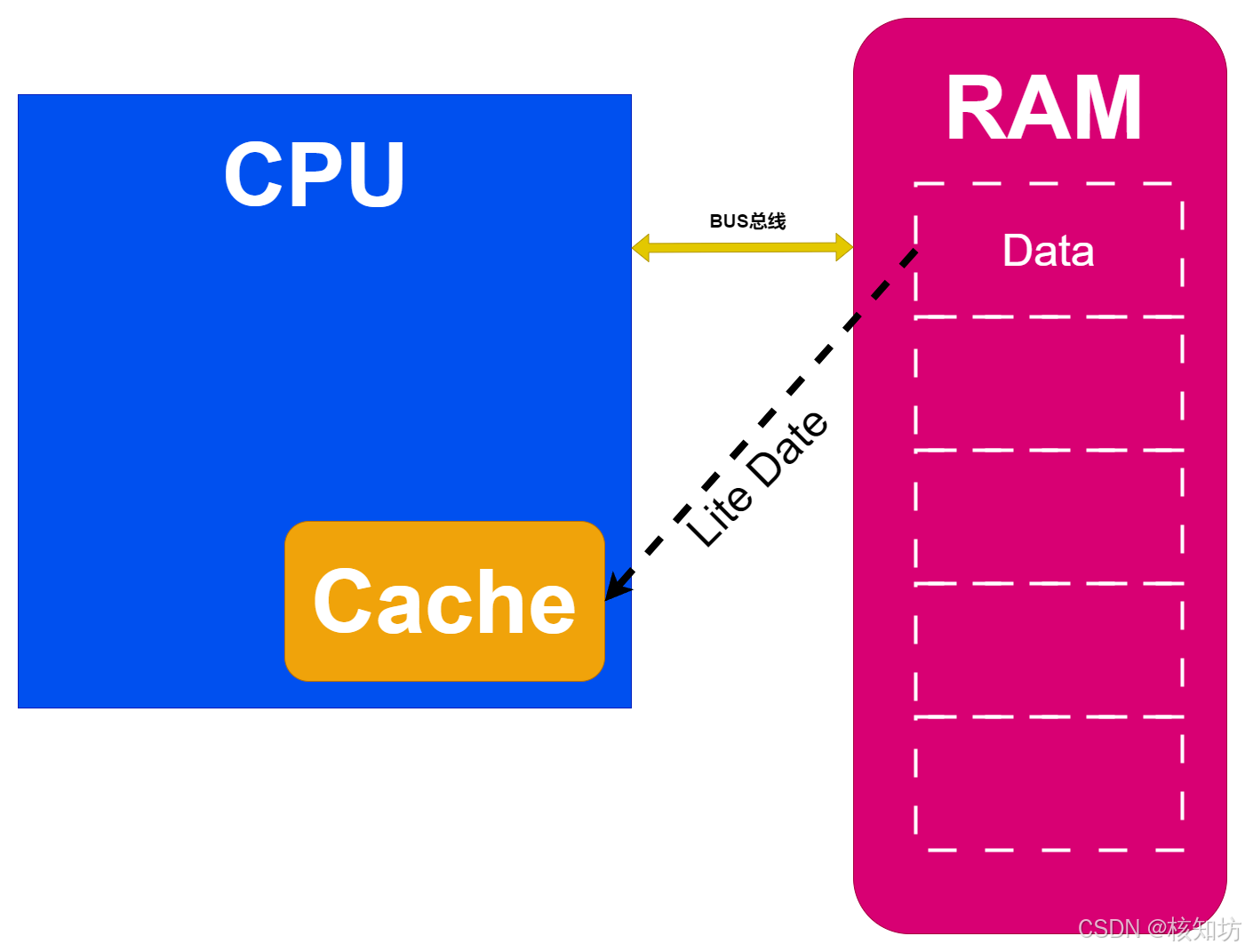
缓存的原始意义是指一种访问速度比一般随机存取存储器(RAM)更快的高速存储器。它通常不使用系统主存的DRAM技术,而是采用昂贵但更快速的SRAM技术。作为现代计算机系统发挥高性能的关键部件之一,缓存极大地提升了数据处理效率。
早期的CPU没有缓存,每次处理的数据都直接来自大容量存储器RAM。CPU与RAM之间的数据传递依赖于连接两者的导线,这些导线被统称为总线(BUS)。这种结构虽然简单明了,但随着CPU处理速度的飞速提升,已经远远超过了总线的数据传输速度,导致CPU在等待数据时出现大量空闲时间。这种情况显然是我们希望避免的,我们希望CPU始终保持高效的工作状态,时刻处理所需的数据。
为了减少CPU与RAM之间的延迟,现代处理器引入了缓存模块。缓存是位于CPU内部的小型快速存储器,能够存储频繁访问的数据,其读写速度远超CPU外部的RAM。当CPU请求数据时,RAM会将一个数据块(通常为几十到几百KB)传输到缓存中。如果CPU后续请求的数据已经在缓存中,可以直接从缓存获取,从而显著减少等待时间。如果请求的数据在缓存中,这种情况称为缓存命中;如果不在缓存中,需要从RAM获取,这种情况称为缓存未命中。通过概率统计学的方法,缓存命中率得以科学地提高。
由于缓存中的数据和RAM中的数据不在同一个物理结构中,当两者数据不同步时,可能会导致数据错乱,从而干扰程序的正常运行。为了解决这一问题,引入了一个特殊标记——脏位,用于记录缓存中的数据是否被修改过。当缓存满了,需要将标记为脏位的数据写回RAM,以确保数据的一致性和程序的稳定运行。
流水线
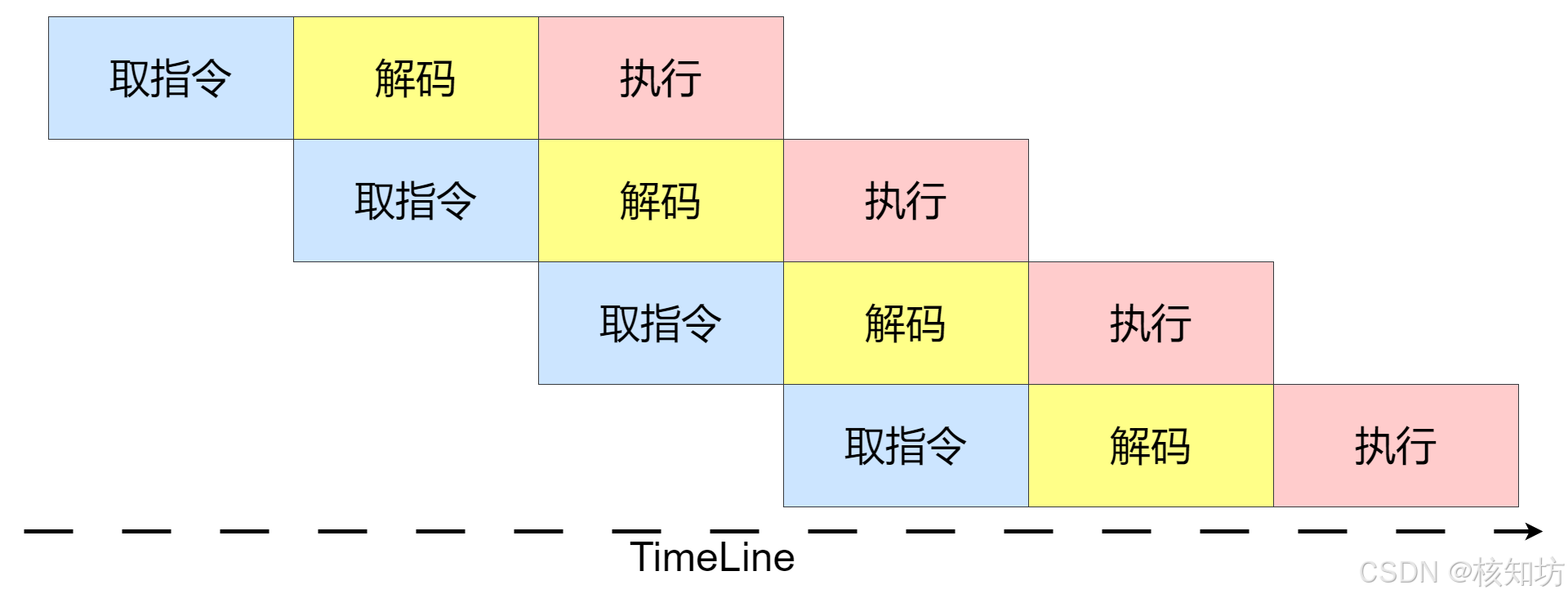
取指、解码、执行这三个步骤都可以在CPU里的单独模块中完成。为了减少模块的空闲时间,让它们一直处于工作状态,研究者们引入了流水线技术。通过流水线技术,CPU可以同时进行不同指令的取指、解码和执行步骤,从而加速每个步骤。
流水线是一种将指令的执行过程分解为多个阶段(如取指、解码、执行)的技术。这种设计使得不同阶段可以同时处理不同的指令,从而提高处理器的吞吐量。具体来说,当一条指令处于执行阶段时,下一条指令可以处于解码阶段,而再下一条指令可以处于取指阶段。通过这种方式,处理器可以在每个时钟周期完成一条指令,大大提高了效率。
尽管流水线技术显著提升了处理器的性能,但它也带来了一些问题。例如,指令之间可能存在依赖关系(数据相关性),这可能导致流水线冲突。此外,条件跳转指令(分支预测)也可能导致流水线停顿。这些问题如果处理不当,会降低流水线的效率。
为了应对这些挑战,高端处理器采用了多种技术。例如,通过动态指令重排序,处理器可以在流水线中重新安排指令的执行顺序,从而最小化因数据依赖导致的停顿。此外,通过分支预测技术,处理器可以提前猜测条件跳转指令的执行方向,从而避免流水线的频繁清空。这些技术的结合使得流水线能够更高效地运行,进一步提升了处理器的整体性能。
多核CPU

为了进一步提升性能,现代处理器采用了多核设计,即在一个CPU芯片中集成多个独立的处理单元。多核处理器可以同时运行多个指令流,提高并行处理能力。它们还可以共享资源,如缓存,从而提高整体性能。
多CPU设备

当多核处理器的性能仍然不足以满足需求时,可以通过增加多个独立的CPU来进一步提升性能。高端计算机,如服务器,通常采用多CPU配置来满足高性能需求。例如,YouTube的数据中心服务器需要强大的计算能力来支持大量用户的视频流。多CPU配置可以提供更高的计算能力和更好的并行处理能力,适用于需要处理大量并发任务的场景。
超级计算机

超级计算机是性能极高的计算设备,用于执行复杂的科学计算和大规模数据处理任务。超级计算机用于人工智能,模拟宇宙形成、气候预测、生物医学研究等需要巨大计算能力的领域。
目前世界上最强大的超级计算机是 El Capitan,位于美国加利福尼亚州劳伦斯利弗莫尔国家实验室。
-
性能:El Capitan的HPL得分为1.742 EFlop/s(每秒1.742百亿亿次浮点运算),是目前世界上首台达到这一性能水平的超级计算机。
-
核心数量:拥有11,039,616个CPU和GPU组合内核。
-
处理器:基于AMD第四代EPYC处理器,每个处理器拥有24个1.8GHz内核,同时配备AMD Instinct MI300A加速器。
-
网络:采用Cray Slingshot 11网络进行数据传输。
-
能效:实现了58.89千兆次/瓦的能效,在GREEN500榜单上排名第18位。
| 排名 | 超级计算机名称 | 所在地 | 性能(HPL分数) | 核心数量 | 处理器及加速器 |
|---|---|---|---|---|---|
| 2 | Frontier | 美国田纳西州橡树岭国家实验室 | 1.353 EFlop/s | 9,066,176个核心 | AMD EPYC 64核CPU + AMD Instinct MI250X GPU |
| 3 | Aurora | 美国伊利诺伊州阿贡国家实验室 | 1.012 EFlop/s | 4,742,808个核心 | 英特尔至强CPU Max系列 + 英特尔数据中心GPU Max系列 |
| 4 | Eagle | 微软Azure云平台 | 561.2 PFlop/s | 1,123,200个核心 | 英特尔Xeon Platinum 8480C CPU + 英伟达H100 GPU |
| 5 | Fugaku | 日本神户理研计算科学研究中心 | 442 PFlop/s | 7,630,848个核心 | 福富通A64FX处理器 |
| 6 | LUMI | 芬兰CSC EuroHPC中心 | 379.7 PFlop/s | 2,752,704个核心 | AMD第三代EPYC 64核CPU + AMD Instinct MI250X GPU |
文章总结
本文简要介绍了CPU缓存技术和流水并行技术等计算机提升性能的方法。这些技术从硬件和软件两个层面进行了优化,以实现更高的计算效率。接下来的文章将深入探讨编程,进一步展示如何利用这些硬件来实现更高效、更强大的软件应用。
感谢阅览,如果你喜欢该内容的话,可以点赞,收藏,转发。由于 Koro 能力有限,有任何问题请在评论区内提出,Koro 看到后第一时间回复您!!!
其他精彩内容:
[计算机科学#3]:布尔逻辑 (计算机数学基础)-CSDN博客
[计算机科学#4]:二进制如何塑造数字世界(0和1的力量)-CSDN博客
[计算机科学#5]:计算机的“数学大脑”——核心部件ALU揭秘-CSDN博客
参考内容:
Crash Course Computer Science(Y-T)

















 9663
9663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









