









一、什么是池化
池化(Pooling)是卷积神经网络(CNN)中的一种关键操作,通常位于卷积层之后,用于对特征图(Feature Map)进行下采样(Downsampling)。其核心目的是通过压缩特征图的尺寸来减少计算量,同时保留最重要的特征信息,增强模型的鲁棒性和泛化能力。池化层不包含可学习的参数(如权重),而是通过固定的数学操作(如取最大值或平均值)实现特征压缩。
二、池化操作
池化操作类似卷积操作,使用的也是一个很小的矩阵,叫做池化核,但是池化核本身 没有参数,只是通过对输入特征矩阵本身进行运算,它的大小通常是2x2、3x3、4x4 等,然后将池化核在卷积得到的输出特征图中进行池化操作,需要注意的是,池化的 过程中也有Padding方式以及步长的概念,与卷积不同的是,池化的步长往往等于池 化核的大小。
最常见的池化操作为最大值池化(Max Pooling)和平均值池化(Average Pooling)两种。 最大池化是从每个局部区域中选择最大值作为池化后的值,这样可以保留局部区域中 最显著的特征。最大池化在提取图像中的纹理、形状等方面具有很好的效果。
平均池化是将局部区域中的值取平均作为池化后的值,这样可以得到整体特征的平均 值。平均池化在提取图像中的整体特征、减少噪声等方面具有较好的效果。
池化的具体过程如下:
-
窗口划分:在输入特征图上滑动一个固定大小的窗口(如2×2、3×3)。
-
步长(Stride):窗口每次滑动的步长通常与窗口尺寸一致(如2×2窗口配合步长2),确保特征图尺寸减半。
-
池化类型:
-
最大池化(Max Pooling):取窗口内的最大值作为输出,强调最显著的特征(如边缘、纹理)。
-
平均池化(Average Pooling):取窗口内的平均值作为输出,平滑特征并降低噪声。
-
全局池化(Global Pooling):将整个特征图压缩为一个值,常用于全连接层前的过渡。
-
三、卷积核与池化的关系
卷积核的作用是提取局部特征(如边缘、角点),通过滑动和点乘生成特征图。但卷积层输出的特征图可能包含冗余信息(如重复的纹理或噪声)。
池化层则对卷积层的输出进行筛选:
-
降维:减少特征图尺寸,降低后续层的计算复杂度。
-
特征增强:通过保留窗口内的最显著值(最大池化)或平滑特征(平均池化),强化关键特征并抑制次要信息。
四、池化结果
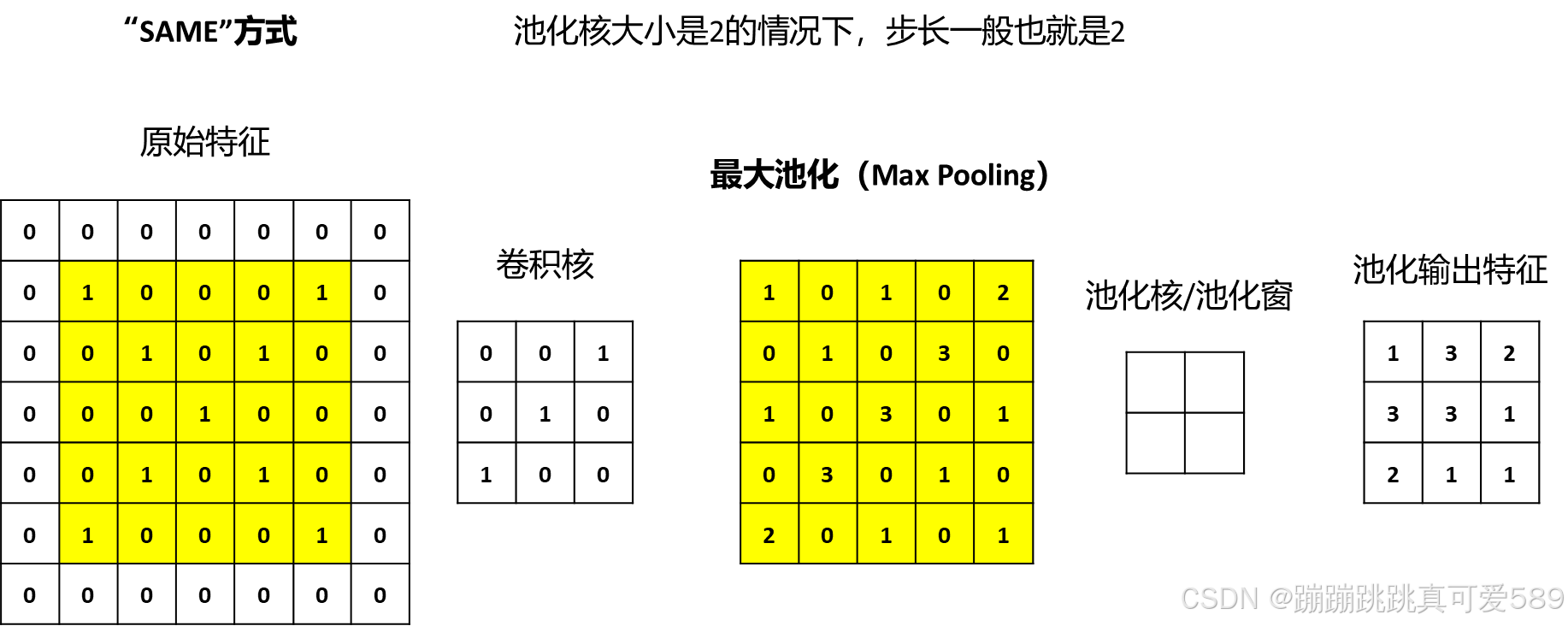
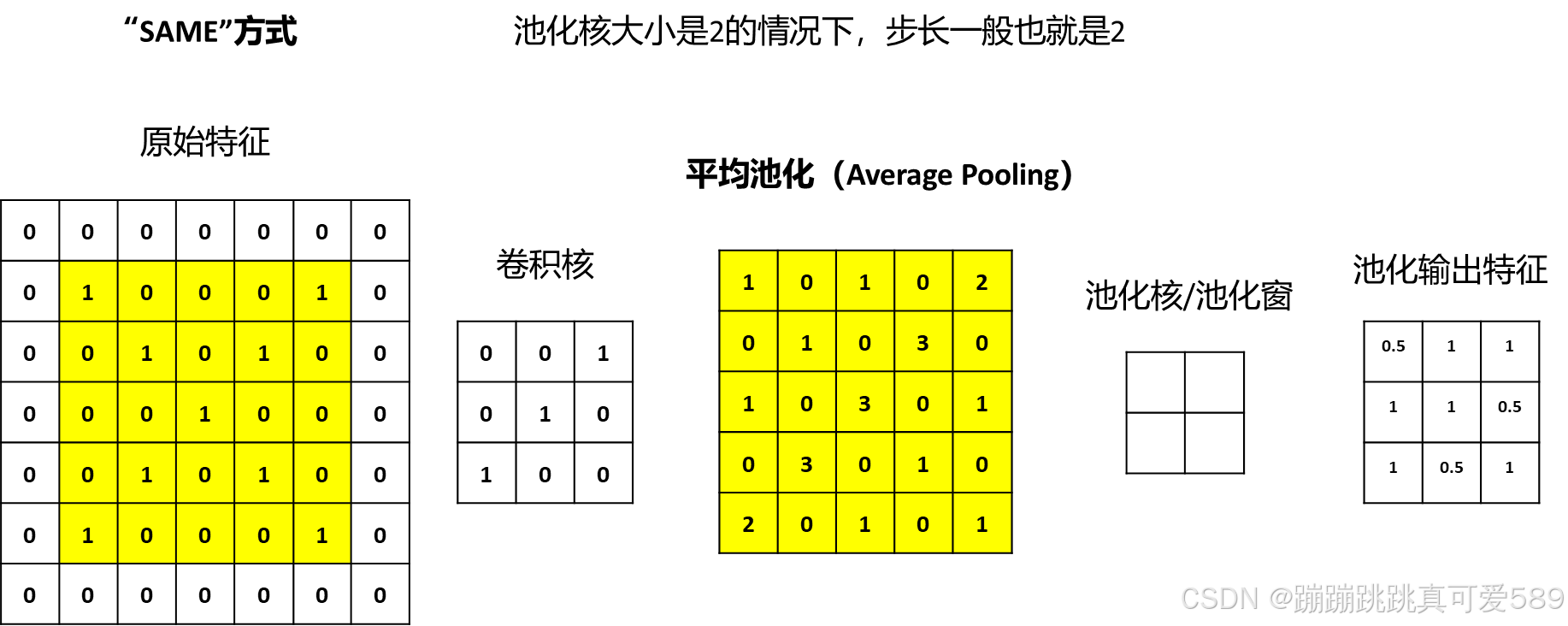
池化后的特征图具有以下特点:
-
尺寸缩减:例如,输入尺寸为224×224,经过多次池化后可能降至7×7。
-
特征不变性增强:对输入的小幅度平移、旋转或缩放不敏感(因池化窗口内的最大值可能保持不变)。
-
信息浓缩:保留高层语义特征(如物体的整体形状),忽略细节(如局部噪声)。
五、池化的作用
-
降低计算复杂度:减少特征图尺寸和参数量,加速模型训练和推理。
-
防止过拟合:通过压缩特征维度,减少模型对训练数据中噪声的敏感度。
-
增强平移不变性:物体在输入中的微小位置变化不影响特征提取结果。
-
突出关键特征:最大池化保留最显著特征,平均池化抑制局部波动。
-
扩大感受野:池化后的高层卷积核能覆盖更广的原始输入区域,捕获更高层次的语义信息。
import tensorflow as tf
# 输入特征张量
# [batch_size, input_height, input_width, in_channels]
# 这里创建了一个形状为 (1, 5, 5, 1) 的输入张量,代表一个批次,大小为5x5的图像,1个通道
input = tf.constant([[
[[1], [0], [0], [0], [1]],
[[0], [1], [0], [1], [0]],
[[0], [0], [1], [0], [0]],
[[0], [1], [0], [1], [0]],
[[1], [0], [0], [0], [1]]
]], dtype=tf.float32)
# 卷积核张量
# [kernel_height, kernel_width, in_channels, out_channels]
# 这里创建了一个形状为 (3, 3, 1, 1) 的卷积核,代表3x3的滤波器,1个输入通道,1个输出通道
wc1 = tf.constant([[
[[0]], [[0]], [[1]]],
[[[0]], [[1]], [[0]]],
[[[1]], [[0]], [[0]]]
], dtype=tf.float32)
# 创建卷积层
# 使用 tf.nn.conv2d 进行卷积操作,strides=[1, 1, 1, 1] 表示在每个维度上移动1步,padding='SAME' 填充使输出与输入相同大小
conv_layer1 = tf.nn.conv2d(input, wc1, strides=[1, 1, 1, 1], padding='SAME')
# 将卷积的输出转为 NumPy 数组
output1 = conv_layer1.numpy()
# 获取卷积层输出特征图的形状
batch_size = output1.shape[0] # 批次大小
height = output1.shape[1] # 高度
width = output1.shape[2] # 宽度
channels = output1.shape[3] # 通道数
# 打印卷积后特征图的形状和值
print(f"卷积后的特征大小: [batch_size={batch_size}, height={height}, width={width}, channels={channels}]")
print("输出特征图:", output1.reshape(height, width)) # 以 (height, width) 的形状打印输出特征图
# 添加池化操作
# 在卷积后的特征图上进行平均池化操作,ksize=[1, 2, 2, 1] 表示在 2x2 的区域内进行池化,strides=[1, 1, 1, 1] 表示步幅为 1,padding='SAME' 表示填充
pool_layer1 = tf.nn.avg_pool(conv_layer1, ksize=[1, 2, 2, 1], strides=[1, 1, 1, 1], padding='SAME')
# 获取池化后的输出特征图并将其转为 NumPy 数组
output_pool_layer1 = pool_layer1.numpy()
# 获取池化后输出特征图的形状
pool_batch_size = output_pool_layer1.shape[0] # 批次大小
pool_height = output_pool_layer1.shape[1] # 高度
pool_width = output_pool_layer1.shape[2] # 宽度
pool_channels = output_pool_layer1.shape[3] # 通道数
# 打印池化后的特征图的形状和值
print(f"池化后的特征大小: [batch_size={pool_batch_size}, height={pool_height}, width={pool_width}, channels={pool_channels}]")
print("输出特征图:", output_pool_layer1.reshape(pool_height, pool_width)) # 将池化后的输出特征图调整为 (pool_height, pool_width) 的形状并打印
















 1558
1558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









