






文章目录
问题:
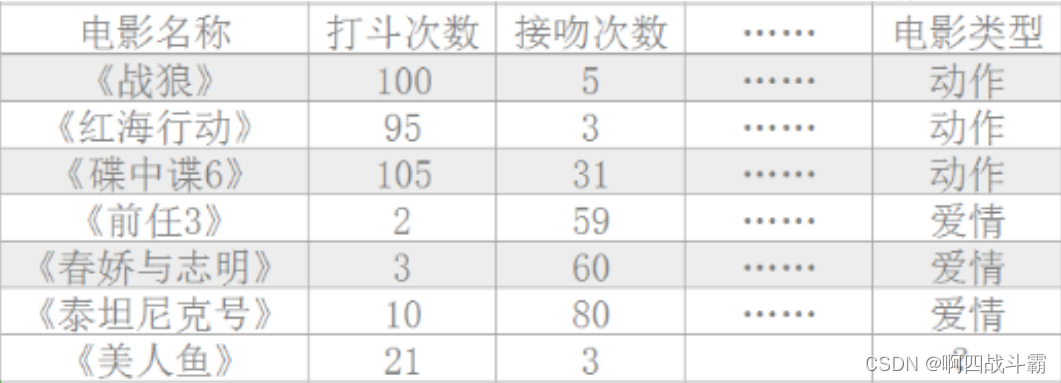
已知《战狼》《红海行动》《碟中谍 6》是动作片,而《前任 3》《春娇救志明》《泰坦尼克 号》是爱情片。但是如果⼀旦现在有⼀部新的电影《美人鱼》,有没有⼀种方法让机器也可以掌握⼀个分类的规则,自动的将新电影进行分类?
将数据进行可视化
因为如上表格的数据看起来并不直观,所以进行可视化。
代码如下:
# 数据可视化,直观观察电影数据分类
import matplotlib.pyplot as plt
# matplotlin默认情况下不支持中文的显示——通过rcParams配置参数
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
# 1.获取数据
# 2.数据基本处理
# 3.数据可视化
x = [5,3,31,59,60,80] # x轴代表接吻次数
y = [100,95,105,2,3,10] # y轴代表打斗次数
labels = ["《战狼》","《红海行动》","《碟中谍6》","《前任3》","《春娇与志明》","《泰坦尼克号》"]
# 设置刻度与标签
plt.scatter(x,y,s=120)
plt.xlabel("亲吻次数")
plt.ylabel("打斗次数")
plt.xticks(range(0,150,10))
plt.yticks(range(0,150,10))
# 给每个点添加注释文本
count = 0
for x_i,y_i in list(zip(x,y)): # 用zip将x,y进行打包,再转为列表
plt.annotate(f"{labels[count]}",xy=(x_i,y_i),xytext=(x_i,y_i))
count+=1
plt.show()
输出结果如图下所示:
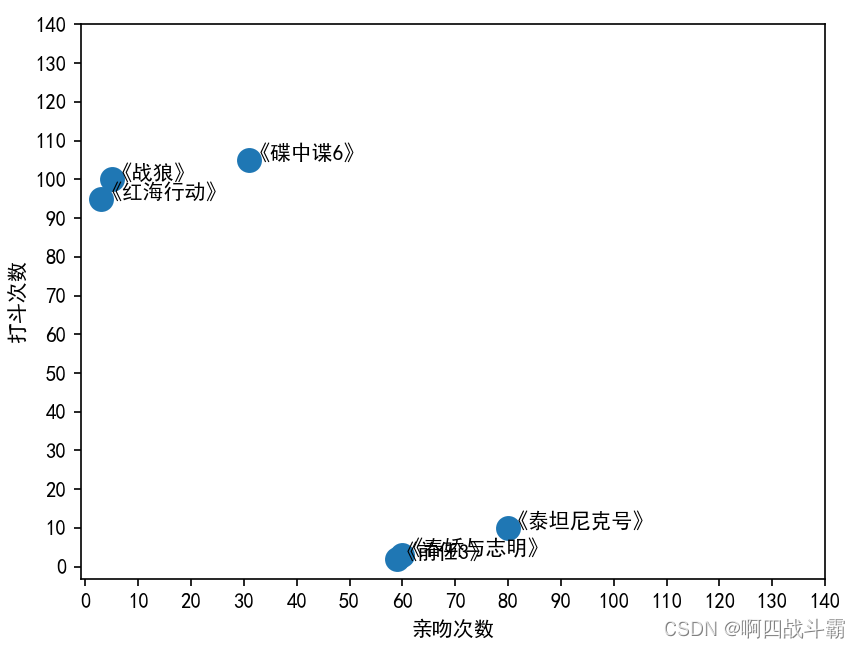
由此,对表格中的数据一目了然。
但我们并不知道《美人鱼》这个点到底离哪个点比较近,怎么计算《美人鱼》该点与其他各点的距离?——两点距离
两点距离也叫做欧氏距离: d = ( x 1 − y 1 ) 2 + ( x 2 − y 2 ) 2 d=\sqrt{\left ( x_{1} -y_{1}\right )^2+\left ( x_{2}-y_{2} \right )^2} d=(x1−y1)2+(x2−y2)2
具体了解文章:
概念到方法,绝了《统计学习方法》——第三章、k近邻法
现在的需求就是计算《美人鱼》与每个电影的距离。我们也许都会想,只找⼀个最邻近的邻居来判断《美人鱼》的类型不就行了吗?其实这种做法是不可行的。
举个栗子如下:

图中A同学与B、D两个同学的距离相等,而这两个同学分别在不同的区,那么就无法判断A同学是属于哪个区了。也就是说,应该多找几个近邻,才能更加准确的确定其分类。比如此处电影分类确定选取3个近邻,也就是说k=3。
在上篇文章(概念到方法,绝了《统计学习方法》——第三章、k近邻法)中已详细说明了KNN工作流程,在此简洁回忆一番。
总结KNN工作流程:
- 1.计算待分类物体与其他物体之间的距离;
- 2.统计距离最近的 K 个邻居;
- 3.对于 K 个最近的邻居,它们属于哪个分类最多,待分类物体就属于哪⼀类。
有以下两种实现方式:
1、Numpy实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
# 1. 准备数据
# 训练数据特征和目标
# 测试数据特征和目标
# 2. 计算未知数据特征和训练数据特征之间的欧式距离
# 3. 统计距离最近K个邻居
# 4. 进行类别统计
class Myknn(object):
def __init__(self, train_df, k):
"""
:param train_df: 训练数据
:param k: 近邻点个数
"""
self.train_df = train_df
self.k = k
# 计算预测数据 与 训练数据的 距离
# 选择距离最小k个值
# 计算k个值当中 的类别 占比
def predict(self, test_df):
"""预测函数"""
# 计算欧式距离——使用nupy计算距离
self.train_df['距离'] = np.sqrt(
(test_df['打斗次数'] - self.train_df['打斗次数']) ** 2 + (test_df['接吻次数'] - self.train_df['接吻次数']) ** 2)
# 按距离排序 获取距离最小的 前K个数据的类别
my_types = self.train_df.sort_values(by='距离').iloc[:self.k]['电影类型']
print(my_types)
# 对k个点的分类进行统计,看谁占得多,预测值就属于哪个类
new_my_type = my_types.value_counts().index[0]
print(new_my_type)
# 1. 读取数据
my_df = pd.read_excel('电影数据.xlsx', sheet_name=0)
# print(my_df)
# 2.数据基本处理
# 3.特征工程
# 4.数据可视化(省略)
# 2. 训练数据 特征化特征:打斗次数和接吻次数 初始化标签(类别):电影类型
train_df = my_df.loc[:5, ["打斗次数", "接吻次数", "电影类型"]]
# 3. 预测数据
test_df = my_df.loc[6, ["打斗次数", "接吻次数", ]]
# 4. 算法实现——实例化类
mk = Myknn(train_df, 3) # k=3
mk.predict(test_df)
输出结果:
3 爱情
4 爱情
5 爱情
Name: 电影类型, dtype: object
爱情
2、Sklearn实现
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=‘uniform’, algorithm=‘auto’)
- n_neighbors:默认情况下kneighbors查询使用的邻居数。就是k-NN的k的值,选取最近的k个点。临近点个数,即k的个数。(默认为 5)
- weights:默认为 “uniform” 表示为每个近邻分配同一权重,即确定近邻的权重;可指定为 “distance” 表示分配权重与查询点的距离成反比;同时还可以自定义权重。
- algorithm: 近邻算法,可选{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}。可选快速k近邻搜索算法,默认参数为auto,可以理解为算法自己决定合适的搜索算法;也可以自己指定搜索算法ball_tree、kd_tree、brute方法进行搜索,brute是蛮力搜索,也就是线性扫描。
步骤:
- 1、构建特征数据与目标数据
- 2、构建k个近邻的分类器
- 3、使⽤fit进行训练
- 4、预测数据
from sklearn.neighbors import KNeighborsClassifier
# 1.读取数据
mv_df = pd.read_excel("电影数据.xlsx",sheet_name=0)
# 2.构建训练集的特征数据——注意:二维的数组
x = mv_df.loc[:5,"打斗次数":"接吻次数"].values
# 3.构建训练集的目标数据——注意:一维的数组
y = mv_df.loc[:5,"电影类型"].values
# 4.实例化KNN算法(分类器)
knn = KNeighborsClassifier(n_neighbors=4)
# 5.进行训练——训练集的特征数据 训练集的目标数据
knn.fit(x,y)
# 6.预测数据
knn.predict([[5,29]])
输出结果:
['爱情']
所以,通过训练KNN模型,最终得出《美人鱼》是一部爱情片。
学习心得:
博主立志于搞懂每一个知识点。为什么呢?之前看过一位大佬的学习经验分享的文章,其中讲到一点非常好:【基础知识就像一座大楼的地基,它决定了我们的技术高度,而要想快速做出点事情,前提条件一定是基础能力过硬,“内功”到位】。因此,从此之后我便专注于扎实基础,而且我也知道,学技术并不是一朝一夕就能学到家的,没有个半年、一年,或两年,甚至更久;但我相信,坚持总不会错的。最后,我想说:注重基础,建立属于自己的知识体系。
好了,本次学习分享到此为止蛤。劳逸结合——上面的七部电影你看过几部?最喜欢哪一部呢?评论区告诉我呗!嘿嘿,,忍不住的赶紧去看了再学习吧。
















 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











