






ps. 菜鸡本科生借助百度翻译进行的第一篇论文翻译,建议参考原文
文章目录
CodeXGLUE:用于代码理解和生成的机器学习基准数据集
摘要
基准数据集可以显著促进在编写程序语言任务方面的研究。在这篇论文中我们介绍了CodeXGLUE,这是一个基准数据集,用于促进“程序理解和生成”的机器学习研究。CodeXGLUE包含 14个数据集上的10个任务,以及一个用于模型评估和比较的平台。CodeXGLUE还具有三个基准线系统,包含BERT风格,GPT风格和Encoder-Decoder模型,以此使研究者更容易使用该平台。这些数据和基准线可以帮助开发和验证那些被应用到各种程序理解和生成问题中的新方法。
关键词
程序理解;机器学习;软件的自然性
1 引言
Evans数据公司估计,在2019年有2390万专业的开发人员,而且这一数字在2024年将达到2870万。随着开发者的数量以这样的速率增长,利用人工智能来帮助软件开发者提升开发效率的“代码智能”正变得日益重要。人们普遍认为,基准对于应用AI研究的发展有重大影响。在这篇论文中,我们致力于建立为代码智能建立一个基准数据集。
自动化的程序理解和生成可以提升软件开发者的生产效率。事实上,有些开发者想要找到和他们有着相同意图的人编写的代码,这些开发者可以利用代码搜索系统,从而通过使用自然语言查询来自动化地检索到语义上相关的代码。类似的,对于下一步要写什么感到困惑的开发者可以使用代码完成系统,基于对代码已有的编辑,自动化的完成接下来的token。最后,当开发者想要用Python实现Java代码时,code-to-code(代码到代码)的翻译系统可以帮忙将代码从一种编程语言(如Python)翻译到另一种语言(如Java)。
近年来,研究人员越来越多地将包括神经网络在内的统计模型应用于代码智能任务。最近,受到像BERT、GPT这样的预训练模型在自然语言处理(NLP)领域的巨大成功的启发,从大量编程语言数据中学习得到的预训练模型获得应用。这些模型,包括CodeBERT和IntelliCode Compose,已经引发了在代码理解和生成问题上的进一步改善,但是它们缺乏涵盖广泛任务的一整套基准测试。计算机视觉领域的ImageNet和NLP领域的GLUE的使用已经表明,多样化的基准数据集对于应用AI研究的发展有着重大影响。
为了解决这个问题,我们引入了CodeXGLUE,这是一个用于程序理解和生成研究的机器学习基准数据集,包含了14个数据集,10个多样化的编程语言理解和生成任务,以及一个模型评估和比较的平台。CodeXGLUE支持以下任务:
- code-code(从代码到代码)(包括:克隆检测、缺陷检测、完型填空、代码完成、代码修复、从代码到代码的翻译)
- text-code(从文本到代码)(包括:自然语言代码搜索、文本到代码的生成)
- code-text(从代码到文本)(包括:代码摘要)
- text-text(从文本到文本)(包括:文件翻译)
CodeXGLUE包括8个先前提出的数据集——BigCloneBench、POJ-104、Devign、PY150、Github Java Corpus、Bugs2Fix、CONCODE和CodeSearchNet——但也新引入了在 表1中强调的数据集。数据集是在考虑了“任务有明确的定义并且数据集的大小可以支持数据驱动的机器学习方法的开发和评估”的基础上进行选择或者创建的。由我们创建的数据集包括:两个包含6种编程语言的完形填空测试集、两个分别使用Java和Python的行级代码完成测试集、一个在Java和C#之间进行的code-to-code翻译数据集、两个分别使用“web查询”和“规范化函数和变量名”的自然语言代码搜索测试集、以及一个覆盖了5种自然语言的文档翻译数据集。
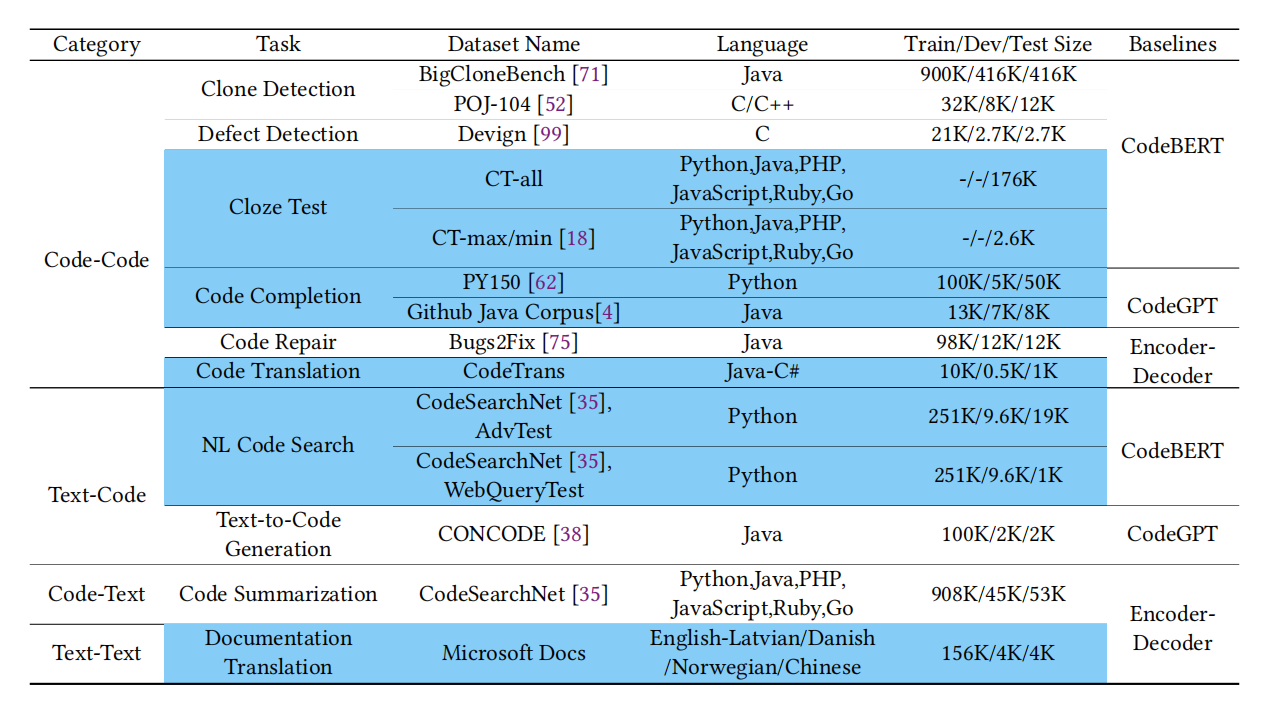
表1 CodeXGLUE的一个简单的总结,包含了任务、数据集、语言、各种状态下的大小、以及基准线系统。高亮的数据集是新引入的。
为了让参与者容易使用,我们提供了三个基线系统来帮助执行任务,包括支持代码理解问题的BERT风格的预训练模型(本例中为CodeBERT),用来帮助解决完成和生成问题的GPT锋哥的预训练模型(我们称之为CodeGPT),以及解决从序列(sequence)到序列的生成问题的Encoder-Decoder框架。
2 任务概述
在本节中,我们为每个任务提供一个定义。
- 克隆检测: 任务是测量代码之间的语义相似性。这包含两个子任务:一对代码之间的二进制分类、以及代码检索,目标是找到语义相似的代码。
- 缺陷检测: 目标是确定源代码体是否包含可用于攻击软件系统的缺陷,如资源泄漏、释放后使用漏洞和DoS攻击。
- 完形填空测试: 旨在于预测一个代码中的掩码标记,包含两个子任务。第一个是从整个词汇表中测量预测掩码标记的准确性。另一个是通过区分“max”和“min”来测试语义推理能力。
- 代码完成: 它旨在于根据代码的上下文预测接下来的token。它的子任务是token级别的代码完成和行级别的代码完成。前者检查了下一个token是否被正确预测,而后者检查了生成的行有多好。
- 代码翻译: 它涉及到将代码从一种编程语言翻译成另一种。
- 代码搜索: 它测量文本和代码见的语义相关性。它由两个子任务构成。第一个是根据自然语言询问,从一些列代码中找到最相关的代码。第二个子任务是分析 询问-代码 对,来预测代码是否回答了询问。
- 代码修复: 它的目标是通过自动化的修复bug来完善代码。
- **文本到代码的生成:**旨在于通过自然语言描述生成代码。
- 代码摘要: 目标是为代码生成自然语言注释。
- 文件翻译: 目标是将代码文档从一种自然语言翻译到另一种。
3 数据集
在本节中,我们将描述CodeXGLUE中的数据集。基于数据集的大小足够支持数据驱动的机器学习方法的开发和评估的标准,数据集被选择或者创建。
3.1 克隆检测
克隆检测包含两个子任务。第一个子任务是检查两个给定的代码是否有相同的语义。我们为这个子任务使用了BigCloneBench数据集。第二个子任务的目标是,给定一个代码作为询问,检索语义相似的代码。我们使用数据集POJ-104来执行它。
- BigCloneBench 是一种被广泛使用的大型代码克隆基准测试,包含来自10个不同的功能的6000000多个值为真的克隆对和260000多个值为假的克隆对。Wang等人提供的数据集通过丢弃没有任何标记的真或假克隆对的代码片段进行过滤,留下了9134个Java代码片段。最后,数据集分别为训练、验证和测试准备了901028、415416、415416个示例。
- POJ-104 数据集来自一个教学编程开放判断(OJ)系统,它通过运行代码来自动化地判定提交的代码对于特定的问题的有效性。我们使用POJ-104数据集,该数据集由104个问题组成,对于每个问题包含了500个学生写的C/C++程序。不同于BigCloneBench数据集,POJ-104的任务目标是,在给定一个程序的情况下,检索完成相同问题的其他程序。我们根据训练、验证和测试所需解决的问题数量(64/16/24),将数据集分为3个子集。
3.2 缺陷检测
对于缺陷检测任务,Zhou等人提供了Devign数据集,包含了27318个人工标注的函数,这些函数从两个受开发者欢迎且功能多样化的大型C语言开源项目中收集,即QEMU和FFmpeq这两个项目。通过收集与安全相关的提交、并从这些提交中提取出容易受攻击的或不容易受攻击的函数,这个数据集被创建了出来。由于Zhou等人没有为这两个项目提供官方的训练/验证/测试集,我们队数据进行了随机洗牌,然后分割为80%/10%/10%三部分分别用于训练/验证/测试。这个任务被公式化为一个二进制分类,用来预测一个函数是否容易被攻击。
3.3 完型填空测试
图1显示了在代码域进行完型填空测试(CT)任务的两个例子。该任务的目的是,通过要求那些模型从几个候选者中预测掩码代码,来评估模型理解代码的能力。我们专注于两个子任务:使用过滤过的词汇表中的所有的词作为候选者的CT-all,和使用“max”和“min”作为候选者的“CT-maxmin”。

图1:完型填空测试数据集中的两个例子
我们使用CodeSearchNet中的验证和测试集来为六种编程语言创建CT-all和CT-maxmin数据集,这六种语言是Go,Java,JavaScript(JS),PHP,Python和Ruby。
CT-all。为了减少引入冗长的变量名、避免由于使用不同分词器引发的问题,我们通过在Byte Pair Encoding(字节对编码)之后保留特定的单词来选择完型填空的目标单词,并且我们使用手工规则移除了没有意义的token(词),比如标点符号。最后,六种语言中共计930个词(token)被选择。我们选择包含着930个词的代码 ,然后手动设置了词(token)出现的阈值,从而平衡930个词在CT-all中出现的频率。
CT-maxmin。 为了进一步评估模型理解代码语义的能力,我们引入了CT-maxmin来测试模型区分max和min的差异的能力有多好。CT-maxmin来自CodeBERT用于PL-Probing任务的数据集,该数据集中有包含以max或min为关键字的代码。
数据统计如表2所示。
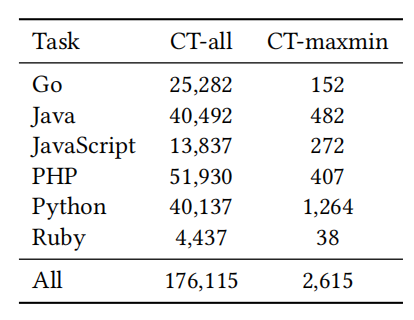
表2:关于完型填空数据集的数据统计
3.4 代码完成
我们为代码完成使用了两个有影响力的数据集:Python语言的PY150和Java语言的Github Java Corpus。这两个数据集都可以帮助实现token级别的代码完成。更进一步,从这两个语料库,我们为行级别的代码完成任务创建了两个测试集。这个任务是完成一个未完成的行。模型应当能够预测有着任意token类型和代码结构的代码序列。
PY150 是一个Python数据集,包含了从Github收集的150000个Python源文件。我们遵循Raychev等人的数据分割,得到100000个文件用来训练,50000个文件用来测试,二者分别包含了7630万个token和3720万个token。通过对源代码进行分词、移除注释、用空字符串替换长度超过15个字符的字符串、添加特殊的token <EOL>(end-of-line,行尾)来明确标记行尾,我们对语料库进行了预处理。对于行级代码完成,我们从PY150测试集的不同文件中创建了10000个示例用于测试。由于我们打算测试模型自动完成一个随机行的能力,所以我们随机选择了要预测的行。我们通过确保有足够的上下文 来 生成测试数据,即至少占整个文件的15%。模型被期待在被给定上下文的情况下,生成以为结尾的下一行。输入和输出的平均token数分别是489.11和6.56。图2展示了一个行级代码完成的例子。

图2:行级别代码完成数据集中的一个例子
GitHub Java Corpus是被Allamanis和Sutton挖掘的Java数据集,它从Github上收集了超过1.4万个Java项目。我们遵循由Hellendoorn、Devanbu以及Karampatsis等人建立的设置,使用语料库中1%的子集。我们有12934/7189/8268个文件用于训练/验证/测试,它们分别由1580万/380万/530万个token组成。我们进行了 和PY150一样的预处理,但是,我们没有添加特殊的token<EOL>,因为在Java中,;和}被用来标记代码语句的结束。对于行级的代码完成,我们从语料库测试集的不同文件中创建了3000个示例用于测试。与我们队Python所遵守的过程类似,要预测的行是从测试文件中随机选择的。输入和输出的平均token数分别为350.62和10.49。
3.5 代码翻译
代码翻译的训练数据是用两种编程语言的等效功能的代码对。在这篇论文中,我们提供了一个由Java和C#之间的并行代码组成的数据集。我们没有使用Lachaux等人的数据集,因为他们没有为监督模型训练的数据。继Nguyen等人和Chen等人之后,我们使用了从几个开源项目中收集的数据,即Lucene、POI、JGit和ntlr这几个开源项目。由于许可证问题,我们没有使用ltext和JTS。这些项目最初用Java开发,然后被移植到C#。他们是被建立很好的系统,有着悠久的开发历史,同时使用Java和C#版本。
接下来的步骤是从这些项目中挖掘成对的函数和方法。根据我们的观察,当两个版本被应用到同一个项目时,它们的目录结构、函数或方法的名字 是相同的或者相似的。因此,继Nguyen等人之后,我们谨慎地搜索了那些在两个版本中,属于有着相同或相似名字的类、有着相同的署名、且包含在相同或相似的目录结构中。我们丢弃了重复的代码对和那些使用上述方法搜索后有多个目标的代码。在这一步后,我们移除了那些重叠token数少于句子长度1/3的代码对。为了使我们的数据对于进一步的语法和语义分析具有更好的拓展性,我们还移除了那些 根据抽象语法树(AST) 函数主体为null的函数。然后我们为每个函数构建了数据流图,它表示了两个变量之间的以来关系,并为代码理解提供了有价值的语义信息。最后,没有从特定函数的AST中提取出数据流的函数也被丢弃了。
最后,配队的函数或方法的综述是11800。我们随机地为开发集选择了500对函数,又为测试集另选了1000对。在分词之后,Java和C#函数的平均长度分别为38.51和36.16。图3展示了挖掘的一个从C#到Java的翻译对的例子。

图3:代码翻译数据集中的一个例子
3.6 代码搜索
代码搜索包含两个子任务。第一个是给定一个自然语言询问,从一系列候选者中找到最相关的代码。我们从CodeSearchNet语料库中创建了一个有挑战的测试集用于执行这个任务,该数据集被称为CodeSearchNet AdvTest。该数据集的一个例子在图4中被展示。第二个子任务是判断一个代码是否回答了一个给定的询问。我们提供了一个真实用户查询的测试集WebQuery Test。该数据集的两个示例如图5所示。

图4:CodeSearchNet AdvTest数据集中的一个例子

图5:WebQueryTest数据集中的两个例子
CodeSearchNet AdvTest 是一个来自CodeSearchNet语料库的Python数据集。每个示例包含一个配有文档的函数。我们遵循Husain等人,选择文档的第一段作为相应函数的询问。为了提升数据集的质量,我们通过移除以下示例来过滤它。
(1)代码无法被解析为抽象语法树(AST)的示例。
(2)文档token数小于3或者多于256的示例。
(3)文档中包含例如“http://”这样特殊token的示例。
(4)文档是空的,或者不是用英文编写的示例。
在这一系列流程之后,我们获得了一个数据集,其中有251820/9604/19210个例子用于训练/验证/测试。在用特殊token归一化函数名或变量名之后,我们观察到,在Python语言中,RoBERTa和CodeBERT在CodeSearchNet数据集的平均倒数排名(MRR)分数分别从0.809和0.869降至0.419和0.507。为了更好地测试模型的理解和生成能力,我们在测试和开发集中归一化了函数名和变量名,例如,使用
f
u
n
c
func
func代表函数名,使用
a
r
g
i
arg_i
argi代表第
i
i
i个变量名。图4展示了CodeSearchNet AdvTest数据集中一个例子。这个任务旨在于为一个自然语言查询从候选者中查找源代码。与先前只涉及1000个候选者的测试阶段的工作相反,我们为每个询问使用整个测试集,这使得CodeSearchNet AdvTest数据集更加困难。这个任务的训练集来自过滤的CodeSearchNet数据集。
WebQueryTest:绝大多数代码搜索数据集使用为软件开发者准备的线上社区里代码文档或问题作为询问,但是这和真实用户的搜索询问不同。为了解决这个差异,我们提供了WebQueryTest,一个Python语言的真实代码搜索测试集。这个问题被构筑为一个二元的分类任务和对于检索场景的补充设置。给定一堆询问和代码函数,一个模型需要区分这个代码是否能够回答询问。
数据创建过程可以被分为两个阶段:数据收集和注释。我们首先从一个商业搜索引擎的网络查询日志中收集真实用户的查询,并且我们保留有“python”的查询。受Yan等人的启发,我们设计了一些基于关键词精确匹配的启发式算法来滤除没有代码搜索意图的询问。然后,我们从CodeSearchNet的Python验证集和测试集中为每一个询问选择候选代码。为了缩小每个查询要注释的候选者,我们根据由CodeBERT计算出的最高查询代码相似度,选择排名前2名的函数。CodeBERT是基于代码的检索模型,在148K具有自动思想的Python栈溢出问题代码(148K automated-minded Python Stack Overflow Question-Code, StaQC)上训练,模型默认参数由Feng等人提供。
我们使用一个两个阶段的注释模式来为每个实例做标记。第一步是判断询问是否有代码搜索意图。没有代码搜索意图的询问被标记为“-1”。第二步是评估代码(和它的文档)是否可以回答询问。标记为“1”的实例是代码可以回答查询的询问。否则,它们将被标记为“0”。两个例子如图5所示。我们邀请了13位精通Python的开发者来标记1300个实例,每位注释人员处理100个。在注释期间讨论是被允许的。最终,被标记为-1,0,1的实例数量分别为254,642,422。由于我们对询问代码匹配更感兴趣,所以我们最后的测试集中只包含类别0和类别1。我们用于这个任务的训练和验证集来自原始的CodeSearchNet数据集。
3.7 代码修复
代码修复旨在于自动修复代码中的bug。我们使用由Tufano等人发布的数据集。源是有缺陷的Java函数,而目标是相应的修复的函数。为了构建这个数据集,他们首先从GitHub Archive上下载2011年3月到2017年十月之间的每一个公共GitHub事件 (原文为event) ,然后使用Google BigQuery APIs 来识别所有信息中包含如下特征的Java文件提交:(“fix”或“solve”)和(“bug”或“issue”或“problem”或“error”)。对于每个修复bug的提交,他们通过使用GitHub Compare API来手机有缺陷的(提交前的)和修复的(提交后的)代码,从而提取修复前后的源代码。随后,他们规范化了所有变量和自定义方法的名字,这极大的限制了词库的大小,并使得模型专注于学习bug修复模式。然后,他们滤掉了那些在有缺陷的代码和修复后的代码中都包含语法和语义错误的代码对,还滤掉了那些修复前后 相差超过100个原子AST修改操作的对。为了实现这一点,他们使用了GumTree Spoon AST Diff工具。最终,他们基于代码长度把整个数据集分为两个子集(小的token数
≤
50
\leq50
≤50,中等大小的token数
>
50
\gt 50
>50且
≤
100
\leq100
≤100)。对于小的子集,训练、开发、测试的例子样本数分别为46680、5835和5835,对于中等大小的子集,数量分别为52364、6545、6545。
3.8 文本代码生成
为了执行这个任务,我们使用了CONCODE,一个被广泛使用的代码生成数据集,从GitHub上大约33000个Java项目中收集获得。它包含100000个例子用于训练和4000个例子用于验证和测试。每一个例子是由NL(自然语言)描述、代码环境和代码片段组成的元组。这个数据集的任务是从自然语言描述(Javadoc风格的方法注释)和类环境生成类成员函数。类环境是由类的剩余部分提供的编程上下文,包括类中的其他成员变量和其他成员函数。
3.9 代码摘要
对于代码摘要,我们使用了CodeSearchNet数据集,包含了6种编程语言,即Python、Java、JavaScript、PHP、Ruby和Go。数据来自公开的开源非分叉GitHub库,每个文档是第一段。我们观察到,一些文档包含了和函数不相关的上下文,例如像http://...这样指向一个外部资源的链接,以及用于插入图片的HTML图片标记<img...>。因此,为了提升数据集的质量,我们使用了在3.6节提到的四种规则来对数据集进行了过滤。
表3列出了CodeXGLUE中使用的过滤后的CodeSearchNet数据集的统计数据。
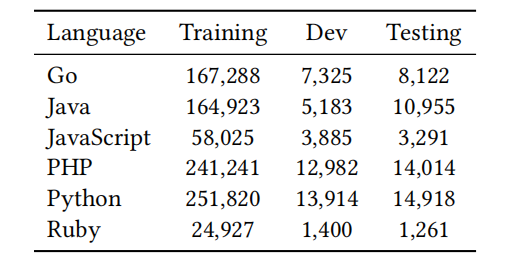
表3:用于代码摘要任务的过滤后的CodeSearchNet数据集的统计数据
3.10 文档翻译
文档翻译的目标是将代码文档自动地从一种自然语言(如英语)翻译到另一种自然语言(如中文),如图7所示。我们使用的数据集是从Microsoft Documentation中爬取的,其中包括不同语言的软件和代码描述文档。我们专注于低资源的语言对,在那里并行数据很稀少。我们引入多语言的机器翻译任务,例如,英语 ⇔ 拉脱维亚语、丹麦语、挪威语、汉语。为了提高数据质量,我们通过移除下面的示例来过滤语料库。
(1)源句与目标句一样的对;
(2)源语言或目标语言少于三个词的对;
(3)源语言和目标语言之间的长度比例大于3的对;
(4)由fast_align计算的字对齐比例小于0.6的对。
最终的训练数据在英语⇔拉脱维亚语、英语 ⇔丹麦语、英语 ⇔挪威语和英语 ⇔中文上分别包含43K、19K、44K和50K的句子对。

图7:在文档翻译数据集中的一个英语转中文的例子
4 基准线系统
我们提供了三种类型的基准线模型来执行前面提到的任务,包括支持程序理解问题的BERT风格的预训练模型(在本例中为CodeBERT),帮助我们解决完成和生成问题的、被叫做CodeGPT的GPT风格的预训练模型,以及处理从序列到序列的生成问题的Encoder-Decoder框架。三种管线的示意图如图6所示。
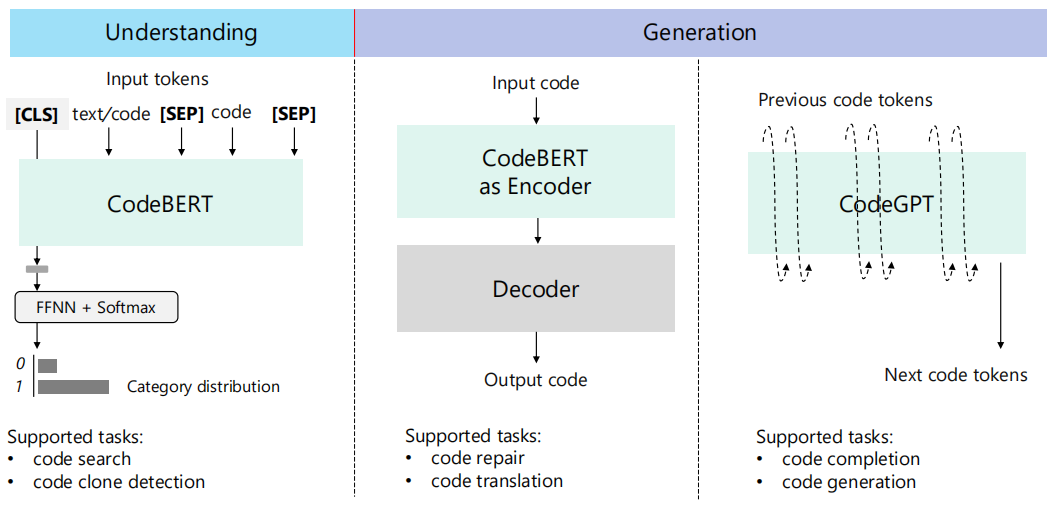
图6:三个管线被提供,包括CodeBERT、CodeGPT以及:Encoder-Decoder
4.1 CodeBERT
为了执行像克隆检测、缺陷检测、完型填空和代码搜索这样的代码理解任务,我们使用CodeBERT作为我们的编码器,这是一个基于Transformer的双峰预训练模型,该Transformer有12层、768维的隐藏状态以及12个用于编程语言(PL)和自然语言(NL)的注意力头。Feng等人通过掩码的语言模型和在CodeSearchNet数据集上的替代的token检测目标来预训练CodeBERT模型,其中CodeSearchNet数据集中包含6种编程语言的2.4M个具有文档对的函数。模型支持不同类型的输入序列,像text/code和code/code,在序列前使用特殊标记[CLS]并使用特殊标记[SEP]来拆分两种数据类型。
模型公开在https://huggingface.co/microsoft/codebert-base。
4.2 CodeGPT
我们提供了CodeBERT,这是一个在编程语言(PL)上预训练的、基于Transformer的语言模型,用来支持代码完成和从文本到代码的生成任务。CodeGPT和GPT-2有着相同的模型结构和训练目标,其由12层Transformer解码器组成。表4列出了更多模型设置。我们利用CodeSearchNet数据集的Python和Java语料库训练了单语的模型。CodeSearchNet数据集中包含了1.1M的Python函数和1.6M的Java方法。训练数据集中的每一个函数都有一个函数签名和函数主体。有些函数也包含自然语言文档。
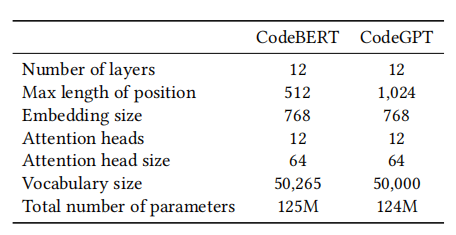
表4:CodeBERT和CodeGPT模型的参数
我们为每个编程语言训练了两个模型。一个模型是从头开始预训练的,所以BPE(byte pair encoder,字节对编码器)词汇表是从代码语料库中新获得的,模型参数是随机初始化的。另一个模型是域适应,它使用了GPT-2作为起点并在代码语料库上不断训练。结果,因此,第二个模型和GPT-2有着一样的词库和自然语言理解能力。我们称这个模型为CodeGPT-adapted,并将其视作代码完成和从文本到代码的生成任务的默认模型。
模型公开在https://huggingface.co/microsoft/CodeGPT-small-java和https://huggingface.co/microsoft/CodeGPT-small-java-adaptedGPT2。
4.3 Encoder-Decoder
对于像代码修复、代码翻译、代码摘要和文档翻译这样的从序列到序列的生成问题,我们提供了一个Encoder-Decoder框架。我们使用CodeBERT初始化编码器,并在所有设置中,使用随机初始化的、有6层、768维隐藏状态和12个注意力头的Transformer作为解码器。
5 实验
在本节中,我们报告了基准线系统在10项任务上的准确度数字。我们也将展示训练模型和在模型上进行推理需要多长时间。
5.1 克隆检测
设定。我们使用BigCloneBench和POJ-104数据集用于克隆检测。BigCloneBench数据集的任务被公式化为一个二元分类任务,用来预测一对给定的代码是否有着相同语义,使用F1分数作为评估指标。POJ-104数据集的任务旨在于从 用于验证\测试的开发\测试集 中 为了一个给定的代码检索499个代码,以平均精度(MAP)作为评估指标。克隆检测任务的总得分是F1和MAP得分的平均值。
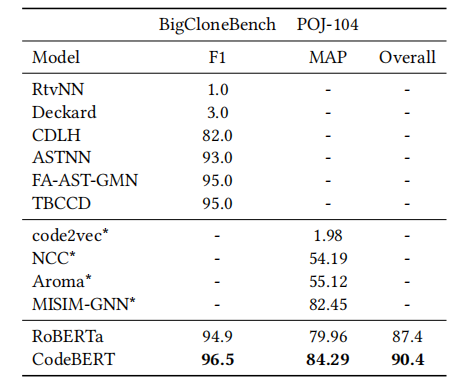
表5:克隆检测任务的结果
结果。不同模型获得的结果如表5所示。RtvNN训练了一个递归自动编码器来学习AST的表示。Deckard计算AST中结构信息的向量,并使用局部敏感哈希(LSH)来对类似向量进行聚类。CDLH通过基于AST的LSTM学习代码片段的表示。ASTNN使用RNN来对语句的AST子树进行编码。它将所有语句树的编码喂给一个RNN网络来学习程序的表示。FA-AST-GMN在流增强AST上使用GNN来利用显式控制和数据流信息。TBCCD提出一种位置感知字符嵌入方法,并使用基于树的卷积从代码片段的AST中捕获代码片段的结构信息和从代码token中捕获词汇信息。Code2vec通过将多个句法路径聚合到一个单独的向量来学习代码片段的表示。NCC通过利用程序的底层数据流和控制流来对程序进行编码。Aroma是一个代码推荐引擎,它采用部分代码片段然后推荐一个小的简洁代码片段的集合,这个集合中包含了询问片段。MISIM-GNN从上下文感知语义结构中学习了代码的结构化表示,该语义结构专门用于从代码语法中提升语义。
在这个实验中,我们使用了像RoBERTa和CodeBERT这样的预训练模型对源代码进行编码,并通过前馈神经网络或内积计算两个代码的语义相关性。尽管CodeBERT没有利用已被证明在代码相似性度量方面有效的代码结构,这个模型依然在克隆检测任务上表现的比RoBERTa好,总体得分为90.4。这些实验结果表明,预训练对于克隆检测是有用的。如果进一步利用代码结构,还有进一步的提升空间。
5.2 缺陷检测
设置。对于缺陷检测,我们使用3.2节中提到的数据集,该数据集的目的是预测一个源代码中是否包含可以被用来攻击软件系统的缺陷。评估指标是准确度分数。我们使用CodeBERT基准线来编码源代码,并采用源代码的表示来计算暴露于漏洞的概率。
结果。表7展示了我们实现的模型的结果。我们使用双向LTSM(BiLSTM)、TextCNN、RoBERTa和CodeBERT分别对源代码的表示进行编码。然后,使用一个双层的前馈神经网络和一个softmax层来计算遇到缺陷的概率。如结果所示,CodeBERT到达了62.1的准确度分数,实现了最先进的性能。然而,与TextCNN相比,预训练模型所得的提升是有限的。提升这些预训练模型的一个潜在方向是合并代码结构的信息,如抽象语法树、数据流、控制流等。
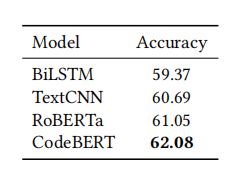
表7:缺陷检测任务的结果
5.3 完型填空
设置。我们使用CT-all和CT-maxmin数据集来完成完形填空任务。模型被期待利用文档和代码上下文来预测屏蔽的代码token。每一种语言的准确度都被报告,并使用所有语言的宏观平均准确度分数作为总体评估指标。
结果。 表6展示了在CT-all和CT-maxmin数据集上的结果。我们报告了RoBERTa和CodeBERT(掩蔽语言建模,MLM)模型的表现。CodeBERT是用RoBERTa初始化的,并使用掩蔽语言建模目标进一步训练。结果表明,CodeBERT的性能优于仅从自然语言中学习的RoBERTa。

表6:完型填空任务的结果
5.4 代码完成
设置。我们使用PY 150和Github Java Corpus数据集用于token级和行级代码翻译任务。token级任务是给定先前token的上下文,预测下一个token,并根据token级的准确性来评估预测;而行级任务需要完成整行的代码, 并且通过称为精确匹配准确性和Levenstein编辑相似性的度量来评估代码的质量。Levenstein编辑相似性度量将一个字符串转换为另一个字符串所需的单个字符编辑次数。这是代码完成场景的一个关键评估指标,因为它衡量开发人员纠正代码中错误所需的工作量。每个数据集上的得分是token级完成的准确性和行级完成的编辑相似性的平均值。代码完成任务的总体得分是通过对两个数据集上的得分进行平均来计算的。
结果。表8显示了两个数据集上所有模型的结果。我们微调LSTM、Transformer、GPT-2、CodeGPT和CodeGPT-adapted,以生成接下来的令牌。CodeGPT和CodeGPT-adapted 模型在4.2节中进行了描述。CodeGPT-adapted实现了最先进的性能,总分为71.28。
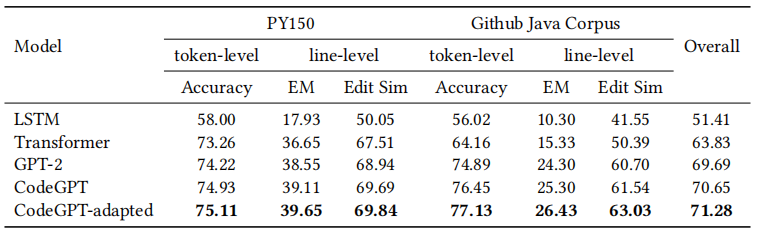
表8:代码完成任务的结果
5.5 代码搜索
设置。我们将3.6节中提到的CodeSearchNet AdvTest和WebQueryTest数据集用于代码搜索。为了提高效率,我们分别对文本和代码进行编码以执行代码搜索。对于CodeSearchNet AdvTest数据集,任务是给定一个查询,从一系列候选代码中找到最相关的代码,并通过平均倒数排名(MRR)度量对其进行评估。对于WebQueryTest数据集,任务被公式化为二元分类,以预测代码是否可以回答给定的查询,我们使用F1和准确度得分作为评估指标。代码搜索的总得分是为两个子任务得分的平均值。
结果。表9显示了在CodeSearchNet AdvTest和WebQueryTest数据集上的结果。我们报告了RoBERTa和CodeBERT的表现。该表显示CodeBERT的表现优于RoBERTa。
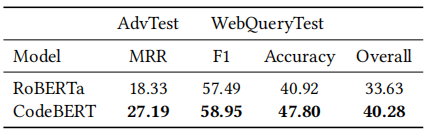
表9:代码搜索任务上的结果
5.6 文本代码生成
设置。我们将CONCODE数据集用于从文本到代码的生成。在给定自然语言描述和类环境的情况下,模型被期待生成Java类成员函数的源代码。我们报告了准确的匹配精度、BLEU分数和CodeBLEU分数。我们使用CodeBLEU分数作为总体评估指标。
结果。表10呈现了在CONCODE测试集上的结果。Seq2Seq是一种基于RNN的序列到序列模型。Seq2Action + MAML将上下文感知检索模型与模型不可知元学习(MAML)相结合。Iyer-Simp + 200 idoms提取代码惯用语并应用基于惯用语的解码。我们还报告了预训练模型的性能,包括GPT-2、CodeGPT和CodeGPT-adapted模型。CodeGPT自适应实现了35.98的CodeBLEU分数,从而实现了最先进的性能。
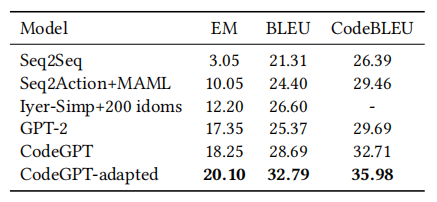
表10:在文本转代码生成任务上的结果
5.7 代码翻译
设置。我们使用我们3.5节构建的数据集。该数据集包含Java和C#函数的匹配示例。我们报告了该任务的精确匹配精度、BLEU分数和CodeBLEU分数。CodeBLEU被用作总体评估度量。
结果。表12显示了两个方向进行翻译的模型结果。Naive方法直接复制源代码作为翻译结果。PBSMT是基于短语的统计机器翻译(phrase-based statistical machine translation)的缩写。Transformer使用与预训练模型相同的层数和隐藏大小。该表显示,使用CodeBERT初始化并使用相应的样本对进行微调的Transformer会产生最佳结果。
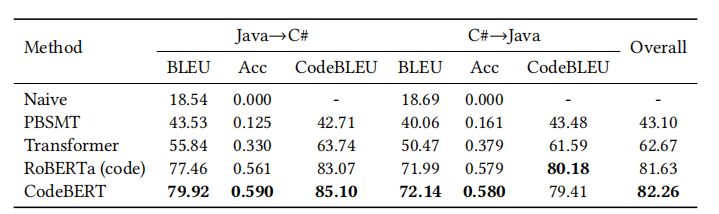
表12:在代码翻译任务上的结果
5.8 代码维修
设置。我们使用3.7节中描述的、由Tufano等人最初发布的数据集。数据集包含根据Java函数长度建立的两个子集:small≤50和50<medium≤100。我们报告了该任务的精确匹配精度、BLEU分数和CodeBLEU分数。精确匹配精度被用作总体评估度量。
结果。Naive方法直接复制有缺陷的代码作为修复结果。至于Transformer,我们使用与预训练模型相同的层数和隐藏大小。关于CodeBERT方法,我们使用预训练的CodeBERT模型初始化Transformer编码器,并随机初始化解码器和源到目标注意力(source-to-target attention)。然后我们使用训练数据对整个模型进行微调。如表所示,带有CodeBERT初始化的Transformer在所有模型中实现了最佳性能。
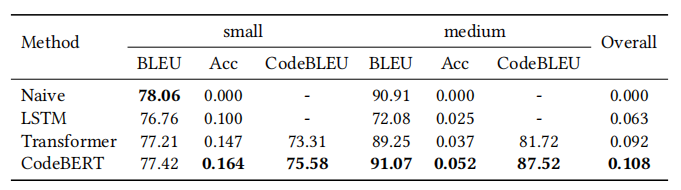
表11:代码修复任务的结果
5.9 代码摘要
设置。我们将3.9节中提到的数据集用于代码摘要任务。为了评估模型,我们遵循Feng等人的观点,他们使用平滑的BLEU分数作为评估指标,因为这适用于评估短文档。我们使用编码器-解码器(encoder-decoder)流水线来解决这个问题。输入和推断的最大长度分别设置为256和128。我们使用Adam优化器来更新模型的参数。学习率和批大小(batch size)分别为5e-5和32。我们调整超参数并对开发集执行早期停止。
结果。表13显示了不同模型在代码摘要中获得的结果。Seq2Seq是一种基于RNN的序列到序列模型。Transformer和RoBERTa使用与CodeBERT相同的设置,但编码器分别是随机初始化的和由RoBERTa初始化的。所有模型都使用字节对编码(BPE)词汇表。在这个实验中,CodeBERT在BLEU分数上比RoBERTa提高了1.3%,并在六种编程语言上实现了最先进的性能。
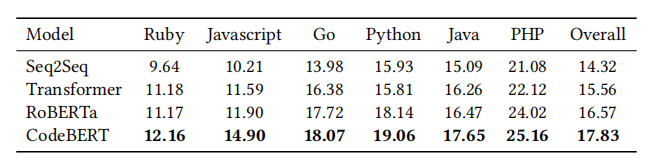
表13:代码摘要任务的结果
5.10 文档翻译
设置。我们使用Microsoft Docs数据集进行文本到文本的翻译任务,该数据集的重点是英语(EN)和其他语言(包括拉脱维亚语(LA)、丹麦语(DA)、挪威语(NO)和汉语(ZH))之间的低资源多语言翻译。继Johnson等人之后,我们训练了一个单独的多语言模型作为基线。为了区分不同的翻译对,我们在源句子的开头添加一个语言token(例如,<2en>,<2zh>),以指示模型应该翻译的目标语言。我们用XLM-R初始化多语言翻译模型的编码器。通过BLEU分数来评估模型,文档翻译的总体分数是八个翻译方向上的平均BLEU分数。
结果。表14显示了模型在八个翻译方向上获得的结果。Transformer Baseline是多语言翻译模型。pretrained Transformer使用XLM-R初始化Transformer Baseline的编码器。就八个翻译方向的总体性能而言,Transformer Baseline和pretrained Transformer分别获得52.67和66.16的BLEU分数。实验结果表明,与强大的基线模型相比,预训练在BLEU得分上提高了13.49。图8显示了训练模型、对模型进行推理所需的时间,其中也包含了其他任务的相关信息。
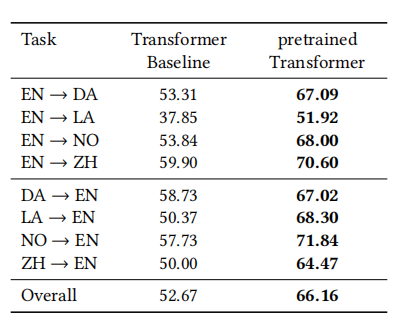
表14:文档翻译任务的结果
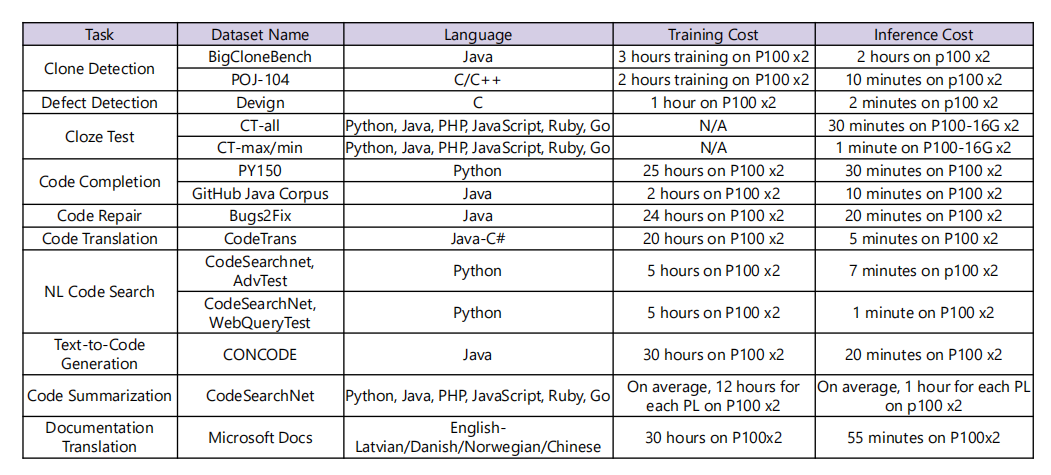
图8:每个任务的训练和推理时间成本,在两个P100 GPU上进行评估
6 相关工作
基准数据集在应用人工智能研究的发展中发挥着核心作用。例如,LibriSpeech和SQuAD数据集分别推动了用于自动语音识别和文本阅读理解的数据驱动模型的开发。随着对在广泛应用中测试模型泛化能力的需求不断增长,研究人员已经创建或组装了涵盖许多任务的数据集。这些数据集的代表性样本包括用于计算机视觉的ImageNet、用于自然语言理解的GLUE、用于跨语言自然语言处理的XTREME和XGLUE。据我们所知,CodeXGLUE是第一个可应用于各种代码智能问题的多样化基准数据集。
许多与软件工程的机器学习相关的任务都有足够的数据来支持数据驱动方法的开发,但CodeXGLUE没有涵盖这些任务。我们计划在未来扩展到这些任务。例如,语法挖掘任务是提取代码语法,这些语法是在软件项目中重复出现的语法片段,服务于单一的语义目的。错误定位是指当程序测试失败时指出错误位置。测试用例生成任务是自动生成单元测试用例。程序综合拓展了文本到代码的生成任务,旨在根据规范生成程序,如伪代码、自然语言描述和输入/输出示例。
7 结论
通过CodeXGLUE,我们致力于帮助 可应用于各种程序理解和生成问题的模型 的开发,以提高软件开发人员的生产力。我们鼓励研究人员参与公开挑战,以在代码智能方面取得进展。接下来,我们计划将CodeXGLUE扩展到更多的编程语言和下游任务,同时通过探索新的模型结构、引入新的预训练任务、使用不同类型的数据等,继续开发先进的预训练模型。

















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









