







前言
为了实现这个平台,我们需要搭建一个Hadoop1集群。同时,下面是集群要求
1、集群至少要有三个节点;
2、由于条件有限,所以要求集群至少可以存储100G的数据;
3、将HDFS副本数设置为3;
4、NameNode要高可用,即运行两个NameNode进程,同一时刻只有一个对外提供服务的NameNode,如果活跃的NameNode进程所在机器宕机了,整个集群还是可以正常运行的;
5、可以正常提交MapReduce运行;
6、Hbase要集群部署,可正常建表、插入数据和查询数据等;
7、部署一个Mysql数据库,要求可以远程访问。
1.搭建三节点Hadoop集群
1.1集群规划 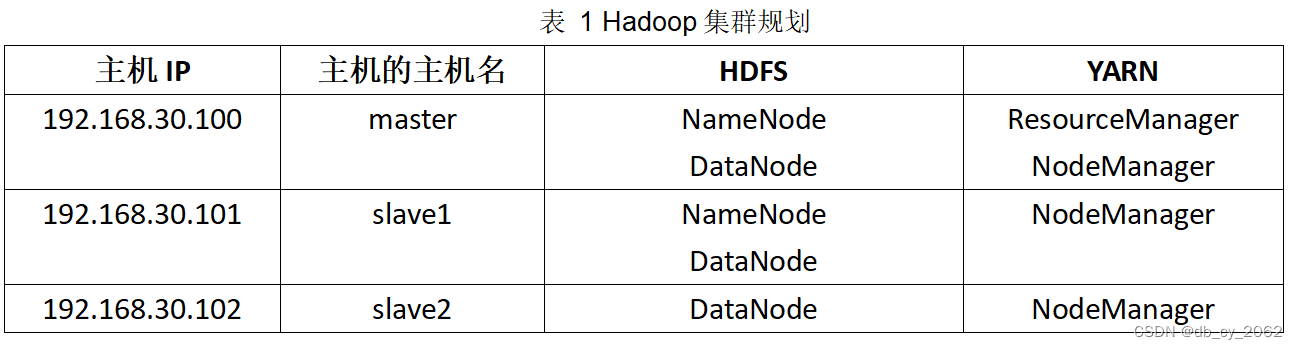
1.2复制虚拟机
准备一台伪分布式虚拟机,具体可以参考我的Hadoop专栏的伪分布式Hadoop文章,或者是在网上寻找教程配置。
然后就是克隆虚拟机:如果使用的虚拟机不支持克隆,可以选择直接复制整个虚拟机文件夹,复制3份,如果支持克隆。记得选择完全克隆,不然等于克隆了个蛋壳过来。
把三台虚拟机都启动,且三台虚拟机命名为master、slave1、slave2
1.2配置完全分布式集群
修改master、slave1、slave2的虚拟机IP,只需要把三个节点的IP,分别修改为100、101和102。在修改完后记得 重新启动网卡,并且使用ping www.baidu.com 进行验证,保证三台机器能够正常连接外网。
# 打开网卡
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# 重新启动网卡
systemctl restart network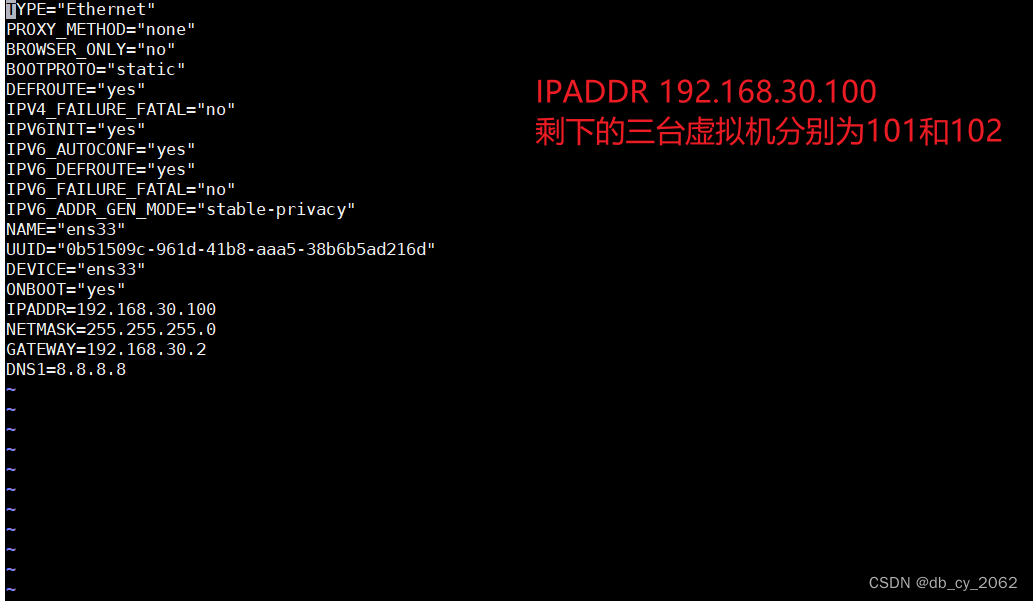
在第一台机器执行 hostnamectl set-hostname master 修改主机名为master。在剩下的两台机器一样,一台是slave1另一台是slave2。修改完成后使用exit或者logout退出登录,重新登录查看,确保三台机器名字分别为master、slave1、slave2.
修改master、slave1和slave2的主机名与IP的映射
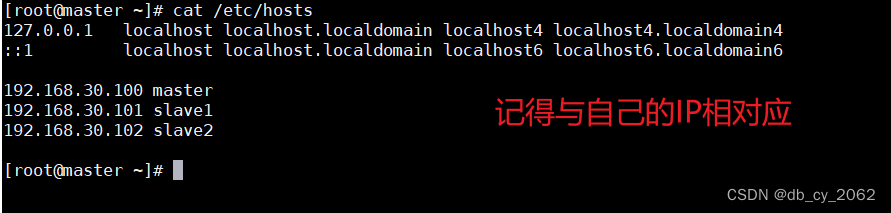
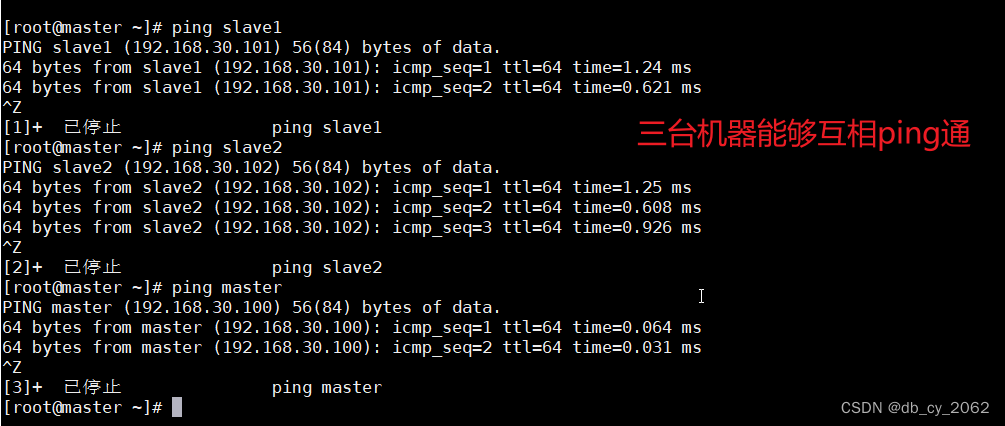
最重要的步骤来了: 把配置好的文件hosts分发给slave1和slave2
scp /etc/hosts root@slave1:/etc
scp /etc/hosts root@slave1:/etc
接下来是设置免密登录和关闭防火墙。这个想想大家在伪分布式的时候已经配置好,没有的话记得回去配置好哦。
删除三台虚拟机的hdfs数据,我的路径是/usr/local/hadoop-2.7.1/data,如果不知道的可以查看Hadoop的core-site.xml文件的hadoop.tmp.dir配置项查看自己的存储目录。
进入Hadoop的按照目录。我的是 /usr/local/hadoop-2.7.1/etc/hadoop
修改core-site.xml
<!-- hdfs分布式文件系统名字/地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!--存放namenode、datanode数据的根路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/newdisk/data</value>
</property>修改 hdfs-site.xml
<!-- 数据块副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- secondary namenode 按照规划部署到slave1上 -->
<property>
<name>dfs.secondary.http.address</name>
<value>slave1:50090</value>
</property>
修改 yarn-site.xml 和 slave
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
把配置好的文件分发给剩下的两台虚拟机:
scp * root@slave1:`pwd`
scp * root@slave2:`pwd`
时间同步,在三台虚拟机运行:ntpdate -u ntp1.aliyun.com
NameNode格式化,这个命令只需要在master运行,并且只运行一次!!!
hdfs namenode -format
启动Hadoop集群:
在master上执行start-all.sh命令启动hadoop集群
使用jps查看进程。
master进程应该是:
DataNode
nameNode
Jps
ResourceManager
NodeManager
slave1进程应该是:
NodeManager
DataNode
Jps
SecondaryNameNode
slave2进程应该是:
NodeManager
Datanode
Jps
在进程前面的数字是端口号,另外如果少了进程记得去检查修改,记得修改后重新启动集群就行了,不需要格式化!!!
浏览器访问master的50070端口http://192.168.30.100:50070
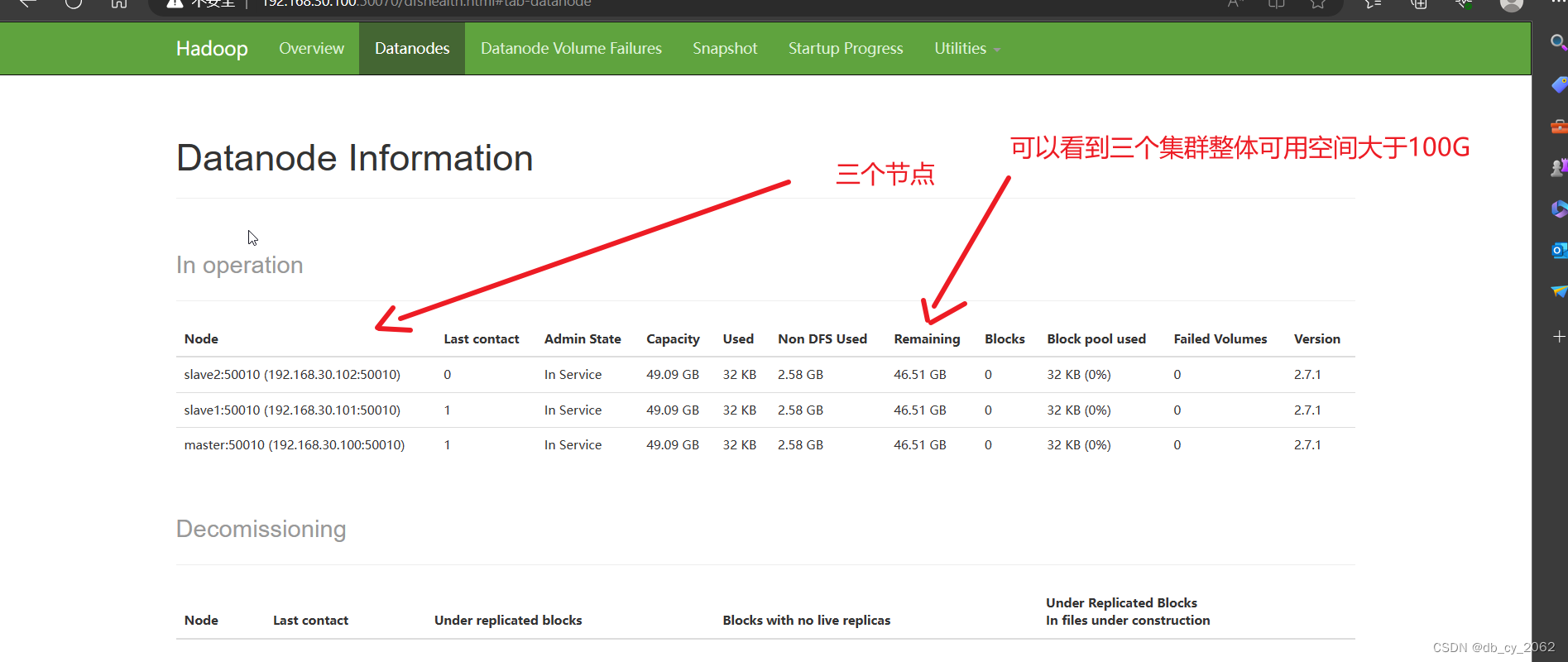
到这里我们完成了完全分布式搭建,同时也完成了要求1、2、3。那么问题来了,请问要求2和要求3在哪个配置文件实现的呢?
让我们回到 修改core-site.xml修改 hdfs-site.xml。
hdfs-site.xml 那个小3就是配置HDFS副本
至于那个100g,就需要三台虚拟机准备3块硬盘
把硬盘分区一个主分区50g,然后挂载到目录中,接下来需要在挂载目录下创建data目录,把data目录放到core-site.xml的配置项中。这样子三台合起来就有100g存储数据了。
下一篇文章我讲具体的进HA的搭建。在专栏里可以找到哦。
















 1355
1355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











