







Hadoop
1.Hadoop 概述
1.1 Hadoop 是什么
(1)Hadoop是一个由Apache基金会所开发的分布式系统基础架构
(2)主要解决海量数据的存储和海量数据的分析计算问题
(3)广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈
1.2 Hadoop 优势
(1)高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失。
(2)高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
(3)高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
(4)高容错性:能够自动将失败的任务重新分配。
1.3 Hadoop 组成(面试重点)
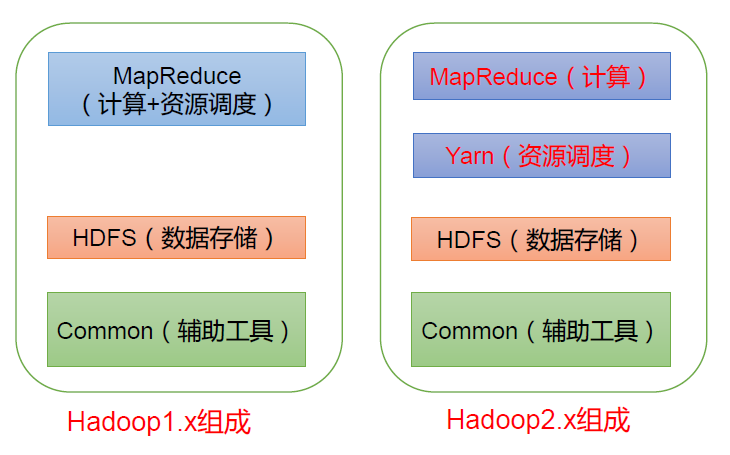
在Hadoop1.x 时代,Hadoop中的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。 在Hadoop2.x时代,增加了Yarn。Yarn只负责资源的调度,MapReduce 只负责运算。 Hadoop3.x在组成上没有变化。
1.3.1 HDFS 架构概述
Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
(1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
(2)DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
(3)Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
1.3.2 YARN 架构概述
Yet Another Resource Negotiator 简称YARN ,另一种资源协调者,是Hadoop 的资源管理器。
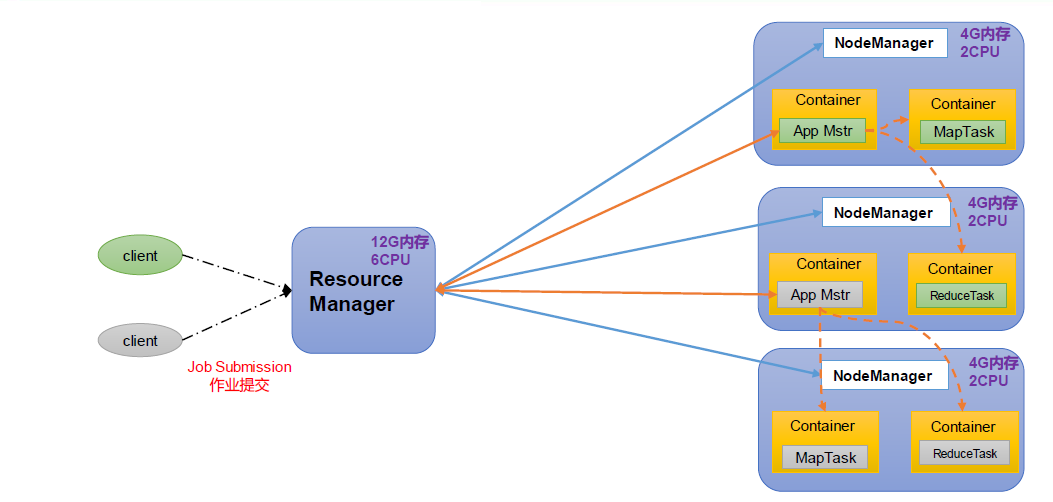
ResourceManager(RM):整个集群资源(内存、CPU等)的管理者
NodeManager(NM):单个节点服务器资源的管理者。
ApplicationMaster(AM):单个任务运行的管理者。
Container:容器,相当于一台独立的服务器,里面封装了任务运行所需要的资源,如内存、CPU、磁盘、网络等。
说明:
(1)客户端可以有多个
(2)集群上可以运行多个ApplicationMaster
(3)每个NodeManager上可以有多个Container
1.3.3 MapReduce 架构概述
MapReduce 将计算过程分为两个阶段:Map 和Reduce 1)Map 阶段并行处理输入数据 2)Reduce 阶段对Map 结果进行汇总
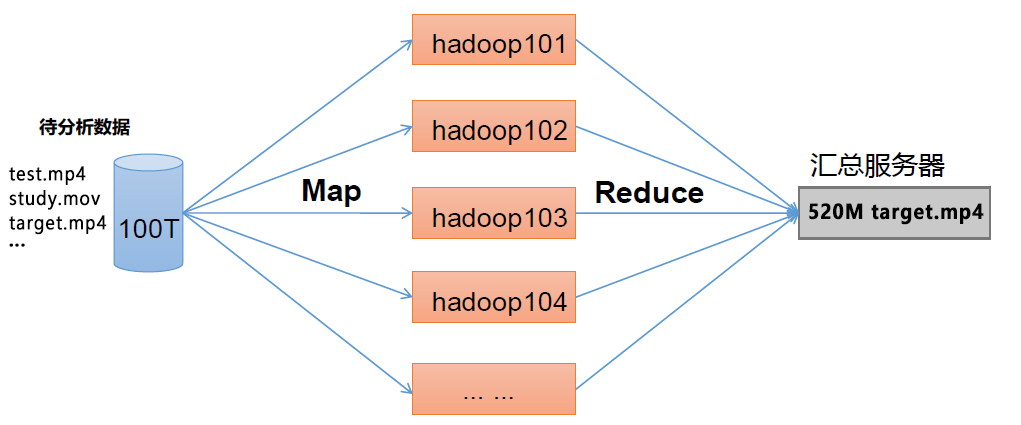
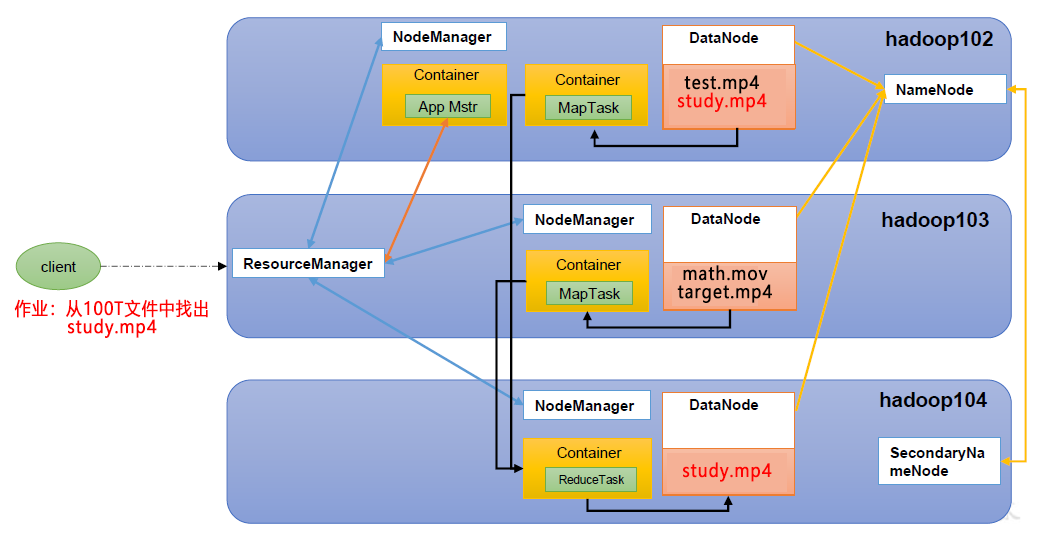
1.3.4 HDFS、YARN、MapReduce 三者关系
如图所示:
1.3.5 大数据技术生态体系
如图所示: 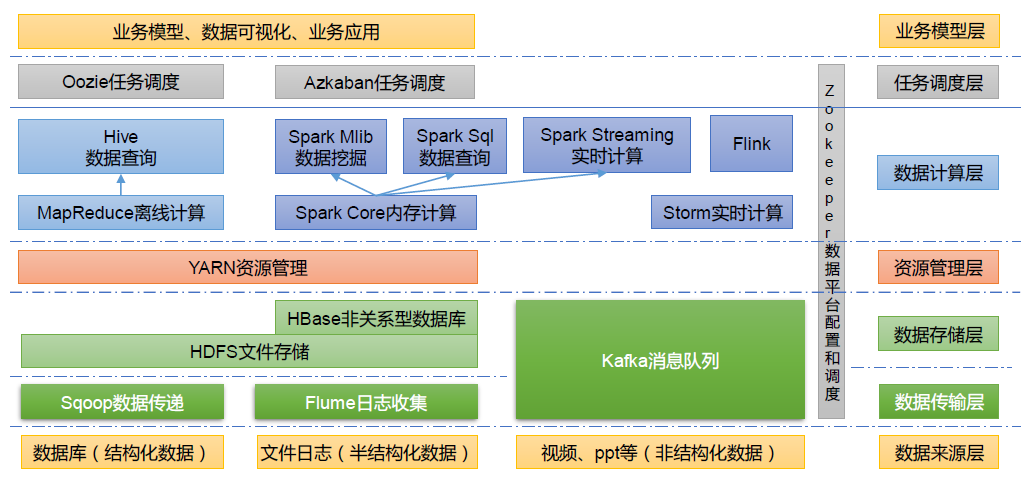
图中涉及的技术名词解释如下:
(1)Sqoop:Sqoop 是一款开源的工具,主要用于在Hadoop、Hive 与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop 的HDFS 中,也可以将HDFS 的数据导进到关系型数据库中。
(2)Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume 支持在日志系统中定制各类数据发送方,用于收集数据。 (3)Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统。
(4)Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于Hadoop 上存储的大数据进行计算。
(5)Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
(6)Oozie:Oozie 是一个管理Hadoop 作业(job)的工作流程调度管理系统。
(7)Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
(8)Hive:Hive 是基于Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL 查询功能,可以将SQL 语句转换为MapReduce 任务进行运行。其优点是学习成本低,可以通过类SQL 语句快速实现简单的MapReduce 统计,不必开发专门的MapReduce 应用,十分适合数据仓库的统计分析。
(9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
1.3.6 推荐系统框架图
推荐系统项目框架
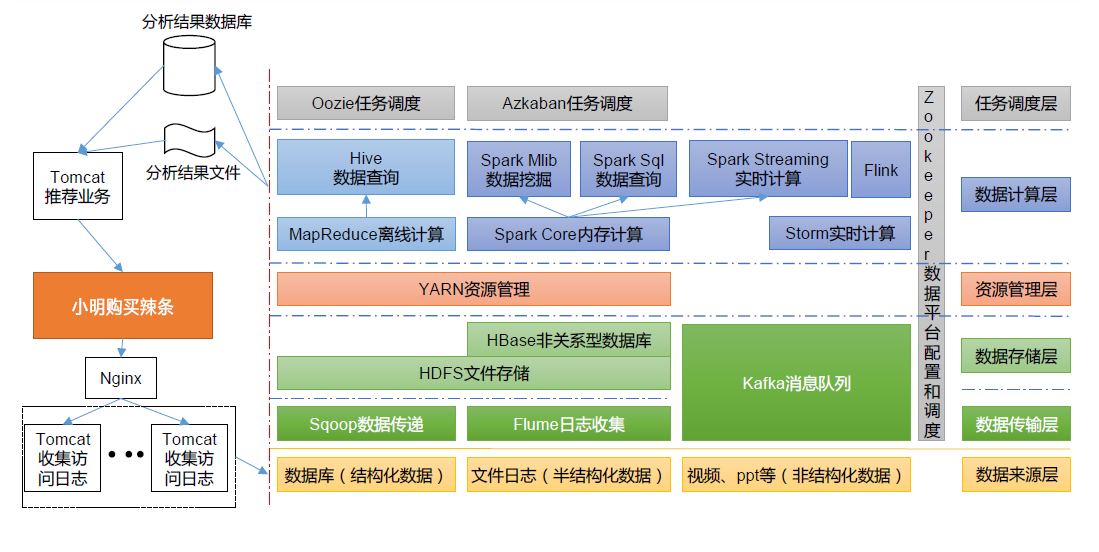
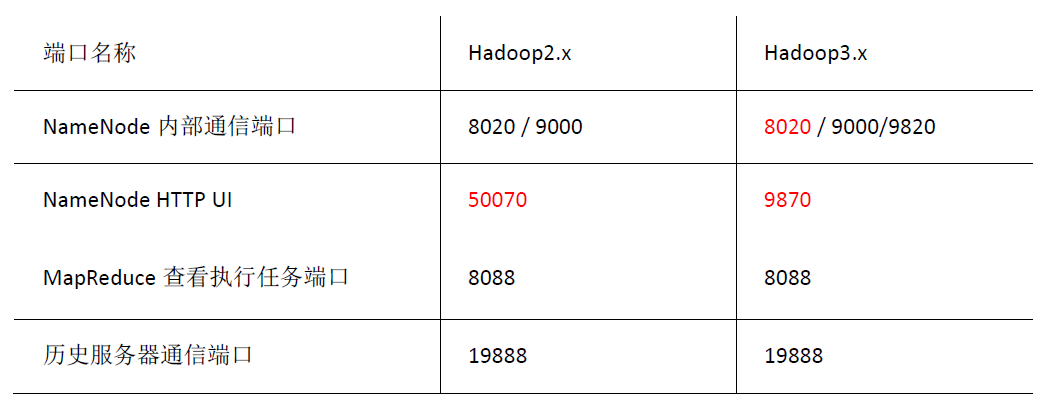
1.3.7 常用端口号说明
2. Hadoop 完全分部署运行环境搭建
环境说明:
| 容器 | 容器ip |
|---|---|
| master | 192.168.1.10 |
| slave1 | 192.168.1.20 |
| slave2 | 192.168.1.30 |
2.1 配置主机名
hostnamectl set-hostname master && bash
hostnamectl set-hostname slave1 && bash
hostnamectl set-hostname slave2 && bash
2.2 修改hosts,添加映射,关闭防火墙
所有节点执行
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
192.168.1.10 master
192.168.1.20 slave1
192.168.1.30 slave2
systemctl stop firewalld
systemctl disable firewalld
2.3 设置三台主机的免密登录
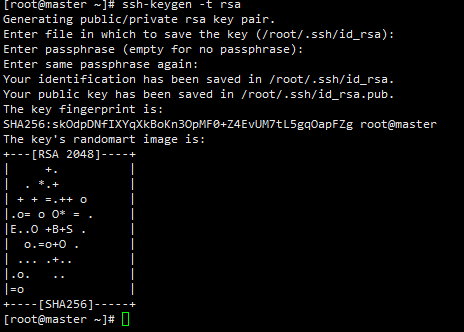
2.3.1 生成免密公钥
[root@master ~]# ssh-keygen -t rsa #然后一直回车
或者
[root@master ~]# ssh-keygen -f ~/.ssh/id_rsa -P '' #免回车
2.3.2 复制公钥到服务器
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
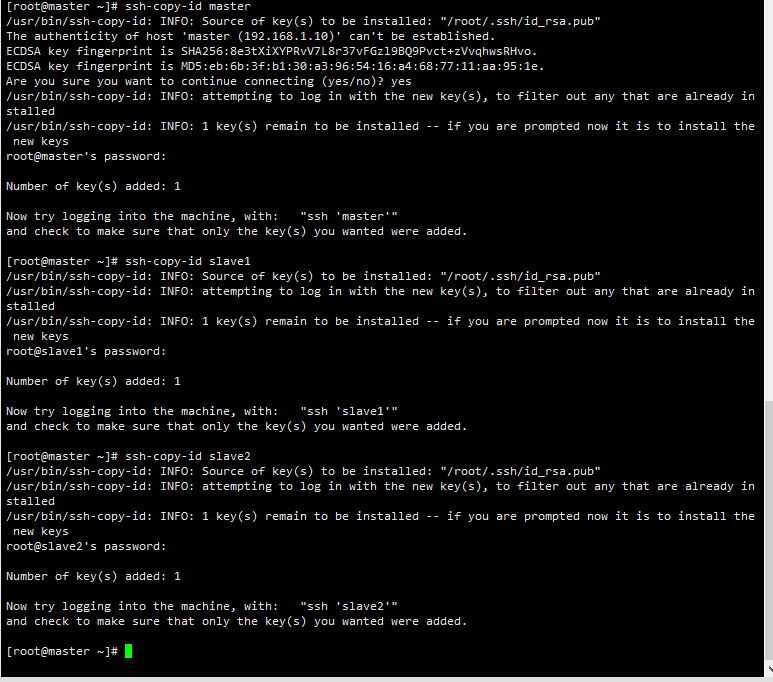
(另外两个节点也是如此操作,这里就不演示了)
2.4 JDK配置
解压文件到相应的位置:
[root@master ~]# tar -zxvf /opt/software/jdk-8u162-linux-x64.tar.gz -C /opt/module/
[root@master ~]# cd /opt/module/ #进入解压目录,可以给解压后的文件改个名字,方便记忆
[root@master module]# mv jdk1.8.0_162/ jdk
设置jdk环境变量:
[root@master module]# vi /etc/profile
在末尾添加如下配置:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
刷新环境变量:
[root@master module]# source /etc/profile
配置完后即可查看jdk版本号:
[root@master module]# java -version

分发JDK和环境变量到两个副节点:
[root@master module]# scp /etc/profile root@slave1:/etc/profile
[root@master module]# scp /etc/profile root@slave2:/etc/profile
[root@master module]# scp -rq jdk/ root@slave1:/opt/module/
[root@master module]# scp -rq jdk/ root@slave2:/opt/module/

分发到两个副节点后,刷新环境变量,查看JAVA版本:
slave1节点:

slave2节点:

基础环境搭建完成!!
添加jpsall脚本(可选)
vi $JAVA_HOME/bin/jpsall
chmod +x $JAVA_HOME/bin/jpsall
脚本内容如下:
#!/bin/bash
for hostname in master slave1 slave2
do
echo ===========$hostname==========
ssh $hostname ". /etc/profile; jps"
done
2.5 Hadoop环境搭建
前提:已完成3个节点的免密登录,jdk配置
2.5.1 解压包到相应位置:
[root@master module]# tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
[root@master module]# mv hadoop-3.1.3/ hadoop #改一下名字,方便记忆
2.5.2 添加hadoop环境变量
[root@master module]# vi /etc/profile
在末尾添加以下内容:
#HADOOP
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CLASSPATH=`$HADOOP_HOME/bin/hadoop classpath`
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#备注:3.0后的版本需要指定服务用户
:wq 保存退出后,刷新环境变量:
[root@master module]# source /etc/profile
配置好后,即可直接查看hadoop 版本号
[root@master module]# hadoop version

2.6 修改6个主配置文件
- 1️⃣ core.site.xml
- 2️⃣ hdfs-site.xml
- 3️⃣ mapred-site.xml
- 4️⃣yarn-site.xml
- 5️⃣ hadoop-env.sh
- 6️⃣ workers
配置参考官方文档
目录:
\hadoop-3.1.3\share\doc\hadoop
或直接查看官方配置文件:
find ./ -name "core-de*" -o -name "hdfs-de*" -o -name "mapred-de*" -o -name "yarn-de*"

(记住主要参数名即可)
2.6.1先进入配置目录
[root@master module]# cd hadoop/etc/hadoop/
[root@master hadoop]# ll
可以看到如下文件:
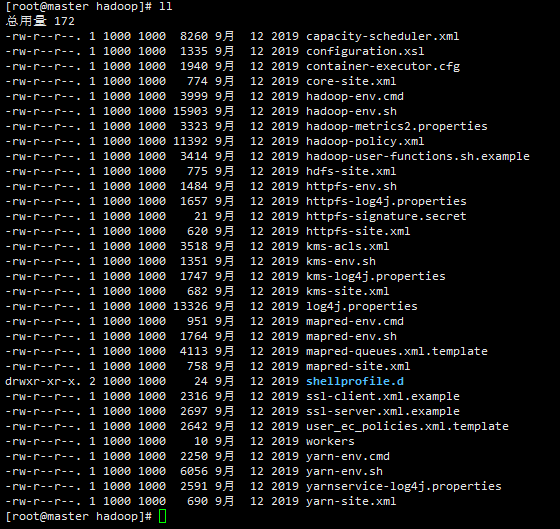
我们只用修改其中的6条
2.6.2 hadoop-env.sh配置:
[root@master hadoop]# vi hadoop-env.sh #告诉hadoop jdk在哪里

2.6.3 workers配置
(根据自己的集群来进行配置):
[root@master hadoop]# vi workers
master
slave1
slave2
2.6.4 core.site.xml配置:

[root@master hadoop]# vi core-site.xml
<configuration>
<!-- hdfs的地址名称:schame,ip,port-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- hdfs的基础路径,被其他属性所依赖的一个基础路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoopdir/tmp</value>
</property>
</configuration>
2.6.5 hdfs.site.xml:
[root@master hadoop]# vi hdfs-site.xml
<configuration 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7648
7648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









