







多重共线性
在回归分析中,多重共线性(Multicollinearity)是自变量之间存在高度线性相关性的现象。它可能导致模型参数估计不稳定、方差增大,甚至使模型失去解释能力。本文将系统介绍多重共线性的影响、检测方法及解决方案,并附带相关技术原理的详细说明。
一、多重共线性的影响
-
参数估计不稳定
特征间的高度相关性会导致模型参数对数据微小变化异常敏感,参数值可能大幅波动。 -
参数方差增大
多重共线性会降低回归系数的统计显著性,使得参数的置信区间变宽,增加模型不确定性。 -
模型解释困难
高度相关的特征难以区分对因变量的独立贡献,导致模型可解释性下降。 -
过拟合风险
模型可能在训练数据上表现良好,但泛化能力差,测试数据表现显著下降。
二、多重共线性的检测方法
2.1 方差膨胀因子(VIF)
VIF 是衡量多重共线性的核心指标。对于第 i 个特征,其 VIF 值为:
VIF
i
=
1
1
−
R
i
2
\text{VIF}_i = \frac{1}{1 - R_i^2}
VIFi=1−Ri21
其中
R
i
2
R_i^2
Ri2 是该特征对其他特征回归的决定系数。
- VIF < 5:低度共线性
- 5 ≤ VIF < 10:中度共线性
- VIF ≥ 10:高度共线性
也可以用p个自变量所对应的方差扩大因子的平均数来度量多重共线性。
V
I
F
‾
=
1
p
∑
i
=
1
p
V
I
F
i
\overline{VIF} = \frac{1}{p} \sum_{i=1}^{p} VIF_i
VIF=p1i=1∑pVIFi
2.2 相关系数矩阵
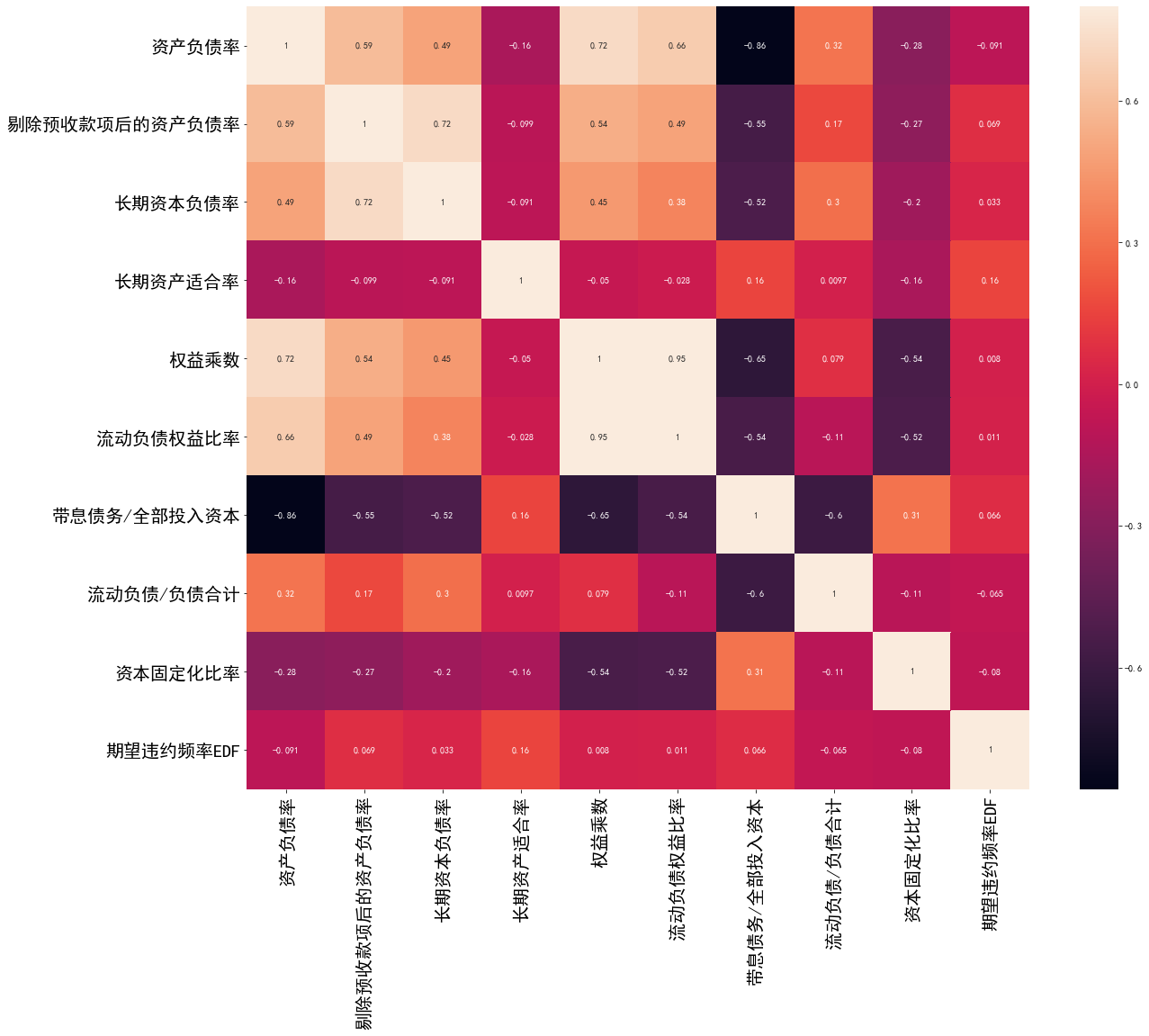
通过计算特征间的相关系数矩阵并绘制热力图,可直观识别高度相关(接近 ±1)的特征:
import seaborn as sns
import matplotlib.pyplot as plt
corr = data.corr()
plt.figure(figsize=(12, 10))
sns.heatmap(corr, annot=True, cmap='coolwarm', fmt='.2f')
plt.show()
2.3 特征根判断法
协方差矩阵与特征值分解
计算协方差矩阵
X
T
X
X^T X
XTX并求其特征值。若存在接近零的特征值,矩阵
X
T
X
X^T X
XTX至少有一个特征根近似为0,则表明存在多重共线性。
步骤:
- 计算协方差矩阵
协方差矩阵描述了各个自变量之间的关系:
C o v ( X ) = 1 n − 1 X T X Cov(X)= \frac{1}{n-1}X^T X Cov(X)=n−11XTX - 计算特征值
对协方差矩阵 Cov(X) 进行特征值分解,求得其特征值。特征值表示矩阵在不同方向上的伸缩能力。特征值的大小直接反映了矩阵在不同方向上的方差。如果某个特征值接近零,则说明矩阵在该方向上的方差非常小,意味着自变量之间存在线性相关性。
我们通过解特征方程:
d e t ( C o v ( X ) − λ I ) = 0 det(Cov(X)-λI)=0 det(Cov(X)−λI)=0
得到特征值 λ 1 , λ 2 , … , λ p λ_1,λ_2,…,λ_p λ1,λ2,…,λp,其中 p 是自变量的个数。 - 解读特征值
如果所有特征值都较大,说明自变量之间的相关性较低,模型中不存在严重的多重共线性。
如果某些特征值非常小,特别是接近零,则表明自变量之间存在高度线性依赖,可能存在多重共线性问题。
这时,引入条件数来判断特征值是否近似于零。
条件数
矩阵的条件数(Condition Number)也是用来判断多重共线性的一种方法,条件数是特征值最大值与最小值的比值。
K ( X ) = λ m a x λ m i n K(X)=\frac{λ_{max}}{λ_{min}} K(X)=λminλmax
条件数越大,说明矩阵接近病态,可能存在多重共线性。通常认为,K<100 时,矩阵X的多重共线性的程度很弱;100≤K≤1000 时,存在较强多重共线性;如果K>1000,则认为存在严重的多重共线性。
三、解决多重共线性的方法
3.1 删除冗余特征
通过 VIF 或相关系数矩阵识别并删除高度相关的冗余特征。
3.2 主成分分析(PCA)
将原始特征转换为线性无关的主成分,消除共线性。
3.3 正则化方法
| 方法 | 正则化项 | 系数收缩特性 | 适用场景 |
|---|---|---|---|
| 岭回归 | L2(平方和) | 系数压缩至接近零 | 保留所有变量,缓解共线性 |
| Lasso | L1(绝对值和) | 部分系数压缩至零 | 高维数据特征选择 |
3.4 其他方法
- 增加数据量:减少共线性影响(可行性受限)。
- 手动组合特征:将相关特征合并为新特征(如加权平均)。
- 逐步回归:通过前向选择、后向剔除或双向逐步选择优化特征子集。
- 偏最小二乘法(PLS):同时考虑 X 和 Y 的协方差,提取潜在变量。
四、主成分分析详解
4.1 PCA的基本思想
PCA的核心思想是将原始数据通过正交变换,投影到一个新的坐标系中,使得新坐标系的每个轴(主成分)都代表数据中的最大方差方向。具体来说,PCA通过以下几个步骤实现降维:
计算协方差矩阵:首先,计算数据的协方差矩阵,它反映了各个特征之间的线性关系。如果特征之间高度相关,那么协方差值就较大。
计算特征值和特征向量:对协方差矩阵进行特征值分解,得到特征值和特征向量。特征值表示主成分的方差大小,特征向量表示主成分的方向。
选择主成分:选择特征值较大的特征向量作为主成分,因为这些特征向量对应的方向承载了数据中最大的方差信息。
数据投影:将原始数据投影到选定的主成分上,得到降维后的数据。
4.2 PCA的数学原理
假设有一个数据集 X(大小为 n×p,其中 n 是样本数,p 是特征数),PCA通过以下步骤进行计算:
(1) 标准化数据
为了消除不同特征之间的量纲差异,通常首先对数据进行标准化,使得每个特征的均值为0,方差为1。标准化后的数据 Z 计算公式为:
Z
=
X
−
μ
σ
Z = \frac{X - \mu}{\sigma}
Z=σX−μ
其中,μ 是特征的均值,σ 是特征的标准差。
(2) 计算协方差矩阵
数据标准化后,计算数据的协方差矩阵 C:
C
=
1
(
n
−
1
)
Z
T
Z
C= \frac{1}{(n-1)}Z^T Z
C=(n−1)1ZTZ
Z
T
Z
Z^T Z
ZTZ 计算的每个元素就是样本间特征的乘积,用于衡量不同特征之间的关系。
Z
T
Z
Z^TZ
ZTZ的第 (i, j) 元素表示特征 i 和特征 j 之间的内积。
协方差矩阵描述了不同特征之间的线性关系。
(3) 计算特征值和特征向量
对协方差矩阵 C 进行特征值分解:
C
v
=
λ
v
C_v=λv
Cv=λv
其中,
- λ 是特征值
- v 是特征向量
特征值代表了各个主成分的方差大小,特征向量代表了主成分的方向。
(4) 选择主成分
主成分的选择有很多种方法,以下简单介绍两种。
- 直接选择前几个主成分,投影数据到主成分空间
将特征值按降序排列,并选择前 k 个最大的特征值所对应的特征向量。前 k 个特征向量所组成的矩阵
V
k
V_k
Vk 就是新的投影矩阵。将原始数据投影到选定的主成分方向,得到降维后的数据
X
k
X_k
Xk:
X
k
=
Z
V
k
X_k=ZV_k
Xk=ZVk
其中,
X
k
X_k
Xk是降维后的数据,
V
k
V_k
Vk 是前 k 个特征向量所组成的投影矩阵。
- 累计方差解释比例 (Cumulative Explained Variance)
每个主成分(特征向量)都有一个对应的特征值,这个特征值表示主成分方向上数据的方差大小。主成分的方差越大,表示该方向上的数据分布越广泛,携带的信息也越多。PCA的目标是选择尽可能少的主成分,同时保留数据中的大部分变异性(方差)。
通常,累计方差解释比例被用来衡量选择的主成分总共解释了多少原始数据的方差。**每个主成分的方差占比为其特征值与所有特征值之和的比例。**通过选择一定数量的主成分,使得累计方差解释比例达到某个阈值(例如95%),可以在保留数据主要特征的同时减少特征空间的维度。
1.计算每个主成分的方差占比
每个主成分的方差占比(也叫做贡献率)可以通过计算其特征值与所有特征值之和的比值来得到。
假设特征值为
λ
1
,
λ
2
,
…
,
λ
p
λ_1,λ_2,…,λ_p
λ1,λ2,…,λp,那么每个主成分的方差占比为:
方差占比
=
λ
i
∑
i
=
1
p
λ
i
方差占比= \frac{λ_i}{∑_{i=1}^pλ_i}
方差占比=∑i=1pλiλi
2.计算累计方差解释比例
累计方差解释比例是前 k 个主成分所解释的方差总和。选择主成分时,可以计算各个主成分的方差占比的累计和,直到累计方差达到预设的阈值(如95%)为止。
累计方差占比
=
∑
i
=
1
k
λ
i
∑
i
=
1
p
λ
i
累计方差占比=∑_{i=1}^k \frac{λ_i}{∑_{i=1}^pλ_i}
累计方差占比=i=1∑k∑i=1pλiλi
3.选择主成分数
当累计方差占比达到设定的阈值(如95%)时,选择前 k 个主成分。这样,数据中95%的方差信息被保留,剩下的5%方差则丢失。
五、逐步回归(Stepwise Regression)
逐步回归是一种在回归模型中选择解释变量(自变量)的方法。其基本思想是从多个候选变量中逐步选择与因变量(目标变量)最相关的变量,通过不断地加入或剔除变量来优化回归模型。
逐步回归的主要方法有三种:前向选择(Forward Selection)、后向剔除(Backward Elimination)和双向逐步选择(Bidirectional Stepwise)。
5.1 前向选择(Forward Selection)
初始模型:开始时模型没有任何自变量。
逐步添加变量:从剩余的自变量中选择与因变量关系最强的变量(通常通过统计检验,如p值最小的变量)。
重复过程:每次添加最显著的变量,并重新计算模型,直到没有其他自变量能显著改善模型为止。
5.2 后向剔除(Backward Elimination)
初始模型:开始时将所有候选变量都包含在内。
逐步剔除变量:检查每个变量的显著性(通常通过p值),从中剔除不显著的变量(如p值大于某个阈值)。
重复过程:每次删除最不显著的变量,直到所有剩下的变量都显著为止。
5.3 双向逐步选择(Bidirectional Stepwise)
结合了前向选择和后向剔除的策略。
逐步添加和剔除变量:每次选择或剔除最显著的变量,模型不仅会逐步加入变量,也会考虑剔除掉那些已经进入模型但不再显著的变量。
这样可以同时进行添加和剔除变量,直到没有更多的改进为止。
六、偏最小二乘法(Partial Least Squares,PLS)
偏最小二乘法(PLS)是一种用于多变量回归和降维的统计方法,它特别适用于自变量(特征)之间存在强烈共线性或自变量数量多于样本数量的情形。PLS通过在建模过程中同时考虑自变量和因变量的关系,寻求一组潜在的因子(称为成分或主成分),这些成分能够最好地解释因变量的变化。
6.1 PLS的基本概念
PLS的基本思想:通过将自变量(X矩阵)和因变量(Y矩阵)之间的关系映射到一个新的潜在变量空间中,找到一组新的成分,这些成分不仅能最大化自变量之间的方差,还能够最大化这些成分与因变量之间的相关性。PLS能够找到一个新的潜在变量空间,使得自变量和因变量的关系得到最优化。
PLS的目标是同时最大化自变量和因变量之间的协方差,因此它通过迭代的方式来优化潜变量,使得它们在自变量和因变量空间中都能获得最大的共变信息。
6.2 PLS降维的步骤
PLS降维的过程通常包括以下几个步骤:
标准化数据:通常在进行PLS分析之前,我们会先对数据进行标准化处理,即将每个特征变量减去其均值,然后除以标准差。
构建潜在变量(T和U):PLS通过一种称为“交替最小二乘法”(ALS, Alternating Least Squares)的迭代方法来提取潜在变量。每一次迭代都会找出一对潜在变量T和U,使得它们尽可能地解释输入(X)和输出(Y)数据之间的关系。
计算加载矩阵:加载矩阵(P和Q)分别描述了每个潜在变量在自变量空间和因变量空间的贡献。
选择合适的潜在变量数量:在PLS中,我们需要选择合适的潜变量个数(通常通过交叉验证来决定),过多的潜变量可能导致过拟合,过少的潜变量则可能无法捕捉数据的主要结构。
回归和预测:通过获得的潜变量,我们可以构建回归模型,进行预测。
6.3 PLS与PCA的区别
虽然PLS和PCA(Principal Component Analysis,主成分分析)都属于降维技术,但它们有着显著的不同之处:
PCA:通过最大化方差来寻找数据中最重要的方向。PCA仅仅考虑自变量X的数据结构,不关心因变量Y。
PLS:通过最大化自变量X和因变量Y之间的协方差来寻找新的方向,因此PLS能够更好地反映自变量与因变量之间的关系。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









