






1. 模型导入+推理
- 参考教程: https://docs.voxel51.com/integrations/pytorch_hub.html#adding-hub-models-to-your-local-zoo
-
# pip install ultralytics==8.0.232 安装这个包
import torch
# 方法一和方法二的教程
# model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt') # local model
# model = torch.hub.load('path/to/yolov5', 'custom', path='path/to/best.pt', source='local') # local repo
model = torch.hub.load('/home/helen/code/gitee-yolov5/yolov5-work/yolov5', 'custom',
path='/home/helen/code/gitee-yolov5/yolov5-work/yolov5/weights_val/yantai_boat.pt', source='local') # local repo
// 这个可以实现从torch.hub加载到自己的pt数据集;给定模型仓库,给定Pt即可,但是无法使用fiftyone的仓库,还需要结合一下使用
from PIL import Image
img = Image.open('/media/zhr/T9/zhr/boat-dataset/shipdata/shipdata/images/train/1_1.jpg')
# Inference
results = model([img, img], size=640) # batch of images
results.print()
results.xyxy[0] # im1 predictions (tensor)
results.pandas().xyxy[0] # im1 predictions (pandas)
results.show()
// 方法二: 成功实现 fiftyone导入yolov5的自定义模型 yolov5.pt; 也可以实现自定义模型的导入和输入
// 还需要将预测结果给转为fiftyone的格式
model2 = fout.load_torch_hub_image_model(
repo_or_dir="/home/helen/code/gitee-yolov5/yolov5-work/yolov5",
model='custom', // 后面的参数是以hub_kwargs的形式给输入的。上面的local和path都是以dict形式输入的,就成功了
hub_kwargs=dict(source="local", path="/home/helen/code/gitee-yolov5/yolov5-work/yolov5/weights_val/yantai_boat.pt"),
output_processor=YOLOv5OutputProcessor(),
raw_inputs=True,
)
predictions = model2.predict(img)
# Generate predictions for all images in a collection
dataset.apply_model(model2, label_field="yolov5")
# dataset.count("yolov5.detections") # 26
session = fo.launch_app(dataset)
# https://docs.voxel51.com/integrations/pytorch_hub.html#adding-hub-models-to-your-local-zoo
from PIL import Image
import numpy as np
import fiftyone as fo
import fiftyone.zoo as foz
import fiftyone.utils.torch as fout
class YOLOv5OutputProcessor(fout.OutputProcessor):
"""Transforms ``ultralytics/yolov5`` outputs to FiftyOne format.
reusult来自于模型推理结果:对结果进行后处理
进一步筛选conf,然后转化为Detections FO的格式
"""
def __call__(self, result, frame_size, confidence_thresh=None):
batch = []
for df in result.pandas().xywhn:
if confidence_thresh is not None:
df = df[df["confidence"] >= confidence_thresh]
batch.append(self._to_detections(df))
return batch
def _to_detections(self, df):
return fo.Detections(
detections=[
fo.Detection(
label=row.name,
bounding_box=[
row.xcenter - 0.5 * row.width,
row.ycenter - 0.5 * row.height,
row.width,
row.height,
],
confidence=row.confidence,
)
for row in df.itertuples()
]
)
# 只要small, medium, large面积段的
import fiftyone.zoo as foz
from fiftyone import ViewField as F
ds = foz.load_zoo_dataset("quickstart")
box_width, box_height = F("bounding_box")[2], F("bounding_box")[3]
rel_bbox_area = box_width * box_height
im_width, im_height = F("$metadata.width"), F("$metadata.height")
abs_area = rel_bbox_area * im_width * im_height
ds.filter_labels("predictions", abs_area > 32**2 && abs_area < 96**2)- 导入voc xml格式标签和图像;
- 复制ground_truth标签域--->gt_boat标签阈
- 标签映射:细分类映射为单分类
- 获取model模型
- 使用模型对数据集进行推理,apply_model,并将预测的标签阈称为label_field
- 有gt标签,有predict标签,进行mAP计算。注意,这里的mAP和cocomAP有较大差异,cocomAP要的是conf>=0.01的all boxes,这里的box是推理后的,conf>0.25所以会比cocomAP好很多;这个cocomAP指标,之后也会出一个详细的分析指南。
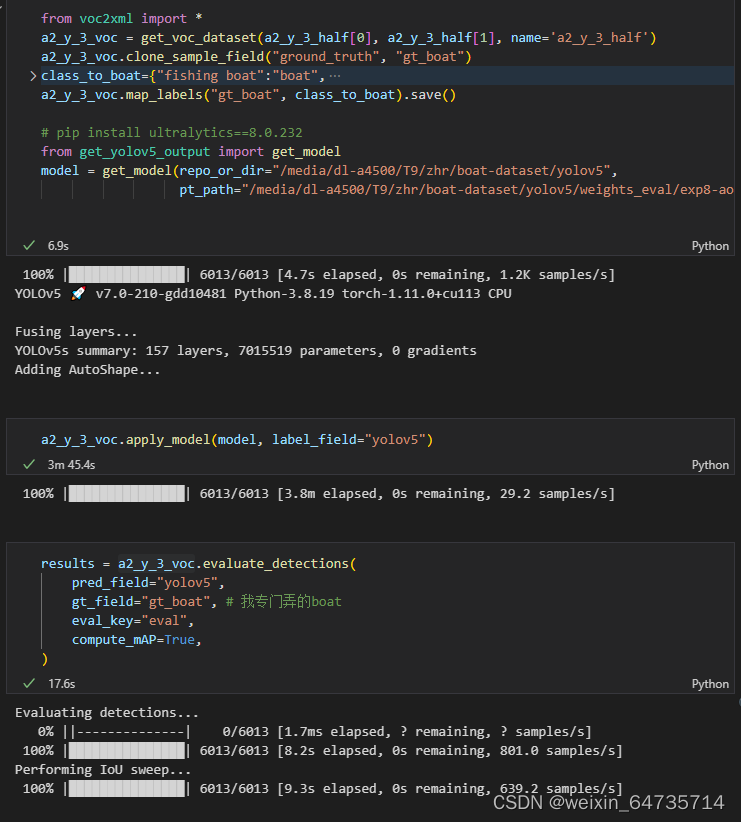
2. evaluate
dataset.apply_model(model, label_field="yolov5")
results = dataset.evaluate_detections(
pred_field="yolov5",
gt_field="ground_truth",
eval_key="eval",
compute_mAP=True,
)
print(results.mAP())
- mAP=0.21左右,很差的;原因分析
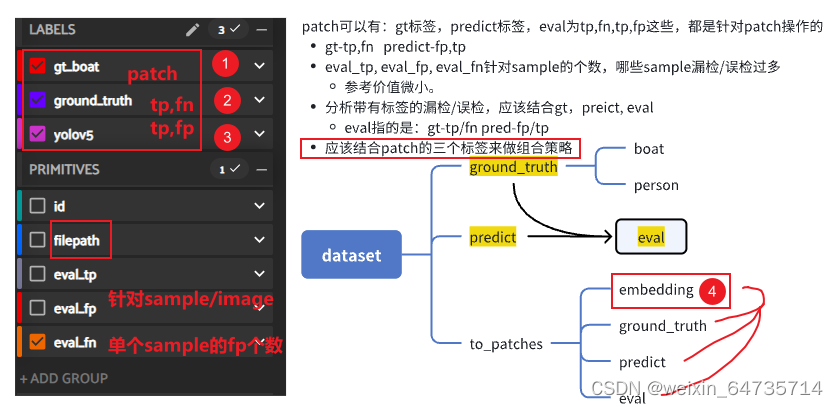
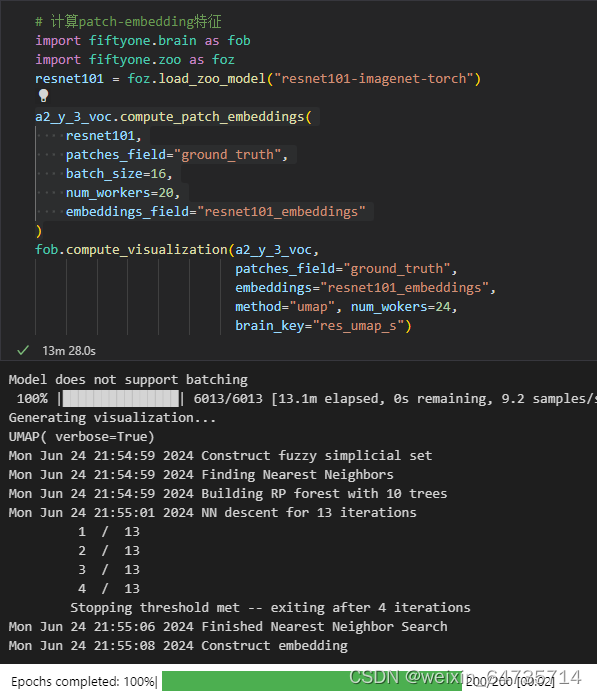
3. 分析eval_fn, fp
- 想看下fn漏检,fp误检,都是什么原因?——比如之前的fp,误检,大部分是桥墩之类的误检,后来聚类分析之后,发现是标签有巨大的bug,框进入的背景太多了。所以优化了帆船的标签;以及筛选了标签,发现帆船的标签和实际的出入很大。所以数据的认识是必要充分的!!!
- 这里有好几个路子,需要分析一下















 259
259

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









