






在跑大模型的lora训练时,我发现最后提交结果的分数在0.7左右,到群里去一交流发现不少群友也是0.7左右。这个时候我发现第一次不修改参数结果模型中存了一个1000步的模型,于是又使用这个Lora模型去跑,发现最后跑出来上到0.8出头。鉴于最后模型的loss值降得非常低,我怀疑这个模型过拟合了,因此打算重新训练。
这个时候,有人指出,是不是训练参数中没有加入author(作者)一栏导致数据集质量不够好?于是我们去看建构训练集部分的代码,发现是这样的:
res = []
for i in range(len(train_df)):
paper_item = train_df.loc[i]
tmp = {
"instruction": "Please judge whether it is a medical field paper according to the given paper title and abstract, output 1 or 0, the following is the paper title and abstract -->",
"input": f"title:{paper_item[1]},abstract:{paper_item[3]}",
"output": str(paper_item[5])
}
res.append(tmp)在这一段之前,我们已经从train.csv文件中,将数据集读取进来了,但是我们注意到这里只使用了第一列和第三列作为输入,将第五列作为输出。于是我们打开CSV文件,发现数据集的构成其实是由第0列(uuid),第1列(title),第二列(author),第三列(abstract),第四列(keywords)组成。于是我们就将author和keywords也加入进去,将代码修改成:
# 创建一个空列表来存储数据样本
res = []
# 遍历训练数据的每一行
for i in range(len(train_df)):
# 获取当前行的数据
paper_item = train_df.loc[i]
# 创建一个字典,包含指令、输入和输出信息
tmp = {
"instruction": "Please judge whether it is a medical field paper according to the given paper title and abstract, output 1 or 0, the following is the paper title and abstract -->",
"input": f"title:{paper_item[1]},author:{paper_item[2]},abstract:{paper_item[3]},Keywords:{paper_item[4]}",
"output": str(paper_item[5])
}
# 将字典添加到结果列表中
res.append(tmp)
# 导入json包,用于保存数据集
import json
# 将制作好的数据集保存到data目录下
with open('./data/paper_label.json', mode='w', encoding='utf-8') as f:
json.dump(res, f, ensure_ascii=False, indent=4)修改完后,我考虑到有可能最终训练结果有可能极为不可控,于是在shell脚本中“--save_steps 1000 \”改为“--save_steps 50 \”。使每50步存储一个模型。最后我在第600步左右的lora模型达到了比较好的效果。(在150,300步时能到到0.97,0.99的结果)
其实在一开始配置环境的时候,训练模型时候报错
dataclasses.FrozenInstanceError: cannotassign to field optim
以及
ddp_find_unused_parameters
后面发现是transformers包版本在4.32.0的原因,只要重新
pip install transformers==4.31.0
就可以正常运行了这坑踩了我俩小时,是真要命。
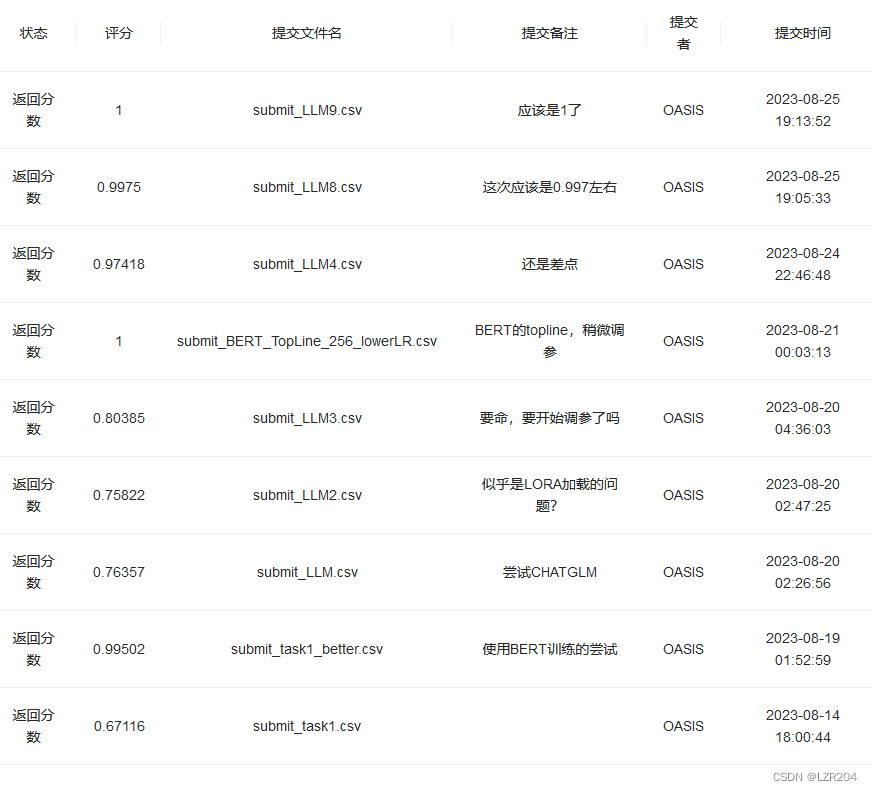
附上结果















 2257
2257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









