







 文章详细解释了回归模型、分类模型中的Accuracy与类别不平衡问题,重点介绍了ReceiverOperatingCharacteristic(ROC)曲线、Precision-Recall曲线以及F-Score的概念和应用,还涵盖了混淆矩阵在评估模型性能中的作用。
文章详细解释了回归模型、分类模型中的Accuracy与类别不平衡问题,重点介绍了ReceiverOperatingCharacteristic(ROC)曲线、Precision-Recall曲线以及F-Score的概念和应用,还涵盖了混淆矩阵在评估模型性能中的作用。
1.回归模型
回归模型常常使用MSE均方误差,预测值与真实值之间的平均差距
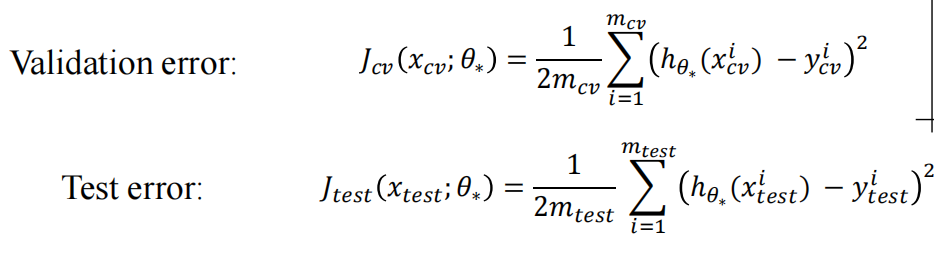
2.分类模型
2.1 Accuracy正确率
分类正确的数目的占比
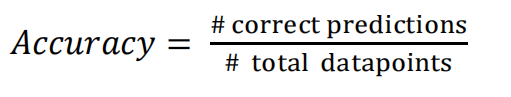
但在类别不平衡的情况下,模型可能倾向于预测占多数的类别,导致Acc高但对少数类别的预测效果其实比较差的。
2.2 类别不平衡的指标
1.先验知识
假设+1为positive正向类,-1为negative负向类。对于一个分类模型会有如下情况

True positive(TP):预测为positive,实际上确实为positive。正确的预测了正向类
False negative(FN):预测为negative,实际上却为positive。错误的预测成负向类
False positive(FP):预测为positive,实际上却为negative。错误的预测成正向类
True negative(TN):预测为negative,实际上确实为negative。正确的预测了负向类
样本总数量Total=TP+FN+TN
正向类样本数量P=TP+FN
负向类样本数量N=TN+FP
于是我们可以得到一些指标

2.Receiver Operating Characteristics Curve,ROC——接受者操作特征曲线
2.1 如何得到ROC曲线
假设我们有一个二分类模型,也就是逻辑回归模型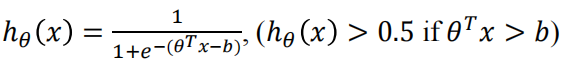
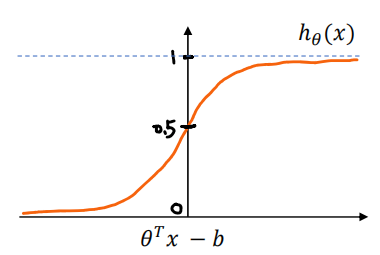
注意现在这个式子和以前有些不同,现在多了一个阈值(threshold)b,当![]() 时经过sigmoid函数输出会大于0.5,最终会输出1(有些地方的描述是修改输出1的阈值,两者想要说明的效果是一样的)
时经过sigmoid函数输出会大于0.5,最终会输出1(有些地方的描述是修改输出1的阈值,两者想要说明的效果是一样的)
当b趋向于-∞时,
恒>0,即
恒>0.5,最终对于任意x输入都预测为1。此时FN=0,TN=0,
,
当b趋向于+∞时,
,
当b由小变大时,FRP和TPR的值都会增加
最终对于每一个b,我们都可以得到一对TRP和FPR的值,以FPR为x轴,TPR为y轴绘制的图就是ROC图,如下图示例
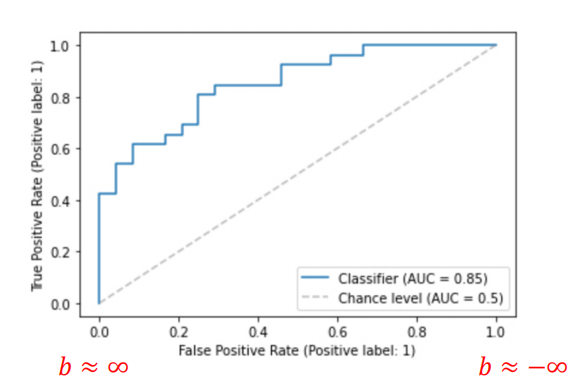
在二元分类任务中,ROC曲线用于描述接受真正样本并同时拒绝负样本的学习模型的性能。
2.2 如何通过ROC曲线判断比较模型性能
通常我们希望模型的TPR更高而FPR更低
第一种方法:更靠近左上角的曲线性能是更好的,因为TPR更高而FPR更低
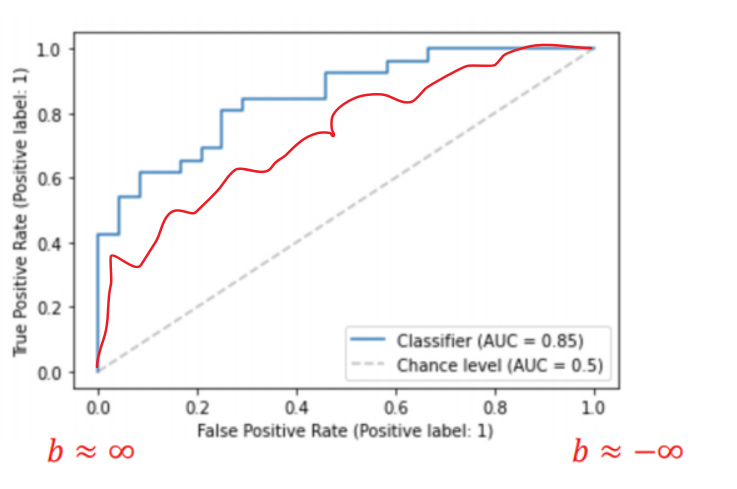
如蓝色的曲线的模型就好于红色曲线的模型
第二种方法:通过ROC曲线下方与坐标轴围成的面积大小AUC(Area under the curve),AUC越大,对应的模型性能越好。故又叫AUC-ROC曲线
2.3 对角线的意义
AUC-ROC 曲线的对角线代表随机猜测模型的性能。这条对角线是指当模型对样本进行随机分类时得到的 ROC 曲线。在这条对角线上,TPR=FPR,因为随机猜测的模型的正确率为0.5,对正负样本的分类没有区分度,所以这种情况下 ROC 曲线表现为一条直线,斜率为 1。
对于 AUC-ROC 曲线,如果一个模型的 ROC 曲线在对角线上方(AUC 值大于 0.5),表示模型的性能优于随机猜测;而如果 ROC 曲线在对角线以下(AUC 值小于 0.5),则说明模型性能不如随机猜测。
因此,AUC-ROC 曲线下的面积(AUC 值)越接近于 1,代表模型的性能越好;而越接近 0.5,则说明模型的性能越接近于随机猜测。
3.Precision and Recall
3.1 定义
1.召回率/查全率Recall(TPR),召回率是指在所有实际属于正类别的样本中,被分类器正确预测为正类别的样本所占的比例。例:在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的百分比
2.精确率/查准率Precision=,精确率是指在所有被分类器预测为正类别的样本中,实际上确实属于正类别的样本所占的比例。例:我所有我们预测有恶性肿瘤的病人中,实际上由恶性肿瘤的病人的百分比
3.2 性质
- 召回率和精确率适用于类别不平衡
-
提高精确率可能会导致召回率下降(常常是提高预测1的阈值),因为模型更谨慎,更倾向于只将非常确信是正例的样本预测为正例,这可能导致漏掉一些的真正例,从而降低召回率。
-
提高召回率可能会导致精确率下降(常常是降低预测1的阈值),因为模型更倾向于将更多的样本预测为正例,包括一些可能不是真正正例的样本,这可能会增加假正例的数量,从而降低精确率。
-
一个好的模型两者都应该兼并良好的精确率和召回率


3.3 PR-curve
同样的,我们将不同的阈值情况下,得到两者的值绘制成图表,就得到了PR-curve
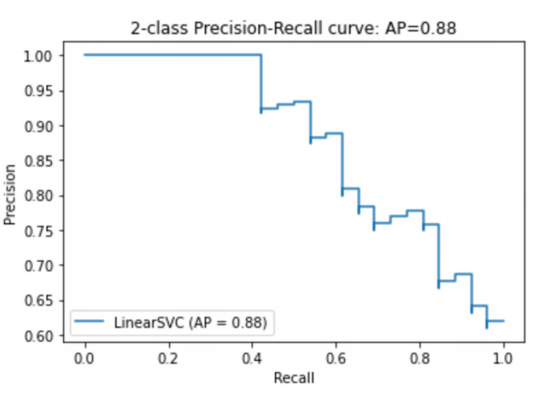
3.4 平均精度(Average Precision,AP)
PR-curve曲线与坐标轴围成的面积。AP 考虑了不同阈值下精确率和召回率之间的平衡,一个较高的 AP 值意味着在保持高精确率的同时,也能保持较高的召回率。AP是针对单个类来说的。
3.5 Mean Average Precision (mAP)
mAP 是衡量模型对多个类别的检测性能的常见指标。对每个类别,都会计算其对应的 AP,然后将所有类别的 AP 取平均得到 mAP。
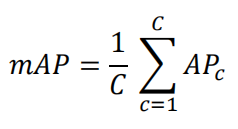 (C代表类别数目)
(C代表类别数目)
当类别平衡时,我们更关注精确率而不是召回率,于是mAP可以修改为如下
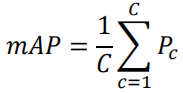
直接使用每个类精确率的均值
3.6 F-Score
F-分数是精确率和召回率的加权调和平均值,用于评估模型在不同类别之间取得平衡的能力。
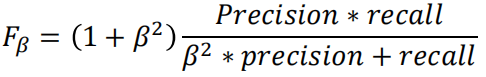
β 用于调整 F-分数中精确率和召回率的权重,产生不同的平衡效果。
- 当 β > 1 时,模型对召回率的重视程度更高,F-分数更倾向于关注召回率。
- 当 β < 1 时,模型对精确率的重视程度更高,F-分数更倾向于关注精确率。
- 当 β = 1 时,即为 F1-Score
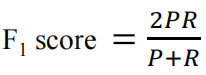
2.3 混淆矩阵(Confusion Matrix)
混淆矩阵是一个分类情况的可视化工具
- 混淆矩阵的每一列代表了模型预测类别,每一列方格总数目代表模型预测该列类别的数目/占比
- 每一行代表了数据的真实类别,每一行方格总数目代表真实该行类别的数目/占比(行列反过来也可以)
- 方格中以数目或者比例的形式显示
- 常常还会有热力图提高可视化效果
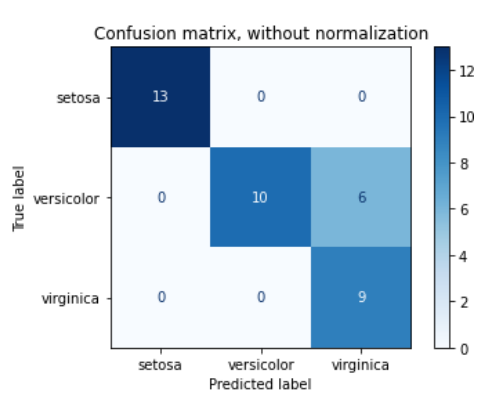
解读一下这个混淆矩阵:
- 类别共有三类:setosa,versicolor,virginica
- 13代表模型预测为setosa同时真实标签也为setosa为13个;10代表模型预测为versicolor同时真实标签为versicolor为10个,依次类推
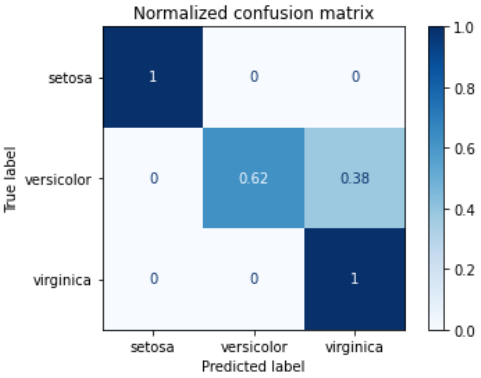
- 左上角1代表,所有的setosa都被正确预测;0.62代表模型预测versicolor正确的占versicolor总数目比例62%,另外有38%被预测成了virginica

















 337
337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









