







本次目标:
kafka的安装和配置
kafka测试
spark读取kafka数据
一、Kafka的安装和配置
上传:kafka_2.11-2.41.tgz
将上传的文件放在/opt/apps下解压并改名为kafka (注:一般改名是包名+版本,便于区分)
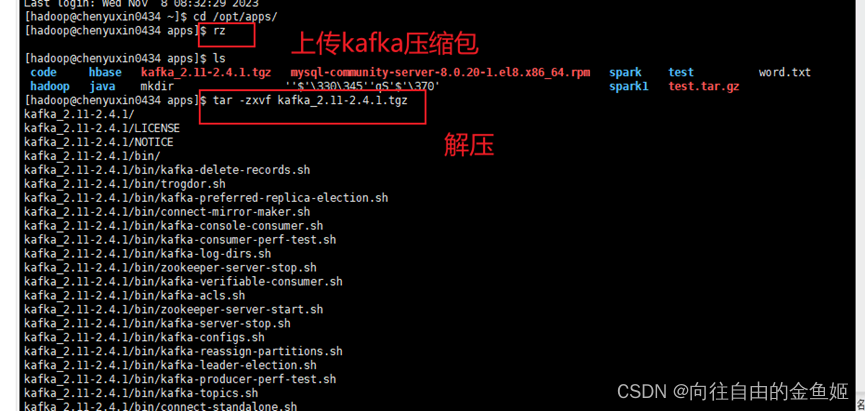
备份kafka目录下的config目录下的server.properties (安全起见,也可以不备份)

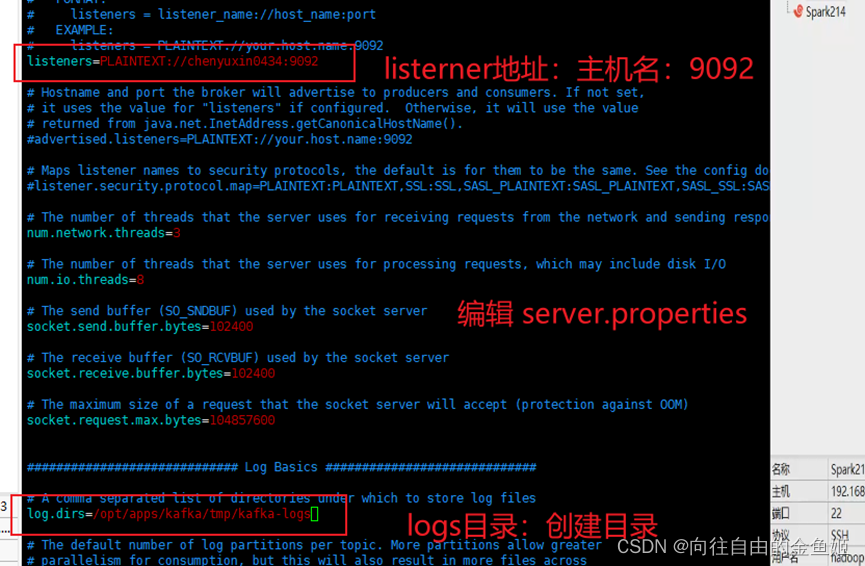
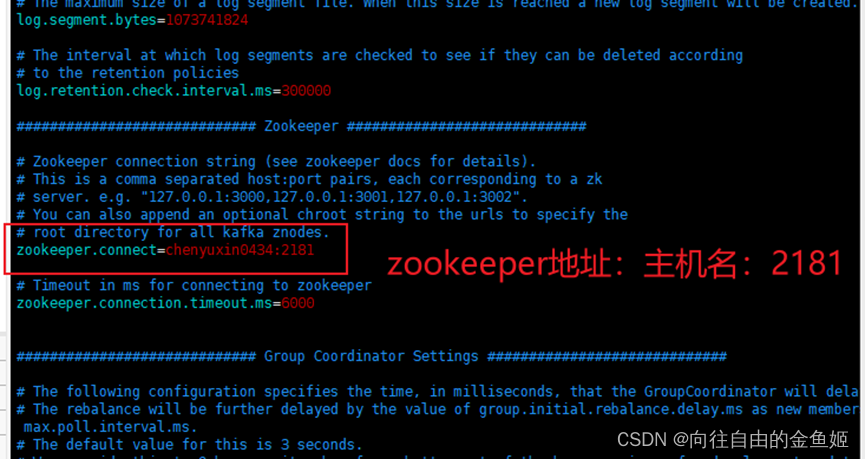
编辑server.properties添加 listener地址、zookeeper地址、logs目录
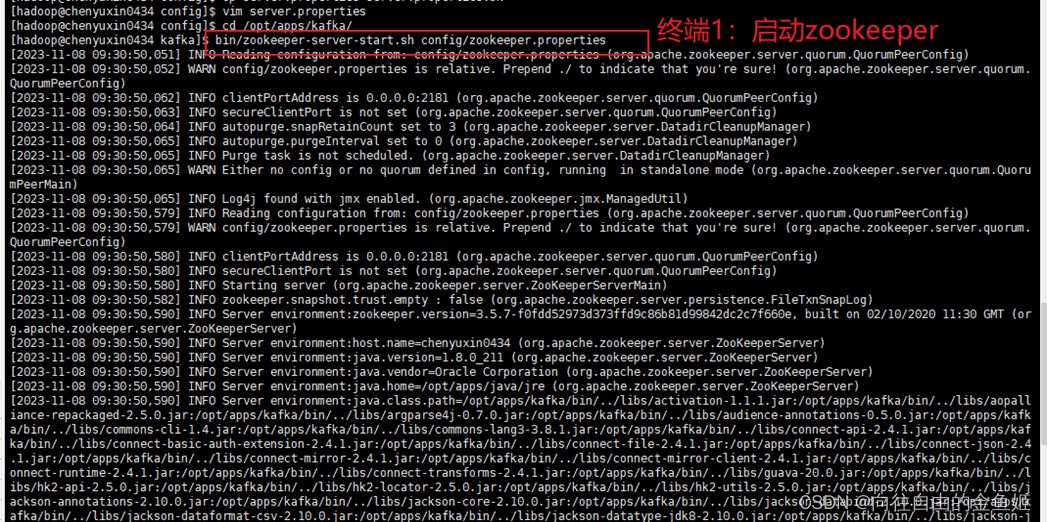
 二、Kafka测试 (因为并没有添加环境变量,所以最保险的办法是切换到/opt/apps/kafka/开启进程,分别在4个终端中运行,每个进程都不能中断)
二、Kafka测试 (因为并没有添加环境变量,所以最保险的办法是切换到/opt/apps/kafka/开启进程,分别在4个终端中运行,每个进程都不能中断)
终端1:启动zookeeper
终端2:启动kafka服务
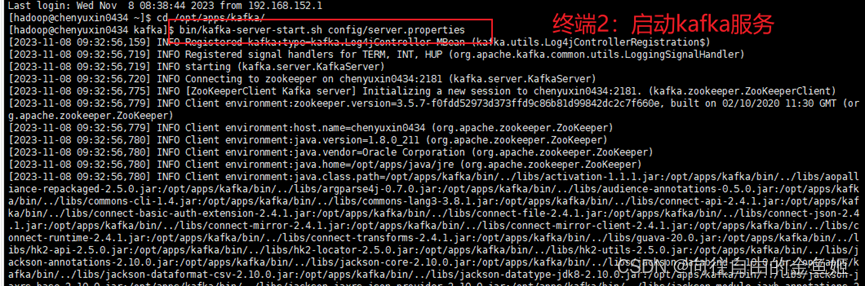 终端3:创建kafka主题,并开启主题写入数据
终端3:创建kafka主题,并开启主题写入数据
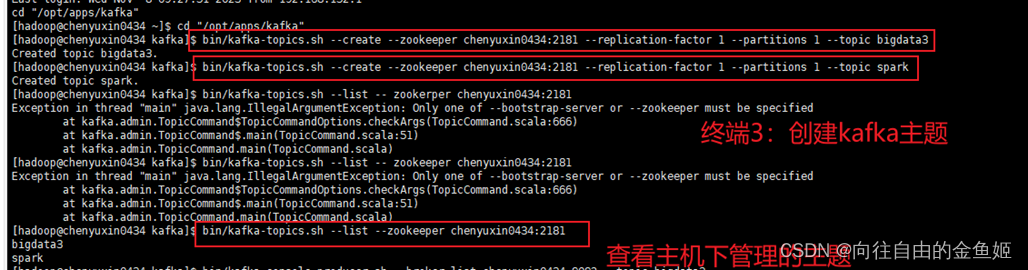
 终端4:kafka的测试
终端4:kafka的测试
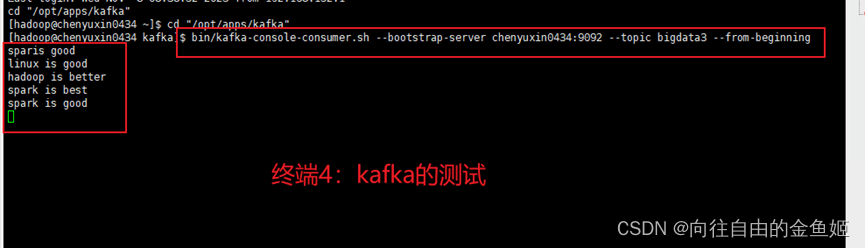 三、Spark读取kafka数据
三、Spark读取kafka数据
上传图中两个文件到spark/jars/kafka/下
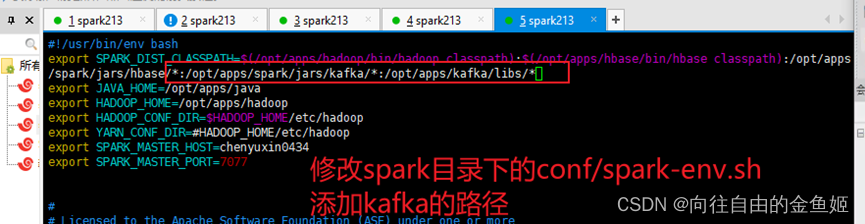
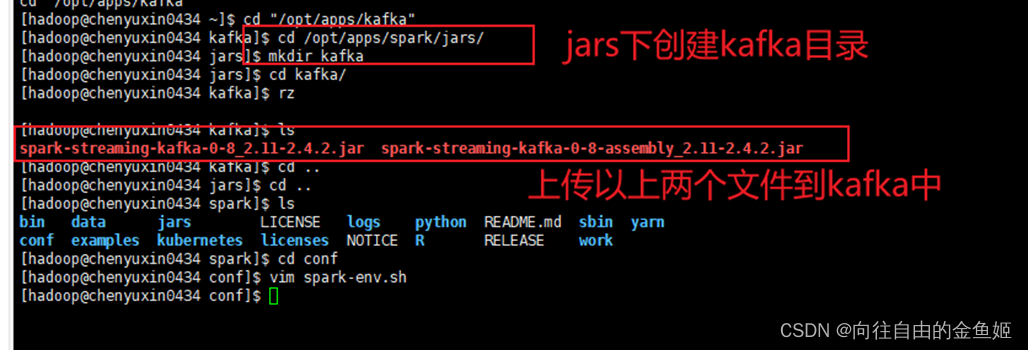 修改spark/conf/spark-env.sh 在$SPARK_DIST_CLASSPATH变量中加入
修改spark/conf/spark-env.sh 在$SPARK_DIST_CLASSPATH变量中加入
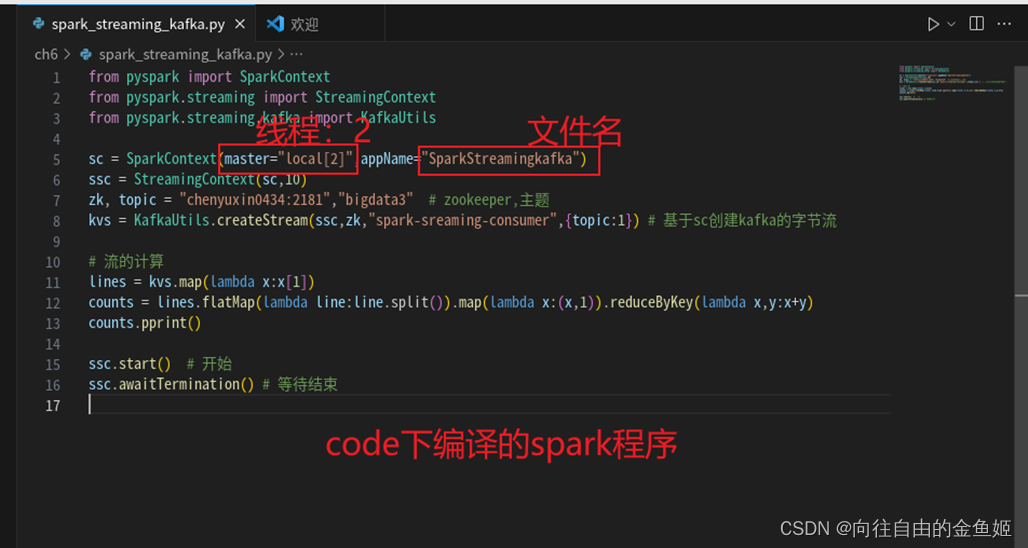
 在vm虚拟机打开code,编译程序,其中使用的主题是bigdata3 (亦可以再创建一个)
在vm虚拟机打开code,编译程序,其中使用的主题是bigdata3 (亦可以再创建一个)
图中的线程必须要有2个以上才可以运行,AppName不指定
 执行程序
执行程序
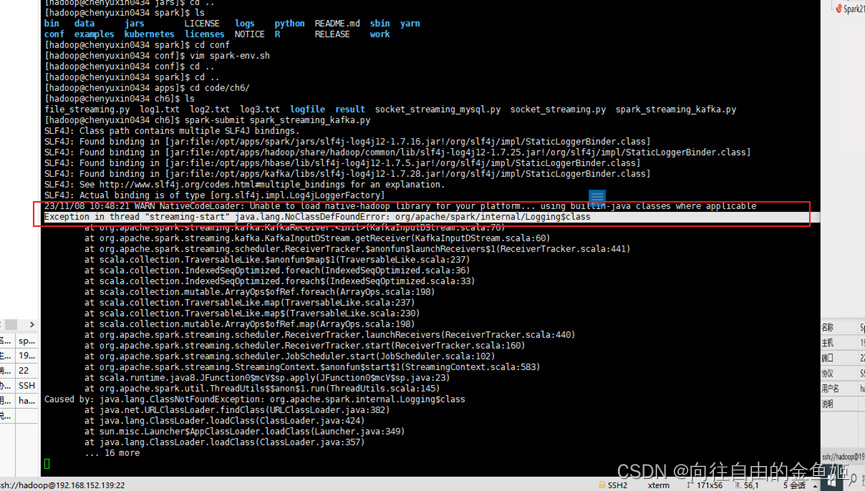
出现错误:Exception in thread “streaming-start”java.lang.NoClassDefFoundError:org/apache/spark/internal/Logging$class
提示没有这个类,原因是spark-core 的版本问题,才会出现兼容,以上安装的时候用的是 spark-core_2.11-2.4.1.jar,这里需要更换这个包
解决方法:
下载spark-core_2.11-2.4.7.jar,并将该文件拷贝到spark/jars/kafka/
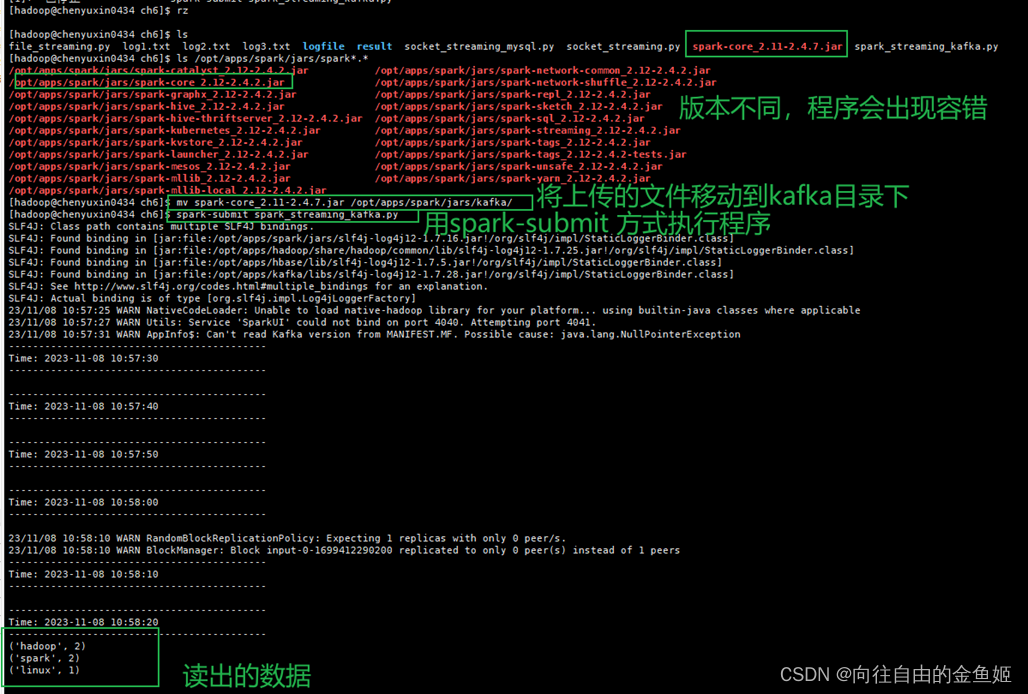
在终端3中写入数据
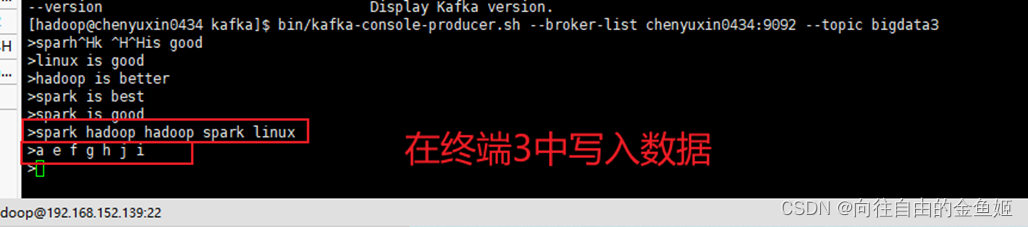
就可以看到流输出
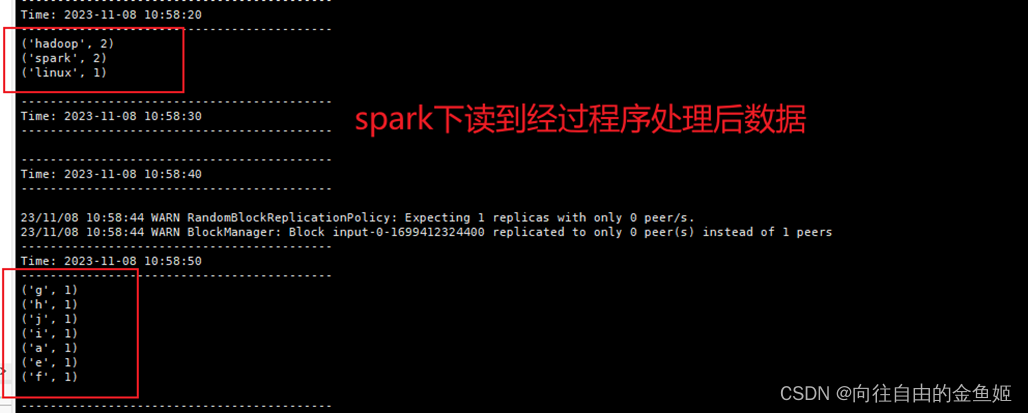 若拷贝后还是会出现错误,可以试试加上spark-core版本运行,原因是kafka目录下存在着两个不同版本的spark-core。(提醒:不能将低版本的删除,否则会出错)
若拷贝后还是会出现错误,可以试试加上spark-core版本运行,原因是kafka目录下存在着两个不同版本的spark-core。(提醒:不能将低版本的删除,否则会出错)
执行语句:spark-submit --jars spark-core_2.11-2.4.7.jar spark_streaming_kafka.py

















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









