




 本文提出CASR-Net,一种针对不规则文本的字符感知采样和校正网络,通过预测字符级几何属性,有效纠正文本实例,提升识别准确度。实验结果显示在多个基准数据集上优于传统方法,特别是在透视和弯曲文本识别上表现出色。
本文提出CASR-Net,一种针对不规则文本的字符感知采样和校正网络,通过预测字符级几何属性,有效纠正文本实例,提升识别准确度。实验结果显示在多个基准数据集上优于传统方法,特别是在透视和弯曲文本识别上表现出色。
摘要
由于形状和纹理变化较大,曲面场景文本识别在多媒体社会中是一项具有挑战性的任务。以前的方法通过等距离采样提取和校正文本行来解决这一问题,这忽略了字符级别信息并导致字符失真。为了解决这个问题,本文提出了一个字符感知采样和校正(CASR)模块,该模块根据每个字符的位置和方向信息来校正不规则文本实例。具体而言,CASR将每个字符视为基本单元,并预测用于采样和校正的字符级属性。我们的模块不仅利用详细的字符信息来获得更好的文本行纠正,而且在训练过程中采用字符级监督。此外,CASR提供了一个即插即用模块,可以很容易地集成到现有的文本识别流水线中。在几个基准测试上的大量实验表明,我们的方法获得了更准确的校正文本实例,并取得了令人满意的性能。我们将在未来发布我们的代码和模型。
1. introduction
在野外阅读文本是多媒体社会的一项基本任务,也是一项具有挑战性的任务,其目标是将文本实例的图像转换为一系列机器可读符号。作为一种重要的图像分析技术,该任务已广泛应用于各种现实世界应用,如自动驾驶、人机交互和视觉辅助。近年来,由于深度学习技术的成功,场景文本识别得到了显著的改进。这些识别模型的标准原理是使用编码网络来提取视觉上下文信息,然后使用解码模型来将特征向量转换成目标序列。解码模块主要基于一维序列到序列模型,该模型在处理不规则文本实例方面具有固有的局限性,特别是对于透视文本和弯曲文本,这为将文本图像转换为文本符号带来了新的挑战。
为了解决不规则文本识别问题,近年来提出了几种方法,大致可分为两类:基于二维(2D)注意力的方法和基于纠正的方法。对于2D注意力机制,生成2D注意力图用于特征对齐和序列解码。然而,由于注意力图不准确,识别性能受到限制。对于基于校正的方法,设计了特定的采样机制来生成控制点,用于通过薄板样条(TPS)将不规则文本实例校正为规范文本实例。例如,ASTER使用空间变换网络(STN)以弱监督的方式直接预测文本实例边界上的控制点,ScRN通过在校正模块中添加额外的监督来扩展这项工作。ASTER和ScRN的校正流水线如图1(a)和(b)所示。
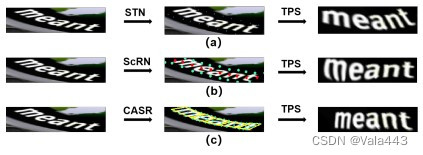
尽管使用了几个局部属性来获得精确的文本行,但文本级等距离采样过程在很大程度上忽略了字符级信息,并可能导致字符失真。由于字符是文本实例的基本单位,因此文本识别的关键是正确翻译每个字符。对于透视文本和曲线文本,识别性能高度依赖于单个字符是否被精确地纠正为规范形式。此外,由于TPS严格地将所选控制点转换到相应的预定义位置,因此控制点及其周围环境的纠正结果更为准确。基于以上观察,我们假设基于字符级采样策略的不规则文本实例纠正可以获得更好的结果,因为它将在纠正过程中包含更多的字符特定指导。
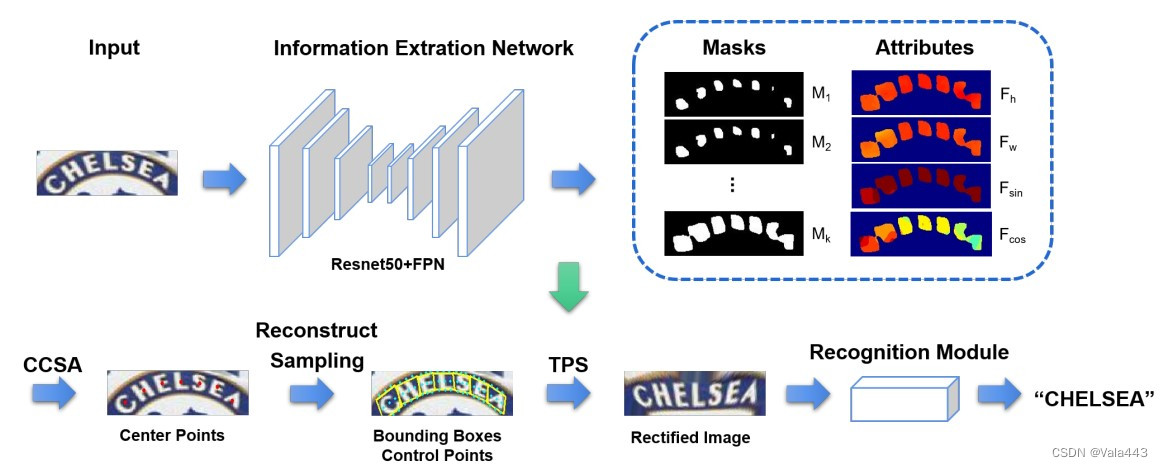
基于上述讨论,我们提出了一种新颖的字符感知采样和校正(CASR)模块,该模块根据每个字符的位置和方向信息来校正不规则文本实例。具体而言,CASR将每个字符视为一个基本单元,并使用基于分割的网络来预测字符特定的几何属性,包括每个字符的掩码、高度、宽度和角度。由于文本实例中的字符彼此非常接近,导致分离的困难,我们的模块预测了一组大小不同的字符级掩码,以避免粘连。然后,使用连接组件选择算法(CCSA)来获得不同掩码上每个单独字符的中心。基于这些几何属性,可以重建字符级文本实例,并生成用于图像校正的精确控制点,如图1(c)所示。因此,基于字符的采样过程可以确保每个字符在校正后保持接近水平,然后识别模块可以容易地将文本实例转换为序列。
我们将我们提出的CASR纳入常用的基于注意力的识别平台,以构建字符感知采样和校正网络(CASR-Net),整体流程如图2所示。已经进行了大量实验,以证明我们的CASR-Net在各种公共基准上的有效性。我们的CASR-Net在许多文本识别数据集,尤其是在不规则文本数据集(如ICDAR2015、SVTP和CUTE80)上取得了令人满意的性能。
本文的主要贡献总结如下:
- 我们注意到,特定于字符的采样是获得更准确的校正文本实例的一种合理且有前景的方法,并提出了字符感知采样和校正(CASR)模块来执行字符级校正。
- CASR是一个即插即用模块,我们将该模块纳入基于注意力的识别平台,以构建字符感知采样和校正网络(CASR-Net)
- 实验结果验证了我们的CASR网络的有效性,该网络在许多公共数据集(如SVT、ICDAR2013、ICDAR2015、SVTP和CUTE80数据集)上实现了令人满意的性能。
2. 相关工作
场景文本检测和识别形成了一个连续的流水线来定位文本区域和识别文本实例,这对于机器从场景图像中读取文本至关重要。检测模型被用于定位自然图像上的文本区域,而识别模型被进一步用于将文本实例转换为符号序列,这两者在该信息翻译过程中都很重要,本文重点关注场景文本识别。
A. 场景文本识别
在自然场景中阅读文本是一项具有挑战性的任务,并受到了业界和学术界的广泛关注。近年来提出了各种方法,可分为两种方法:基于自下而上的方法和基于自上而下的方法。在本节中,我们将简要介绍几种最先进的模型,并在[16]中对场景文本识别的发展进行了全面研究。
自下而上的方法首先生成字符级别预测,然后将每个字符连接到相应的序列中。文本信息由手工制作的特征提取模块提取,如描边生成和半马尔可夫条件随机场,然后使用分类器来预测文本实例中的每个字符。最近,几种基于深度学习的方法通过用神经网络替代手工制作的特征提取方法,显著提高了性能。例如,LCSegNet利用分割模型为每个字符生成逐像素预测,并使用条件随机场平滑标签分配,这在几个公共基准测试中实现了令人满意的性能。
自顶向下的方式采用另一种哲学来识别文本实例,它直接读取整个文本实例,而不需要对单个字符进行任何预测。受图像分类任务的启发,Jaderberg等人设计了一个具有90k个类别的分类网络,以识别90k个单词。然而,由于词汇表外的单词和分类网络中的巨大类别,这种方法不能被广泛使用。对于任意长度的文本实例,本文提出了序列方法,大致可分为两类:基于连接的时间分类(CTC)方法和基于注意力的方法。基于CTC的方法通常使用深度网络来编码视觉上下文和序列信息,然后使用CTC来获得任意长度文本的条件概率。近年来,注意力机制已广泛应用于识别模型中,该模型为文本区域中的每个字符位置生成聚焦图,以提高识别性能。
B. 不规则文本实例的识别
由于基于CTC和基于注意力的模型的成功,在常规和近水平文本中阅读文本已取得了可接受的性能,并已广泛应用于各种现实应用中。然而,由于序列模型的固有局限性,对不规则文本实例的识别仍然是一项具有挑战性的任务,尤其是对透视文本和曲线文本。最近,已经提出了几种方法,它们可以分为两类。第一种方法通过使用2D注意力模型来对齐特征并解码相应的序列,将一维(1D)序列模型推广为二维(2D)版本。对于这种方法,识别性能与深度网络生成的不准确注意力图相矛盾,因此需要进一步改进。第二种方法采用了一个校正模块,将不规则文本实例转换为规则和接近水平的文本实例。ASTER使用空间变换网络(STN)[12]来直接预测输入图像上的控制点。由于缺乏指导,这种无监督方法无法足够精确地预测控制点。ScRN通过在整流模块中添加额外的监督来扩展ASTER。它预测具有多个几何属性的文本中心线(TCL),并通过在TCL上等距采样生成文本级控制点。然而,这种方法忽略了可以为TPS转换提供更准确信息的字符级信息。[34]通过提出渐进校正网络以迭代方式识别不规则文本实例来扩展ASTER。[34]和我们的模型的主要区别有两个:1.[34]是一种多步骤方法,它将在每个步骤估计转换参数以提高识别性能,而我们的方法是一种单步方法。2.我们的方法为每个字符引入几何监督,以预测更准确的字符信息,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2596
2596




 到【灌水乐园】发言
到【灌水乐园】发言







