






论文地址:[2210.08161] Geometric Representation Learning for Document Image Rectification (arxiv.org)
代码:
摘要
在文档图像矫正问题中,真实图像与失真图像存在着丰富的几何约束条件。然而,在现存的先进的解决方法中,这些几何约束大多数被忽略了,这大大限制了矫正的性能。为此,我们提出了DocGeoNet进行文档图像矫正,通过引入显式的几何表征。从技术上讲,所提出的几何表征学习中涉及文档图像的两个典型的属性,即3D形状和文本行。我们的动机来自于一种见解:3D形状为矫正一张扭曲的文档图像提供了全局unwarping线索,然而忽略了局部结构;另一方面,文本行互补地为局部图案提供了显示几何约束。学到的几何表征有效的连接了扭曲图像与真实图像。大量实验表明了我们框架的有效性,并在DocUNet Benchmark数据集和我们提出的DIR300测试集上证明了我们的DocGeoNet优于最先进的方法。
1、introduction
随着智能手机的普及,越来越多的人使用它们来数字化文档文件。与典型的平板扫描仪相比,智能手机为文档图像捕获提供了一种灵活、便携和非接触的方式。然而,由于不受控制的物理变形、不均匀的照明和各种相机角度,这些文档图像总是失真的。这种失真使这些图像在许多正式审查场合无效,并可能导致下游应用程序的失败,如自动文本识别、分析、检索和编辑。为此,近几年来,文档图像矫正已成为一个新兴的研究课题。在这项工作中,我们专注于文档图像的几何失真校正,旨在将任意扭曲的文档校正为其原始平面形状。
传统上,文档图像校正是通过3D重建来解决的。通常,对扭曲文档的3D网格进行估计以使文档图像变平。然而,这种技术要么是基于辅助硬件,要么是用多视点图像开发的,这在个人应用中是不友好的。其他一些方法假设文档表面上有一个参数化模型,并通过提取特定的表示来优化模型,例如着色、边界、文本线或纹理流。然而,过于简化的参数模型通常导致性能有限,并且优化过程引入了不可忽略的计算成本。最近,基于深度学习的解决方案已成为传统方法的一种很有前途的替代方案。通过训练网络来直接预测扭曲流,可以通过对扭曲图像中的像素进行重新采样来校正变形的文档图像。尽管这些方法具有最先进的性能,但失真图像和真实图像之间的丰富几何约束在很大程度上被忽略了。
通常,在文档图像中,纹理主要存在于文本行中。注意,失真图像和真实图像之间的文本线之间存在强烈的几何约束,即,如果弯曲的文本线是文档中的水平文本线,则它们在校正后应该是直的。换句话说,文本行为纠正提供了强有力的提示。然而,现有的方法都只是通过对预测的翘曲流的监督,在深度网络中隐含地学习这一先验知识,这导致了次优性能。此外,与失真的文档图像相比,3D形状的属性是一种更明确的表示,它直接决定了取消绘制过程。以上两个属性桥接了失真和真实的图像,并相互补充:文本行的分布反映了文档的局部变形,这是对局部结构细节上3D形状的补充。基于上述动机,我们在深度网络中从这些属性中明确学习几何约束,以提高校正性能。
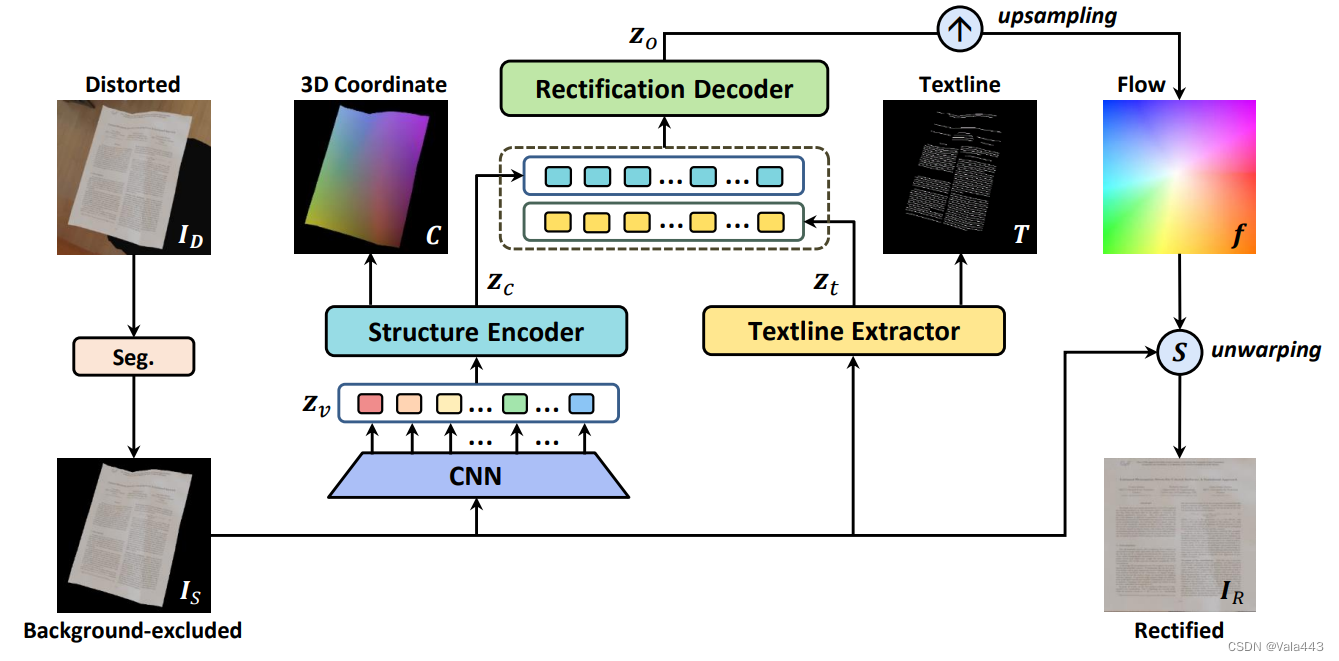
在这项工作中,我们提出了DocGeoNet,一种新的用于文档图像校正的深度网络。DocGeoNet通过引入从文档属性派生的几何约束表示,将失真图像与其真实情况桥接起来。它由一个结构编码器、一个文本行提取器和一个整流解码器组成。具体而言,给定失真的文档图像,DocGeoNet采用结构编码器和文本线提取器分别对变形文档的3D形状进行建模并提取其文本线。然后,为了利用这两个属性的互补性,并利用它们连接失真和真实图像的直接约束,我们进一步融合了它们的表示,并在校正解码器中预测校正。在DocGeoNet的培训过程中,以端到端的方式优化了3D形状、文本行和校正的学习。此外,考虑到3D形状是全局属性,而文本行是局部属性,所提出的DocGeoNet采用了混合网络结构,利用自注意机制和卷积运算来增强表示学习。为了评估我们的方法,在Doc3D数据集、DocUNet基准数据集和我们提出的具有挑战性的DIR300基准数据集上进行了大量实验。结果证明了我们的方法的有效性以及与现有最先进方法相比的优势。总之,我们作出了以下三方面的贡献:
- 我们提出了DocGeoNet,这是一种新的深度网络,它对失真图像和目标校正图像之间的几何约束进行显式表示学习,以提高文档图像校正的性能。
- 我们设计了一个新的pipeline来自动注释训练集中失真文档图像的文本行。此外,为了反映现有工作的有效性,我们提出了一个新的大规模挑战基准数据集。
- 我们进行了广泛的实验来验证DocGeoNet的优点,并在流行的和提出的基准上展示了最先进的结果。
2、相关工作
基于三维重建的校正。早期的方法首先估计变形文档的3D网格,然后将其展平为平面形状。Brown和Seales部署了一个结构光3D采集系统来采集变形文档的3D模型。张等人使用激光测距扫描仪,并使用物理建模技术进行修复。Meng等人利用两个结构化光束照射在文档上,恢复文档表面的两条空间曲线。这种方法通常依赖于辅助硬件来扫描变形的文档,这在日常个人使用中是不友好的。
另一方面,一些方法利用多视点图像来重建3D文档模型。Tsoi等人基于文档的边界将文档的多个视图转换为规范坐标系。Koo等人通过SIFT配准两幅图像中的对应点来构建变形表面。最近,游等人提出了一种基于多视点图像的山脊感知曲面重建方法。然而,在上述工作中,多视角拍摄的参与限制了其进一步的应用。
一些其他方法旨在从单个视图重建3D形状。通常,他们假设文档表面上有一个参数化模型,并通过提取特定的表示来优化模型,例如着色、边界、文本线或纹理流。Tan等人根据阴影信息构建书籍表面的3D形状。他等人提取了一个图书边界模型来重建图书表面。Cao等人和Meng等人将表面表示为一般的圆柱形表面,并提取文本线来估计模型的参数。
基于深度学习的矫正。对于文档图像校正,第一种基于学习的方法是DocUNet。通过训练堆叠的UNet,它直接回归逐像素的位移场来校正几何失真。后来,李等人提出先对失真的图像补丁进行校正,然后缝合进行校正。谢等人为逐像素位移场的学习添加了平滑约束。最近,Amir等人提出学习文档中单词的方向,Das等人提出用UNet对文档的3D形状进行建模。冯等人从自然语言处理任务中引入transformer来改进特征表示。Das等人预测了局部变形场,并将它们与全局信息拼接在一起,以获得改进的解扭曲。
与上述方法不同,在这项工作中,我们通过引入几何约束的表示学习来处理文档图像校正,该几何约束桥接失真图像和校正图像,而最近最先进的方法在很大程度上忽略了这一点。
3、方法
在本节中,我们介绍了我们的文档图像校正网络(DocGeoNet),用于对失真的文档图像进行几何校正。给定失真文档图像,我们的DocGeoNet估计了一个密集的位移场
作为warping flow。基于
,被矫正图像
的像素
能够获得,通过从失真图像
中采样某个像素
。如图1所示,我们的框架由三个关键组成部分组成:(1)背景去除的预处理,(2)从两个文档属性中学习几何约束表示,包括3D形状和文本线,以及(3)表示融合和几何校正。这里,第一个预处理阶段是独立训练的,后两个阶段是可微分的,并组成一个端到端可训练的架构。在下文中,我们将分别阐述这三个组成部分。
3.1 预处理
对于文档图像的几何校正,将整个失真图像作为校正网络的输入是一种通用操作。然而,除了预测校正之外,它还涉及到对前景文档进行本地化的外隐学习,这限制了性能。因此,在[9,10]之后,我们首先采用预处理操作来去除聚集的背景,因此下面的网络可以专注于失真的校正。
具体来说,给定一个失真的RGB文档图像,利用轻量级语义分割网络来预测前景文档的置信度图。然后,用阈值τ进一步对置信图进行二值化,以获得文档区域掩码
。随后,获得去除背景的文档图像
,预处理网络使用二进制交叉熵损失独立训练:
3.2 结构编码器和文本线提取器
在文档图像中,文本线是主要纹理,它包含用于校正的直接几何约束。换句话说,与ground truth中的水平或垂直文本线相对应的扭曲弯曲文本线在校正后应该是直的。此外,文本行的分布也反映了文档的变形。因此,文本行为纠正提供了强有力的提示。此外,对于几何校正,与失真的文档图像相比,3D形状是更直接的表示,它决定了去扭曲过程。因此,我们建议对3D形状进行建模,并提取网络中变形文档的文本线,以利用它们的几何约束来桥接失真图像和校正图像。
具体来说,如图1所示,给定一个排除背景的文档图像,我们采用两个平行的子网络分别对3D形状进行建模并提取文本线。我们使用基于transformer的[36]子网络来学习3D形状,并使用基于CNN的子网络学习文本线。采用这种设计有两个考虑因素。首先,物理扭曲论文中的每个部分都是相互关联的,因此我们引入了自注意机制[36]来捕获长距离特征依赖关系。其次,像素是否属于文本行更多地取决于局部特征,因此我们在这里利用了卷积运算。在下文中,我们详细介绍了两个子网络,即结构编码器和文本行提取器。
结构编码器。给定一张去除背景的文档图像,一个包含6个残差块的卷积模块生成了feature map
,其中C为128.feature map的分辨率每经过两个残差块就减少1/2.为了适应后续transformer编码器的序列输入形式,我们将z展平为一系列tokens:
,其中
是tokens的数量。
由于transformer层是置换不变的,为了使其对输入标记的原始2D位置敏感,我们使用正弦空间位置编码作为视觉特征的补充。具体来说,位置编码加入到每一个transformer层的query和key编码中。我们堆叠了6个transformer编码层,每层都包含一个多头自注意力模块和前馈神经网络。对于第i个encoder层,输出表示为:
其中W的维度都是M*C*C_w,M=8表示注意力头的数量,C_w=256表示注意力层的特征维度。transformer层并行进行全局视觉上下文推理,并输出与形状相同的高级视觉嵌入
。
我们将输出特征reshape成
。最后,我们使用双线性采样上采样经过reshape的feature map来匹配ground truth 3D 坐标图,然后使用3*3卷积将维度降到3.那之后,我们得到了预测的3D坐标图,每个像素值对应文档图像的3D坐标。
文本行提取器。我们在前景文档区域上通过逐像素的二进制分类来分割文本行。给定一张去除背景的文档图像,预测一张置信度图
,值在(0,1)之间。这包含了每个像素的置信度(文本/非文本)。
文本行提取器采用紧凑的多尺度CNN网络。它由收缩部分、扩张部分和分类部分组成。对于收缩部分,我们重复应用两个3×3卷积层来编码来自的纹理特征,每个卷积层后面都有一个校正线性单元(ReLU)和一个2×2最大池化操作,步长为2,用于下采样。对于扩展部分,在每个尺度上基于双线性插值对特征图进行上采样后,我们将其与来自收缩路径的相应特征图连接,然后是两个3×3卷积层和一个ReLU。在分类部分,使用1x1卷积层和Sigmoid函数来生成置信图
。
3.3 校正解码器
混合表征学习。为了利用这两个属性的互补性,并利用它们的几何约束来桥接失真图像和目标校正图像,我们进一步融合它们的表征,并预测校正解码器中的校正。具体来说,我们首先将文本线提取器的扩张部分的1/8分辨率表征图展平为2D特征序列.然后,我们将其与
融合,即结构编码器中的第四层transformer编码器。融合的表征放入另一个6个transformer编码器来获得融合表征
.
校正估计。将获得的送入可学习模块中来执行上采样并预测高分辨率矫正估计。具体来说,我们首先通过两层卷积网络预测粗分辨率位移图
.然后,我们上采样
到
,通过采用每个像素的粗分辨率邻居的3×3网格的可学习加权组合。
3.4 训练目标
4、DIR300数据集
在本节中,我们介绍了DIR300数据集,这是一个用于文档图像校正的新数据集。在下文中,我们首先回顾以前的数据集,然后详细介绍介绍的数据集的细节。
4.1 重温现有数据集
Doc3D没有文本行注释。
DocUNet只有130张文档图像,太少。
4.2 数据集细节
我们加倍努力构建DIR300数据集。一方面,我们使用文本行注释扩展合成的Doc3D数据集以构建训练集。另一方面,我们捕获了300个真实的文档样本,以根据DocUNet Benchmark数据集构建更大的测试集。
训练集。在这里,我们描述了如何在Doc3D数据集上以较少的劳动力需求生成文本行注释。通常,很难在失真的文档图像中定位文本行,因为文本行具有各种形状。但是在扁平文档图像中实现它很容易。因此,我们使用ground truth扭曲流校正Doc3D数据集中的所有失真图像,然后通过以下步骤检测水平文本线。

具体而言,如图2(a)所示,我们首先将校正后的图像转换为灰度,并基于局部高斯加权和进行自适应二值化。接下来,我们在二值图像中进行水平膨胀,以获得连接区域及其相应的边界框。然后,我们对边界框的形状设置阈值,以过滤掉非文本线连接的区域。最后,我们定位边界框的中心和水平长度,以生成水平文本线。在使用翘曲流将这些水平文本线映射到原始扭曲图像之后,我们获得弯曲文本线注释。如图2(b)所示,我们可视化了一些文本行注释示例,其中大多数文本行都得到了准确的注释。值得注意的是,我们注意到,由于大小的原因,在过滤时会遗漏一些带注释的文本行,但它们在网络的容错范围内。
测试集。我们用移动相机拍摄的照片构建了DIR300数据集的测试集。它包含300个文档中的300张真实文档照片。与DocUNet Benchmark数据集相比,DIR300中失真的文档图像涉及更复杂的背景和各种照明条件。此外,我们还增加了翘曲文件的变形程度。创建细节在补充材料中提供。据我们所知,DIR300测试集是目前评估文档图像校正的最大真实数据基准。

















 2694
2694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









