






本周开启隐语的第四次课程学习,关于隐语的安装部署及简单体验。
1. 隐语部署模式
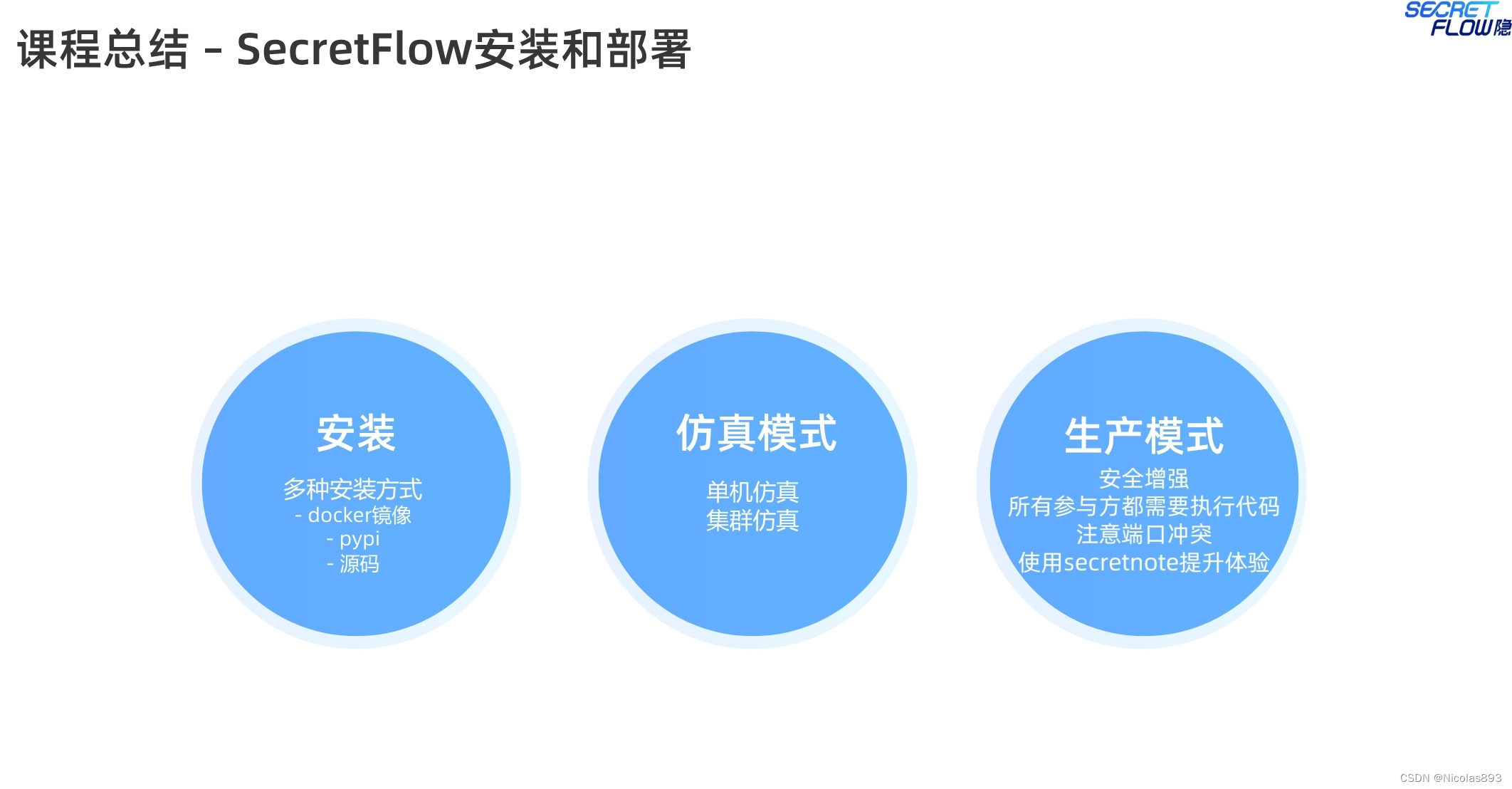

对于隐私计算开发以及业务生成场景使用,提供两种不同的模式:
(1)仿真模式,包括单机仿真以及集群仿真。
仿真模式具备很多优势。在这点上,业内的隐私计算厂商基本都有提供,但隐语可能在
这方面体验感会更好一些,投入了更多的资源去完善。
a. 成本低
开发者:在仿真模式下,开发者可以在单机或集群环境中模拟生产环境,进行调试
和测试,避免了直接在真实数据上操作的高成本和高风险。
使用者:可以在仿真模式下熟悉平台的功能和操作流程,而无需承担数据泄露或系
统故障的风险。
b. 高效调试
开发者:可以在仿真模式下快速迭代开发和测试代码,查找和解决问题,提升开发
效率。
使用者:可以快速验证其应用程序或流程在仿真环境中的表现,确保在投入生产前
已经过充分测试。
c. 安全性
开发者:仿真模式下使用的是模拟数据或脱敏数据,降低了实际数据泄露的风险。
使用者:在进行功能测试和性能测试时,无需担心实际数据的安全性问题。
(2)生产模式,多机部署执行。更加注重安全性以及真实环境。
a. 安全增强
开发者:生产模式下所有参与方都需要执行代码,并且平台提供了额外的安全增强措
施,如数据加密、访问控制等,确保数据传输和处理的安全性。
使用者:在生产模式下,用户的数据得到了严格保护,符合企业和行业的安全标准和
合规要求。
b. 高可靠性
开发者:生产模式经过严格测试和验证,能够在高负载下稳定运行,确保系统的可
靠性和可用性。
使用者:生产模式提供了可靠的计算和存储服务,能够处理大规模数据和复杂计算
任务,保证业务的连续性和稳定性。
c. 真实场景
开发者:在生产模式下,可以在真实数据和真实环境中验证和优化算法和模型,提
升模型的准确性和适用性。
使用者:能够在实际业务场景中使用平台的功能,获得真实有效的计算结果,推动
业务决策和发展。
2. 隐语部署资源要求及安装

隐语在多系统方面的支持做的还挺不错,包括常见的linux系统、macOS系统,以及支持windows内置的WSL2 linux子系统。python的版本要求是3.8及以上,隐私计算行业公开的资料看,普遍厂商都将python升级到了3.10之后,一方面出于漏洞修复考虑,另一方面基于性能考虑。

隐私计算一旦包含了tensorflow、pytorch等第三方包,一般docker镜像的大小会扩大到2-3G,业内厂商,比如蓝象提出一种空中安装的方式来提供安装服务,一开始可以是一个小的包,需要安装的全部服务的时候才会将所有的requirements都安装。因为你如果只是想要安全求交服务,完全没必要安装大且重的联邦学习模块的内容。类似富数等厂商,与隐语一样,可以提供lite的安装部署包,体积较小,适合轻量化部署。这种也是行业服务机构过程中衍生出来的共识。

隐语提供了多种安装方式,包括docker镜像、pypi、源码等。一般来说,docker镜像部署是最一步到位和简单的,包含了运行应用所需的所有依赖和环境配置,无论是在开发、测试还是生产环境,使用 Docker 都能确保应用运行的一致性。这个也是业内目前看,最普遍采用的方案。

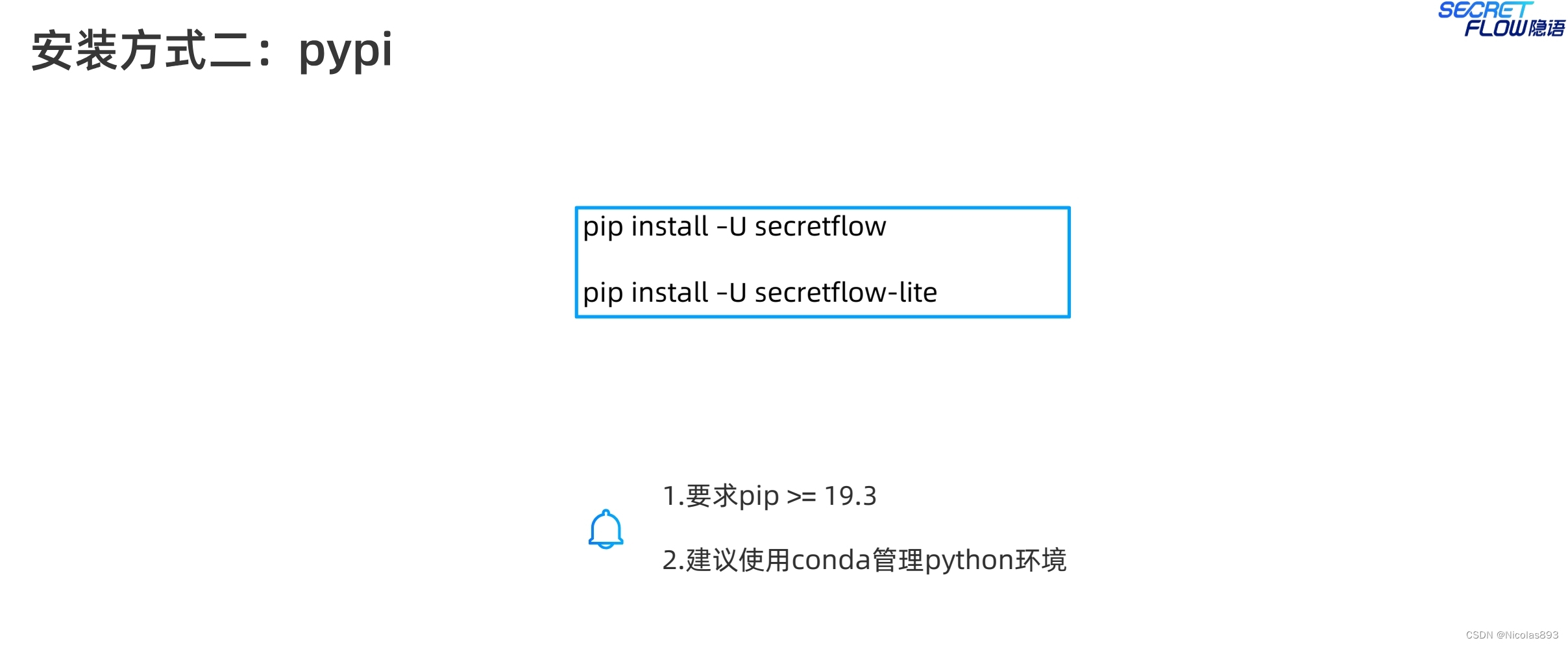

其他诸如pypi安装、源码安装,更适合开发者用来研发和调试。不过只要下载docker镜像的速度能保证的基础上,个人还是更推荐使用docker的安装模式,简单方便。
3. 隐语使用初探
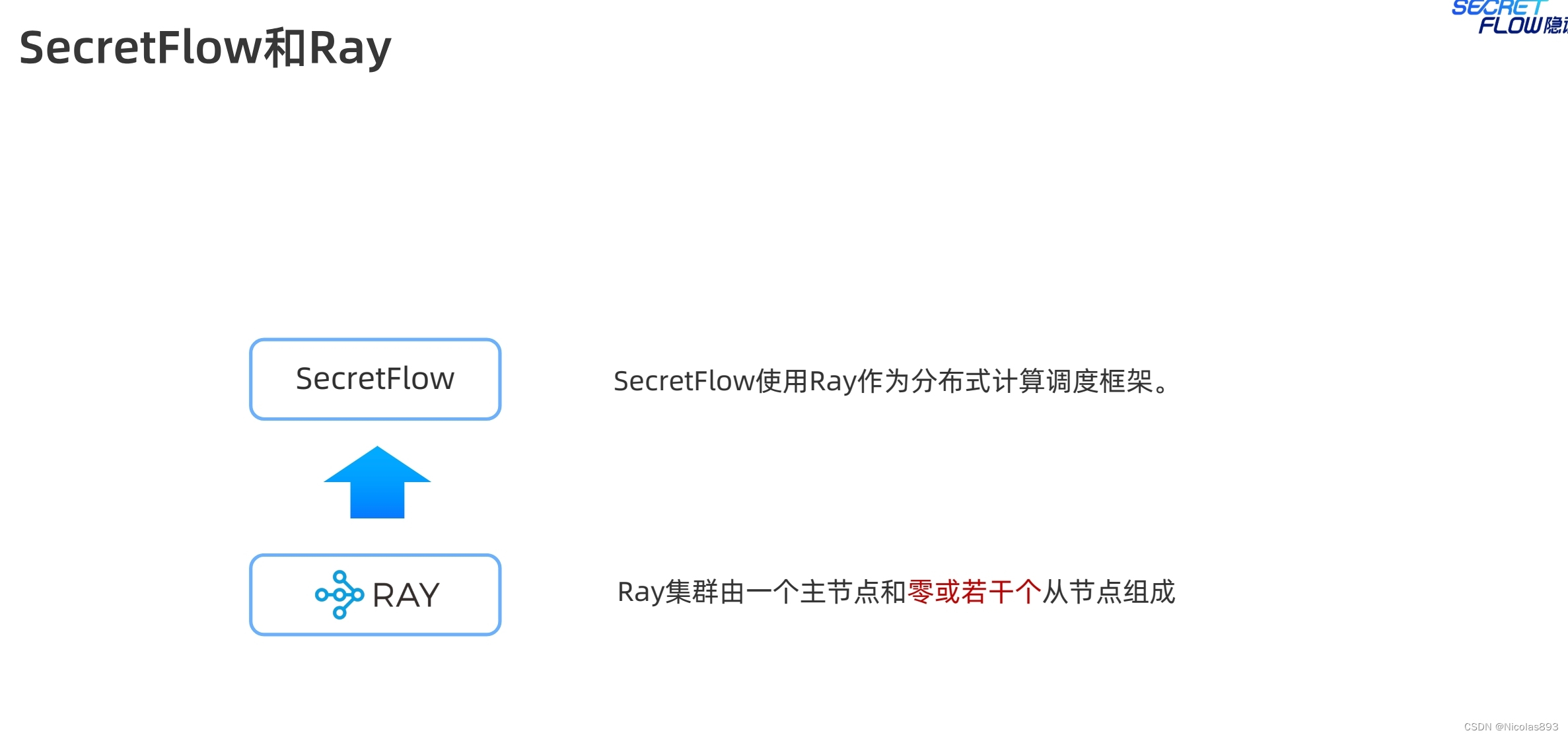
3.1 Ray基本概念
隐语是基于 RayFed 实现,RayFed 是 Ray 框架的一个扩展,用于实现跨集群的分布式计算。因此,理解 Ray 的使用和分布式调度是理解隐语的关键。以下是如何从 Ray 的使用来理解隐语的使用和分布式调度的详细说明:
Ray 任务:Ray 允许用户定义并行任务,这些任务可以在不同的节点上执行。每个任务都是一个独立的计算单元,可以由 Ray 调度器分配到集群中的任意节点。
Actor 模式:Ray 中的 Actor 是一个有状态的计算单元,能够维护状态并处理消息。Actors 可以在不同节点之间通信,从而实现复杂的分布式应用。
资源隔离:Ray 通过定义资源(如 CPU、内存等)来管理任务和 Actor 的资源分配。用户可以指定每个任务或 Actor 需要的资源,Ray 会根据资源情况调度这些任务。
自动扩展:Ray 支持自动扩展,可以根据任务的负载动态增加或减少节点,以优化资源利用和任务执行效率。
对象存储:Ray 提供了分布式对象存储(Plasma),允许任务之间共享数据。数据可以存储在内存中,提供高效的读写性能。
任务依赖:Ray 允许用户定义任务之间的依赖关系,调度器会根据依赖关系自动安排任务的执行顺序。
3.2 基于ray来理解隐语的使用和分布式调度(个人的理解)
隐语基于 RayFed 实现,RayFed 扩展了 Ray 的能力,使其能够支持跨集群的分布式计算。以下是如何理解隐语的使用和分布式调度:
联邦学习任务:隐语支持跨多个集群的联邦学习任务。每个参与方可以在自己的集群中运行任务,RayFed 会负责调度这些任务并协调它们之间的通信。
安全计算任务:隐语支持安全多方计算(MPC)任务,这些任务需要在多个参与方之间进行数据交换和计算。RayFed 提供了安全的通信通道,确保数据在传输过程中不被泄露。
资源分配:隐语可以基于 Ray 的资源管理机制,为每个参与方分配合适的计算资源。用户可以指定每个参与方需要的资源,RayFed 会根据集群的资源情况进行调度。
负载均衡:RayFed 能够根据任务的负载情况动态调整资源分配,确保计算任务能够高效执行。
数据隔离与共享:在隐语中,不同参与方的数据是隔离的,但计算任务可以通过安全协议共享必要的数据。RayFed 利用 Ray 的对象存储和消息传递机制,确保数据在不同参与方之间安全传输和处理。
数据依赖管理:隐语可以管理计算任务之间的数据依赖,确保任务按照正确的顺序执行。RayFed 会根据任务的依赖关系自动安排执行计划。
3.3 仿真模式

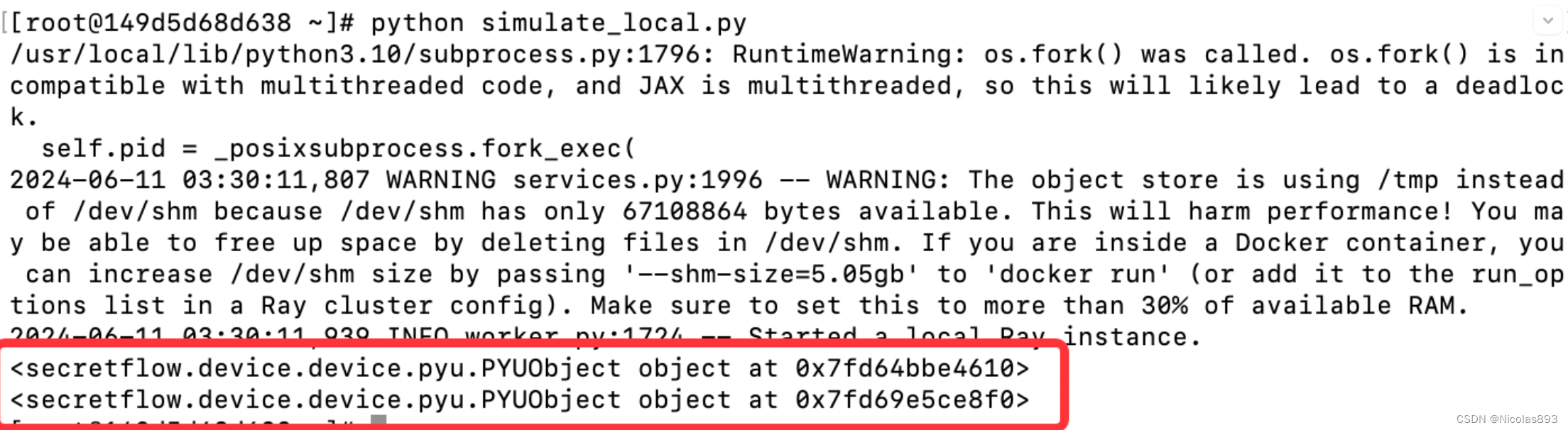
单机仿真就是在自己当前本地,启动一个ray节点,来执行相应的计算任务。这个例子是在本地节点启动两个角色,alice和bob。执行的是PYU,也就是python的明文计算单元。
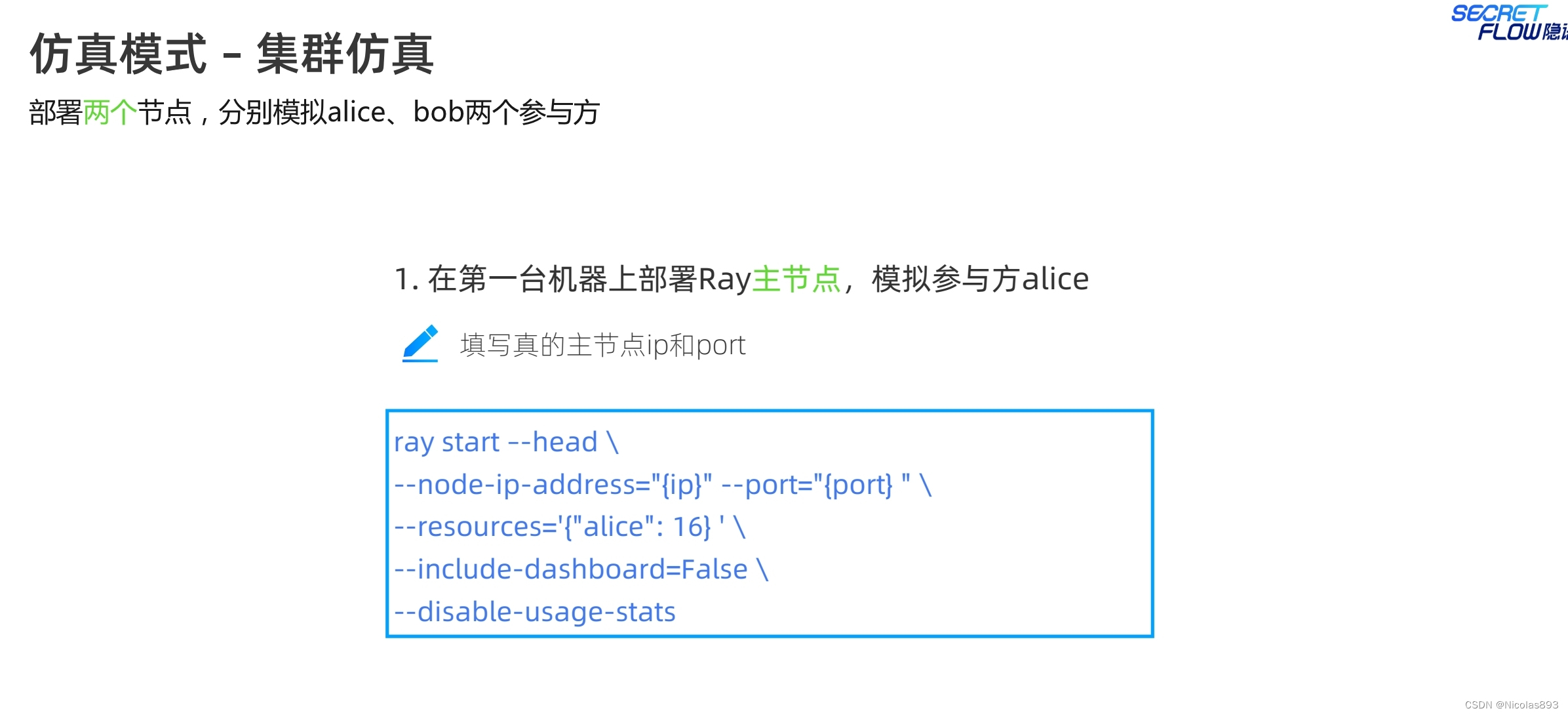


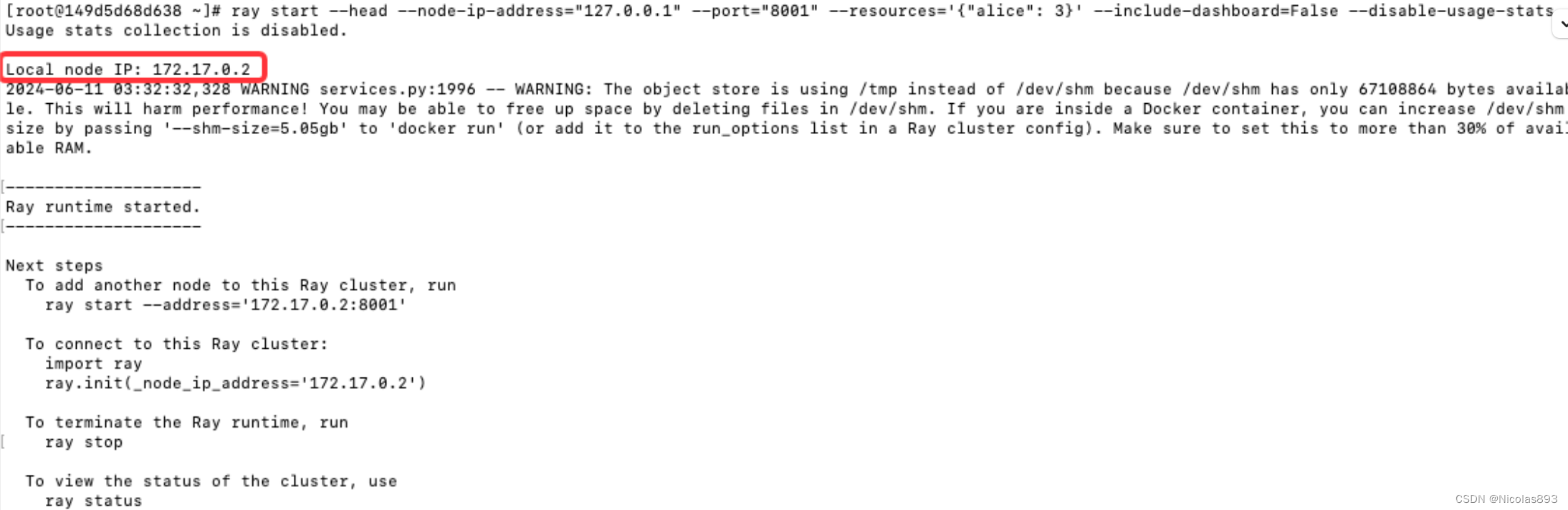
集群仿真,是指部署两个节点,两台机器上部署,应该也可以支持在一台机器上,通过不同端口模拟两台机器,在第一台机器上部署ray的主节点,也就是ray head,指定ip、port、资源等信息,另一台则部署从节点,注意从节点的address这里写的是主节点的通信地址。服务启动完成后,执行python代码,address改成对应主节点的ip和端口。

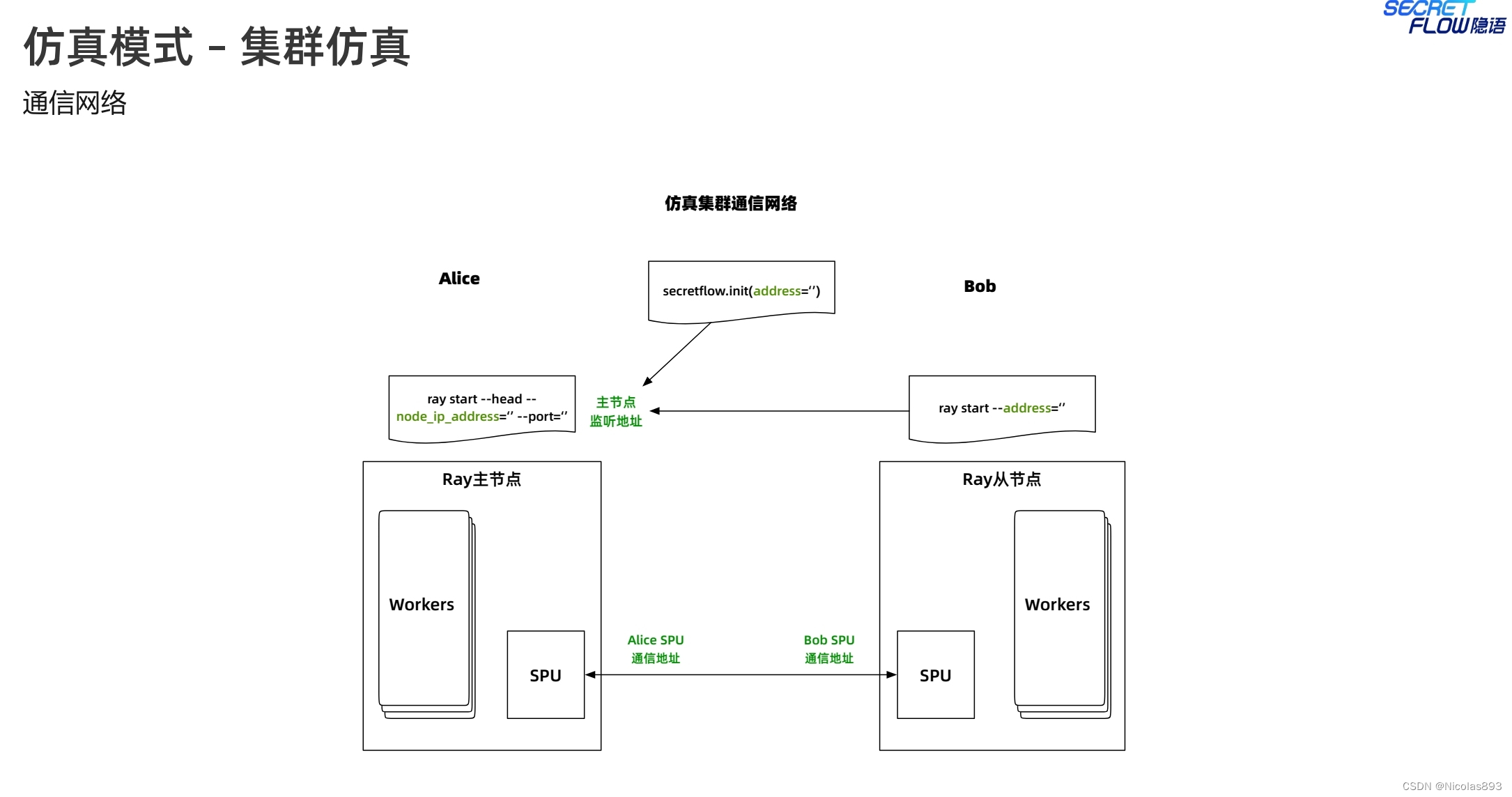
之前都是pyu的明文执行单元。现在创建spu的密态设备计算单元,在cluster集群配置信息,需要填写实际的alice和bob的通信地址,指定对应的mpc协议和整型碎片长度等一些必要的配置信息,这里选的是semi2k协议。然后初始化spu的集群信息。这种mpc启动模式在业内应该基本统一,没什么大的区别。从通信网络看,需要注意spu的端口,需要有别于ray的端口号。这里之所以采用不同的端口号,个人猜测是可能基于不同任务的功能分离或者安全性层面考虑,ray主要用于任务调度、资源管理和分布式计算。SPU 负责安全计算任务,如安全多方计算(MPC)等。SPU 的端口号用于安全计算任务的通信和数据交换。
3.4 生产模式
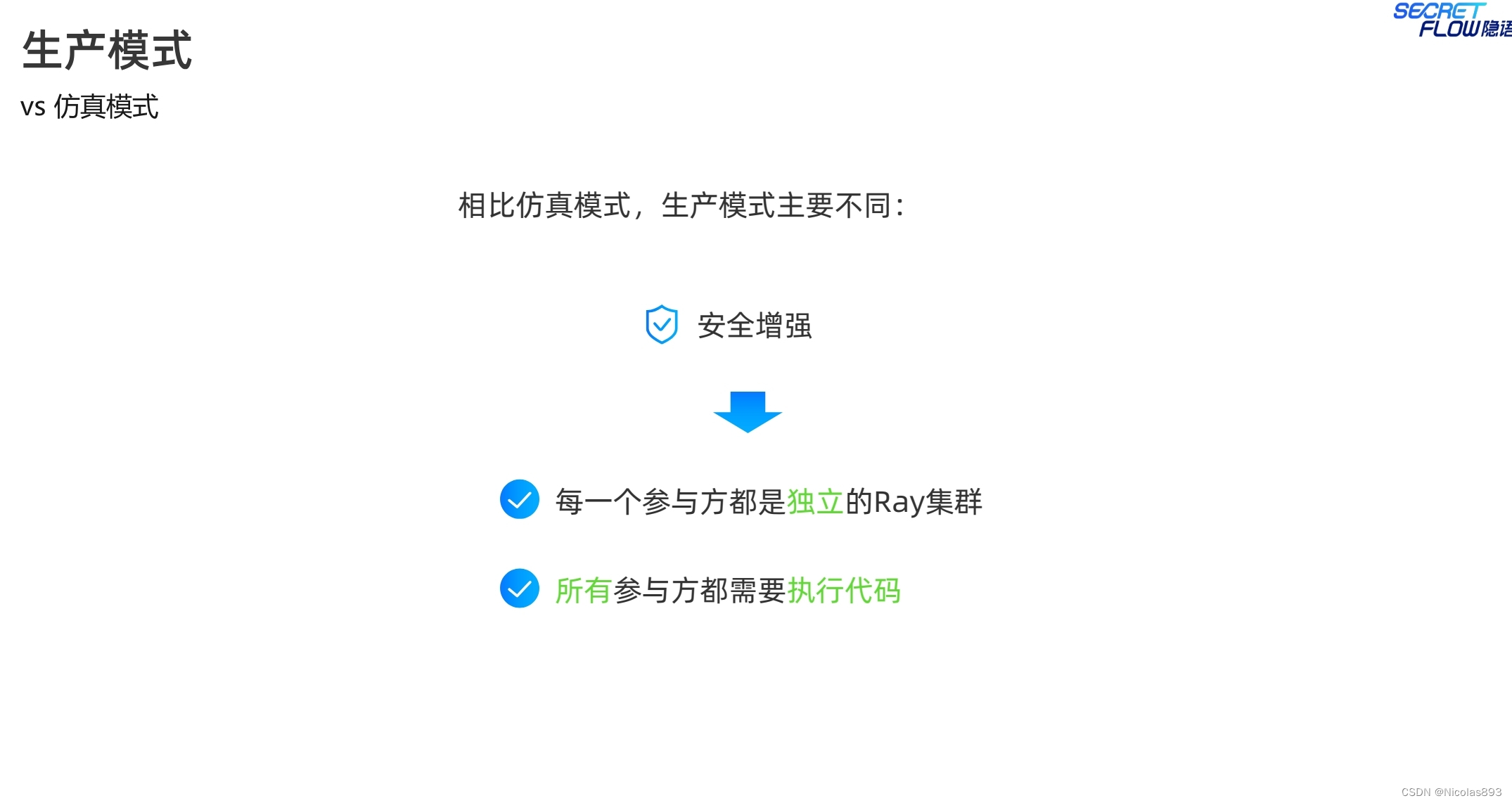
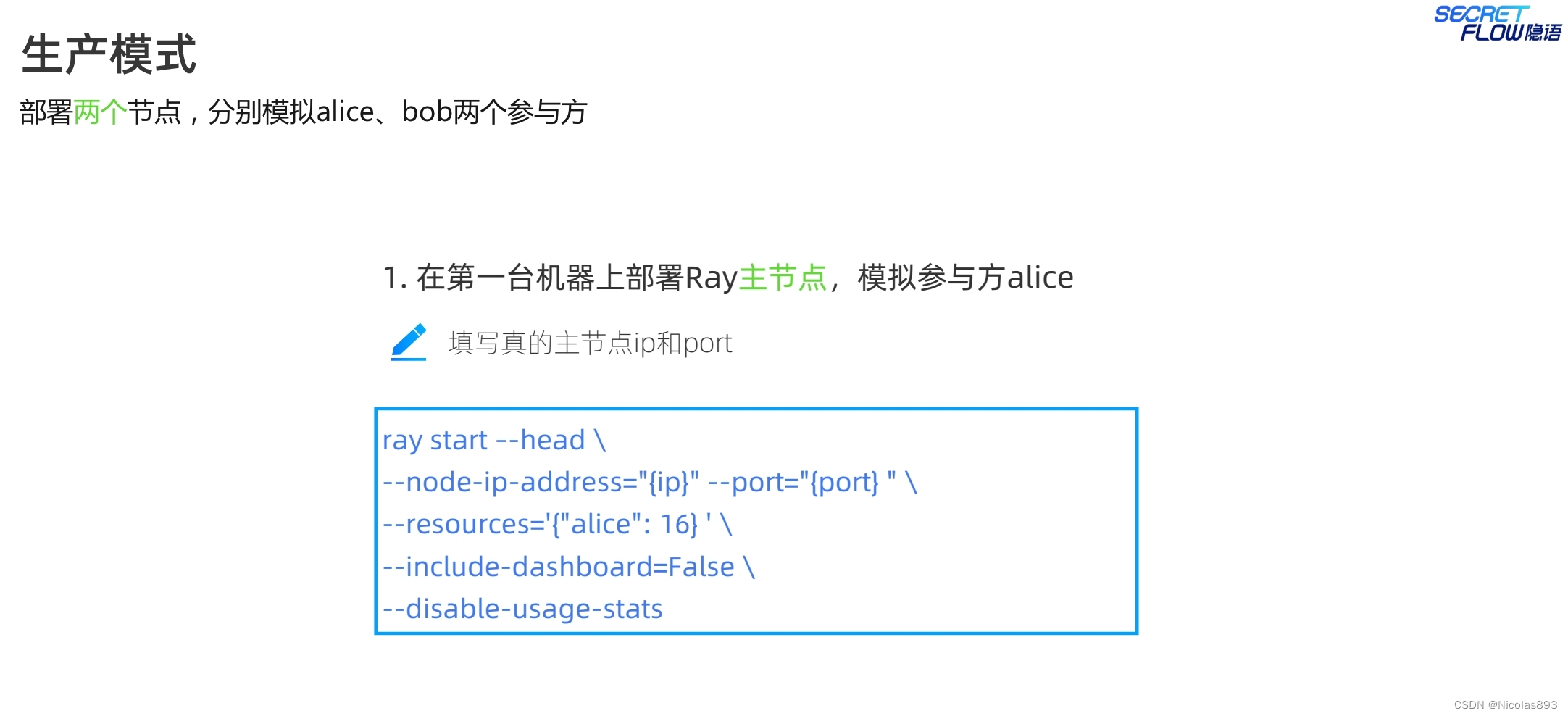
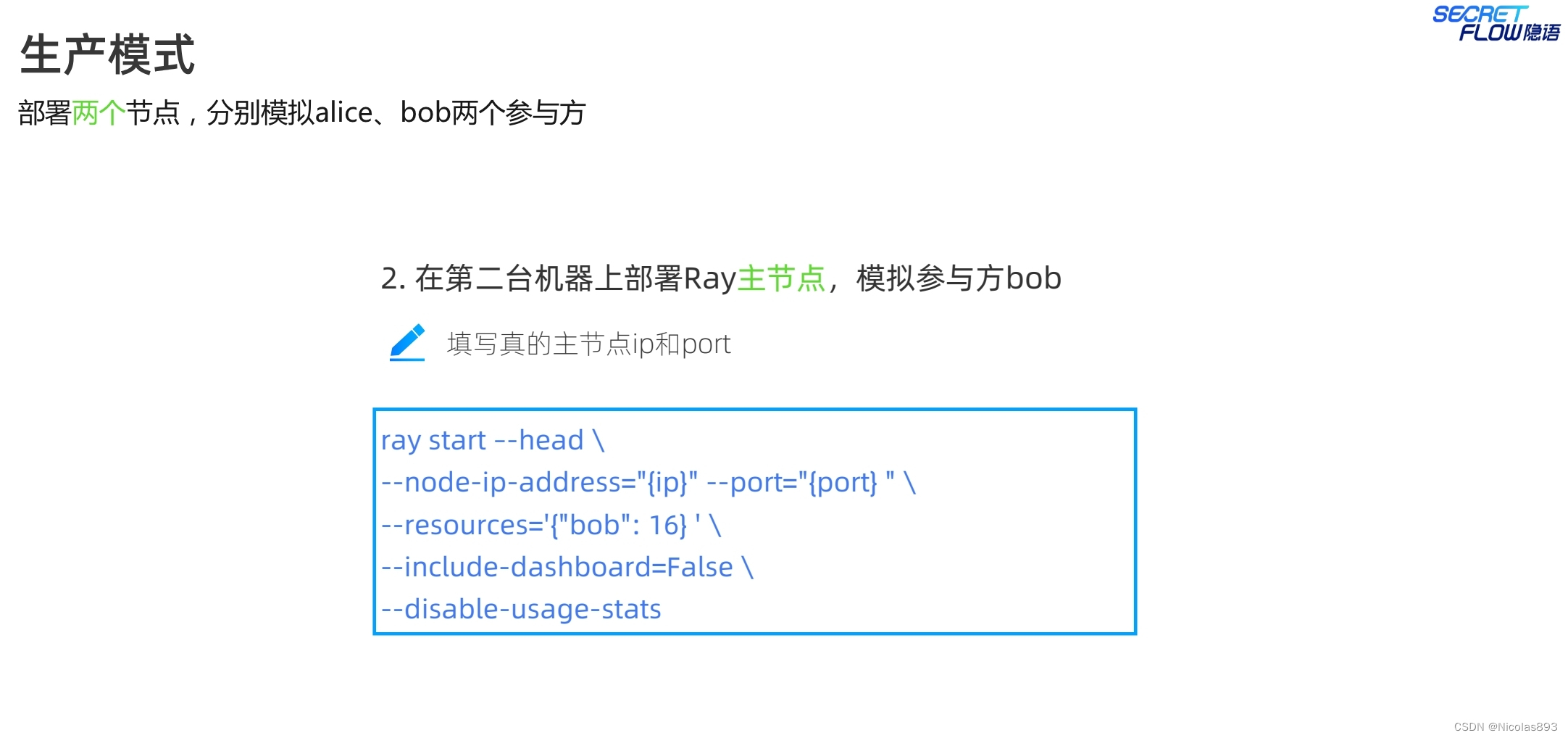
注意生产模式的启动指令与仿真模式的差别,生产模式下,各个节点都是一个完整的ray集群,因此启动指令中都是ray start --head。
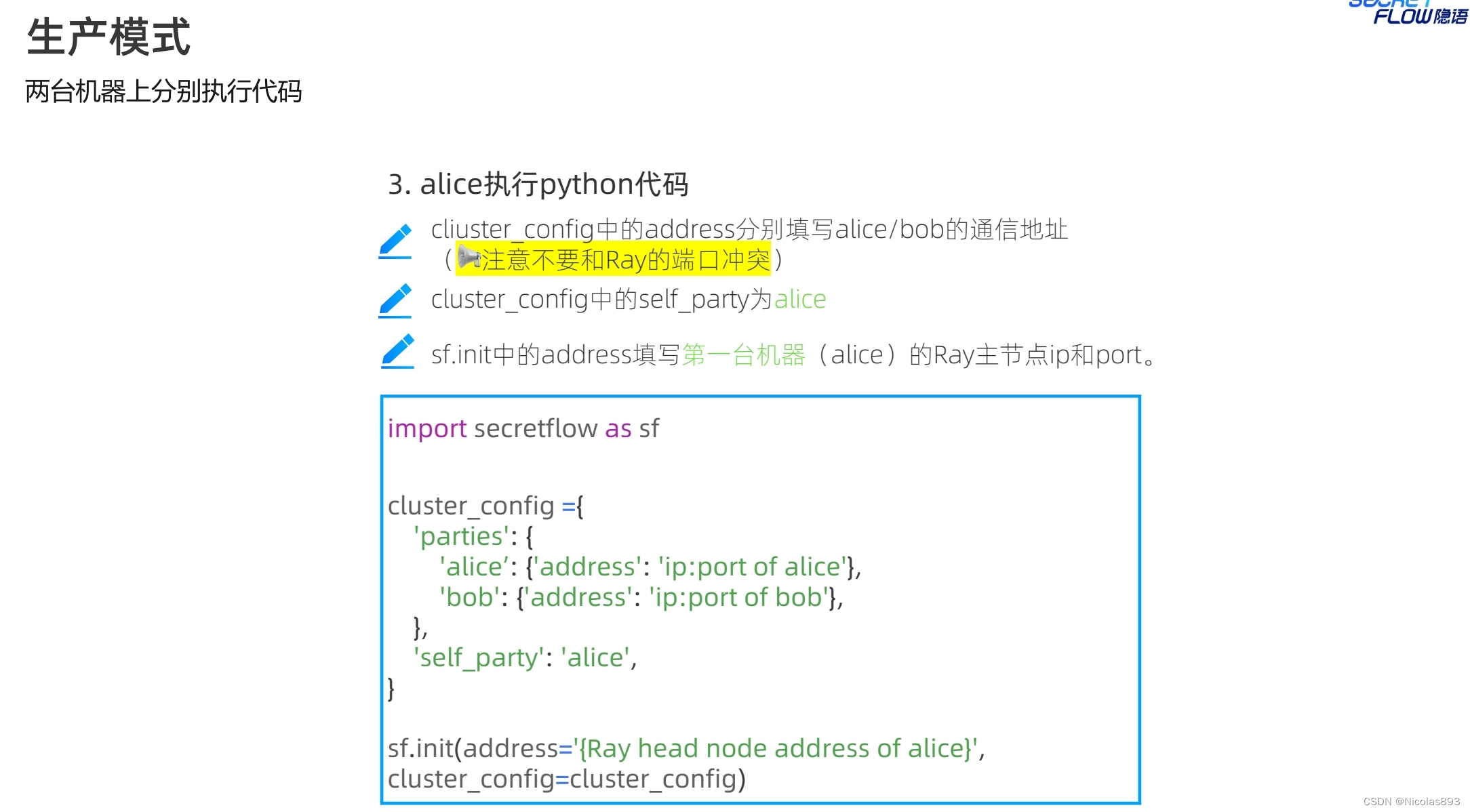
生产模式下,多了self_party的参数设置,用于区分节点角色。init的address是self_party的ray head节点地址。

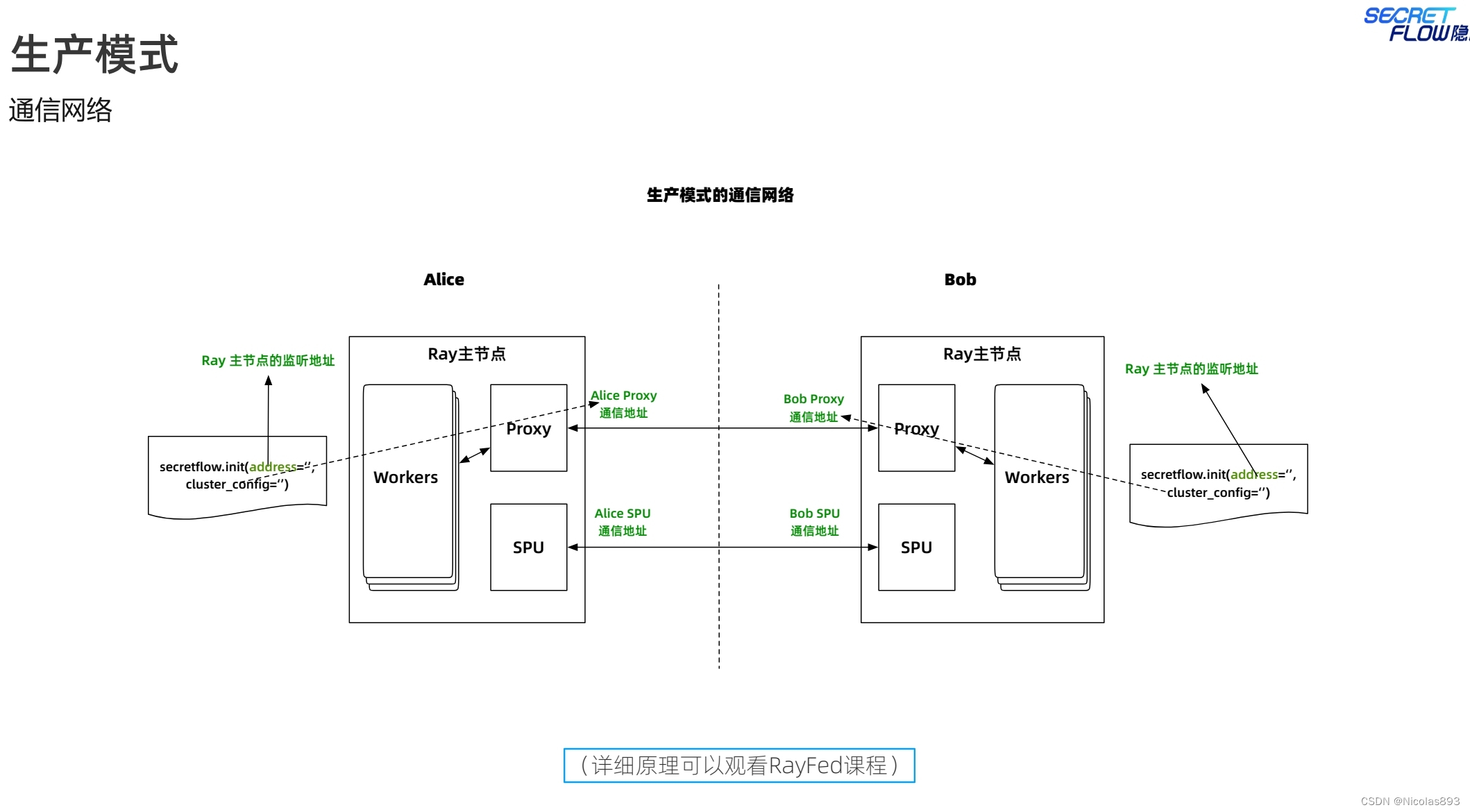
spu的设置与仿真模式差别不大,注意区分端口号不要冲突,否则会带来网络通信相关的报错。说实话,端口号的管理也是一个累人的活。不过隐语提供了kuscia来解决。从生产模式的通信网络看:
- Ray:负责分布式任务调度和资源管理,主要在集群内部节点之间进行通信。
- Proxy:充当通信代理,确保不同计算节点之间的安全、可靠通信。
- SPU:执行安全计算任务,确保涉及敏感信息的数据处理过程中的隐私和安全。
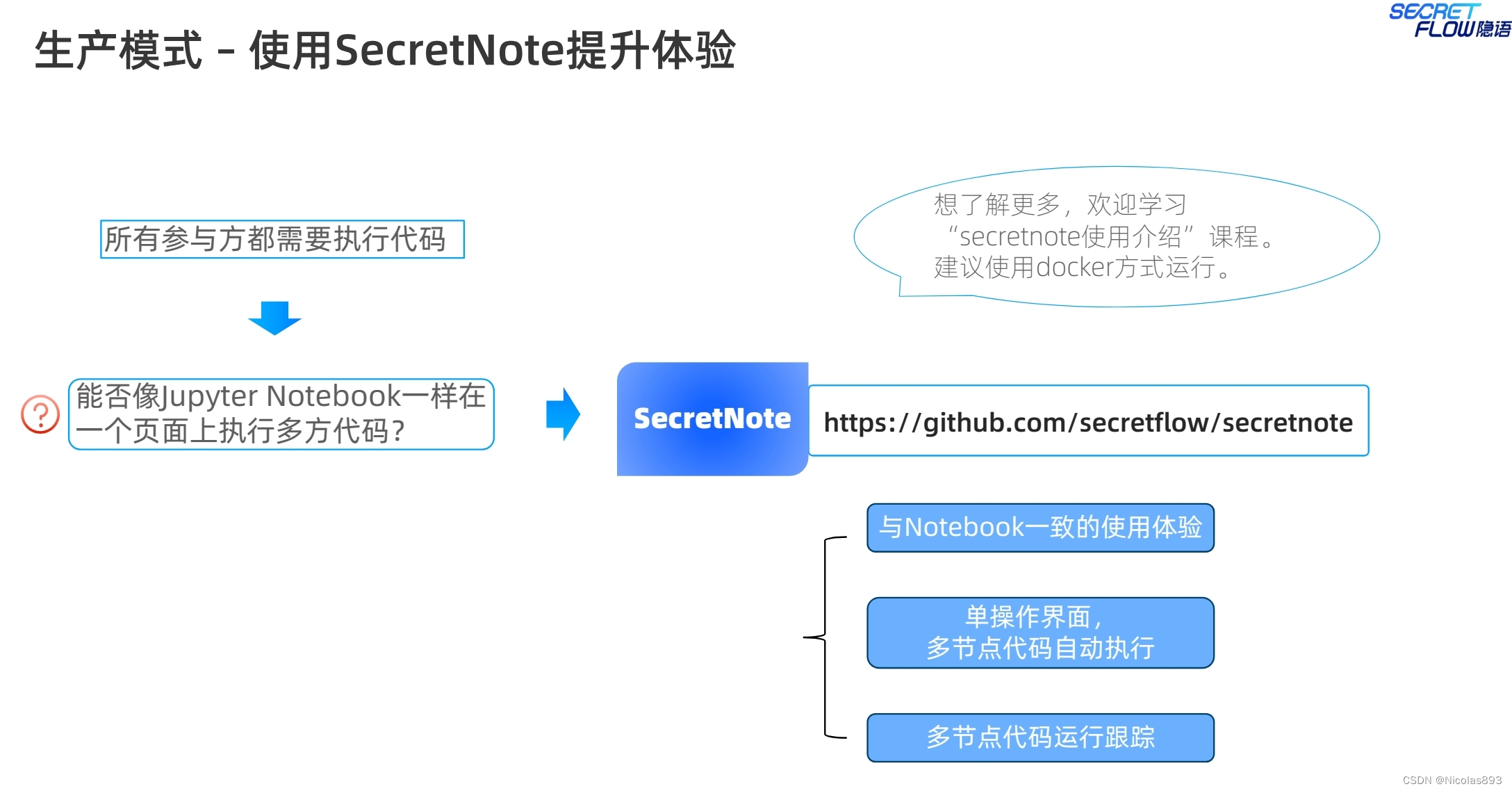
另外也介绍了一下secretnote的使用,类似于notebook的编程体验。这个业内也有一些厂商提供该功能,隐语做了更多的用户体验的适配。
分布式框架,业内普遍采用ray,可能也是一种共识。也许以后会有更优秀的框架取代ray,拭目以待。从隐语的设计来看,保持了对于使用其他可替代分布式框架的能力,架构还是蛮优秀的。

4. 实操体验
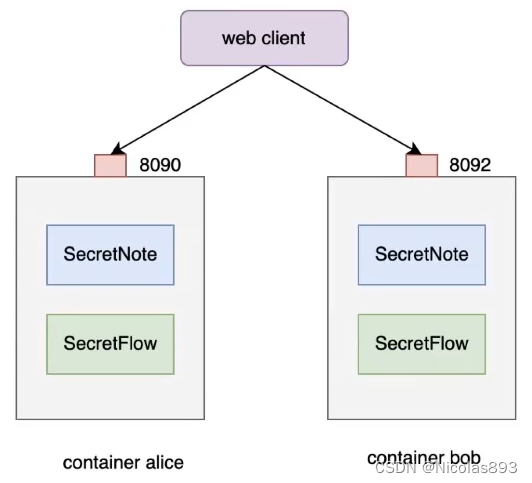
4.1 secretflow实操
采用docker镜像部署的模式,只需要拉取对应的docker镜像,运行即可。
![]()
![]()
为了模拟两个节点执行模式,需要启动两个镜像,如下所示:

单机模拟的场景,不需要执行ray启动命令,直接运行即可。
import secretflow as sf
sf.init(parties=['alice', 'bob'], address='local')
alice = sf.PYU('alice')
bob = sf.PYU('bob')
a = alice(lambda x : x + 1)(2)
print(a)
b = bob(lambda x : x + 1)(2)
print(b)执行日志如下:
集群模拟,则需要在两个镜像中分别启动ray,alice节点执行head的启动,记录一下当前的ip地址。bob节点启动从节点,需要填写head节点的ip和端口。当然也可以采用docker指令docker inspect -f '{{range.NetworkSettings.Networks}}{{.IPAddress}}{{end}}'来查看镜像ip。

启动完成后,就可以执行相应的脚本了。依然选择在alice节点执行脚本,填写的address为主节点地址。
import secretflow as sf
sf.init(parties=['alice', 'bob'], address='172.17.0.2:8001')
alice = sf.PYU('alice')
bob = sf.PYU('bob')
a = alice(lambda x : x + 1)(2)
print(a)
b = bob(lambda x : x + 1)(2)
print(b)
print(sf.reveal(b))执行日志如下:

spu的密态计算场景,也是类似,执行脚本如下:
import spu
import secretflow as sf
# Use ray head adress please.
sf.init(parties=['alice', 'bob'], address='172.17.0.2:8001')
cluster_def={
'nodes': [
{
'party': 'alice',
# Please choose an unused port.
'address': 'ip:port of alice',
'listen_addr': '172.17.0.2:9001'
},
{
'party': 'bob',
# Please choose an unused port.
'address': 'ip:port of bob',
'listen_addr': '172.17.0.3:9001'
},
],
'runtime_config': {
'protocol': spu.spu_pb2.SEMI2K,
'field': spu.spu_pb2.FM128,
'sigmoid_mode': spu.spu_pb2.RuntimeConfig.SIGMOID_REAL,
}
}
spu = sf.SPU(cluster_def=cluster_def)
print(spu)
需要注意,端口号与ray不同。
执行日志如下:

生产环境方法类似,只是每一个节点需要启动ray集群,需要注意带上head。
4.2 secretnote实操
我们采用的是将secretnote部署到服务器上,然后通过本地电脑的浏览器进行访问。
在服务器上使用 docker compose 启动两个容器,容器启动时会安装 SecretFLow、SecretNote,并且分别启动 Ray 服务以及 SecretNote 服务。
操作步骤如下:
mkdir snote
cd snote
vi docker-compose.ymldocker-compose.yml的内容
services:
alice:
image: 'docker.mirrors.sjtug.sjtu.edu.cn/secretflow/secretnote:1.5.0.dev'
platform: linux/amd64
environment:
- SELF_PARTY=alice
- ALL_PARTIES=alice,bob
ports:
- 8090:8888
entrypoint: /root/scripts/start.sh
volumes:
- /root/scripts
bob:
image: 'docker.mirrors.sjtug.sjtu.edu.cn/secretflow/secretnote:1.5.0.dev'
platform: linux/amd64
environment:
- SELF_PARTY=bob
- ALL_PARTIES=alice,bob
ports:
- 8092:8888
entrypoint: /root/scripts/start.sh
volumes:
- /root/scriptsdocker compose up启动后可以看到成功启动日志:
[+] Running 3/3
✔ Network snote_default Created 0.1s
✔ Container snote-alice-1 Created 0.5s
✔ Container snote-bob-1 Created 0.5s
Attaching to alice-1, bob-1
alice-1 | 2024-06-11 11:06:54,824 WARNING services.py:1832 -- WARNING: The object store is using /tmp instead of /dev/shm because /dev/shm has only 67108864 bytes available. This will harm performance! You may be able to free up space by deleting files in /dev/shm. If you are inside a Docker container, you can increase /dev/shm size by passing '--shm-size=5.09gb' to 'docker run' (or add it to the run_options list in a Ray cluster config). Make sure to set this to more than 30% of available RAM.
bob-1 | 2024-06-11 11:06:54,850 WARNING services.py:1832 -- WARNING: The object store is using /tmp instead of /dev/shm because /dev/shm has only 67108864 bytes available. This will harm performance! You may be able to free up space by deleting files in /dev/shm. If you are inside a Docker container, you can increase /dev/shm size by passing '--shm-size=5.09gb' to 'docker run' (or add it to the run_options list in a Ray cluster config). Make sure to set this to more than 30% of available RAM.
alice-1 | 2024-06-11 11:06:52,011 INFO usage_lib.py:381 -- Usage stats collection is disabled.
alice-1 | 2024-06-11 11:06:52,012 INFO scripts.py:722 -- Local node IP: 172.20.0.3
alice-1 | 2024-06-11 11:06:55,953 SUCC scripts.py:759 -- --------------------
alice-1 | 2024-06-11 11:06:55,954 SUCC scripts.py:760 -- Ray runtime started.
alice-1 | 2024-06-11 11:06:55,954 SUCC scripts.py:761 -- --------------------
alice-1 | 2024-06-11 11:06:55,954 INFO scripts.py:763 -- Next steps
alice-1 | 2024-06-11 11:06:55,954 INFO scripts.py:766 -- To add another node to this Ray cluster, run
alice-1 | 2024-06-11 11:06:55,954 INFO scripts.py:769 -- ray start --address='172.20.0.3:6379'
alice-1 | 2024-06-11 11:06:55,954 INFO scripts.py:778 -- To connect to this Ray cluster:
alice-1 | 2024-06-11 11:06:55,954 INFO scripts.py:780 -- import ray
alice-1 | 2024-06-11 11:06:55,954 INFO scripts.py:781 -- ray.init()
alice-1 | 2024-06-11 11:06:55,954 INFO scripts.py:812 -- To terminate the Ray runtime, run
alice-1 | 2024-06-11 11:06:55,954 INFO scripts.py:813 -- ray stop
alice-1 | 2024-06-11 11:06:55,954 INFO scripts.py:816 -- To view the status of the cluster, use
alice-1 | 2024-06-11 11:06:55,954 INFO scripts.py:817 -- ray status
bob-1 | 2024-06-11 11:06:52,051 INFO usage_lib.py:381 -- Usage stats collection is disabled.
bob-1 | 2024-06-11 11:06:52,052 INFO scripts.py:722 -- Local node IP: 172.20.0.2
bob-1 | 2024-06-11 11:06:55,991 SUCC scripts.py:759 -- --------------------
bob-1 | 2024-06-11 11:06:55,991 SUCC scripts.py:760 -- Ray runtime started.
bob-1 | 2024-06-11 11:06:55,991 SUCC scripts.py:761 -- --------------------
bob-1 | 2024-06-11 11:06:55,991 INFO scripts.py:763 -- Next steps
bob-1 | 2024-06-11 11:06:55,991 INFO scripts.py:766 -- To add another node to this Ray cluster, run
bob-1 | 2024-06-11 11:06:55,991 INFO scripts.py:769 -- ray start --address='172.20.0.2:6379'
bob-1 | 2024-06-11 11:06:55,991 INFO scripts.py:778 -- To connect to this Ray cluster:
bob-1 | 2024-06-11 11:06:55,991 INFO scripts.py:780 -- import ray
bob-1 | 2024-06-11 11:06:55,991 INFO scripts.py:781 -- ray.init()
bob-1 | 2024-06-11 11:06:55,991 INFO scripts.py:812 -- To terminate the Ray runtime, run
bob-1 | 2024-06-11 11:06:55,991 INFO scripts.py:813 -- ray stop
bob-1 | 2024-06-11 11:06:55,992 INFO scripts.py:816 -- To view the status of the cluster, use
bob-1 | 2024-06-11 11:06:55,992 INFO scripts.py:817 -- ray status
alice-1 | [W 2024-06-11 11:06:57.602 ServerApp] ServerApp.token config is deprecated in 2.0. Use IdentityProvider.token.
bob-1 | [W 2024-06-11 11:06:57.622 ServerApp] ServerApp.token config is deprecated in 2.0. Use IdentityProvider.token.
alice-1 | [I 2024-06-11 11:06:57.666 ServerApp] jupyter_lsp | extension was successfully linked.
alice-1 | [I 2024-06-11 11:06:57.666 ServerApp] jupyter_resource_usage | extension was successfully linked.
alice-1 | [I 2024-06-11 11:06:57.666 ServerApp] jupyter_server_proxy | extension was successfully linked.
alice-1 | [I 2024-06-11 11:06:57.675 ServerApp] jupyter_server_terminals | extension was successfully linked.
bob-1 | [I 2024-06-11 11:06:57.680 ServerApp] jupyter_lsp | extension was successfully linked.
bob-1 | [I 2024-06-11 11:06:57.681 ServerApp] jupyter_resource_usage | extension was successfully linked.
bob-1 | [I 2024-06-11 11:06:57.681 ServerApp] jupyter_server_proxy | extension was successfully linked.
alice-1 | [I 2024-06-11 11:06:57.682 ServerApp] secretnote.server | extension was successfully linked.
bob-1 | [I 2024-06-11 11:06:57.689 ServerApp] jupyter_server_terminals | extension was successfully linked.
alice-1 | [I 2024-06-11 11:06:57.695 ServerApp] Writing Jupyter server cookie secret to /root/.local/share/jupyter/runtime/jupyter_cookie_secret
bob-1 | [I 2024-06-11 11:06:57.696 ServerApp] secretnote.server | extension was successfully linked.
bob-1 | [I 2024-06-11 11:06:57.707 ServerApp] Writing Jupyter server cookie secret to /root/.local/share/jupyter/runtime/jupyter_cookie_secret
alice-1 | [W 2024-06-11 11:06:57.710 ServerApp] WARNING: The Jupyter server is listening on all IP addresses and not using encryption. This is not recommended.
alice-1 | [W 2024-06-11 11:06:57.710 ServerApp] WARNING: The Jupyter server is listening on all IP addresses and not using authentication. This is highly insecure and not recommended.
alice-1 | [I 2024-06-11 11:06:57.716 ServerApp] jupyter_lsp | extension was successfully loaded.
alice-1 | [I 2024-06-11 11:06:57.717 ServerApp] jupyter_resource_usage | extension was successfully loaded.
bob-1 | [W 2024-06-11 11:06:57.722 ServerApp] WARNING: The Jupyter server is listening on all IP addresses and not using encryption. This is not recommended.
bob-1 | [W 2024-06-11 11:06:57.722 ServerApp] WARNING: The Jupyter server is listening on all IP addresses and not using authentication. This is highly insecure and not recommended.
bob-1 | [I 2024-06-11 11:06:57.728 ServerApp] jupyter_lsp | extension was successfully loaded.
bob-1 | [I 2024-06-11 11:06:57.730 ServerApp] jupyter_resource_usage | extension was successfully loaded.
alice-1 | [I 2024-06-11 11:06:57.737 ServerApp] jupyter_server_proxy | extension was successfully loaded.
alice-1 | [I 2024-06-11 11:06:57.739 ServerApp] jupyter_server_terminals | extension was successfully loaded.
alice-1 | [I 2024-06-11 11:06:57.744 ServerApp] secretnote.server | extension was successfully loaded.
alice-1 | [I 2024-06-11 11:06:57.746 ServerApp] Serving notebooks from local directory: /root/workspace
alice-1 | [I 2024-06-11 11:06:57.746 ServerApp] Jupyter Server 2.13.0 is running at:
alice-1 | [I 2024-06-11 11:06:57.746 ServerApp] http://localhost:8888/secretnote/
alice-1 | [I 2024-06-11 11:06:57.746 ServerApp] http://127.0.0.1:8888/secretnote/
alice-1 | [I 2024-06-11 11:06:57.746 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
bob-1 | [I 2024-06-11 11:06:57.750 ServerApp] jupyter_server_proxy | extension was successfully loaded.
bob-1 | [I 2024-06-11 11:06:57.752 ServerApp] jupyter_server_terminals | extension was successfully loaded.
bob-1 | [I 2024-06-11 11:06:57.757 ServerApp] secretnote.server | extension was successfully loaded.
bob-1 | [I 2024-06-11 11:06:57.758 ServerApp] Serving notebooks from local directory: /root/workspace
bob-1 | [I 2024-06-11 11:06:57.759 ServerApp] Jupyter Server 2.13.0 is running at:
bob-1 | [I 2024-06-11 11:06:57.759 ServerApp] http://localhost:8888/secretnote/
bob-1 | [I 2024-06-11 11:06:57.759 ServerApp] http://127.0.0.1:8888/secretnote/
bob-1 | [I 2024-06-11 11:06:57.759 ServerApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).

然后在本地电脑浏览器打开,打开地址需要注意一下,使用服务器的ip地址
http://服务器ip:8092/secretnote/secretflow
配置节点的时候注意使用服务器ip

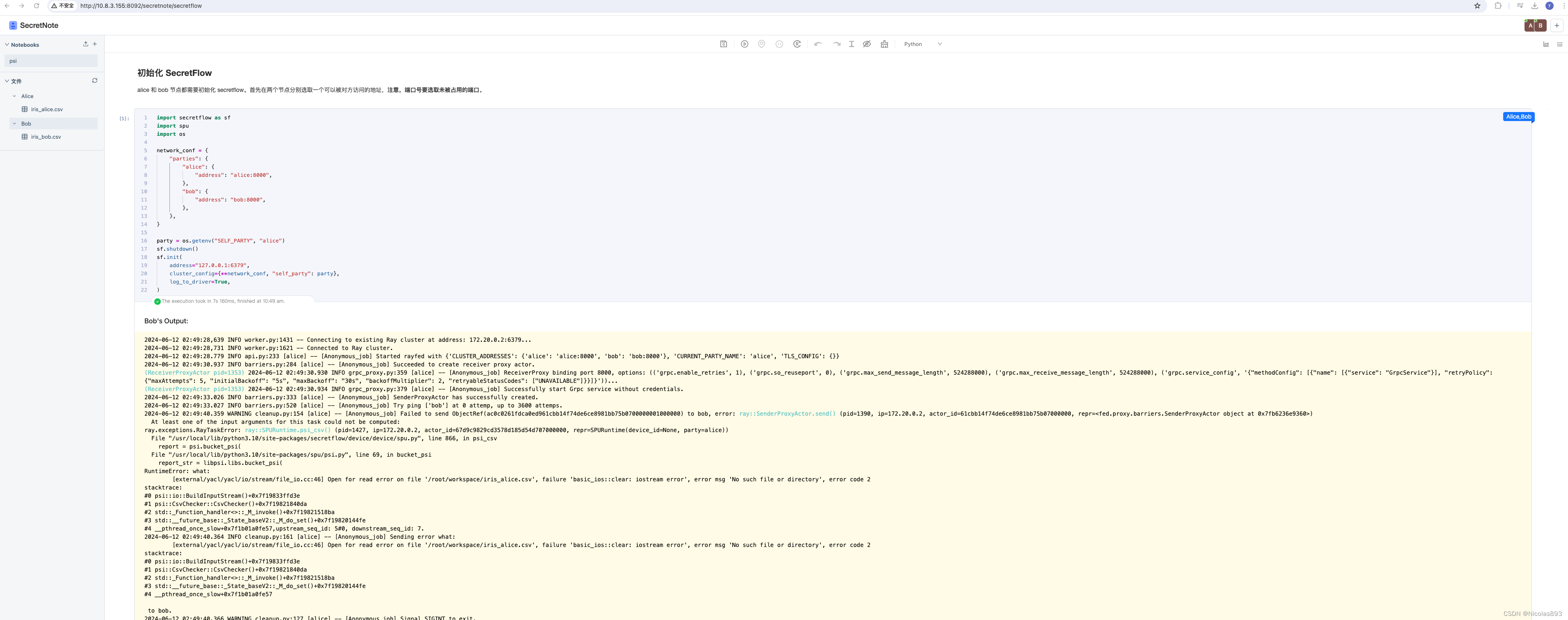
使用的数据和脚本来自:secretnote/docs/guide/secretnote-sf.md at main · secretflow/secretnote · GitHub
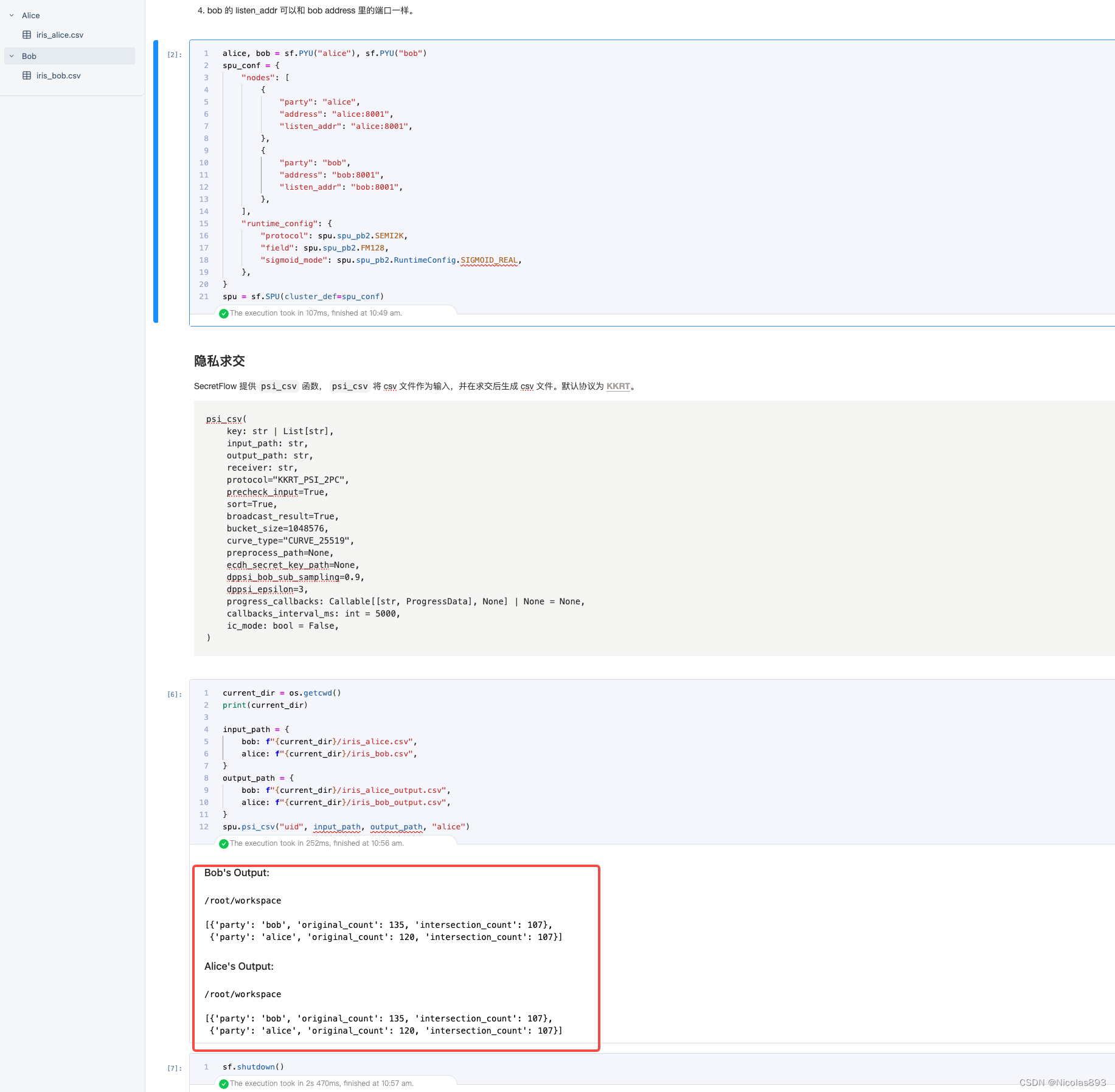
其他代码不用动,直接执行全部,注意节点与数据文件对应关系,因为不对应会导致报错文件找不到的问题。对调一下节点名称就可以解决。















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









