







本周开启隐语课程的第七节,关于纵向多方协同的集成树模型XGB算法的学习,隐语提供了基于两种不同加密协议实现的算法,一种是基于MPC协议实现SS-XGB, 一种是基于半同态加密算法实现的SecureBoost。本笔记分为两个部分来阐述,第一部分为理论篇,第二部分为实战篇。
一、隐语理论篇学习
XGBoost是日常建模工作中特别常见的一类树模型算法,属于梯度提升树(Gradient Boosting Tree)的一种实现。它通过集成多个弱学习器(通常是决策树)来构建一个强大的预测模型。该算法具有一些突出的优点,包括:(1)高性能:具有较快的训练速度和较低的内存消耗。可以使用并行计算和近似算法等技术,提高模型的训练效率。(2)准确性:通过梯度提升的方式,它能够逐步改善模型的预测能力,获得较高的准确性。(3)鲁棒性:使用了正则化技术来控制模型的复杂度,从而减少过拟合的风险。(4)灵活性:适用于回归问题和分类问题。(4)可解释性:能够计算每个特征对模型预测的重要性。通过分析特征重要性,可以了解哪些特征对于模型的决策起到关键作用。通过分析SHAP值,可以了解每个特征如何影响模型的预测结果,进而得出对模型预测的解释。
在介绍具体的SS-XGB和SGB之前,先回顾一下明文XGBoost的算法逻辑,可以帮助理解后续对于SS-XGB和SGB的算法原理。
以下是XGBoost算法的主要原理:
1. 梯度提升框架
XGBoost基于梯度提升框架,该框架通过逐步构建一系列决策树来提高模型性能。每一
棵新树都是在前面所有树的基础上,针对当前模型的残差(即预测误差)进行训练的。
2. 目标函数
XGBoost优化的是一个目标函数,包含两个部分:
损失函数:度量模型预测值与真实值之间的差异。
正则化项:控制模型复杂度,防止过拟合。目标函数的形式如下:
其中,L是损失函数,
是前 t−1棵树的预测值,ft是第t棵树,Ω是正则化项。
3. 二阶泰勒展开
为了方便优化目标函数,XGBoost使用了二阶泰勒展开,将目标函数近似为一个二次函
数。这使得优化过程更高效:
其中,gi和 hi分别是损失函数的一阶和二阶导数(梯度和Hessian矩阵)。
4. 树的结构
XGBoost通过贪心算法来构建决策树。它在每一步都选择能够最大化增益的分裂点。增
益的计算方式考虑了损失函数的梯度和Hessian,以及正则化项:
其中, GL和 HL是左子节点的梯度和Hessian,GR 和 HR是右子节点的梯度和
Hessian,λ 和 γ是正则化参数。
5. 学习率和采样
学习率:在每次迭代后对树的输出乘以一个小于1的因子,以降低每棵树的影响,从而提高模型的鲁棒性。
子样本采样:在每次迭代时,随机选择部分样本来构建树,类似于随机森林中的样本采样,能减少过拟合。
6. 特征列抽样
除了对样本进行采样外,XGBoost还对特征进行采样。每次分裂时随机选择部分特征进
行分裂,这进一步减少了过拟合并提高了计算效率。
7. 并行化
XGBoost通过并行化提高了计算效率。在构建树的过程中,可以并行计算每个分裂点的增益,并选择最佳分裂点。
8. 缺失值处理
XGBoost能够自动处理数据中的缺失值。对于每个分裂点,XGBoost会分别计算缺失值分配到左子节点和右子节点的增益,并选择最优分配方式。

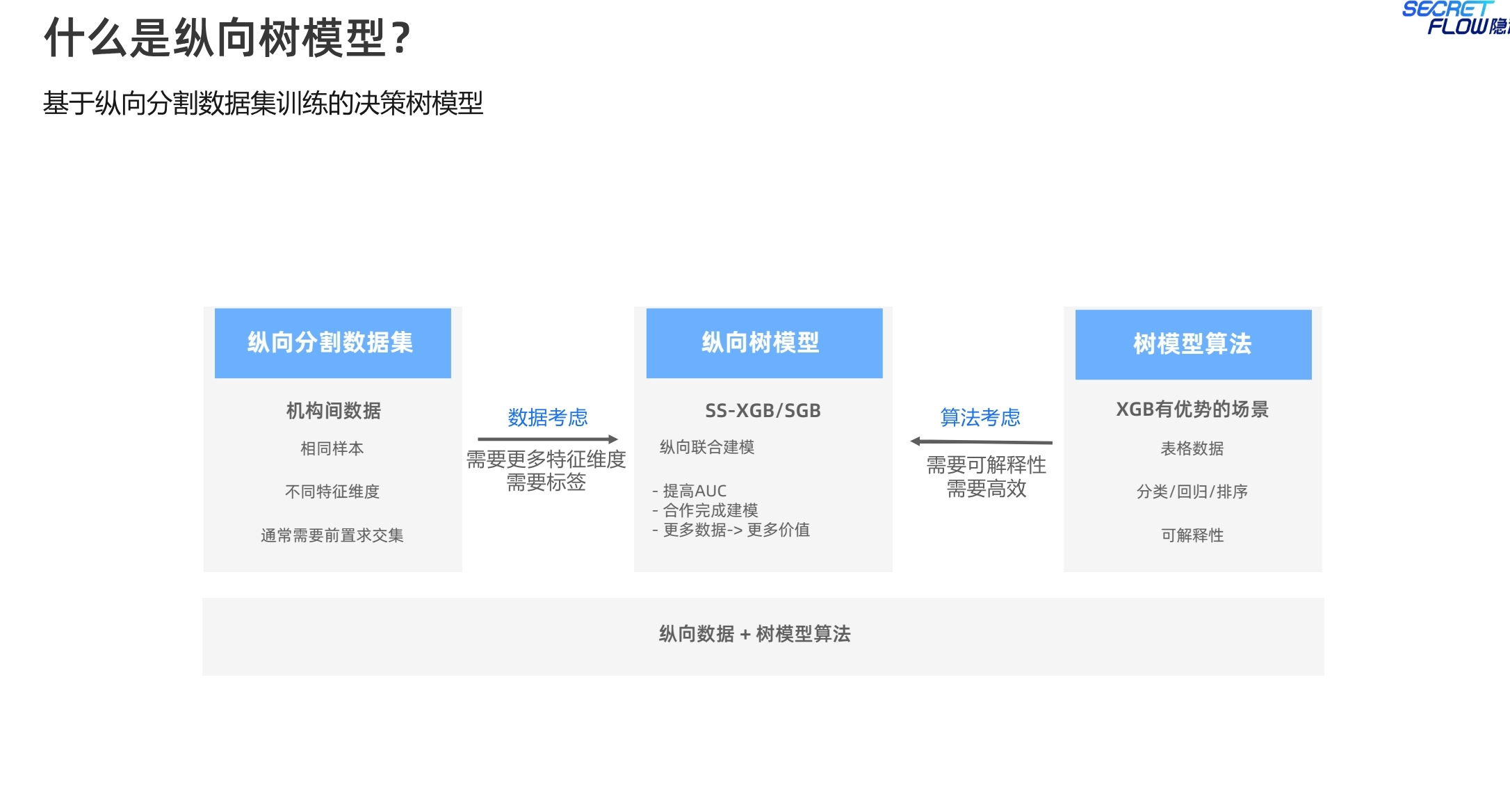
SS-XGB实现了XGB的经典功能,面向纵向数据切分场景,采用MPC协议进行密态计算,无信息泄露,可证安全。由于依赖于MPC,因此适用于网络条件相对较好的场景。
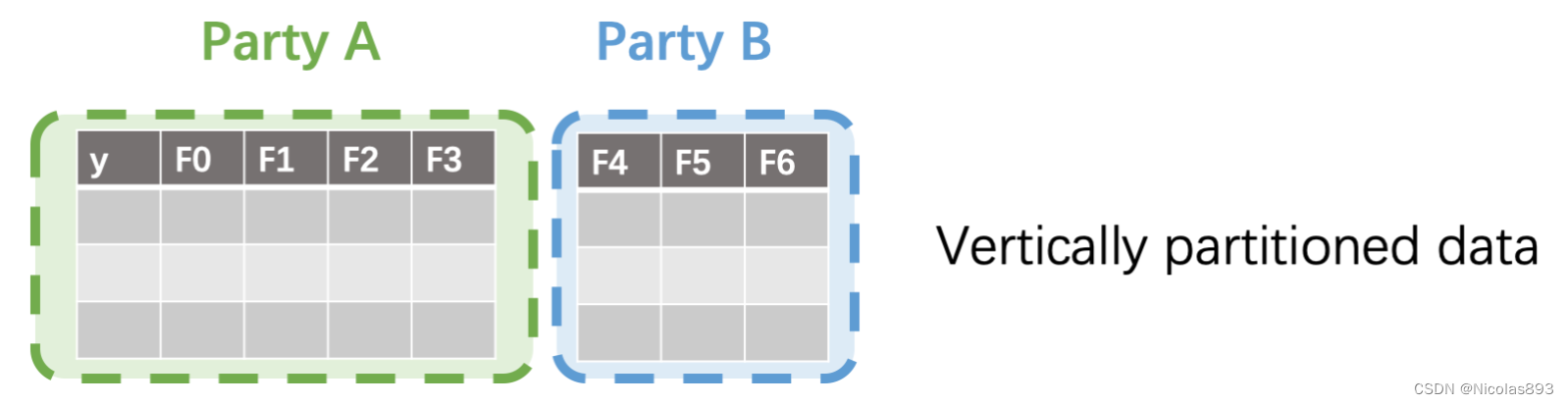
SS-XGB使用秘密分享计算分裂增益值和叶权重。使用秘密分享协议提供的加/乘等操作来实现安全的多方联合计算。特别需要关注的问题是:在计算分桶加和时,不泄漏任何样本分布相关的信息。可以看到,SS方式实现的XGB,一阶、二阶梯度信息以及数据分布信息都实现了安全保护。向量𝑆中标记为1的样本是被选中的样本需要加和,0相反。为了保证样本分布不泄漏,这个向量也是通过秘密分享协议保护的。在秘密分享协议的保护下,计算向量𝑆和梯度向量的内积,即可得到梯度在分桶内的累加和。参考:Large-Scale Secure XGB for Vertical Federated Learning。
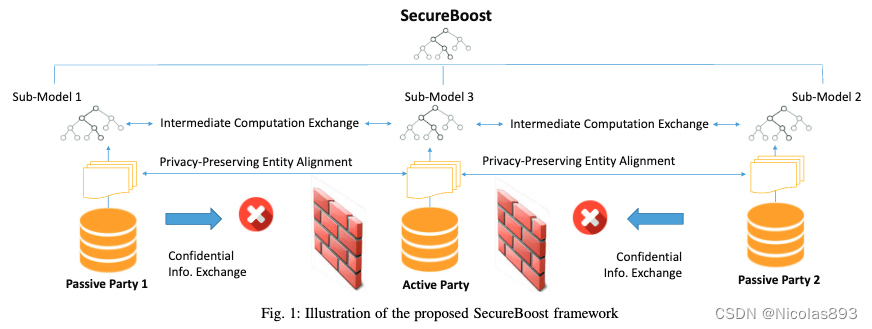
而SecureBoost(SGB)是来自微众团队研发的算法,吸收了XGB和Lightgbm的一些优势。采用同态加密算法来保护标签数据。在网络条件受限的情况下,具备一定的优势,对算力资源有一定的要求。在隐语中,使用HEU设备进行密态计算支持,另外支持了一些高级训练功能,包括lightGBM风格(叶子优先和GOSS)训练,仅使用标签持有者的数据训练第一棵树等。参考:SecureBoost: A Lossless Federated Learning Framework。
另外,针对secureboost,需要提一下其后续的迭代版本secureboost+,引入了更多的性能提升项,值得参考SecureBoost+ : A High Performance Gradient Boosting Tree Framework forLarge Scale Vertical Federated Learning
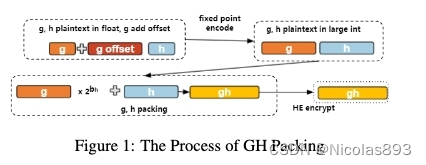
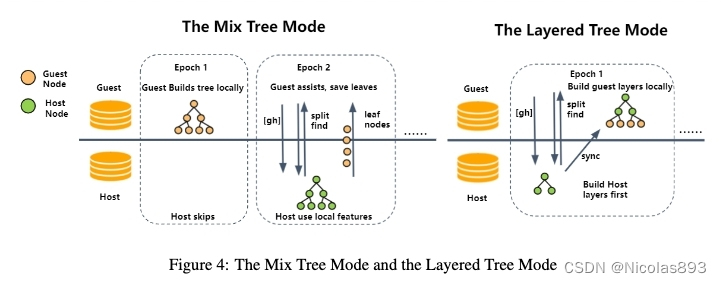
在这篇文章中,引入了梯度打包机制、混合树构建等新的训练优化机制,大幅提升了计算性能。
对于SS-XGB和SGB等多方协同树模型的使用,与明文模型的使用,基本是一致的,包括数据的准备、训练参数设置及执行,以及对训练完成的模型进行指标评估和预测使用。

SS-XGB,需要准备SPU设备,这个例子中设置的是三个参与方。参数设置与明文模型基本一致。模型评估需要先将预测结果进行reveal成明文后再进行计算。

SGB则是在两方下执行,包括公私钥生成对象sk_keeper,以及使用公钥计算方evaluators。

两种实现在设备初始化存在差异,需要注意。SS-XGB基于SPU设备,采用MPC协议。SGB基于HEU设备,隐语提供了OU、Paillier等实现,由标签持有方决定密钥持有方。

SS-XGB与SGB目前在参数设置上存在一定的差异,SGB由于吸收了XGB和lightGBM的更多功能点,引入了更多的训练参数设置。

SS-XGB预测结果为MPC碎片形态,以各方持有分片的形式保存模型,因此单独的任意一方都无法知晓模型的任何信息。而SGB是标签持有方以明文形式获得预测结果,各方持有部分明文模型参数(分裂点、分裂阈值信息),叶子权重一般是存在标签方。

另外,隐语也给出了将经典明文算法改造成MPC算法的要点。主要是各方对自身特征进行处理分桶记录分桶结果信息,然后采用MPC计算分桶对应的一阶梯度和以及二阶梯度和。最佳分裂点的计算也采用MPC进行。特征持有方获得真实分裂点。各方计算单方已知信息到MPC整合。叶子节点权重计算也采用MPC除法算子等。预测结果也是各方先计算一个中间结果,再进行MPC整合。实现全流程的安全保护。

对于明文模型到联邦模型SGB的改造,涉及同态加密。以标签方为保护中心,在标签方计算一阶梯度、二阶梯度,参与方持有特征的分桶求和在参与方以同态密文计算,分裂点计算在标签方计算。节点的样本分布、预测结果整合都在标签方进行。从实现上来看,标签方的权力和信息会更多,因此相对于SS-XGB来说,安全性较弱一些。高密场景建议使用SS-XGB。

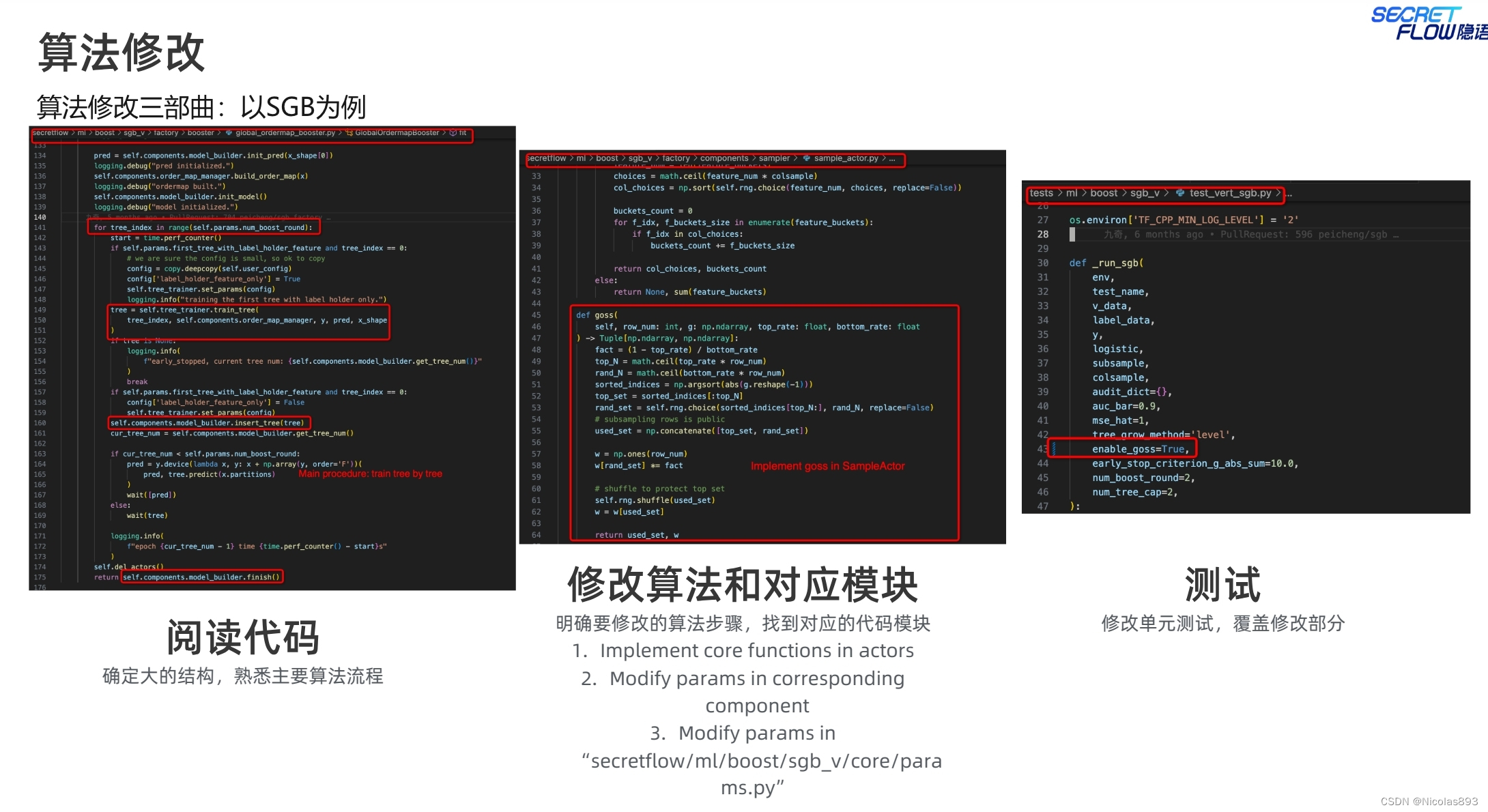
针对SS-XGB和SGB组件的封装和调用,也给出了一些示例,整理复杂度还好,找到对应模块,修改对应模块的代码功能,再进行单元测试覆盖。


得益于隐语对设备抽象(包括PYU\SPU\HEU),采用分层架构,对密码原语进行针对性算子优化,将明文模型改造成联邦或者基于mpc协议的密文模型,整体实现起来对于开发者还是比较友好的。
二、隐语SGB以及SS-XGB实战篇
执行代码如下:
1. 首先初始化集群
import secretflow as sf
import spu
import os
network_conf = { # 定义网络配置字典,包含参与方的地址信息
"parties": {
"alice": {
"address": "alice:8000", # Alice的地址
},
"bob": {
"address": "bob:8000", # Bob的地址
},
},
}
party = os.getenv("SELF_PARTY", "alice")
sf.shutdown()
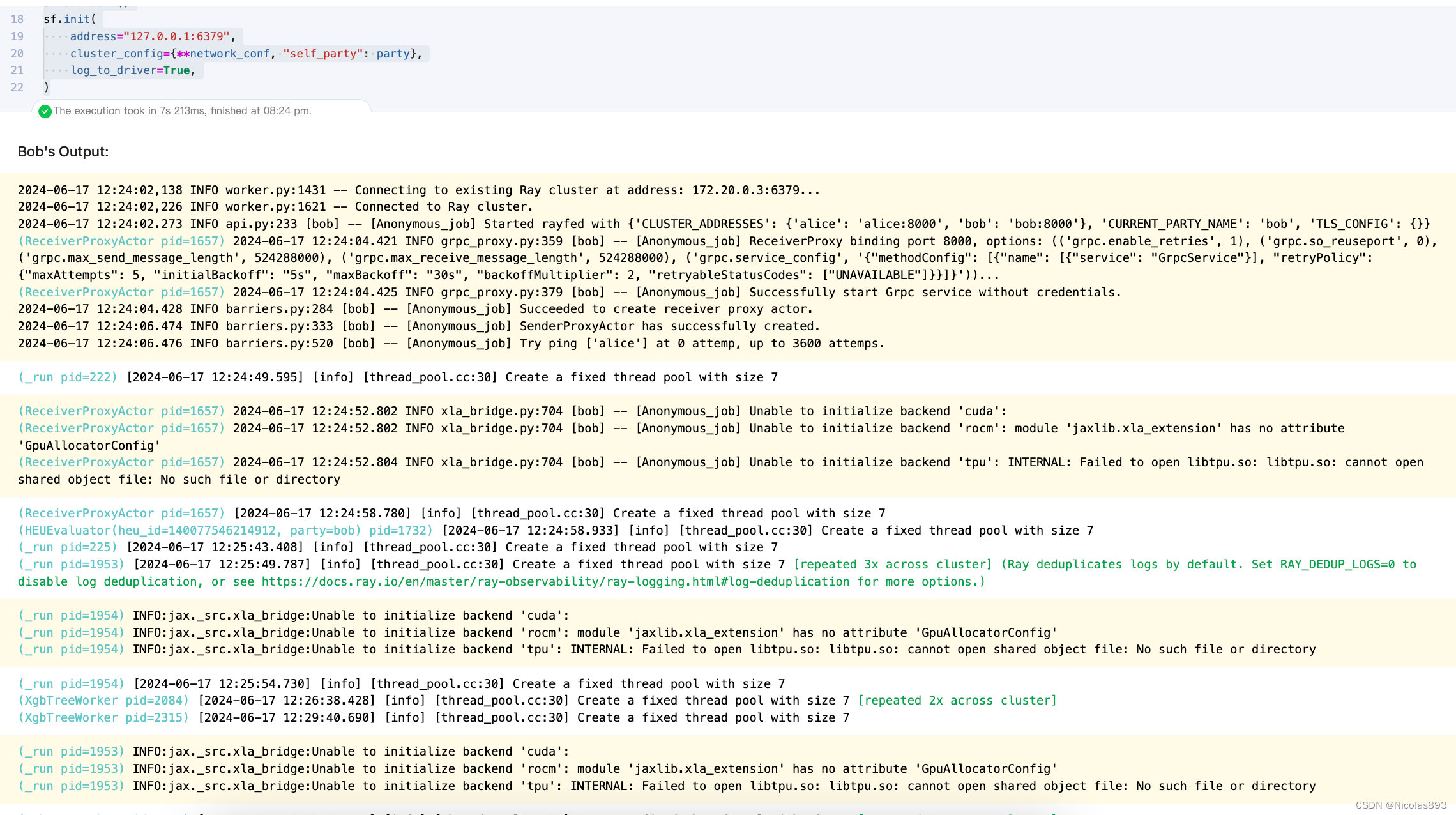
sf.init( # 初始化secretflow集群
address="127.0.0.1:6379",
cluster_config={**network_conf, "self_party": party}, # 集群配置,包括网络配置和当前参与方
log_to_driver=True,
)
这一步可能因为网络的原因会出现失败,多试几次。
2. 配置HEU设备信息以及SPU设备信息,为后续计算做准备
alice, bob = sf.PYU("alice"), sf.PYU("bob") # 创建alice和bob的PYU对象
# 配置SPU设备信息
spu_conf = {
"nodes": [
{
"party": "alice",
"address": "alice:8001",
"listen_addr": "alice:8001",
},
{
"party": "bob",
"address": "bob:8001",
"listen_addr": "bob:8001",
},
],
"runtime_config": {
"protocol": spu.spu_pb2.SEMI2K, # 使用semi2k协议
"field": spu.spu_pb2.FM128, # 采用128bit环
"sigmoid_mode": spu.spu_pb2.RuntimeConfig.SIGMOID_REAL,
},
}
# 初始化HEU设备信息
heu_config = {
'sk_keeper': {'party': 'alice'}, # 保密保管者为Alice
'evaluators': [{'party': 'bob'}], # 评估者为Bob
'mode': 'PHEU',
'he_parameters': {
# ou是一个快速加密方案,安全性与paillier相当。
'schema': 'ou', # 加密模式为ou
'key_pair': {
'generate': {
# 位数应为2048,提供足够的安全性。
'bit_size': 2048, # 密钥位数
},
},
},
'encoding': {
'cleartext_type': 'DT_I32', # 明文类型为32位整数
'encoder': "IntegerEncoder", # 编码器类型为整数编码器
'encoder_args': {"scale": 1}, # 编码器参数设置
},
}
heu = sf.HEU(heu_config, spu_conf['runtime_config']['field']) # 使用heu_config和字段类型来初始化HEU对象
3. 加载数据
import pandas as pd
import os
from secretflow.data.vertical import read_csv as v_read_csv, VDataFrame
from secretflow.data.core import partition
current_dir = os.getcwd()
# 将Alice和Bob的数据加载为垂直数据结构
data = v_read_csv(
{alice: f"{current_dir}/bank_0_8.csv", bob: f"{current_dir}/bank_8_16.csv"},
keys="id",
drop_keys="id",
)
# 加载Alice的标签数据
alice_y_pyu_object = alice(lambda path: pd.read_csv(path, index_col=0))(f"{current_dir}/bank_y.csv")
label = VDataFrame(partitions={alice: partition(alice_y_pyu_object)})
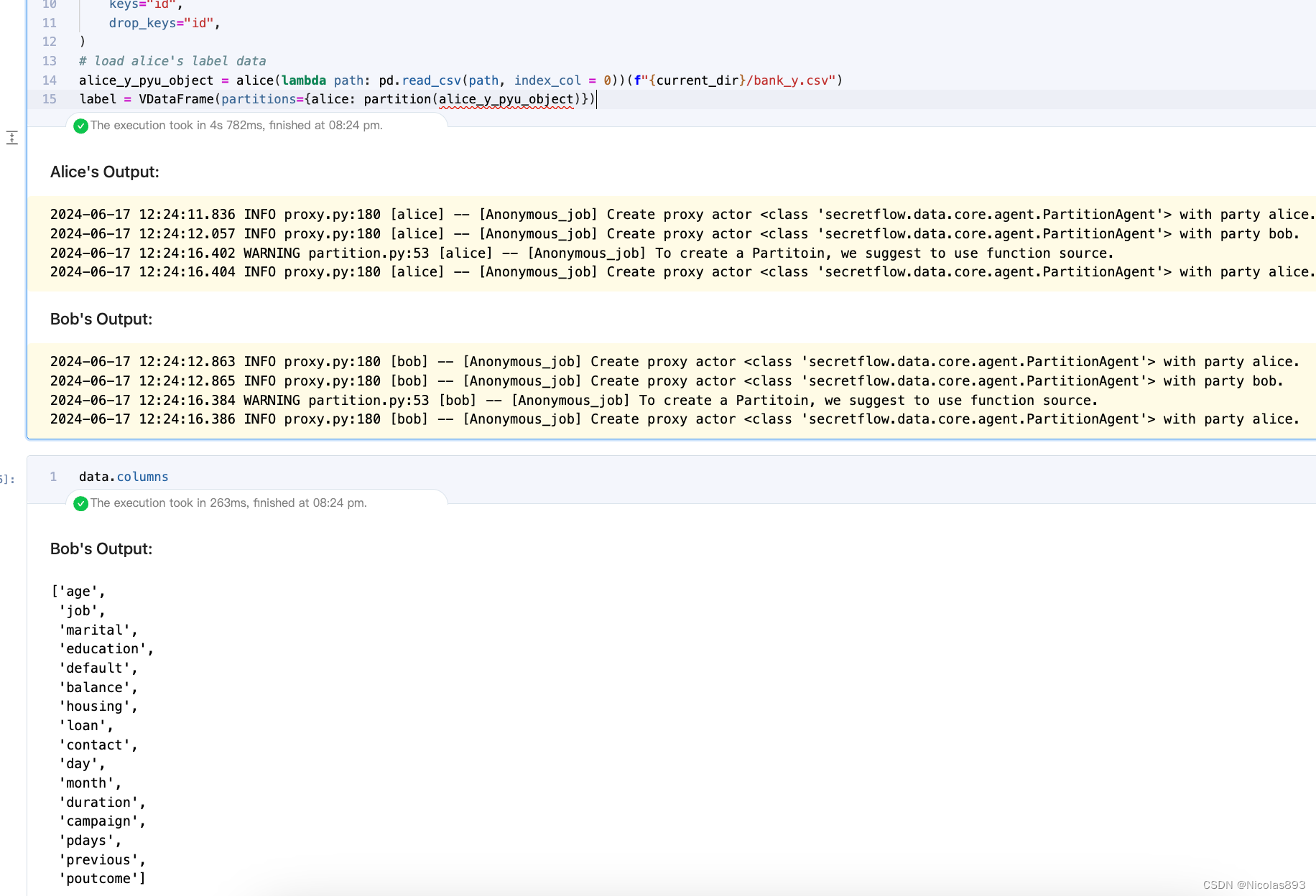
4. 数据预处理,对数据做label encoder,处理成数值编码,适合后续的heu以及spu的模型学习。
from secretflow.preprocessing import LabelEncoder
encoder = LabelEncoder() # 创建标签编码器对象
# 对各列数据进行标签编码处理
data['job'] = encoder.fit_transform(data['job']) # 编码职业列
data['marital'] = encoder.fit_transform(data['marital']) # 编码婚姻状态列
data['education'] = encoder.fit_transform(data['education']) # 编码教育程度列
data['default'] = encoder.fit_transform(data['default'])
data['housing'] = encoder.fit_transform(data['housing']) # 编码是否有住房列
data['loan'] = encoder.fit_transform(data['loan']) # 编码是否有个人贷款列
data['contact'] = encoder.fit_transform(data['contact']) # 编码联系方式列
data['poutcome'] = encoder.fit_transform(data['poutcome'])
data['month'] = encoder.fit_transform(data['month']) # 编码最后一次联系的月份列
label = encoder.fit_transform(label) # 对标签数据进行编码处理5. 对数据进行切分处理,包括特征和标签
from secretflow.data.split import train_test_split as train_test_split_fed
# 特征切分
X_train_fed, X_test_fed = train_test_split_fed(data, test_size=0.2, random_state=94)
# 标签切分
y_train_fed, y_test_fed = train_test_split_fed(label, test_size=0.2, random_state=94)
6. 基于heu进行xgb模型初始化、参数配置及模型训练
from secretflow.ml.boost.sgb_v import (
get_classic_XGB_params,
Sgb, # 从sgb_v模块中导入Sgb类
)
sgb = Sgb(heu) # 使用heu对象初始化Sgb类
params = get_classic_XGB_params() # 调用获取经典XGBoost参数的函数,初始化参数字典
params['num_boost_round'] = 14 # 设定boosting轮数
params['max_depth'] = 5 # 设定每棵树的最大深度
params['base_score'] = 0.5 # 基础得分
params['reg_lambda'] = 0.1 # L2正则化项权重
params['learning_rate'] = 0.3 # 学习率
params['sketch_eps'] = 1 / 10 # sketch_eps参数,控制最大分箱数为10
params['enable_early_stop'] = True # 启用早停策略
params['enable_monitor'] = True # 启用监控模式
params['validation_fraction'] = 0.2 # 验证集比例
params['stopping_rounds'] = 5 # 早停轮数
params['stopping_tolerance'] = 0.001 # 早停容忍度
params['seed'] = 94 # 设定随机种子
params['first_tree_with_label_holder_feature'] = True # 第一棵树是否使用标签持有特征
params['save_best_model'] = True # 是否保存最佳模型
model = sgb.train(params, X_train_fed, y_train_fed) # 使用参数训练模型,得到训练后的模型对象这里我设置了早停容忍度为0.001,避免出现早停,也是为了后续可以和SS-XGB进行对比。
模型迭代
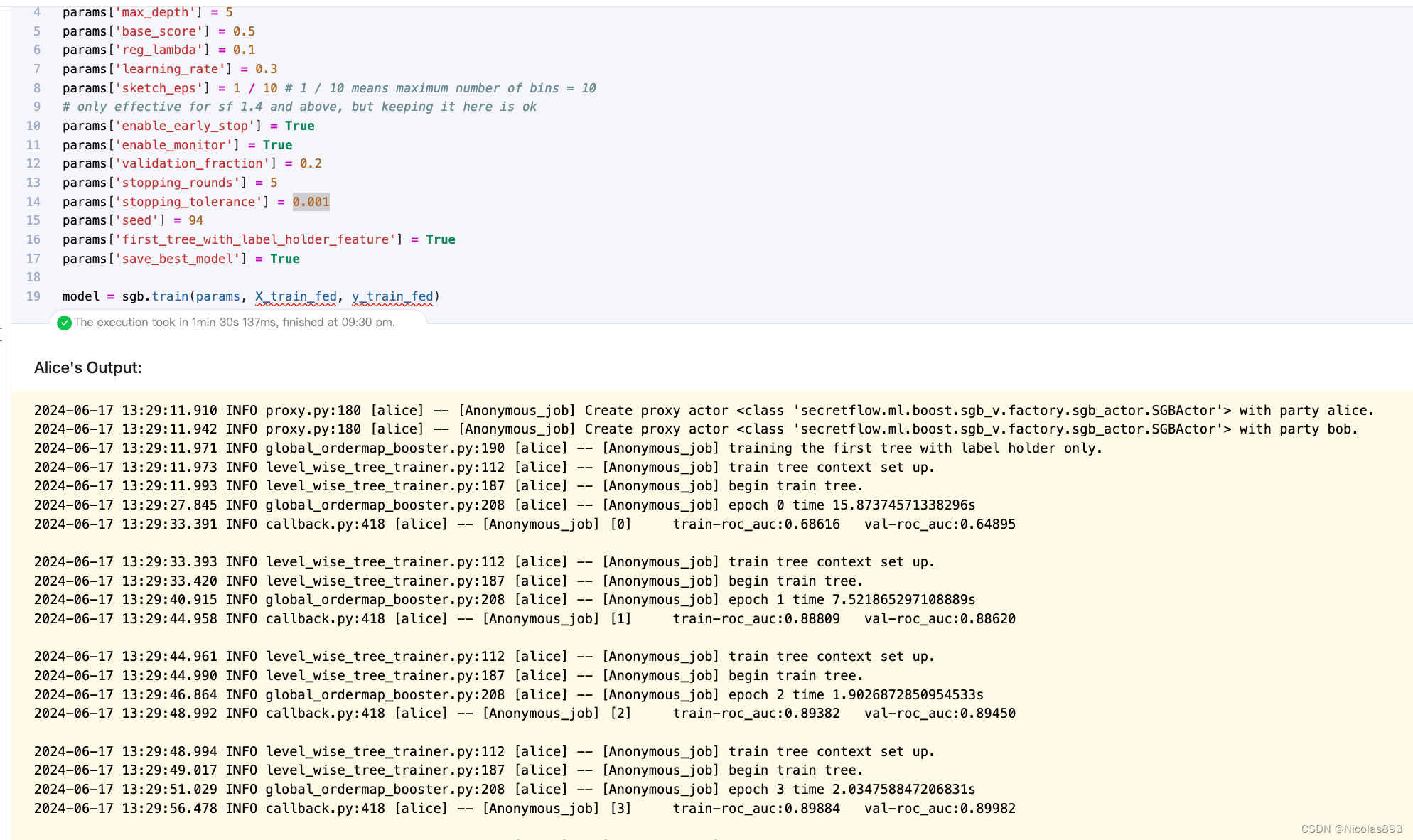
迭代14轮停止
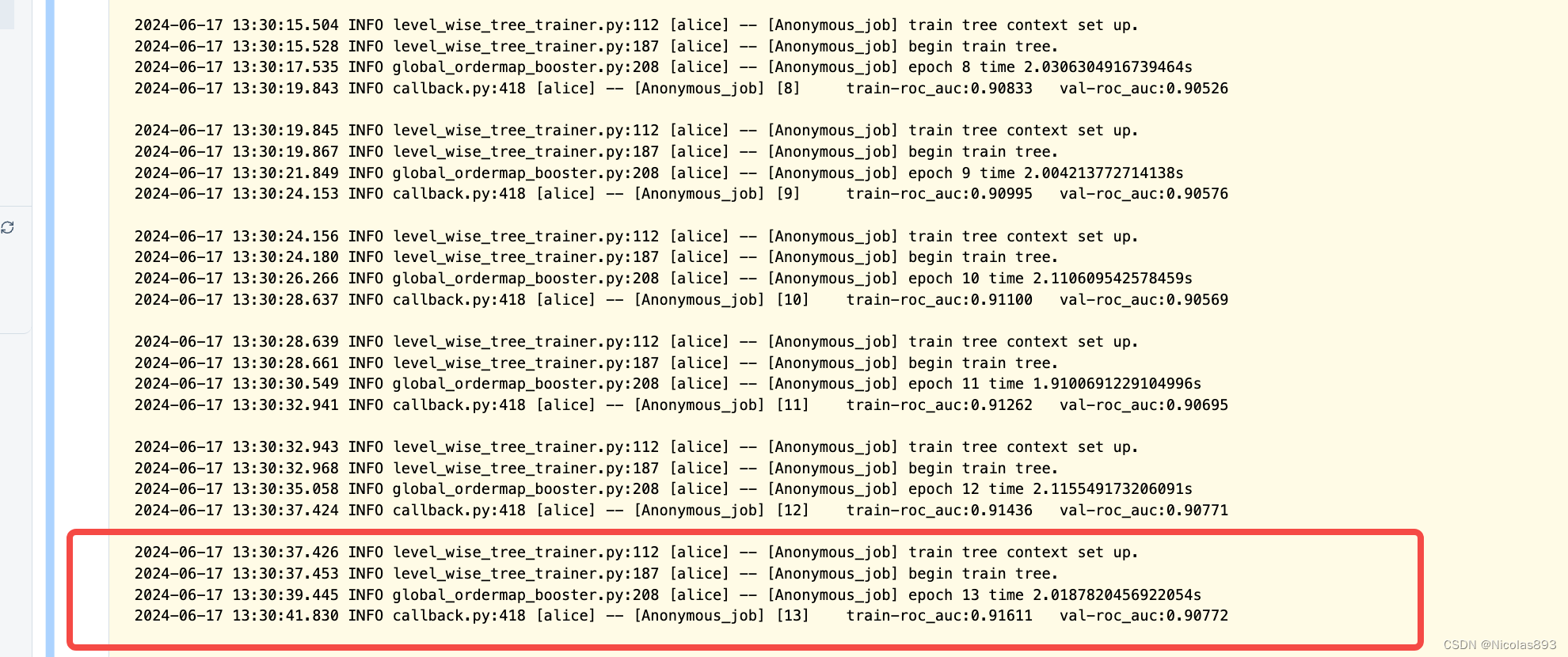
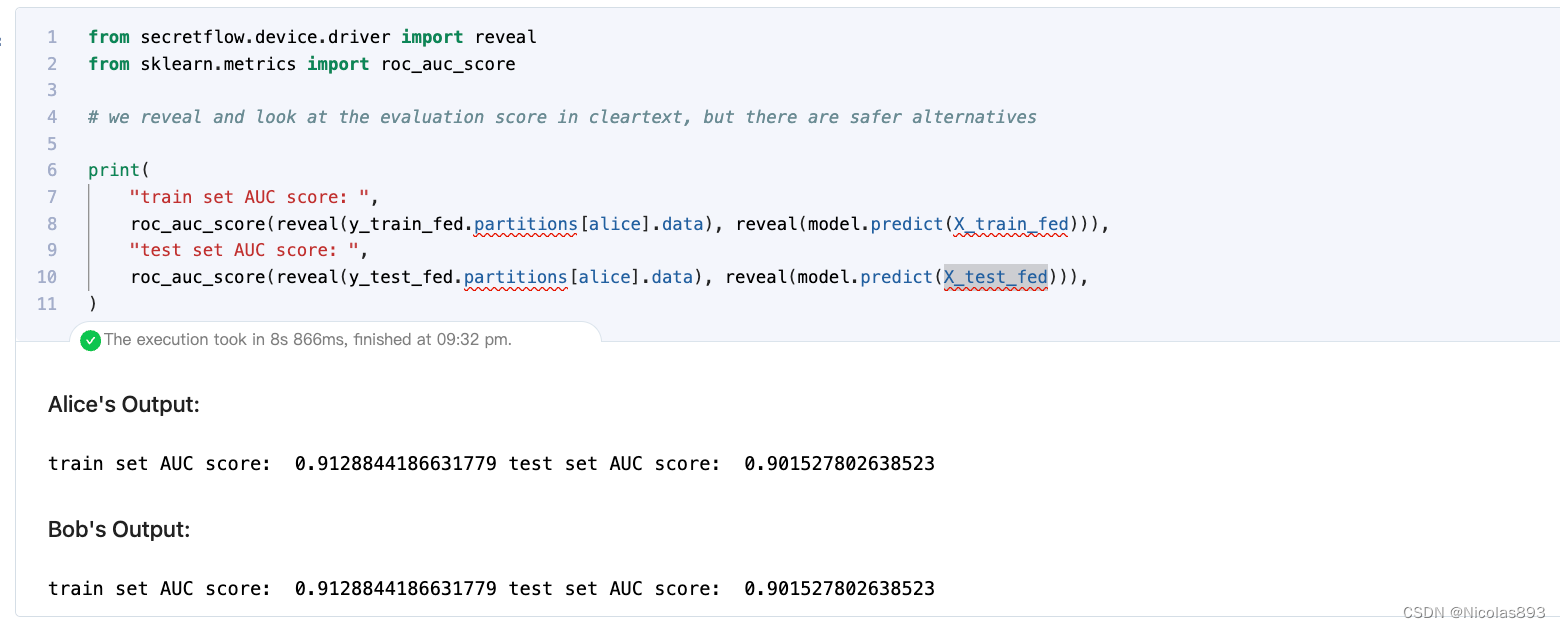
7. 模型评估
from secretflow.device.driver import reveal # 从device.driver模块中导入reveal函数,用于揭示数据
from sklearn.metrics import roc_auc_score # 导入sklearn中的ROC AUC评估指标
# 我们在明文中揭示并查看评估分数,但有更安全的替代方案
print(
"train set AUC score: ",
roc_auc_score(reveal(y_train_fed.partitions[alice].data), reveal(model.predict(X_train_fed))),
"test set AUC score: ",
roc_auc_score(reveal(y_test_fed.partitions[alice].data), reveal(model.predict(X_test_fed))),
)
8.接下来,用SS-XGB设置同样的参数进行运行,跑同样的流程
from secretflow.ml.boost.ss_xgb_v import Xgb
spu = sf.SPU(spu_conf)
# 基于SPU初始化Xgb对象
ss_xgb = Xgb(spu)
# 训练参数
params = {
'num_boost_round': 14,
'max_depth': 5,
'learning_rate': 0.3,
'sketch_eps': 0.1,
'objective': 'logistic',
'reg_lambda': 0.1,
'subsample': 1,
'colsample_by_tree': 1,
'base_score': 0.5,
}
# 训练模型
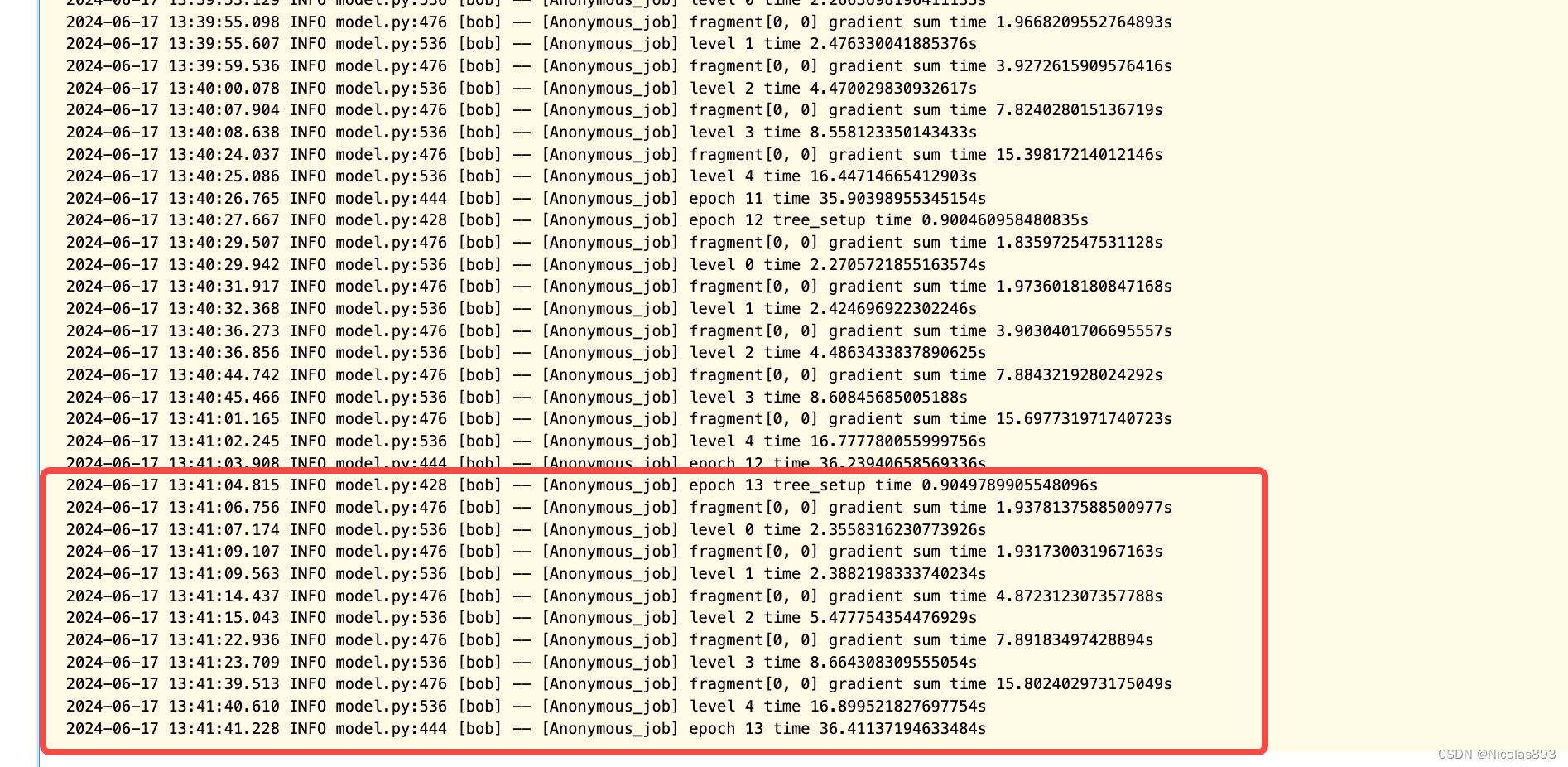
model = ss_xgb.train(params, X_train_fed, y_train_fed)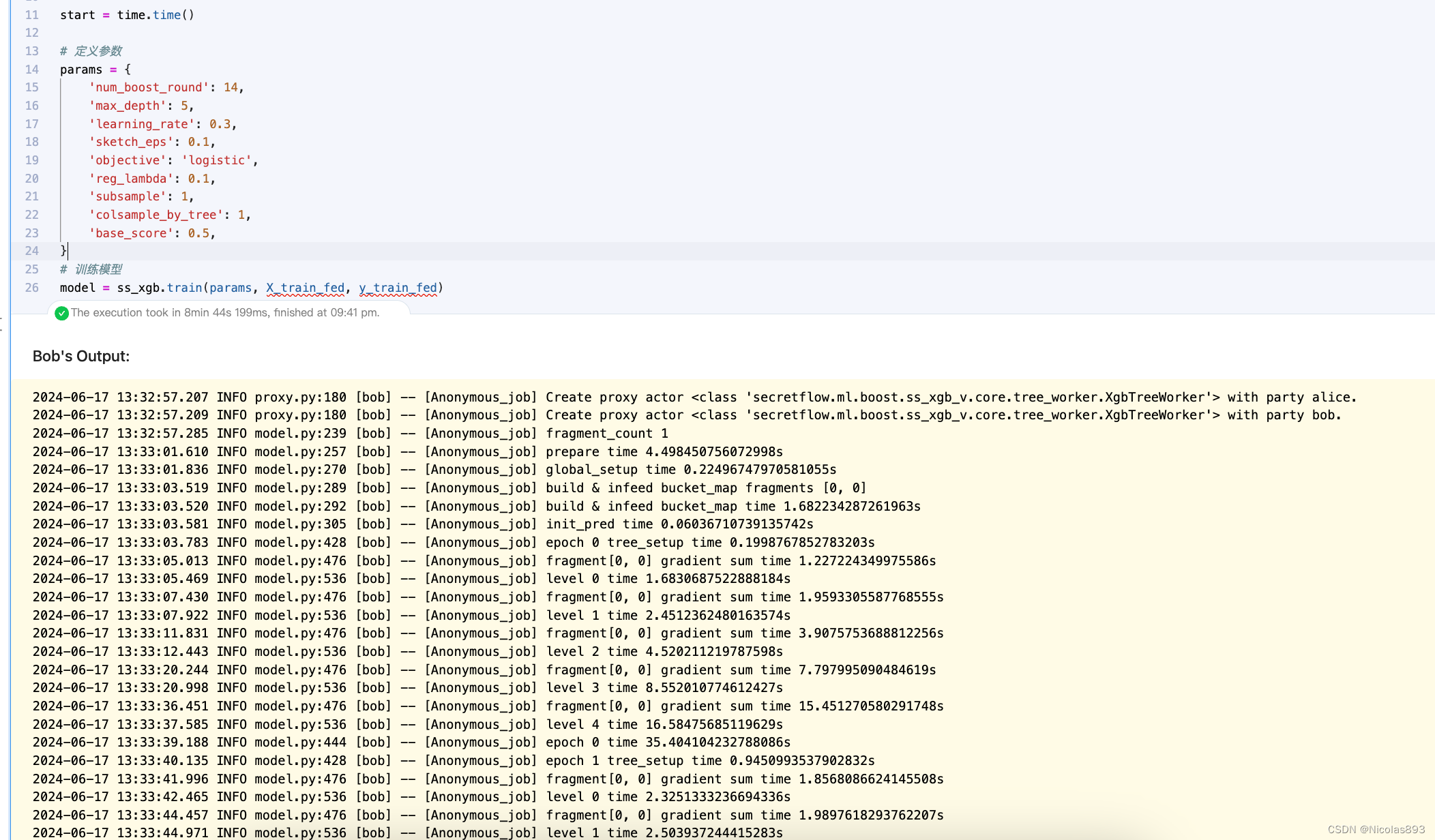
用SS-XGB跑,明显性能要差很多,运行了8分44s。而同样参数的sgb,只需要30s,效率差距很明显。
9. SS-XGB模型评估
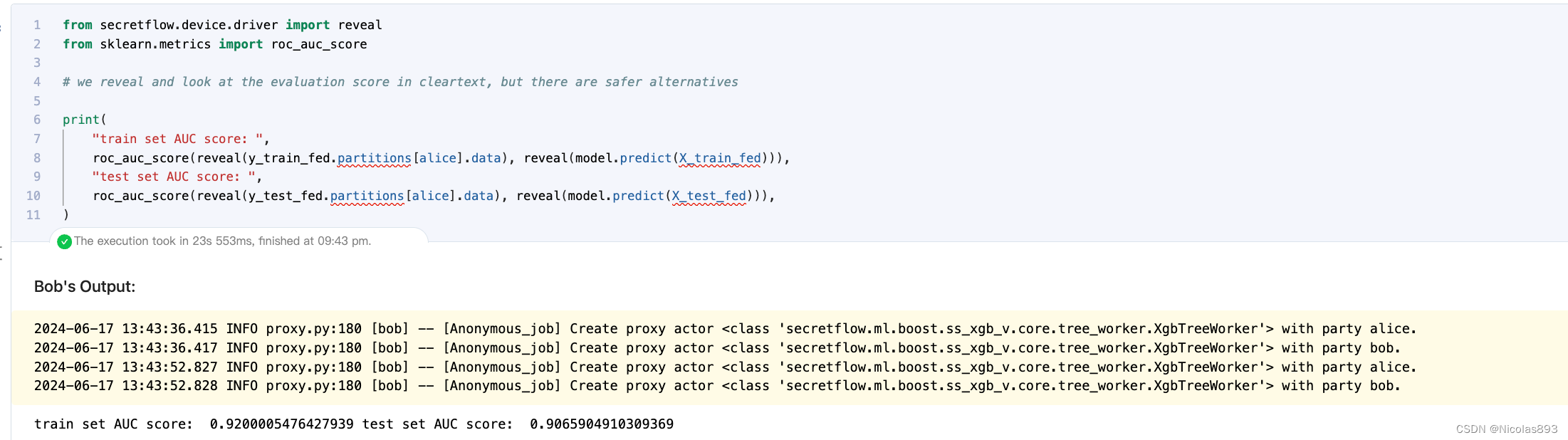
从实际评估结果看,SGB和SS-XGB的准确率基本上持平,SS-XGB略微好一点点,test-auc可以到0.9066.



















 1432
1432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











