







近期陆续接触到关于混合联邦学习的概念,但基于横纵向的混合联邦实际的应用案例却几乎没有看到,普遍是一些实验性的课题,因此这一领域知识没有被很好普及。本篇文章的目的,主要是分析讨论关于横纵向混合联邦学习的业务场景、应用架构、算法执行模式、以及混合联邦学习的算法实现等内容。
混合联邦学习在一个建模任务中同时包含了横向联邦与纵向联邦,由于包含纵向联邦,所以所有参与者都只能得到与己方特征相关的部分的模型。混合联邦以同时扩充特征数和样本数为目的,是横向联邦与纵向联邦的结合,训练后所有成员都只能得到与己方特征相关的部分模型。以图1为例,模型的后续使用需要 A + B 或者 C + B 才能拼合出一个完整的模型进行预测。
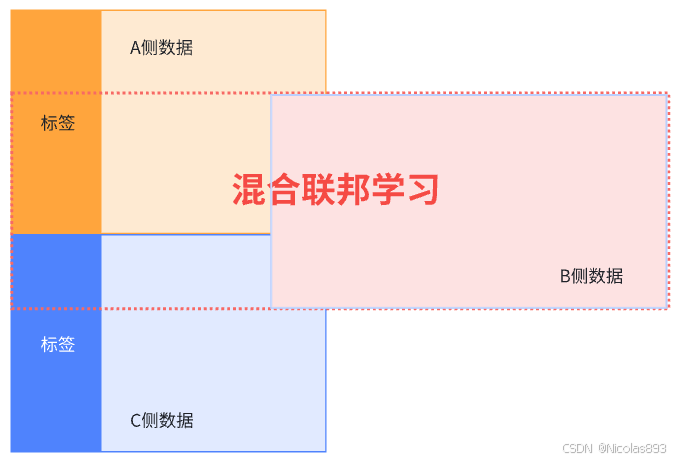
图1. 混合联邦学习面向的数据切分形态
一、业务背景
在不同的行业中,大多数应用程序只能访问小型或低质量的数据集。标注数据非常昂贵,尤其在需要专业技能和领域知识的领域。此外,特定任务所需的数据可能并非集中存储在一个地方。许多组织可能只有未标注的数据,而其他一些组织可能只有非常有限的标注数据。在当前应用的双方联邦学习场景中,参与者Guest和参与者Host进行隐私求交后的联邦建模数据量非常小,导致模型的性能和精度不足。例如,双方可能有10万条样本数据,但求交后只有5000条数据,双方使用这5000条数据进行建模,这样的数据量不足以构建高质量的模型。因此,提高联合模型的精度是一个亟待解决的问题。
在隐私计算领域,to B场景中做纵向联邦学习,很少会去考虑双方数据交集量级的问题,一般都会假设已经有足够的样本量级。但现实往往会有很多的不足。例如应用联邦学习的场景中,经常会遇到参与者A和和B拥有的数据,虽然能形成互补,可以联合构建机器学习模型,但是参与者A和B拥有的数据量仍然非常少,构建的联合模型的性能难以达到预期指标,从而联合模型的精确度也不够高。因此在考虑特征互补的基础上,如何去补充更多的样本是混合联邦学习要解决的关键点。
二、应用架构
因为同时会涉及到横向与纵向的学习,因此混合联邦学习方法适用于具有多组参与者的联邦模型训练。其中,同一组内的参与者的数据集之间包含有相同的样本对象及不同的样本特征(即纵向场景)。不同组间的参与者的数据集之间包含有相同的样本特征及不同的样本对象(即横向场景)。
针对每个组,首先根据组内参与者的数据集联合训练每组的纵向联邦学习模型,训练过程中组内每个参与者都与组内其他参与者交换了训练的中间结果,对各组的纵向联邦学习模型进行融合得到横向联邦学习模型,并将横向联邦学习模型发送给每个组内参与者。针对每个组,根据横向联邦学习模型及组内参与者的数据集训练得到更新后的纵向联邦学习模型,返回对各组的纵向联邦学习模型进行融合得到横向联邦学习模型的步骤,直至模型训练结束。可以看到,整个训练过程是组内纵向联邦学习与组间横向联邦学习交替反复迭代,直至完成最终的模型参数的学习。
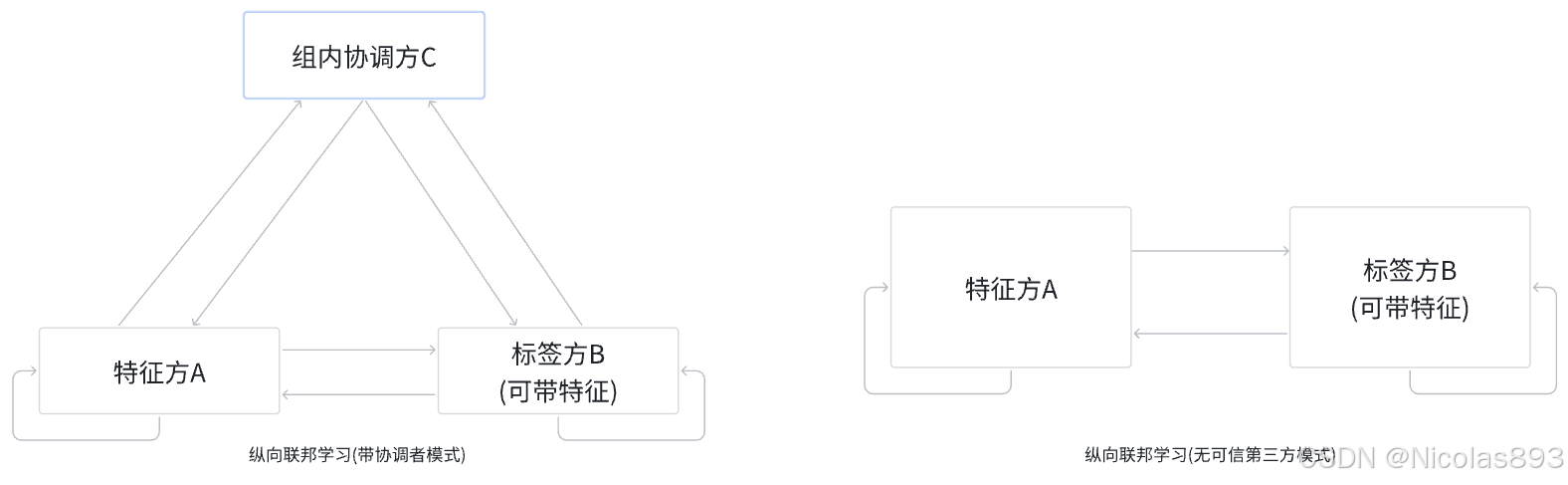
图2. 任意组内纵向联邦学习架构
图2所展示的架构,训练出适用于各组参与者的联邦学习模型过程的一个子训练过程。纵向联邦学习目前主流的是有两种模式:(1)带协调方的可信第三方版本;(2)纯两方学习版本(更推荐这种模式)。训练得到的纵向联邦学习是一个阶段性的联邦学习模型。纵向联邦学习适用于参与者的数据特征重叠较小,而用户重叠较多的情况下,取出参与者用户相同而用户数据特征不同的那部分用户及数据进行联合机器学习训练。比如有属于同一个地区的两个参与者A和B,其中参与者A是一家银行,参与者B是一个电商平台。参与者A和B在同一地区拥有较多相同的用户,但是A与B的业务不同,记录的用户数据特征是不同的。然而A和B记录的用户数据特征可能是互补的。在这样的场景下,可以使用纵向联邦学习方法来帮助A和B构建联合机器学习预测模型,帮助A和B向客户提供更好的服务。
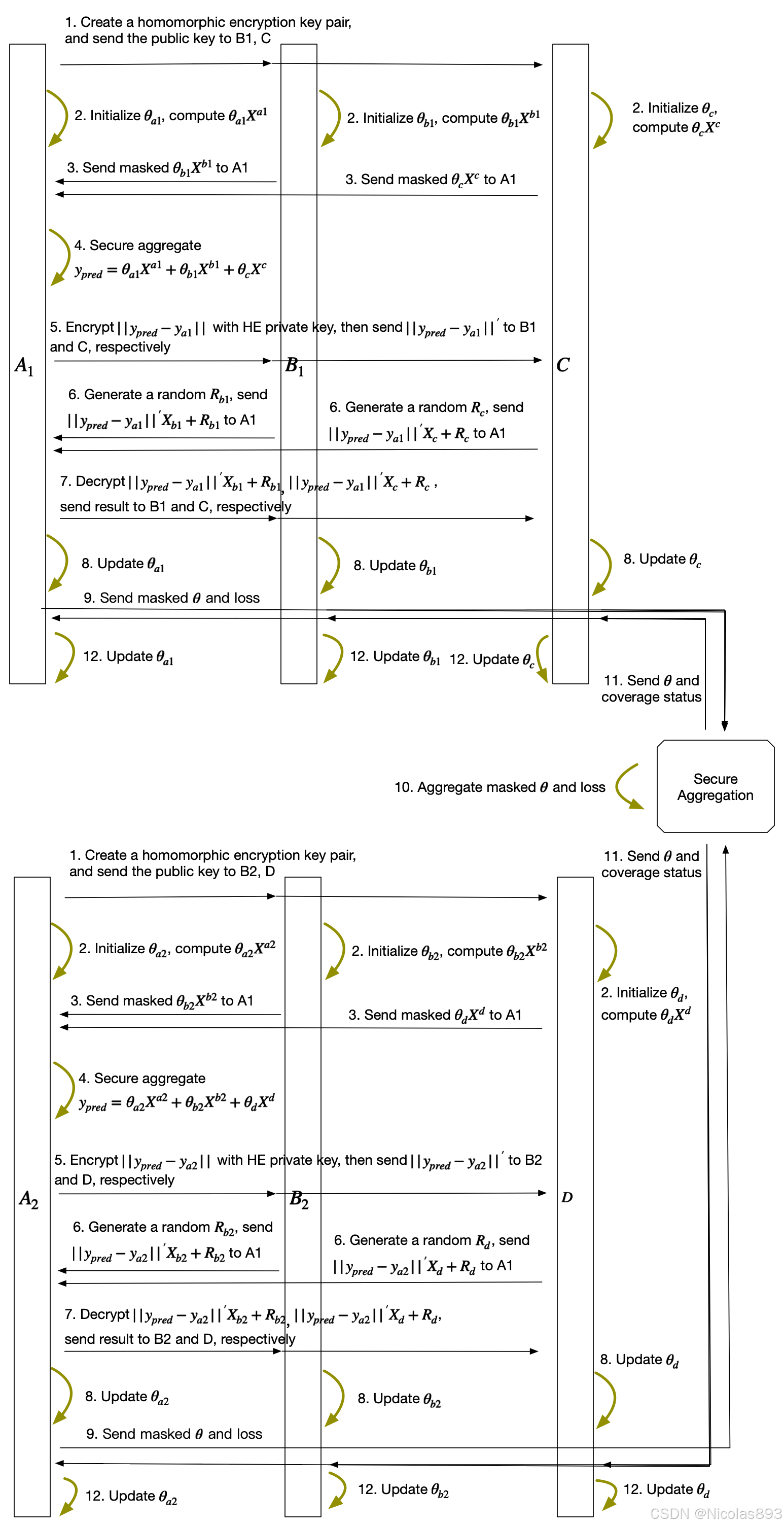
这里给出一个基于协调者模式的计算流程,帮助理解纵向联邦学习的过程。对于无可信第三方的模式计算流程,有兴趣可以单独与我私信沟通。在具有协调者场景中,A和B联合建模,需要协调者C参与。第一部分:参与者A和B实现加密样本对齐。由于两家企业A和B的用户群体并非完全重合,系统利用基于加密的用户样本对齐技术(隐私集合求交),在A和B不公开各自数据的的前提下确认双方的共有用户,并且不暴露非交集的用户,以便联合这些用户的特征进行建模。纵向联邦学习的加密模型训练过程如下(以下步骤仅以梯度下降算法为例说明训练过程):在确定共有用户群体后,就可以利用这些数据训练机器学习模型。为了保证训练过程中数据的保密性,需要借助协调者C进行加密训练。以线性回归模型为例,训练过程可分为以下4步。第1步,协调者C把公钥分发给A和B,用以对训练过程中需要交换的数据进行加密。第2步,参与者A和B之间以加密形式交互用于计算梯度的中间结果。第3步:参与者A和B分别基于加密的梯度值进行计算,同时参与者B根据其标签数据计算损失函数,并把结果汇总给协调者C。协调者C通过汇总结果计算总梯度值并将其解密。第4步:协调者C将解密后的梯度分别回传给参与者A和B,参与者A和B根据梯度更新各自模型的参数。参与者和协调者选代上述步骤直至损失函数收敛或者是模型参数收敛或者是达到最大选代次数或者是达到最大训练时间,这样就完成了整个模型训练过程。
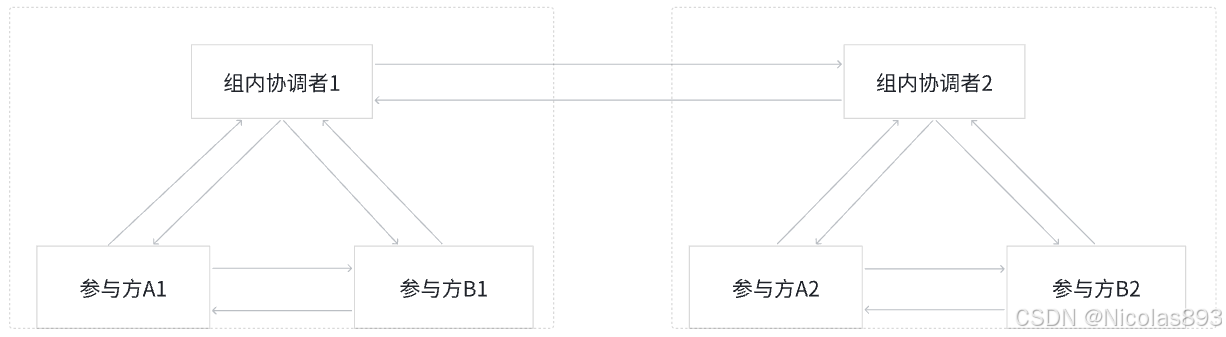
图3. 组间结构(协调者作为各纵向联邦学习系统内的组内协调者)
当协调者作为各纵向联邦学习系统内的组内协调者时,如图3所示,混合联邦学习架构包括2个纵向联邦学习系统(仅以图3示出的2个纵向联邦学习系统为例说明,但纵向联邦学习系统数量可以不限于2个),协调者C1和协调者C2为组内协调者,由协调者C1和协调者C2,对各组的纵向联邦学习模型权重系数进行融合得到横向联邦学习模型,具体如下:
- 协调者C1和参与者A1、B1训练纵向联邦学习模型M1;与此同时,协调者C2和参与者A2、B2训练纵向联邦学习模型M2。纵向联邦学习模型训练过程可以参考图2所示的纵向联邦学习的架构和流程。
- 协调者C1和C2分别将各自的纵向联邦学习模型M1和M2发送给对方。
- 协调者C1和C2分别进行模型融合,例如,对模型M1和]M2参数的值的加权平均值,作为横向联邦学习模型M的对应参数值。
- 协调者C1和C2分别将横向联邦学习模型M分发给参与者:A1、B1、A2、B2,当然这里各方获得的权重系数都是仅对应其自身所持有的特征而言,其他特征对应的参数不发送。
- 协调者C1和参与者A1、B1在横向联邦学习模型M的基础上,继续训练新的纵向联邦学习模型,并更新纵向联邦学习模型M1;与此同时,协调者C2和参与者A2、B2在横向联邦学习模型M的基础上继续训练模型,并更新对应的联邦学习模型M2。
选代以上过程直到横向联邦学习模型M收敛或者达到最大选代次数或者达到最大模型训练时间。在训练好横向联邦学习模型M后,协调者C1将横向联邦学习模型M分发给参与者A1和B1,协调者C2将横向联邦学习模型M分发给参与者A2和B2。参与者A1、B1、A2、B2最终获得的是相同的横向联邦学习模型M,当然是各自持有特征对应的权重系数。
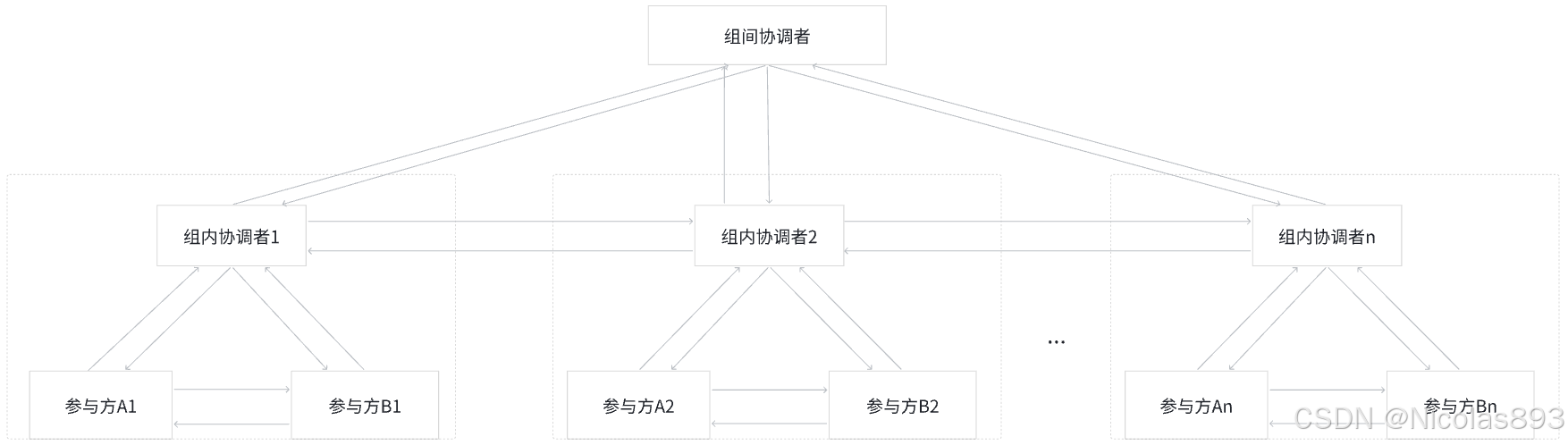
图4. 组间结构(当协调者为各纵向联邦学习系统间的组间协调者)
当协调者为各纵向联邦学习系统间的组间协调者时,如图4听示,混合联邦学习架构包括n个纵向联邦学习系统,n为大于或等于2的整数,由组内协调者C1~Cn以及组间协调者C0,对各组的纵向联邦学习模型进行融合得到横向联邦学习模型,具体如下:
- 协调者Cj和参与者Aj、Bj训练纵向联邦学习模型Mj,j=1,2,...,n具体过程可以参考图2所示的架构和流程。
- 协调者Cj将纵向联邦学习模型Mj发送给组间协调者C0,j=1,2,...,n。
- 组间协调者C0对收到的纵向联邦学习模型Mj进行模型融合,例如,对纵向联邦学习模型M1~Mj参数值的加权平均值,获得适用于各组参与者的横向联邦学习模型M。
- 组间协调者C0将横向联邦学习模型更新M分发给各个协调者Cj,j=1,2,...n。也可以,组间协调者C0将横向联邦学习模型更新M直接分发给参与者Aj和Bj,j=1,2,...,n。
- 协调者Cj将横向联邦学习模型更新M转发给参与者Aj和Bj, j=1,2,...,n。
- 协调者Cj和参与者Aj、Bj在横向联邦学习模型M的基础上继续训练纵向联邦学习模型,并更新纵向联邦学习模型Mj,1,2,......, n。具体过程可以参考图2所示的联邦学习架构和模型训练流程。
选代以上过程, 直到横向联邦学习模型M收敛或者达到最大选代次数或者达到最大训练时间。在训练好横向联邦学习模型M后,组间协调者C0将训练好的横向联邦学习模型M分发给协调者Cj,再由协调者Cj将横向联邦学习模型M分发给参与者Aj和Bj,j=1,2,...,n。参与者Aj和Bj最终获得的是相同的横向联邦学习模型M, j=1,2....,n。也可以,组间协调者C0直接将训练好的横向联邦学习模型M分发给参与者Aj和Bj,j=1,2,.....n。
三、算法执行模式
基于上述讨论,可以得出混合联邦的算法执行流程,通过分级进行联邦学习模型训练:先训练得到各纵向联邦学习系统的纵向联邦学习模型,再根据各纵向联邦学习模型进行横向融合,得到横向联邦学习模型。因此,可以通过上述方法及架构来使用多个参与者拥有的数据,而且纵向联邦学习系统的扩展性较好,可以有效解决参与者拥有的数据量太小的问题。
训练过程得到纵向联邦学习模型的过程具体包括: 参与者将根据参与者的数据集训练的初始模型为中间结果发送给其他参与者;参与者根据其他参与者反馈的中间结果,得到初始模型的训练结果,并发送给组内协调者:组内协调者根据各参与者的训练结果,确定更新参数并发送给各参与者:参与者根据更新参数更新初始模型,得到纵向联邦学习模型。
将各组的纵向联邦学习模型中同一参数的参数值进行加权平均,作为横向联邦学习模型中该参数的值。也可以,通过组间协调者,将各组的纵向联邦学习模型中同一参数的参数值进行加权平均,作为横向联邦学习模型中该参数的值;通过组间协调者,将横向联邦学习模型发过送给各组内协调者。组内协调者将横向联邦学习模型发送给组内参与者。
横向联邦学习适用于各个参与者的数据特征重叠较多,而用户重叠较少的情况下,取出参与者数据特征相同而用户不完全相同的那部分数据进行联合机器学习。比如有两家不同地区的银行,它们的用户群样体分别来自各自所在的地区,相互的交集很小。但是它们的业务很相似,该己录的用户数据特征很大部分是相同的。可以使用横向联邦学习来帮助两家银行构效联合模型来预测他们的客户行为。
关于数据的切分,这里再讨论一下,给出两种形式,这两种形式应该都会存在应用场景。第一种切分形式更适合不同地区的机构,而第二种切分形式更适合同地区的机构。
图5展示的是第一种数据切分形式,在这种场景中,A1、B1、C1、A2、B2、C2、An、Bn、Cn都是不同的节点,比如A1、B1、C1分别为上海地区的运营商、电商、银行机构,A2、B2、C2分别为北京地区的运营商、电商、银行机构,An、Bn、Cn是深圳地区的运营商、电商、银行机构。同地区内的机构,共同用户会更多,不同业务机构的特征互补性更高。因此组内更容易构建纵向联邦学习,而组间样本用户数重叠更少,特征的重叠更多,因此更容易采用横向联邦学习计算。

图5. 第一种数据切分形式
图6展示的是第二种数据切分形式,在这种场景中,参与者只有A、B、C、D、E,都是不同的节点,A中的第一部分样本id与B方的第一部分样本、C方存在重叠,A中的第二部分样本id与B方第二部分样本、D方存在重叠,A中的第n部分样本id与B方第n部分样本、E方存在重叠。这种情况更契合类似的场景,上海地区的电商、保险分别为A和B,然后C、D、E分别为上海地区的三家不同银行。同地区内的机构,共同用户会更多,不同业务机构的特征互补性更高, 然后交集可能会因为金融机构的差异有所差别,需要涉及多家金融机构。组内更容易构建纵向联邦学习,而组间样本用户数重叠更少,特征的重叠更多,因此更容易采用横向联邦学习计算。
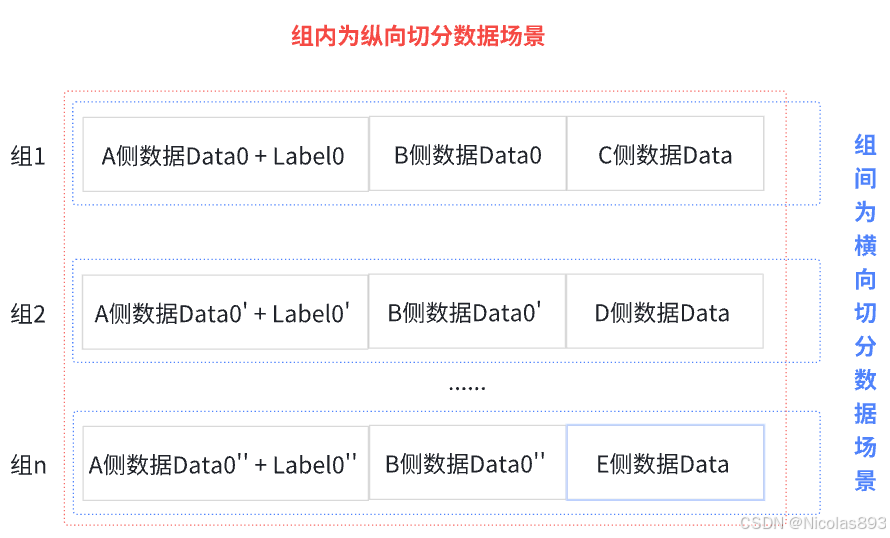
图6. 第二种数据切分形式
四、算法实现
混合切分指的是数据同时包含了水平和垂直切分。此处以图6的数据切分为例:A和B拥有相同的样本但是不同的特征,同时C、D、E拥有不同的样本但是特征相同。
算法:
- 对纵向切分数据的多个数据分块进行纵向联邦逻辑回归。
- 对多个纵向数据进行横向联邦逻辑回归。
针对混合切分数据,基于随机梯度下降的联邦逻辑回归算法如下:
(假设A持有标签)
以隐语代码实现为例:
1. 初始化
import secretflow as sf
sf.init(['alice', 'bob', 'carol', 'dave', 'eric'], address='local', num_cpus=64)
alice, bob, carol, dave, eric = (
sf.PYU('alice'),
sf.PYU('bob'),
sf.PYU('carol'),
sf.PYU('dave'),
sf.PYU('eric'),
)2. 数据准备
| 标签列 | 特征1~特征10 | 特征11~特征20 | 特征21~特征30 |
| alice_y0 | alice_x0 | bob_x0 | carol_x0 |
| alice_y1 | alice_x1 | bob_x1 | dave_x0 |
| alice_y2 | alice_x2 | bob_x2 | eric_x0 |
Alice持有所有的标签数据以及特征1~特征10,bob持有特征11~特征20,carol、dave、eric分别持有特征21~特征30的一部分。
# 从 sklearn.datasets 导入乳腺癌数据集
from sklearn.datasets import load_breast_cancer
# 从 sklearn.preprocessing 导入标准化工具
from sklearn.preprocessing import StandardScaler
# 加载乳腺癌数据集,将特征和标签分别存储在 features 和 label 中
features, label = load_breast_cancer(return_X_y=True, as_frame=True)
# 对特征数据进行标准化处理
features.iloc[:, :] = StandardScaler().fit_transform(features)
# 将标签转换为 DataFrame 格式
label = label.to_frame()
# 将特征数据分成三个子列表
feat_list = [
features.iloc[:, :10], # 前10列特征
features.iloc[:, 10:20], # 中间10列特征
features.iloc[:, 20:], # 后10列特征
]
# 将标签数据分为三部分
alice_y0, alice_y1, alice_y2 = label.iloc[0:200], label.iloc[200:400], label.iloc[400:]
# 将第一个子列表的特征数据分为三部分
alice_x0, alice_x1, alice_x2 = (
feat_list[0].iloc[0:200, :],
feat_list[0].iloc[200:400, :],
feat_list[0].iloc[400:, :],
)
# 将第二个子列表的特征数据分为三部分
bob_x0, bob_x1, bob_x2 = (
feat_list[1].iloc[0:200, :],
feat_list[1].iloc[200:400, :],
feat_list[1].iloc[400:, :],
)
# 将第三个子列表的特征数据分为三部分
carol_x, dave_x, eric_x = (
feat_list[2].iloc[0:200, :],
feat_list[2].iloc[200:400, :],
feat_list[2].iloc[400:, :],
)# 导入 tempfile 模块,用于创建临时目录
import tempfile
tmp_dir = tempfile.mkdtemp()
# 用于生成临时目录中的文件路径
def filepath(filename):
return f'{tmp_dir}/{filename}'
# 为 Alice 的标签数据生成文件路径
alice_y0_file, alice_y1_file, alice_y2_file = (
filepath('alice_y0'),
filepath('alice_y1'),
filepath('alice_y2'),
)
# 为 Alice 的特征数据生成文件路径
alice_x0_file, alice_x1_file, alice_x2_file = (
filepath('alice_x0'),
filepath('alice_x1'),
filepath('alice_x2'),
)
# 为 Bob 的特征数据生成文件路径
bob_x0_file, bob_x1_file, bob_x2_file = (
filepath('bob_x0'),
filepath('bob_x1'),
filepath('bob_x2'),
)
# 为 Carol、Dave 和 Eric 的特征数据生成文件路径
carol_x_file, dave_x_file, eric_x_file = (
filepath('carol_x'),
filepath('dave_x'),
filepath('eric_x'),
)
# 将 Alice 的特征数据保存到对应文件
alice_x0.to_csv(alice_x0_file, index=False)
alice_x1.to_csv(alice_x1_file, index=False)
alice_x2.to_csv(alice_x2_file, index=False)
# 将 Bob 的特征数据保存到对应文件
bob_x0.to_csv(bob_x0_file, index=False)
bob_x1.to_csv(bob_x1_file, index=False)
bob_x2.to_csv(bob_x2_file, index=False)
# 将 Carol、Dave 和 Eric 的特征数据保存到对应文件
carol_x.to_csv(carol_x_file, index=False)
dave_x.to_csv(dave_x_file, index=False)
eric_x.to_csv(eric_x_file, index=False)
# 将 Alice 的标签数据保存到对应文件
alice_y0.to_csv(alice_y0_file, index=False)
alice_y1.to_csv(alice_y1_file, index=False)
alice_y2.to_csv(alice_y2_file, index=False)
# 从多个参与者的CSV文件中读取垂直分割的数据
vdf_x0 = sf.data.vertical.read_csv(
{alice: alice_x0_file, bob: bob_x0_file, carol: carol_x_file}
)
vdf_x1 = sf.data.vertical.read_csv(
{alice: alice_x1_file, bob: bob_x1_file, dave: dave_x_file}
)
vdf_x2 = sf.data.vertical.read_csv(
{alice: alice_x2_file, bob: bob_x2_file, eric: eric_x_file}
)
# 从Alice的CSV文件中读取标签数据
vdf_y0 = sf.data.vertical.read_csv({alice: alice_y0_file})
vdf_y1 = sf.data.vertical.read_csv({alice: alice_y1_file})
vdf_y2 = sf.data.vertical.read_csv({alice: alice_y2_file})
# 将多个垂直分割的数据合并为一个混合数据框
x = sf.data.mix.MixDataFrame(partitions=[vdf_x0, vdf_x1, vdf_x2])
y = sf.data.mix.MixDataFrame(partitions=[vdf_y0, vdf_y1, vdf_y2])
3. 构建 HEU 和 SecureAggregator 用于后续训练。
from typing import List
# 导入安全聚合器
from secretflow.security.aggregation import SecureAggregator
import spu
# 生成 HEU 配置
def heu_config(sk_keeper: str, evaluators: List[str]):
return {
'sk_keeper': {'party': sk_keeper}, # 秘钥持有者
'evaluators': [{'party': evaluator} for evaluator in evaluators], # 评估者列表
'mode': 'PHEU', # 模式设定为PHEU
'he_parameters': {
'schema': 'paillier', # 同态加密方案为 paillier
'key_pair': {'generate': {'bit_size': 2048}}, # 密钥生成参数
},
}
# 创建三个 HEU 实例,分别使用不同的评估者配置
heu0 = sf.HEU(heu_config('alice', ['bob', 'carol']), spu.spu_pb2.FM128)
heu1 = sf.HEU(heu_config('alice', ['bob', 'dave']), spu.spu_pb2.FM128)
heu2 = sf.HEU(heu_config('alice', ['bob', 'eric']), spu.spu_pb2.FM128)
# 创建三个安全聚合器实例,分别使用不同的参与者配置
aggregator0 = SecureAggregator(alice, [alice, bob, carol])
aggregator1 = SecureAggregator(alice, [alice, bob, dave])
aggregator2 = SecureAggregator(alice, [alice, bob, eric])
4.训练模型
import logging
logging.root.setLevel(level=logging.INFO)
# 导入混合联邦逻辑回归模型
from secretflow.ml.linear import FlLogisticRegressionMix
# 创建一个联邦逻辑回归模型实例
model = FlLogisticRegressionMix()
# 训练模型
model.fit(
x, # 特征数据
y, # 标签数据
batch_size=64, # 批处理大小
epochs=3, # 训练轮数
learning_rate=0.1, # 学习率
aggregators=[aggregator0, aggregator1, aggregator2], # 聚合器列表
heus=[heu0, heu1, heu2], # HEU 实例列表
)
INFO:root:MixLr epoch 0: loss = 0.22200048124132613 INFO:root:MixLr epoch 1: loss = 0.10997288443236536 INFO:root:MixLr epoch 2: loss = 0.08508413270494121 INFO:root:MixLr epoch 3: loss = 0.07325763613227645
5.模型预测
import numpy as np
from sklearn.metrics import roc_auc_score
y_pred = np.concatenate(sf.reveal(model.predict(x)))
auc = roc_auc_score(label.values, y_pred)
acc = np.mean((y_pred > 0.5) == label.values)
print('auc:', auc, ', acc:', acc)auc: 0.98755 , acc: 0.93849
五、参考文献
【1】Li, Wenguo, et al. "Vertical Federated Learning Hybrid Local Pre-training." arXiv preprint arXiv:2405.11884 (2024).
【2】PCT/CN2019/117518《一种混合联邦学习方法及架构》
【3】SECRETFLOW 《混合联邦逻辑回归》
【4】CN113689003A 《一种安全的去除第三方的混合联邦学习框架及方法》
【5】WeFe《联邦学习》



















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











