







目录
1. 决策树模型
1.1 数据设定
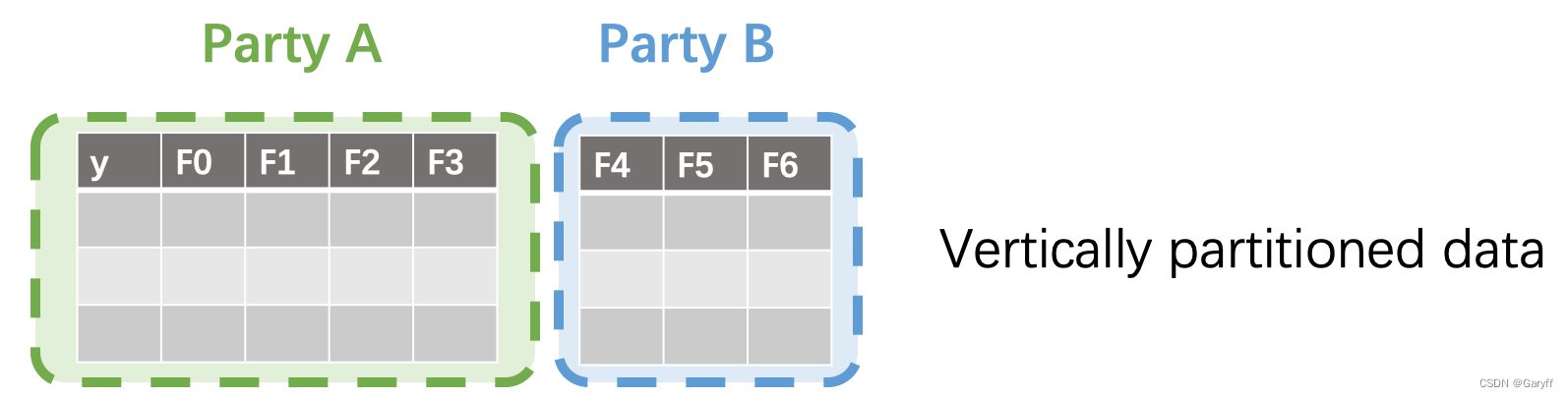
纵向分割数据集:所有数据方的样本一致、样本特征不同、只有一方持有标签。如下示意:
1.2 XGBoost训练算法
单棵树分裂过程:
- 预计算:根据损失函数定义、样本标签、当前预测值,计算每个样本可以求得其一阶导
和二阶导
;
- 结点分裂:通过枚举所有分裂方案,选出带来最优增益值的方式执行分裂。分裂方案包含分裂特征和分裂阈值,可以将当前结点样本集合
分裂为左子树样本集合
和右子树样本集合
,并由如下公式计算出此分裂方案的增益值:
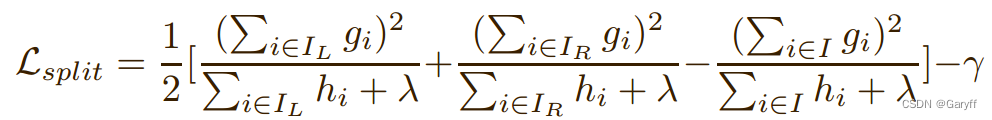
其中:和
分别为叶节点数和叶节点权重的惩罚因子。
- 权重计算:由落入该结点的样本计算得到,公式如下:
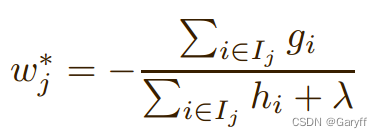
1.3 SS-XGB训练算法
使用秘密分享计算分裂增益值和叶权重,使用秘密分享协议提供的加/乘等操作来实现安全的多方联合计算。特别需要关注的问题是:如何在计算分桶加和时,不泄漏任何样本分布相关的信息。通过引入一个密态下的向量𝑆就可以解决这个问题。
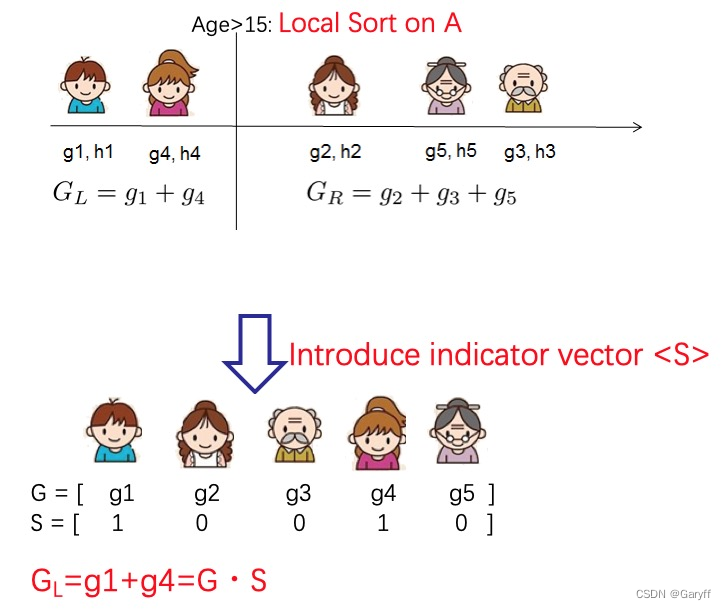
向量𝑆中标记为1的样本是被选中的样本需要加和,0相反。为了保证样本分布不泄漏,这个向量也是通过秘密分享协议保护的。在秘密分享协议的保护下,计算向量𝑆和梯度向量的内积,即可得到梯度在分桶内的累加和。
2. SS-XGB算法应用
import sys
import time
import logging
import secretflow as sf
from secretflow.ml.boost.ss_xgb_v import Xgb
from secretflow.device.driver import wait, reveal
from secretflow.data import FedNdarray, PartitionWay
from secretflow.data.split import train_test_split
import numpy as np
from sklearn.metrics import roc_auc_score
from sklearn.metrics import accuracy_score, classification_report
# init log
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
# init all nodes in local Standalone Mode.
sf.init(['alice', 'bob', 'carol'], address='local')
# init PYU, the Python Processing Unit, process plaintext in each node.
alice = sf.PYU('alice')
bob = sf.PYU('bob')
carol = sf.PYU('carol')
# init SPU, the Secure Processing Unit,
# process ciphertext under the protection of a multi-party secure computing protocol
spu = sf.SPU(sf.utils.testing.cluster_def(['alice', 'bob', 'carol']))
# read data in each party
def read_x(start, end):
from sklearn.datasets import load_breast_cancer
x = load_breast_cancer()['data']
return x[:, start:end]
def read_y():
from sklearn.datasets import load_breast_cancer
return load_breast_cancer()['target']
# alice / bob / carol each hold one third of the features of the data
v_data = FedNdarray(
partitions={
alice: alice(read_x)(0, 10),
bob: bob(read_x)(10, 20),
carol: carol(read_x)(20, 30),
},
partition_way=PartitionWay.VERTICAL,
)
# Y label belongs to alice
label_data = FedNdarray(
partitions={alice: alice(read_y)()},
partition_way=PartitionWay.VERTICAL,
)
# wait IO finished
wait([p.data for p in v_data.partitions.values()])
wait([p.data for p in label_data.partitions.values()])
# split train data and test date
random_state = 1234
split_factor = 0.8
v_train_data, v_test_data = train_test_split(v_data, train_size=split_factor, random_state=random_state)
v_train_label, v_test_label= train_test_split(label_data, train_size=split_factor, random_state=random_state)
# run SS-XGB
xgb = Xgb(spu)
start = time.time()
params = {
# for more detail, see Xgb API doc
'num_boost_round': 5,
'max_depth': 5,
'learning_rate': 0.1,
'sketch_eps': 0.08,
'objective': 'logistic',
'reg_lambda': 0.1,
'subsample': 1,
'colsample_by_tree': 1,
'base_score': 0.5,
}
model = xgb.train(params, v_train_data,v_train_label)
logging.info(f"train time: {time.time() - start}")
# Do predict
start = time.time()
# Now the result is saved in the spu by ciphertext
spu_yhat = model.predict(v_test_data)
# reveal for auc, acc and classification report test.
yhat = reveal(spu_yhat)
logging.info(f"predict time: {time.time() - start}")
y = reveal(v_test_label.partitions[alice])
# get the area under curve(auc) score of classification
logging.info(f"auc: {roc_auc_score(y, yhat)}")
binary_class_results = np.where(yhat>0.5, 1, 0)
# get the accuracy score of classification
logging.info(f"acc: {accuracy_score(y, binary_class_results)}")
# get the report of classification
print("classification report:")
print(classification_report(y, binary_class_results))3. SGB算法应用
import spu
from sklearn.metrics import roc_auc_score
import secretflow as sf
from secretflow.data import FedNdarray, PartitionWay
from secretflow.device.driver import reveal, wait
from secretflow.ml.boost.sgb_v import (
Sgb,
get_classic_XGB_params,
get_classic_lightGBM_params,
)
from secretflow.ml.boost.sgb_v.model import load_model
import pprint
pp = pprint.PrettyPrinter(depth=4)
# Check the version of your SecretFlow
print('The version of SecretFlow: {}'.format(sf.__version__))
alice_ip = '127.0.0.1'
bob_ip = '127.0.0.1'
ip_party_map = {bob_ip: 'bob', alice_ip: 'alice'}
_system_config = {'lineage_pinning_enabled': False}
sf.shutdown()
# init cluster
sf.init(
['alice', 'bob'],
address='local',
_system_config=_system_config,
object_store_memory=5 * 1024 * 1024 * 1024,
)
# SPU settings
cluster_def = {
'nodes': [
{'party': 'alice', 'id': 'local:0', 'address': alice_ip + ':12945'},
{'party': 'bob', 'id': 'local:1', 'address': bob_ip + ':12946'},
# {'party': 'carol', 'id': 'local:2', 'address': '127.0.0.1:12347'},
],
'runtime_config': {
# SEMI2K support 2/3 PC, ABY3 only support 3PC, CHEETAH only support 2PC.
# pls pay attention to size of nodes above. nodes size need match to PC setting.
'protocol': spu.spu_pb2.SEMI2K,
'field': spu.spu_pb2.FM128,
},
}
# HEU settings
heu_config = {
'sk_keeper': {'party': 'alice'},
'evaluators': [{'party': 'bob'}],
'mode': 'PHEU',
'he_parameters': {
# ou is a fast encryption schema that is as secure as paillier.
'schema': 'ou',
'key_pair': {
'generate': {
# bit size should be 2048 to provide sufficient security.
'bit_size': 2048,
},
},
},
'encoding': {
'cleartext_type': 'DT_I32',
'encoder': "IntegerEncoder",
'encoder_args': {"scale": 1},
},
}
# Data Settings
from sklearn.datasets import load_breast_cancer
ds = load_breast_cancer()
x, y = ds['data'], ds['target']
v_data = FedNdarray(
{
alice: (alice(lambda: x[:, :15])()),
bob: (bob(lambda: x[:, 15:])()),
},
partition_way=PartitionWay.VERTICAL,
)
label_data = FedNdarray(
{alice: (alice(lambda: y)())},
partition_way=PartitionWay.VERTICAL,
)
#Parameters settings
params = get_classic_XGB_params()
params['num_boost_round'] = 3
params['max_depth'] = 3
pp.pprint(params)
#Use SGB
sgb = Sgb(heu)
model = sgb.train(params, v_data, label_data)
# Evaluation models
yhat = model.predict(v_data)
yhat = reveal(yhat)
print(f"auc: {roc_auc_score(y, yhat)}")
# each participant party needs a location to store
saving_path_dict = {
# in production we may use remote oss, for example.
device: "./" + device.party
for device in v_data.partitions.keys()
}
r = model.save_model(saving_path_dict) # Save model
wait(r)
#Loading models
# alice is our label holder
model_loaded = load_model(saving_path_dict, alice)
fed_yhat_loaded = model_loaded.predict(v_data, alice)
yhat_loaded = reveal(fed_yhat_loaded.partitions[alice])
assert (
yhat == yhat_loaded
).all(), "loaded model predictions should match original, yhat {} vs yhat_loaded {}".format(
yhat, yhat_loaded
)4. 算法对比
| SS-XGB | SGB | |
| 准备设备和数据 |
|
|
| 设置训练参数 |
|
|
| 模型产出:评估和保存 |
|
|
5. 小结
本篇讲解了决策树模型,例举了SS-XGB和SGB的应用实例,以及对这两种算法在设备准备和数据、训练参数设置以及模型评估和保存角度进行了对比。
(PS:感谢您看到这里!您的支持是我更新的最大动力)















 277
277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









