







隐语第6课,开始介绍具体的机器学习算法以及使用隐语模型进行真实数据的建模实验。

首先介绍广义线性模型,广义线性模型(GLM)是线性模型的扩展,通过联系函数建立响应变量的数学期望值与线性组合的预测变量之间的关系。它的特点是不强行改变数据的自然度量,数据可以具有非线性和非恒定方差结构。是线性模型在研究响应值的非正态分布以及非线性模型简洁直接的线性转化时的一种发展。

具体的,是引入了关于使用广义线性模型对风险保费预测的任务。风险保费的分布,比如车险,呈现的分布往往是大部分车险基本上索赔额为0,少部分的索赔额较高,满足tweedie分布的形态。Tweedie分布是一种泊松分布和伽马分布的复合分布,最明显的一个特点是以一定的概率生成数值为0的样本。Tweedie分布函数是一种广义线性模型中使用的概率分布函数,常用于处理具有过度离散和多度连续的非负连续数据。
使用GLM建模,既可以直接对纯保费建模(tweedie分布),也可以通过两步建模进行间接近似,纯保费=索赔次数 * 平均索赔金额。索赔次数一般满足泊松分布、负二项分布。平均索赔金额才一般服从伽马分布、逆高斯分布。


由于是对纯保费的预测,所以涉及GLM线性回归模型。线性回归假设响应变量y的条件分布为高斯分布,意味着在给定输入变量X的情况下,响应变量y的取值是符合正态分布的。具体来说,这一假设包含以下几个方面:
1. 线性关系:响应变量 y 和输入变量 X 之间存在线性关系。即 y 可以表示为:
![]()
2. 误差项分布:误差项 ϵ服从均值为0,方差为 的正态分布,即 ϵ∼N(0,
)。
3. 条件分布:因此,在给定输入变量 X 的情况下,响应变量 y 的条件分布也是正态分布,即:
![]()
换句话说,对于任意给定的 X,y 的取值在均值 周围按正态分布分布,且方差为
。
如何理解呢,可以从以下几个方面进行解释:
-
均值与回归直线:线性回归模型中的回归直线(或回归平面)表示了在不同的输入变量 X 条件下,响应变量 y 的期望值(均值)。即
。
-
方差与误差:对于每一个给定的 X,响应变量 y 并不是总是精确地等于回归直线的预测值,而是围绕这个预测值上下波动。这种波动由误差项 ϵ 描述,它服从均值为0的正态分布。由于误差项 ϵ 的方差为
,因此响应变量 y 在回归直线附近按照正态分布散布。
-
图形解释:如果我们画出响应变量 y和输入变量 X 的散点图,并拟合一条回归直线,那么在这条直线的每一个点上,响应变量 y 的实际值会在该点的上下呈正态分布。这种分布的中心是回归直线的预测值,分布的扩展范围由方差
广义线性模型中引入了连接函数(Link Function)来处理不同类型的响应变量(因变量),使得模型能够处理二元数据、计数数据等非正态分布的数据。
广义线性模型由三个主要部分组成:
-
随机分布(Random Component):响应变量 Y 的分布,通常属于指数族分布(如正态分布、二项分布、泊松分布等)。
-
系统成分(Systematic Component):解释变量 X 的线性组合,即 η=Xβ,其中 η 称为线性预测子(linear predictor)。
-
连接函数(Link Function):连接线性预测子 η 和响应变量 Y 的期望值之间的关系。连接函数 g(⋅) 满足 g(μ)=η,其中 μ是响应变量的期望值,即 E(Y)=μ。

关于常见的连接函数,比如逻辑函数(Logit Link Function)常用于二项回归模型(如逻辑回归),适用于二元数据(0/1)。对数函数(Log Link Function)常用于泊松回归模型,适用于计数数据。

对于广义线性模型的优化器,隐语采用了二阶(IRLS)和一阶(SGD)的结合使用。一阶(SGD)计算简单速度快,而二阶的优势(初始化准确、收敛速度快),二阶的缺点是通信复杂度、计算复杂度都较高。因此隐语采用前几轮使用二阶优化器进行学习,而之后采用一阶优化器计算。
IRLS 优势
-
收敛速度:IRLS通常在少数几次迭代后就能快速收敛,特别适用于样本量较大时。它在许多实际问题中表现出良好的收敛性。
-
简单易行:IRLS的实现相对简单,基于最小二乘法的迭代加权更新,易于理解和实现。
-
鲁棒性:IRLS在处理某些类型的响应变量(如二项分布、泊松分布等)时表现良好,特别适用于这些分布的特定性质。
-
广泛适用性:IRLS不仅适用于广义线性回归模型,也可以用于其他一些需要迭代加权的统计模型。
除了IRLS,拟牛顿法(Quasi-Newton Methods)也是经常被使用的二阶优化器。L-BFGS(Limited-memory BFGS):适用于大规模问题的BFGS变种,利用有限内存近似海森矩阵。


隐语的GLM是基于秘密共享mpc协议实现的,计算的算子基本都可以化简为加法和乘法,因此列举了这两类算子的秘密贡献计算逻辑,加法比较容易理解,乘法需要借助beaver三元组辅助实现。

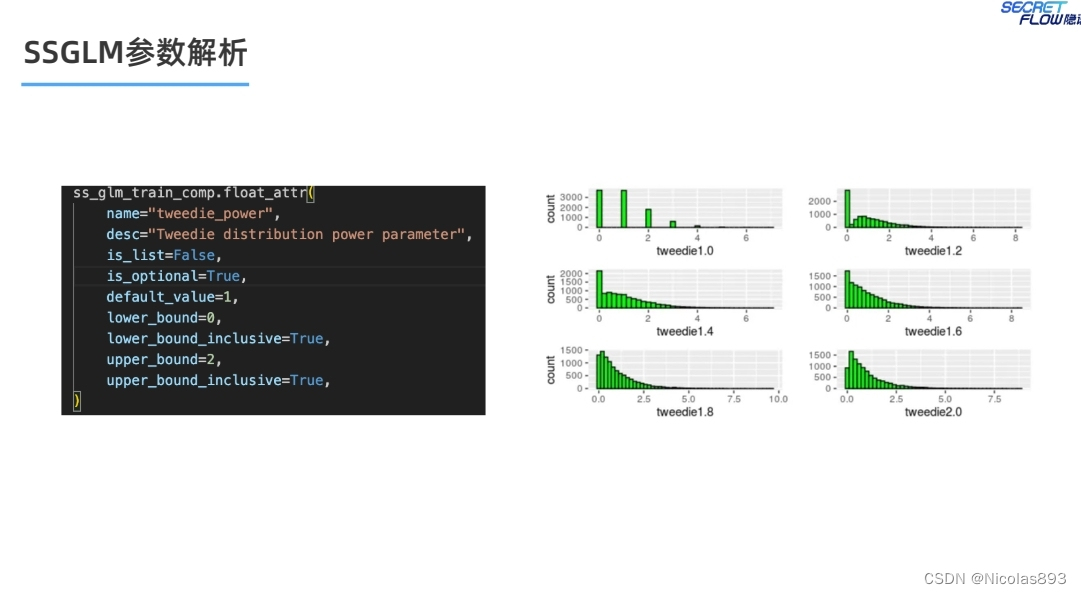
关于GLM的一些常见参数设置,包括标签分布、连接函数,对于tweedie分布,需要设置tweedie power参数,这个参数决定了响应变量的分布类型。因为不能很明确设置,一般还是需要多次实验进行尝试,找到一个最佳的设置参数。
Tweedie Power p值及其对应的分布
Tweedie power p的值决定了GLM中的响应变量分布类型。不同的 p 值对应不同的分布类型:
- p=0:正态分布(Normal distribution)
- p=1:泊松分布(Poisson distribution)
- 1<p<2:混合泊松-伽马分布(Compound Poisson-Gamma distribution)
- p=2:伽马分布(Gamma distribution)
- p=3:逆高斯分布(Inverse Gaussian distribution)
选择适当的 p 值
选择适当的 p 值通常依赖于对数据的理解和分布的类型。以下是一些常见的应用场景和对应的 p 值:
- 正态分布(p=0):用于连续且分布对称的数据,如测量误差。
- 泊松分布(p=1):用于计数数据,如事件发生次数。
- 混合泊松-伽马分布(1<p<2):用于存在零值和正值混合的连续数据,如保险索赔数据。
- 伽马分布(p=2):用于正的连续数据,如响应时间、保险赔付金额。
- 逆高斯分布(p=3):用于正的连续数据,常用于建模重尾数据。
在隐语的保费建模场景,p值在1.9表现较好。


优化器选择二阶和一阶混合使用,前几轮使用IRLS。
以下展示了在隐语中使用SSLR和SSGLM的使用示例,接下来在secret note中实际建模尝试一下。


隐语给出的优势项:采用mpc实现确保模型的可证安全,不依赖可信第三方,支持多种模型,计算高效。不过对于大规模数据,在带宽受限的场景下,ss类的模型,性能还是可能难以满足实际业务需求,需要做很多的优化和提升才行。

接下来,针对具体的问题,进行实际建模体验。

使用 sklearn 训练模型
使用 sf ss glm 复现 sklearn 的`教程 <Tweedie regression on insurance claims — scikit-learn 1.5.0 documentation>`__ 中关于保险索赔的同一实验。
首先需要下载mtpl2数据集,另外还有设置一些辅助函数
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from functools import partial
from sklearn.datasets import fetch_openml
from sklearn.metrics import (
mean_absolute_error,
mean_squared_error,
mean_tweedie_deviance,
)
def load_mtpl2(n_samples=None):
"""获取法国机动车第三方责任保险索赔数据集。
参数
----------
n_samples: int, 默认值=None
要选择的样本数量(为了更快的运行时间)。完整数据集有 678013 个样本。
"""
# 从 https://www.openml.org/d/41214 获取 freMTPL2freq 数据集
df_freq = fetch_openml(data_id=41214, as_frame=True).data
df_freq["IDpol"] = df_freq["IDpol"].astype(int)
df_freq.set_index("IDpol", inplace=True)
# 从 https://www.openml.org/d/41215 获取 freMTPL2sev 数据集
df_sev = fetch_openml(data_id=41215, as_frame=True).data
# 按照相同的 ID 累计索赔金额
df_sev = df_sev.groupby("IDpol").sum()
df = df_freq.join(df_sev, how="left")
df["ClaimAmount"].fillna(0, inplace=True)
# 去掉字符串字段的引号
for column_name in df.columns[df.dtypes.values == object]:
df[column_name] = df[column_name].str.strip("'")
return df.iloc[:n_samples]
def plot_obs_pred(
df,
feature,
weight,
observed,
predicted,
y_label=None,
title=None,
ax=None,
fill_legend=False,
):
"""绘制观察值和预测值 - 按特征级别聚合。
参数
----------
df : DataFrame
输入数据
feature: str
要绘制的特征列名
weight : str
df 中权重或曝光量的列名
observed : str
df 中观察目标的列名
predicted : DataFrame
具有与 df 相同索引的预测目标数据框
fill_legend : bool, 默认值=False
是否显示填充区域的图例
"""
# 按特征级别聚合观察变量和预测变量
df_ = df.loc[:, [feature, weight]].copy()
df_["observed"] = df[observed] * df[weight]
df_["predicted"] = predicted * df[weight]
df_ = (
df_.groupby([feature])[[weight, "observed", "predicted"]]
.sum()
.assign(observed=lambda x: x["observed"] / x[weight])
.assign(predicted=lambda x: x["predicted"] / x[weight])
)
ax = df_.loc[:, ["observed", "predicted"]].plot(style=".", ax=ax)
y_max = df_.loc[:, ["observed", "predicted"]].values.max() * 0.8
p2 = ax.fill_between(
df_.index,
0,
y_max * df_[weight] / df_[weight].values.max(),
color="g",
alpha=0.1,
)
if fill_legend:
ax.legend([p2], ["{} distribution".format(feature)])
ax.set(
ylabel=y_label if y_label is not None else None,
title=title if title is not None else "Train: Observed vs Predicted",
)
def score_estimator(
estimator,
X_train,
X_test,
df_train,
df_test,
target,
weights,
tweedie_powers=None,
):
"""使用不同的指标评估估计器在训练集和测试集上的表现"""
metrics = [
("D² explained", None), # 如果存在,使用默认评分器
("mean abs. error", mean_absolute_error),
("mean squared error", mean_squared_error),
]
if tweedie_powers:
metrics += [
(
"mean Tweedie dev p={:.4f}".format(power),
partial(mean_tweedie_deviance, power=power),
)
for power in tweedie_powers
]
res = []
for subset_label, X, df in [
("train", X_train, df_train),
("test", X_test, df_test),
]:
y, _weights = df[target], df[weights]
for score_label, metric in metrics:
if isinstance(estimator, tuple) and len(estimator) == 2:
# 对由频率模型和严重性模型乘积组成的模型进行评分
est_freq, est_sev = estimator
y_pred = est_freq.predict(X) * est_sev.predict(X)
else:
y_pred = estimator.predict(X)
if metric is None:
if not hasattr(estimator, "score"):
continue
score = estimator.score(X, y, sample_weight=_weights)
else:
score = metric(y, y_pred, sample_weight=_weights)
res.append({"subset": subset_label, "metric": score_label, "score": score})
res = (
pd.DataFrame(res)
.set_index(["metric", "subset"])
.score.unstack(-1)
.round(4)
.loc[:, ["train", "test"]]
)
return res
对数据进行一些预处理,包括一些异常值、离散值的onehot编码、纯保费字段的构建等。
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import (
FunctionTransformer,
KBinsDiscretizer,
OneHotEncoder,
StandardScaler,
)
df = load_mtpl2()
# 注意:过滤掉索赔金额为零的索赔,因为严重性模型需要严格正值的目标值。
df.loc[(df["ClaimAmount"] == 0) & (df["ClaimNb"] >= 1), "ClaimNb"] = 0
# 修正不合理的观测值(可能是数据错误)和一些异常大的索赔金额
df["ClaimNb"] = df["ClaimNb"].clip(upper=4)
df["Exposure"] = df["Exposure"].clip(upper=1)
df["ClaimAmount"] = df["ClaimAmount"].clip(upper=200000)
log_scale_transformer = make_pipeline(
FunctionTransformer(func=np.log), StandardScaler()
)
column_trans = ColumnTransformer(
[
(
"binned_numeric",
KBinsDiscretizer(n_bins=10, subsample=int(2e5), random_state=0),
["VehAge", "DrivAge"],
),
(
"onehot_categorical",
OneHotEncoder(),
["VehBrand", "VehPower", "VehGas", "Region", "Area"],
),
("passthrough_numeric", "passthrough", ["BonusMalus"]),
("log_scaled_numeric", log_scale_transformer, ["Density"]),
],
remainder="drop",
)
X = column_trans.fit_transform(df)
# 保险公司对纯保费的建模感兴趣,即每个保单持有人的单位曝光量预期总索赔金额:
df["PurePremium"] = df["ClaimAmount"] / df["Exposure"]
# 这可以通过两步建模间接近似:频率与每次索赔的平均索赔金额的乘积:
df["Frequency"] = df["ClaimNb"] / df["Exposure"]
df["AvgClaimAmount"] = df["ClaimAmount"] / np.fmax(df["ClaimNb"], 1)
with pd.option_context("display.max_columns", 15):
print(df[df.ClaimAmount > 0].head())按sklearn默认的比例拆分训练集和测试集
from sklearn.model_selection import train_test_split
df_train, df_test, X_train, X_test = train_test_split(df, X, random_state=0)明文sklearn模型训练
from sklearn.linear_model import TweedieRegressor
# 创建 Tweedie 回归模型,用于预测纯保费
# power 参数指定 Tweedie 分布的指数(1.9 介于泊松分布和伽马分布之间)
# alpha 是正则化强度,solver 是求解器类型
glm_pure_premium = TweedieRegressor(power=1.9, alpha=0.1, solver='newton-cholesky')
# 使用训练集数据训练模型
# X_train 是特征矩阵,df_train["PurePremium"] 是目标变量(纯保费)
# sample_weight 参数指定每个样本的权重,这里使用的是曝光量
glm_pure_premium.fit(
X_train, df_train["PurePremium"], sample_weight=df_train["Exposure"]
)
# 定义不同的 Tweedie power 值,用于评估模型
tweedie_powers = [1.5, 1.7, 1.8, 1.9, 1.99, 1.999, 1.9999]
# 评估 Tweedie 回归模型在训练集和测试集上的表现
# 使用不同的评估指标,包括 Tweedie deviance
scores_glm_pure_premium = score_estimator(
glm_pure_premium,
X_train,
X_test,
df_train,
df_test,
target="PurePremium",
weights="Exposure",
tweedie_powers=tweedie_powers,
)
# 将评估结果合并为一个 DataFrame
scores = pd.concat(
[scores_glm_pure_premium],
axis=1,
sort=True,
keys=("TweedieRegressor"),
)
# 打印模型评估结果
print("Evaluation of the Product Model and the Tweedie Regressor on target PurePremium")
with pd.option_context("display.expand_frame_repr", False):
print(scores)

接下来我们构建ss_glm模型
首先获取明文模型的迭代参数
n_iter = glm_pure_premium.n_iter_初始化spu,这里选择REF2K,是隐语提供的明文mpc协议,做展示用。使用semi2k会比较耗内存和计算时间。
import secretflow as sf
# 检查 SecretFlow 的版本
print('SecretFlow 的版本: {}'.format(sf.__version__))
# 如果已经有一个正在运行的 secretflow 运行时,先关闭它。
sf.shutdown()
# 初始化 SecretFlow 环境,指定参与方和地址
sf.init(['alice', 'bob'], address='local')
# 定义参与方
alice, bob = sf.PYU('alice'), sf.PYU('bob')
# 配置和初始化 SPU(安全多方计算单元)
spu = sf.SPU(
sf.utils.testing.cluster_def(
['alice', 'bob'],
{"protocol": "REF2K", "field": "FM128", "fxp_fraction_bits": 40},
),
)

特征进行纵向切分,在alice侧初始化sample weight,使用的是曝光度。
from secretflow.data import FedNdarray, PartitionWay
# 定义输入数据 x, y, w
x, y = X_train, df_train["PurePremium"]
w = df_train["Exposure"]
# 将稀疏矩阵 x 转换为分布式数据对象 v_data
def x_to_vdata(x):
# 将稀疏矩阵转换为密集矩阵
x = x.todense()
# 创建分布式数据对象 FedNdarray,使用垂直分区方式
v_data = FedNdarray(
partitions={
alice: alice(lambda: x[:, :15])(), # Alice 获取前 15 列
bob: bob(lambda: x[:, 15:])(), # Bob 获取后 15 列
},
partition_way=PartitionWay.VERTICAL,
)
return v_data
v_data = x_to_vdata(x)
# 将标签 y 转换为分布式数据对象 label_data
label_data = FedNdarray(
partitions={alice: alice(lambda: y.values)()}, # Alice 持有 y 的所有值
partition_way=PartitionWay.VERTICAL,
)
# 将样本权重 w 转换为分布式数据对象 sample_weight
sample_weight = FedNdarray(
partitions={alice: alice(lambda: w.values)()}, # Alice 持有 w 的所有值
partition_way=PartitionWay.VERTICAL,
)
定义模型的框架,后续会将定义的ss-glm嵌入。
from secretflow.device.driver import reveal
from secretflow.ml.linear.ss_glm.core import get_dist
dist = 'Tweedie' # 设定分布类型为 Tweedie
ss_glm_power = 1.9 # 设定 SS GLM 模型的 power 参数为 1.9
class DirectRevealModel:
def __init__(self, model) -> None:
self.model = model
def predict(self, X):
# 将输入数据 X 转换为分布式数据对象 vdata
vdata = x_to_vdata(X)
# 使用模型预测 vdata
y = self.model.predict(vdata)
# 对预测结果进行解密和重塑
return reveal(y).reshape((-1,))
def score(self, X, y, sample_weight=None):
y = y.values # 获取目标变量的值
y_pred = self.predict(X) # 使用模型预测 X
# 计算常数项
constant = np.mean(y)
if sample_weight is not None:
constant *= sample_weight.shape[0] / np.sum(sample_weight)
# 计算偏差(deviance)
# 在 deviance 计算中缺少的因子 2 将被抵消。
deviance = get_dist(dist, 1, ss_glm_power).deviance(y_pred, y, None)
deviance_null = get_dist(dist, 1, ss_glm_power).deviance(
np.average(y, weights=sample_weight) + np.zeros(y.shape), y, None
)
# 返回评分结果,评分公式如下
return 1 - (deviance + constant) / (deviance_null + constant)
import time
from secretflow.ml.linear.ss_glm import SSGLM
model = SSGLM(spu)
ss_glm_power = 1.9
start = time.time()
model.fit_irls(
v_data,
label_data,
None,
sample_weight,
n_iter,
'Log',
'Tweedie',
ss_glm_power,
l2_lambda=0.1,
infeed_batch_size_limit=10000000,
fraction_of_validation_set=0.2,
stopping_rounds=2,
stopping_metric='deviance',
stopping_tolerance=0.001,
)
wrapped_model = DirectRevealModel(model)
tweedie_powers = [1.5, 1.7, 1.8, 1.9, 1.99, 1.999, 1.9999]
scores_ss_glm_pure_premium = score_estimator(
wrapped_model,
X_train,
X_test,
df_train,
df_test,
target="PurePremium",
weights="Exposure",
tweedie_powers=tweedie_powers,
)
scores = pd.concat(
[scores_glm_pure_premium, scores_ss_glm_pure_premium],
axis=1,
sort=True,
keys=("TweedieRegressor", "SSGLMRegressor"),
)
print("Evaluation of the Tweedie Regressor and SS GLM on target PurePremium")
with pd.option_context("display.expand_frame_repr", False):
print(scores)这一步fit比较慢,实际跑下来大概花了24分钟,而且还只是用了明文的2k协议,要是semi2k估计还要慢个好几倍吧。

明文模型与密文模型预测值对比
res = []
for subset_label, x, df in [
("train", X_train, df_train),
("test", X_test, df_test),
]:
exposure = df["Exposure"].values
res.append(
{
"subset": subset_label,
"observed": df["ClaimAmount"].values.sum(),
"predicted, tweedie, power=%.2f"
% glm_pure_premium.power: np.sum(exposure * glm_pure_premium.predict(x)),
"predicted, ss glm, power=%.2f"
% ss_glm_power: np.sum(exposure * wrapped_model.predict(x)),
}
)
print(pd.DataFrame(res).set_index("subset").T)
看这个结果,明密文模型差距还是比较大的,估计还是需要调参,使用更合适的协议?
另外,使用lorenz_curve分析了模型预测结果的数值分布与真实数据的分布一致性,还是可以的。
from sklearn.metrics import auc
def lorenz_curve(y_true, y_pred, exposure):
y_true, y_pred = np.asarray(y_true), np.asarray(y_pred)
exposure = np.asarray(exposure)
# 按预测风险增序排列样本:
ranking = np.argsort(y_pred)
ranked_exposure = exposure[ranking]
ranked_pure_premium = y_true[ranking]
cumulated_claim_amount = np.cumsum(ranked_pure_premium * ranked_exposure)
cumulated_claim_amount /= cumulated_claim_amount[-1]
cumulated_samples = np.linspace(0, 1, len(cumulated_claim_amount))
return cumulated_samples, cumulated_claim_amount
fig, ax = plt.subplots(figsize=(8, 8))
y_pred_total_ss_glm = wrapped_model.predict(X_test).reshape((-1,))
y_pred_total = glm_pure_premium.predict(X_test)
for label, y_pred in [
("Compound Poisson Gamma", y_pred_total),
("Compound Poisson Gamma SS GLM", y_pred_total_ss_glm),
]:
ordered_samples, cum_claims = lorenz_curve(
df_test["PurePremium"], y_pred, df_test["Exposure"]
)
gini = 1 - 2 * auc(ordered_samples, cum_claims)
label += " (基尼指数: {:.3f})".format(gini)
ax.plot(ordered_samples, cum_claims, linestyle="-", label=label)
# Oracle 模型:y_pred == y_test
ordered_samples, cum_claims = lorenz_curve(
df_test["PurePremium"], df_test["PurePremium"], df_test["Exposure"]
)
gini = 1 - 2 * auc(ordered_samples, cum_claims)
label = "Oracle (基尼指数: {:.3f})".format(gini)
ax.plot(ordered_samples, cum_claims, linestyle="-.", color="gray", label=label)
# 随机基准线
ax.plot([0, 1], [0, 1], linestyle="--", color="black", label="随机基准线")
ax.set(
title="洛伦兹曲线",
xlabel="保单持有人的比例\n(按照模型从最安全到最风险排序)",
ylabel="总赔付金额的比例",
)
ax.legend(loc="upper left")
plt.plot()
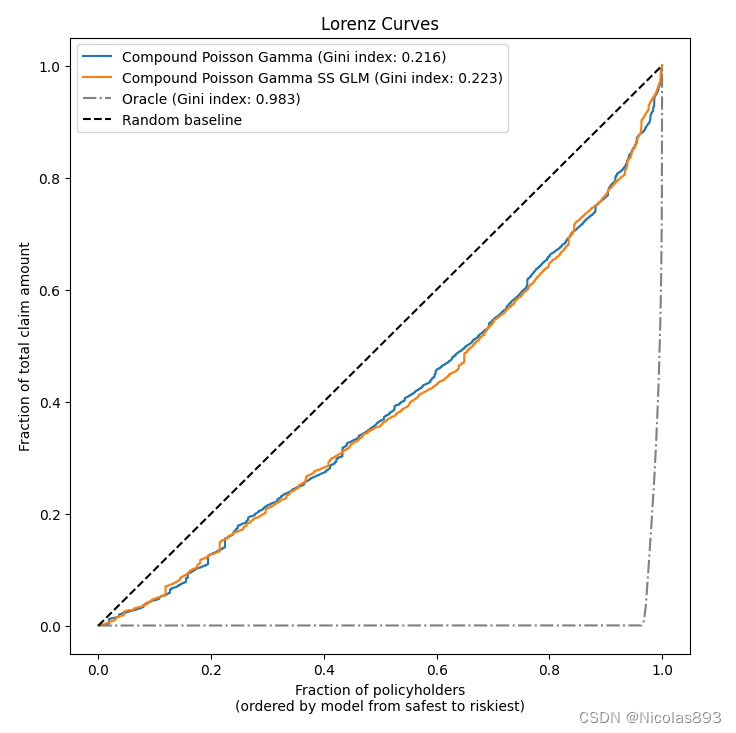
需要说明的是,洛伦兹曲线本身并不直接用于评判模型预测结果的正确性或准确性。洛伦兹曲线主要用于展示数据分布的不平等程度或者集中程度。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











