







检索目录
本节参考官方文档在标准数据集上训练预定义的模型
在上次发布的从深度学习目标检测新手视角安装MMDetection到使用公开数据集进行模型测试中,我们已经学习到如何部署安装MMDetection以及如何利用公开数据集测试被训练好的现有模型。MMDetection也为训练检测模型提供了开盖即食的工具。本节将讨论在标准数据集(比如 COCO)上如何训练一个预定义的模型。
深度学习模型训练过程中预训练和微调的区别
微调(Fine-tuning)和预训练(Pre-training)是机器学习特别是深度学习领域中两种重要的训练策略,它们主要应用于诸如自然语言处理(NLP)和计算机视觉(CV)等领域的大规模模型训练过程。以下是两者的主要区别:
预训练(Pre-training):
- 目标:预训练模型的目标是利用大规模未标注数据学习底层的语言或视觉特征表示,这些特征具有普适性和迁移性。
- 数据集:通常使用大规模的无标签文本数据集(如对于NLP)或大量未标记的图片(如对于CV)进行训练。
- 过程:通过自监督或自我预测任务(如掩码语言模型、对比学习等)训练模型,使其捕获普遍的模式、语法结构和语义特征。
- 结果:预训练产生的模型可以作为一个通用的语言模型(如BERT、GPT系列)或特征提取器(如在CV中的预训练卷积神经网络),为后续任务提供初始化参数。
微调(Fine-tuning):
- 目标:微调是为了将预训练模型应用于特定下游任务,如情感分析、问答系统、目标检测等,通过调整模型参数使其更适合特定任务的需求。
- 数据集:使用相对较小但具有标签的特定任务数据集进行训练,这些数据集与预训练任务的数据分布可能有所不同。
- 过程:在预训练模型的基础上,保留大部分原有参数的同时,对模型的顶层或其他部分参数进行额外训练,有时也会对模型结构进行针对性修改,如添加任务相关的输出层或调整网络结构。
- 结果:经过微调后的模型在特定任务上的性能显著提升,因为它能够结合预训练学到的通用知识与针对特定任务的学习成果。
总的来说,预训练模型着重于学习通用特征表示,而微调则是在预训练模型基础上针对具体应用场景进行优化和个性化调整的过程。通过这种方式,可以有效利用有限的标注数据,同时充分利用大规模无标注数据带来的优势。
接上一个帖子,在做instance实例分割任务的时候选用了QueryInst模型,因此本节继续用该配置文件利用QueryInst模型和COCO2014数据集训练出自己的模型权重文件(checkpoint),本次涉及到的配置文件位于:mmdetection/configs/queryinst/queryinst_r50_fpn_1x_coco.py
queryinst_r50_fpn_1x_coco.py中的顶端代码:
base_ = [
'../_base_/datasets/coco_instance.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
对应mmdetection/configs/_base_/datasets/coco_instance.py中的顶端代码:
# dataset settings
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
data_root指向的文件目录下的COCO数据集格式配置请参考上一节
配置文件命名规则
queryinst_r50_fpn_1x_coco.py 这个Python文件的命名遵循了一套既定的规则,它是用来配置QueryInst模型在COCO数据集上进行训练和推理的配置文件。让我们逐一分解各个部分:
1. queryinst: 这部分表示所使用的模型架构是 QueryInst。QueryInst是一种基于Query-based的方法,通常用于实例分割任务,尤其是像Detectron2这样的开源项目中提出的端到端实例分割框架。
2. _r50: 后缀表明所使用的主干网络(Backbone)是 ResNet-50。ResNet-50是一个深度残差网络,因其在计算机视觉任务中的优秀表现和合理的计算复杂度而被广泛应用。
3. _fpn: 这里指的是使用了 Feature Pyramid Network (FPN) 结构。FPN是一种多尺度特征融合结构,允许模型在多个尺度上进行预测,从而提高了对不同大小物体的检测和分割性能。
4. 1x: 此处类似于之前提到的"Faster R-CNN"配置文件中的1x,同样表示模型的训练策略或者训练速度缩放因子。在相关研究和实践场景中,“1x”通常指代一个基准或标准的训练方案,包括训练周期、学习率策略等,相较于更激进的训练设置(比如“2x”或“3x”),它可能采用了更为保守的训练参数。
5. _coco: 最后的部分标识了模型将要训练和评估的 数据集,这里是 COCO(Common Objects in Context) 数据集。COCO是一个大规模的物体检测、分割和姿态估计数据集,包含了丰富的日常场景中的物体类别和实例。
总结起来,queryinst_r50_fpn_1x_coco.py 文件名指示了这是一个专为在COCO数据集上训练和测试基于ResNet-50主干网络和FPN结构的QueryInst实例分割模型,并遵循一个相对标准训练流程的配置文件。这种命名方式符合开放源代码库中常见的命名规范,便于开发者和研究人员根据模型结构、主干网络、训练策略以及数据集迅速识别和定位所需的配置文件。
在多 GPU 上训练
官方提供了 tools/dist_train.sh 来开启在多 GPU 上的训练。基本使用如下:
bash ./tools/dist_train.sh \
${CONFIG_FILE} \
${GPU_NUM} \
[optional arguments]
在训练期间,日志文件和 checkpoint 文件将会被保存在工作目录下,它需要通过配置文件中的 work_dir 或者 CLI 参数中的 --work-dir 来指定。
这个工具接受以下参数:
- –work-dir ${WORK_DIR}: 覆盖工作目录.
- –resume:自动从work_dir中的最新检查点恢复.
- –resume ${CHECKPOINT_FILE}: 从某个 checkpoint 文件继续训练.
- –cfg-options ‘Key=value’: 覆盖使用的配置文件中的其他设置.
同时启动多个任务
如果你想在一台机器上启动多个任务的话,比如在一个有 8 块 GPU 的机器上启动 2 个需要 4 块GPU的任务,你需要给不同的训练任务指定不同的端口(默认为 29500)来避免冲突。
如果你使用 dist_train.sh 来启动训练任务,你可以使用命令来设置端口。
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG_FILE} 4
CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG_FILE} 4
样例
我根据nvitop监视到的实验室服务器GPU空闲情况,指定了三块GPU(位置0,1,9)进行多GPU训练
CUDA_VISIBLE_DEVICES=0,1,9 ./tools/dist_train.sh \
configs/queryinst/queryinst_r50_fpn_1x_coco.py \
3
在Terminal键入命令之后即可开始训练,训练过程中会自动根据配置文件从网站上下载所需要的模型权重文件
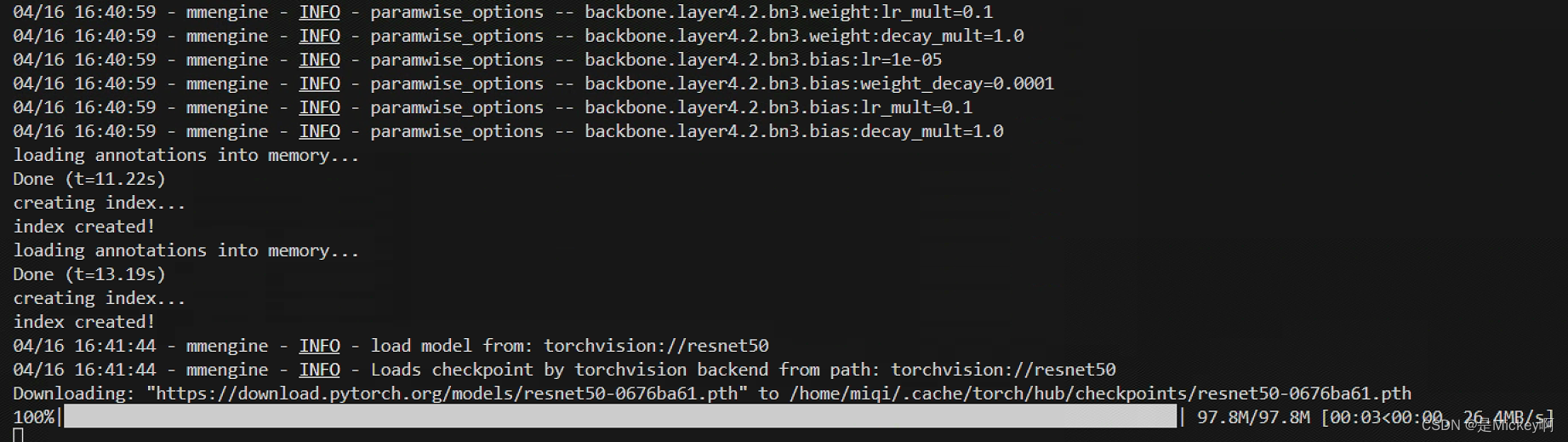
训练工作日志如下,表明QueryInst的模型权重训练正在进行中

训练完成后,训练工作日志和权重文件默认将会位于mmdetection/work_dirs/queryinst_r50_fpn_1x_coco文件夹目录下
关于上述深度学习模型的训练日志。建议大家尽量弄懂关键参数和指标的含义,这可以帮助我们理解模型的训练进度和性能。以下是训练日志中一些主要参数的解释:
-
Epoch: 这表示当前正在进行的训练轮次。在每个epoch中,模型会遍历整个训练数据集一次。 -
[x/total]: 这显示了当前完成的训练批次数和总批次数。例如,“[400/13681]”表示已经完成了400个训练批次,总共将有13681个批次。 -
base lr: 这是基础学习率,它是优化器在当前epoch中使用的初始学习率。 -
et a: 这是剩余时间估计,它显示了模型预计还需要多少时间才能完成训练。例如,“a: 38 days, 4:01:59”表示预计还需要38天4小时零1分59秒。 -
time: 这是完成当前批次训练所需的时间。 -
data time: 这是加载和处理数据所需的时间。 -
memory: 这是当前使用的内存大小。 -
grad norm: 这是梯度的范数,它衡量了梯度的大小。在某些优化算法中,梯度的范数被用来控制梯度更新的幅度。 -
loss: 这是当前批次的损失函数值。损失函数衡量了模型预测与真实标签之间的差异。 -
s0.loss_cls, s0.loss_bbox, s0.loss_iou, s0.loss_mask: 这些是不同类型的损失值,分别对应于分类损失、边界框回归损失、IOU损失和掩模损失。这些损失通常用于衡量模型在不同任务上的表现,例如识别物体类别、定位物体位置、计算对象重叠度以及分割对象。
这些参数提供了关于模型训练过程的详细信息,帮助开发者监控和调整模型的性能。
常用超参数设置路径
学习率(learning rate):优化相关配置
训练轮次(epoch):训练和测试的配置
批大小(batch size):数据集和评测器配置
迭代次数(iteration)= 总工作量 / batch size
多GPU训练时,总的batch size = 被指定的GPU数量 × 单个GPU的batch size
训练过程中出现的问题
1. 服务器异常断联导致训练被迫中断
为了预防此问题出现,我们需要提前在配置文件中配置好mmdetection/configs/_base_/default_runtime.py中default_hooks的checkpoint访问接口,参考 配置文件:钩子(HOOK)摘取2个CheckpointHook常用功能
- 按照间隔保存权重,支持按 epoch 数或者 iteration 数保存权重 假设我们一共训练 20 个 epoch 并希望每隔 5 个
epoch 保存一次权重,下面的配置即可帮我们实现该需求。
# by_epoch 的默认值为 True
default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, by_epoch=True))
- 如果想以迭代次数作为保存间隔,则可以将 by_epoch 设为 False,interval=5 则表示每迭代 5 次保存一次权重。
default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, by_epoch=False))
- 保存最新的多个权重,如果只想保存一定数量的权重,可以通过设置 max_keep_ckpts 参数实现最多保存 max_keep_ckpts个权重,当保存的权重数超过 max_keep_ckpts 时,前面的权重会被删除。
default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, max_keep_ckpts=2))
- 指定保存权重的路径,权重默认保存在工作目录(work_dir),但可以通过设置 out_dir 改变保存路径。
default_hooks = dict(checkpoint=dict(type='CheckpointHook', interval=5, out_dir='/path/of/directory'))
参考我的最终命令:意思是以iteration为单位,间隔100周期,依次产生权重文件,并且只保留最新的2个权重文件
checkpoint=dict(type='CheckpointHook',
interval=100, by_epoch=False, max_keep_ckpts=2,
out_dir='/home/miqi/mmdetection/work_dirs/queryinst_r50_fpn_1x_coco')
此时就可以在训练被迫中断之后加上–resume选项在Terminal再次键入命令,这样训练过程自动从work_dirs中的最新checkpoint(pth文件)恢复,从而不用从头开始训练!下列命令就是我指定从第1000次迭代产生的权重继续训练
CUDA_VISIBLE_DEVICES=0,1,9 ./tools/dist_train.sh \
configs/queryinst/queryinst_r50_fpn_1x_coco.py \
3 \
--resume work_dirs/queryinst_r50_fpn_1x_coco/iter_1000.pth
2. 适当调高训练的batchsize可以提高训练速度
根据训练过程中GPU的UTL实际占用情况,在mmdetection/configs/_base_/datasets/coco_instance.py文件中适当调高train_dataloader的batch_size大小
train_dataloader = dict( # 训练 dataloader 配置
batch_size=2) # 单个 GPU 的 batch size
倘若不自量力调了过高的训练batch_size,会导致训练无法进行或者中途中断
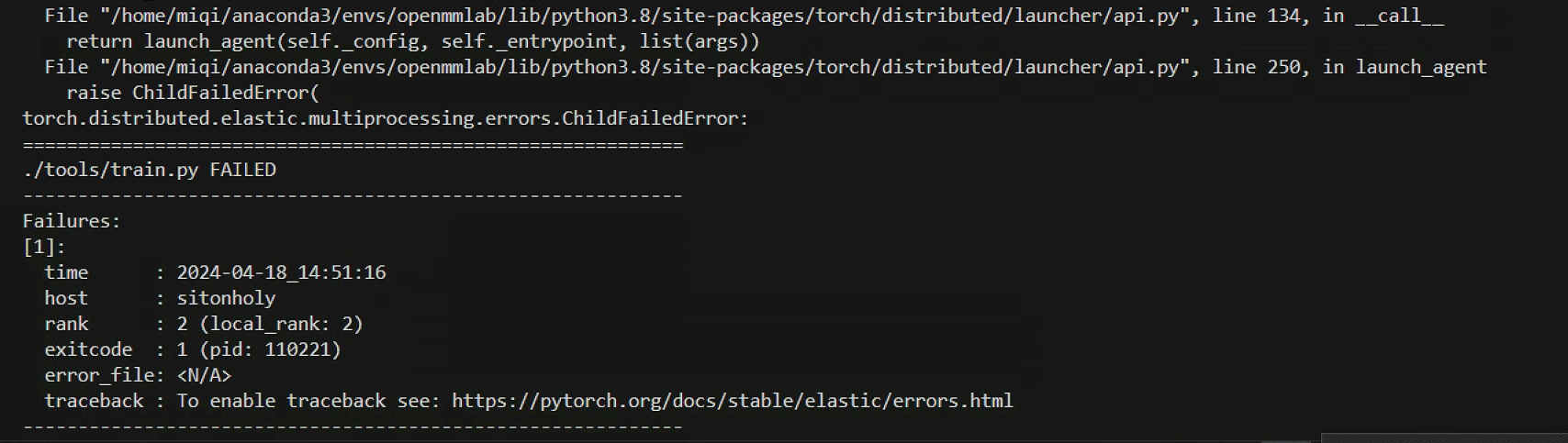
报错
torch.distributed.elastic.multiprocessing.errors.ChildFailedError:
3. 训练异常中断会产生空占用GPU的僵尸进程

报红:
No Such Process
通过kill命令杀掉对应显卡的所有进程,参考如何找到并杀掉占用显存的僵尸进程
# 杀掉 1 号显卡的所有进程
fuser -v /dev/nvidia1 | xargs -t -n 1 kill -9
# 杀掉 2 号显卡的所有进程
fuser -v /dev/nvidia2 | xargs -t -n 1 kill -9















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









