







1. YOLOv12
1.1 相关链接
论文:YOLOv12: Attention-Centric Real-Time Object Detectors
Github:https://github.com/sunsmarterjie/yolov12.git

1.2 论文摘要
YOLOv12是一种基于注意力机制的YOLO框架新版本,旨在解决传统基于卷积神经网络(CNN)的模型在速度和性能之间的权衡问题。尽管注意力机制被证明在建模能力上具有显著优势,但其应用受限于速度不及CNN的问题。YOLOv12通过优化设计,不仅实现了与现有基于CNN的YOLO版本相同的速度,还提升了检测准确性。
具体来说,YOLOv12-N在T4 GPU上的测试显示了40.6%的mAP(mean Average Precision),推理延迟为1.64毫秒,相比之前的YOLOv10-N和YOLOv11-N,在保持相似速度的同时分别提高了2.1%和1.2%的mAP。此外,YOLOv12-S对比RT-DETR-R18和RT-DETRv2-R18等改进自DETR的实时检测器,在速度快42%的情况下,计算量减少至36%,参数使用量减少到45%。因此,YOLOv12在保证高效运行的同时,大幅提升了对象检测任务的准确性和效率。这一进展表明,通过精心设计,可以克服注意力机制固有的速度瓶颈,实现既快又准的实时对象检测。
1.3 在MS COCO数据集上的表现
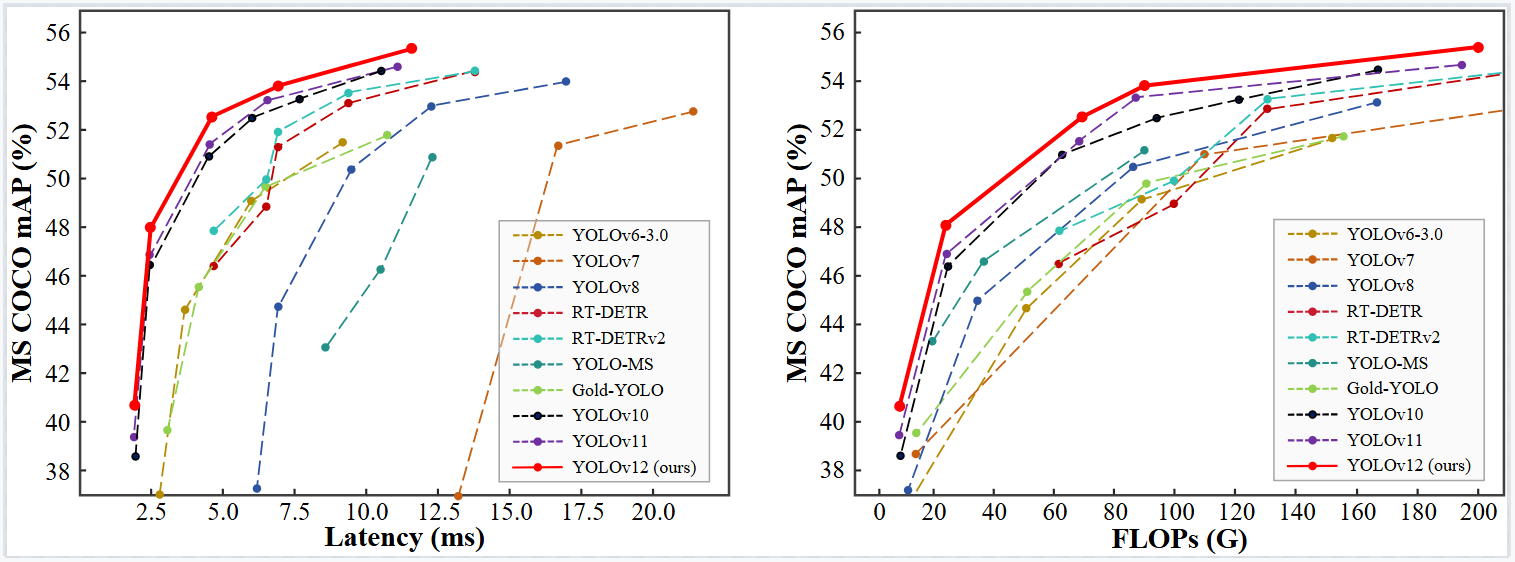
1.4 不同Scale模型的主要结果
| Model | Size (pixels) | mAP val (50-95) | Speed (T4 TensorRT) | Params (M) | FLOPs (G) |
|---|---|---|---|---|---|
| YOLO12n | 640 | 40.6 | 1.64 ms | 2.6 | 6.5 |
| YOLO12s | 640 | 48.0 | 2.61 ms | 9.3 | 21.4 |
| YOLO12m | 640 | 52.5 | 4.86 ms | 20.2 | 67.5 |
| YOLO12l | 640 | 53.7 | 6.77 ms | 26.4 | 88.9 |
| YOLO12x | 640 | 55.2 | 11.79 ms | 59.1 | 199.0 |
2. 创建YOLOv12所需环境依赖
2.1 方式一:官方版本
wget https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.3/flash_attn-2.7.3+cu11torch2.2cxx11abiFALSE-cp311-cp311-linux_x86_64.whl
conda create -n yolov12 python=3.11
conda activate yolov12
pip install -r requirements.txt
pip install -e .
2.2 方式二:我的版本
2.2.1 创建虚拟环境
conda create --name openmmlab python=3.8 -y
conda activate openmmlab # 有的版本要先用source activate XXX激活操作
2.2.2 安装相关模块包
pip install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1 # CUDA 11.7
pip install ultralytics==8.3.63
pip install timm
3. 代码部署
3.1 方式一:官方仓库直接克隆
git clone https://github.com/sunsmarterjie/yolov12.git
3.2 方式二:手动部署
3.2.1 A2C2f模块文件添加
创建文件 ultralytics-8.3.63/ultralytics/nn/modules/A2C2f.py
import torch
import torch.nn as nn
import logging
logger = logging.getLogger(__name__)
USE_FLASH_ATTN = False
try:
import torch
if torch.cuda.is_available() and torch.cuda.get_device_capability()[0] >= 8: # Ampere or newer
from flash_attn.flash_attn_interface import flash_attn_func
USE_FLASH_ATTN = True
else:
from torch.nn.functional import scaled_dot_product_attention as sdpa
logger.warning("FlashAttention is not available on this device. Using scaled_dot_product_attention instead.")
except Exception:
from torch.nn.functional import scaled_dot_product_attention as sdpa
logger.warning("FlashAttention is not available on this device. Using scaled_dot_product_attention instead.")
from timm.models.layers import trunc_normal_
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, bias=False, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=bias)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Apply convolution and activation without batch normalization."""
return self.act(self.conv(x))
class C3(nn.Module):
"""CSP Bottleneck with 3 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""Initialize the CSP Bottleneck with given channels, number, shortcut, groups, and expansion values."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=((1, 1), (3, 3)), e=1.0) for _ in range(n)))
def forward(self, x):
"""Forward pass through the CSP bottleneck with 2 convolutions."""
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class C3k(C3):
"""C3k is a CSP bottleneck module with customizable kernel sizes for feature extraction in neural networks."""
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5, k=3):
"""Initializes the C3k module with specified channels, number of layers, and configurations."""
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
# self.m = nn.Sequential(*(RepBottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, k=(k, k), e=1.0) for _ in range(n)))
class Bottleneck(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a standard bottleneck module with optional shortcut connection and configurable parameters."""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""Applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class AAttn(nn.Module):
"""
Area-attention module with the requirement of flash attention.
Attributes:
dim (int): Number of hidden channels;
num_heads (int): Number of heads into which the attention mechanism is divided;
area (int, optional): Number of areas the feature map is divided. Defaults to 1.
Methods:
forward: Performs a forward process of input tensor and outputs a tensor after the execution of the area attention mechanism.
Examples:
>>> import torch
>>> from ultralytics.nn.modules import AAttn
>>> model = AAttn(dim=64, num_heads=2, area=4)
>>> x = torch.randn(2, 64, 128, 128)
>>> output = model(x)
>>> print(output.shape)
Notes:
recommend that dim//num_heads be a multiple of 32 or 64.
"""
def __init__(self, dim, num_heads, area=1):
"""Initializes the area-attention module, a simple yet efficient attention module for YOLO."""
super().__init__()
self.area = area
self.num_heads = num_heads
self.head_dim = head_dim = dim // num_heads
all_head_dim = head_dim * self.num_heads
self.qkv = Conv(dim, all_head_dim * 3, 1, act=False)
self.proj = Conv(all_head_dim, dim, 1, act=False)
self.pe = Conv(all_head_dim, dim, 7, 1, 3, g=dim, act=False)
def forward(self, x):
"""Processes the input tensor 'x' through the area-attention"""
B, C, H, W = x.shape
N = H * W
qkv = self.qkv(x).flatten(2).transpose(1, 2)
if self.area > 1:
qkv = qkv.reshape(B * self.area, N // self.area, C * 3)
B, N, _ = qkv.shape
q, k, v = qkv.view(B, N, self.num_heads, self.head_dim * 3).split(
[self.head_dim, self.head_dim, self.head_dim], dim=3
)
if x.is_cuda and USE_FLASH_ATTN:
x = flash_attn_func(
q.contiguous().half(),
k.contiguous().half(),
v.contiguous().half()
).to(q.dtype)
elif x.is_cuda and not USE_FLASH_ATTN:
x = sdpa(q.permute(0, 2, 1, 3), k.permute(0, 2, 1, 3), v.permute(0, 2, 1, 3), attn_mask=None, dropout_p=0.0, is_causal=False)
x = x.permute(0, 2, 1, 3)
else:
q = q.permute(0, 2, 3, 1)
k = k.permute(0, 2, 3, 1)
v = v.permute(0, 2, 3, 1)
attn = (q.transpose(-2, -1) @ k) * (self.head_dim ** -0.5)
max_attn = attn.max(dim=-1, keepdim=True).values
exp_attn = torch.exp(attn - max_attn)
attn = exp_attn / exp_attn.sum(dim=-1, keepdim=True)
x = (v @ attn.transpose(-2, -1))
x = x.permute(0, 3, 1, 2)
v = v.permute(0, 3, 1, 2)
if self.area > 1:
x = x.reshape(B // self.area, N * self.area, C)
v = v.reshape(B // self.area, N * self.area, C)
B, N, _ = x.shape
x = x.reshape(B, H, W, C).permute(0, 3, 1, 2)
v = v.reshape(B, H, W, C).permute(0, 3, 1, 2)
x = x + self.pe(v)
x = self.proj(x)
return x
class ABlock(nn.Module):
"""
ABlock class implementing a Area-Attention block with effective feature extraction.
This class encapsulates the functionality for applying multi-head attention with feature map are dividing into areas
and feed-forward neural network layers.
Attributes:
dim (int): Number of hidden channels;
num_heads (int): Number of heads into which the attention mechanism is divided;
mlp_ratio (float, optional): MLP expansion ratio (or MLP hidden dimension ratio). Defaults to 1.2;
area (int, optional): Number of areas the feature map is divided. Defaults to 1.
Methods:
forward: Performs a forward pass through the ABlock, applying area-attention and feed-forward layers.
Examples:
Create a ABlock and perform a forward pass
>>> model = ABlock(dim=64, num_heads=2, mlp_ratio=1.2, area=4)
>>> x = torch.randn(2, 64, 128, 128)
>>> output = model(x)
>>> print(output.shape)
Notes:
recommend that dim//num_heads be a multiple of 32 or 64.
"""
def __init__(self, dim, num_heads, mlp_ratio=1.2, area=1):
"""Initializes the ABlock with area-attention and feed-forward layers for faster feature extraction."""
super().__init__()
self.attn = AAttn(dim, num_heads=num_heads, area=area)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = nn.Sequential(Conv(dim, mlp_hidden_dim, 1), Conv(mlp_hidden_dim, dim, 1, act=False))
self.apply(self._init_weights)
def _init_weights(self, m):
"""Initialize weights using a truncated normal distribution."""
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Conv2d) and m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
"""Executes a forward pass through ABlock, applying area-attention and feed-forward layers to the input tensor."""
x = x + self.attn(x)
x = x + self.mlp(x)
return x
class A2C2f(nn.Module):
"""
A2C2f module with residual enhanced feature extraction using ABlock blocks with area-attention. Also known as R-ELAN
This class extends the C2f module by incorporating ABlock blocks for fast attention mechanisms and feature extraction.
Attributes:
c1 (int): Number of input channels;
c2 (int): Number of output channels;
n (int, optional): Number of 2xABlock modules to stack. Defaults to 1;
a2 (bool, optional): Whether use area-attention. Defaults to True;
area (int, optional): Number of areas the feature map is divided. Defaults to 1;
residual (bool, optional): Whether use the residual (with layer scale). Defaults to False;
mlp_ratio (float, optional): MLP expansion ratio (or MLP hidden dimension ratio). Defaults to 1.2;
e (float, optional): Expansion ratio for R-ELAN modules. Defaults to 0.5;
g (int, optional): Number of groups for grouped convolution. Defaults to 1;
shortcut (bool, optional): Whether to use shortcut connection. Defaults to True;
Methods:
forward: Performs a forward pass through the A2C2f module.
Examples:
>>> import torch
>>> from ultralytics.nn.modules import A2C2f
>>> model = A2C2f(c1=64, c2=64, n=2, a2=True, area=4, residual=True, e=0.5)
>>> x = torch.randn(2, 64, 128, 128)
>>> output = model(x)
>>> print(output.shape)
"""
def __init__(self, c1, c2, n=1, a2=True, area=1, residual=False, mlp_ratio=2.0, e=0.5, g=1, shortcut=True):
super().__init__()
c_ = int(c2 * e) # hidden channels
assert c_ % 32 == 0, "Dimension of ABlock be a multiple of 32."
# num_heads = c_ // 64 if c_ // 64 >= 2 else c_ // 32
num_heads = c_ // 32
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv((1 + n) * c_, c2, 1) # optional act=FReLU(c2)
init_values = 0.01 # or smaller
self.gamma = nn.Parameter(init_values * torch.ones((c2)), requires_grad=True) if a2 and residual else None
self.m = nn.ModuleList(
nn.Sequential(*(ABlock(c_, num_heads, mlp_ratio, area) for _ in range(2))) if a2 else C3k(c_, c_, 2, shortcut, g) for _ in range(n)
)
def forward(self, x):
"""Forward pass through R-ELAN layer."""
y = [self.cv1(x)]
y.extend(m(y[-1]) for m in self.m)
if self.gamma is not None:
return x + self.gamma.view(1, -1, 1, 1) * self.cv2(torch.cat(y, 1))
return self.cv2(torch.cat(y, 1))
3.2.2 模块部署
在 ultralytics-8.3.63/ultralytics/nn/tasks.py 添加如下代码
3.2.2.1 第一处:导包
from ultralytics.nn.modules.A2C2f import A2C2f
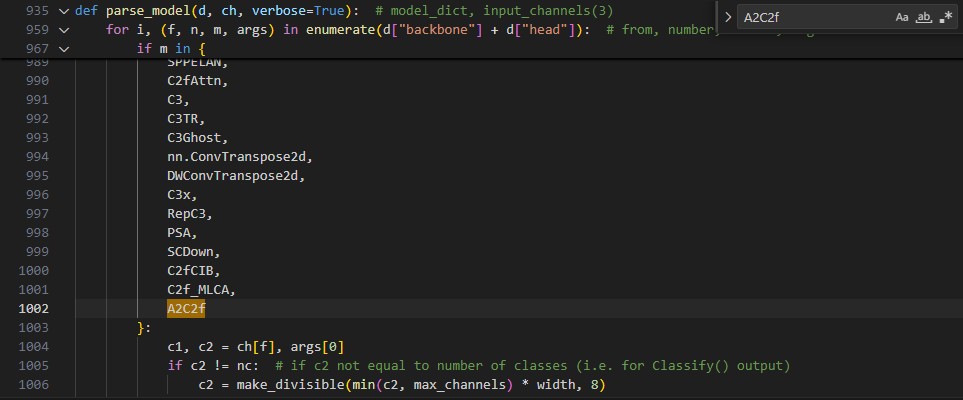
3.2.2.2 第二处:定位 c1, c2 = ch[f], args[0]
3.2.2.3 第三处:定位 args.insert(2, n)
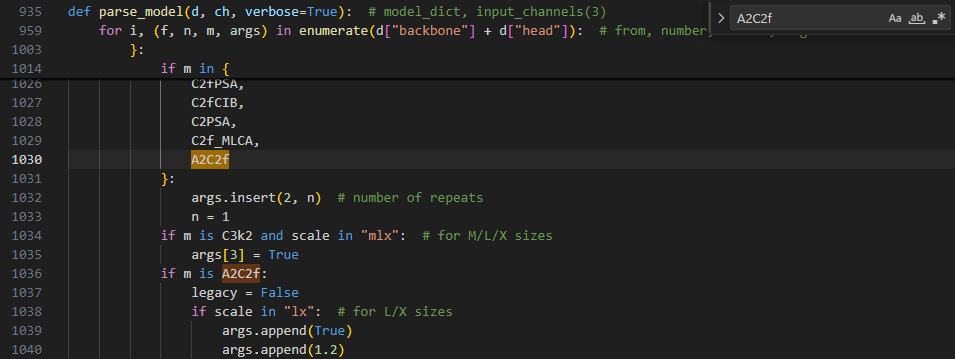
3.2.2.4 第四处:第三处下方添加
if m is A2C2f:
legacy = False
if scale in "lx": # for L/X sizes
args.append(True)
args.append(1.2)
3.2.3 创建YOLOv12的模型配置文件
创建文件 ultralytics-8.3.63/ultralytics/cfg/models/v12/yolov12.yaml.py
# YOLOv12 🚀, AGPL-3.0 license
# YOLOv12 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov12n.yaml' will call yolov12.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 465 layers, 2,603,056 parameters, 2,603,040 gradients, 6.7 GFLOPs
s: [0.50, 0.50, 1024] # summary: 465 layers, 9,285,632 parameters, 9,285,616 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 501 layers, 20,201,216 parameters, 20,201,200 gradients, 68.1 GFLOPs
l: [1.00, 1.00, 512] # summary: 831 layers, 26,454,880 parameters, 26,454,864 gradients, 89.7 GFLOPs
x: [1.00, 1.50, 512] # summary: 831 layers, 59,216,928 parameters, 59,216,912 gradients, 200.3 GFLOPs
# YOLO12n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 4, A2C2f, [512, True, 4]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 4, A2C2f, [1024, True, 1]] # 8
# YOLO12n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, A2C2f, [512, False, -1]] # 11
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, A2C2f, [256, False, -1]] # 14
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P4
- [-1, 2, A2C2f, [512, False, -1]] # 17
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 8], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 20 (P5/32-large)
- [[14, 17, 20], 1, Detect, [nc]] # Detect(P3, P4, P5)
4. 模型训练
4.1 官方训练脚本
from ultralytics import YOLO
model = YOLO('yolov12n.yaml')
# Train the model
results = model.train(
data='coco.yaml',
epochs=600,
batch=256,
imgsz=640,
scale=0.5, # S:0.9; M:0.9; L:0.9; X:0.9
mosaic=1.0,
mixup=0.0, # S:0.05; M:0.15; L:0.15; X:0.2
copy_paste=0.1, # S:0.15; M:0.4; L:0.5; X:0.6
device="0,1,2,3",
)
# Evaluate model performance on the validation set
metrics = model.val()
# Perform object detection on an image
results = model("path/to/image.jpg")
results[0].show()
4.2 我的训练脚本
from ultralytics import YOLO
# Load a model
model = YOLO("/home/xxx/ultralytics-8.3.63/ultralytics/cfg/models/v12/yolov12.yaml") # build a new model from YAML
# model = YOLO("yolo11n.pt") # load a pretrained model (recommended for training)
# model = YOLO("/home/xxx/ultralytics-8.3.63/ultralytics/cfg/models/11/yolo11n.yaml").load("/home/xxx/ultralytics-8.3.63/yolo11n.pt") # build from YAML and transfer weights
# Train the model
results = model.train(data="/home/miqi/ultralytics-8.3.63/ultralytics/cfg/datasets/VisDrone.yaml", device='1', batch=15, epochs=200, imgsz=640)
# model.info()
将模型名称修改为yolov12n.yaml、yolov12s.yaml、yolov12m.yaml、yolov12l.yaml 和 yolov12x.yaml,则分别对应 YOLOv12 的 n(nano)、s(small)、m(medium)、l(large)和 x(extra large)版本。如果仅使用 yolov12.yaml,则默认采用 n(nano)规模的模型配置。
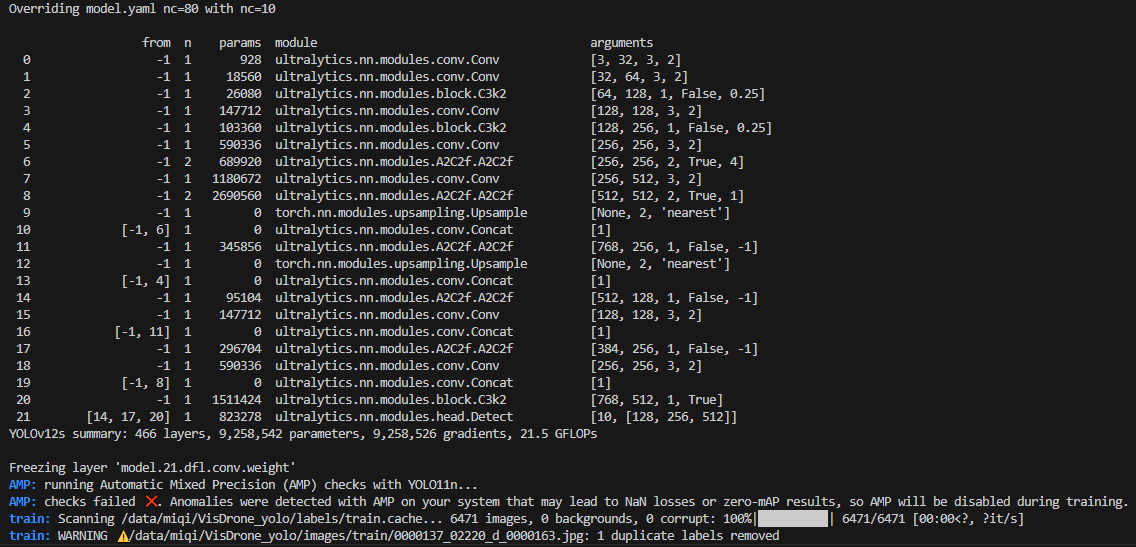
4.2.1 训练模型结果打印
5. YOLOv12局限性
YOLOv12 需要 FlashAttention,目前支持 Turing、Ampere、Ada Lovelace 或 Hopper 架构的 GPU(例如,T4、Quadro RTX 系列、RTX20 系列、RTX30 系列、RTX40 系列、RTX A5000/6000、A30/40、A100、H100 等)。
使用不支持的GPU架构会在终端抛出信息: FlashAttention is not available on this device. Using scaled_dot_product_attention instead.,还会出现多GPU训练情况下,卡位无法指定等问题。
USE_FLASH_ATTN = False
try:
import torch
if torch.cuda.is_available() and torch.cuda.get_device_capability()[0] >= 8: # Ampere or newer
from flash_attn.flash_attn_interface import flash_attn_func
USE_FLASH_ATTN = True
else:
from torch.nn.functional import scaled_dot_product_attention as sdpa
logger.warning("FlashAttention is not available on this device. Using scaled_dot_product_attention instead.")
except Exception:
from torch.nn.functional import scaled_dot_product_attention as sdpa
logger.warning("FlashAttention is not available on this device. Using scaled_dot_product_attention instead.")



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









