







hello,家人们好,今天我们来分享Map这个接口
目录
一.Map接口
-
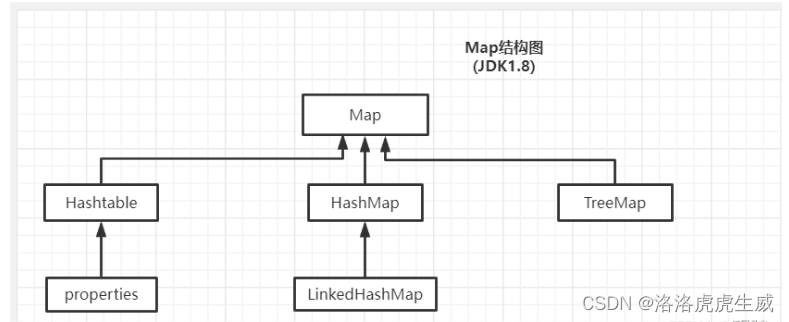
Map的类图
-
Map的特点
- 无序,键值对,键不能重复,值可以重复
- 键重复则覆盖,没有继承Collection接口
Entry键值对对象:用Entry键值对对象遍历Map集合的原理:
Map中存放的是两种对象,一种称为key(键),一种称为value(值),它们在在Map中是一一对应关系,这一对对象又称做Map 中的一个Entry(项)。Entry将键值对的对应关系封装成了对象。即键值对对象,这样我们在遍历Map集合时,就可以从每一个键值对(Entry)对象中获取对应的键与对应的值.
-
Map的扩容
初始容量16,负载因子0.75,扩容增量1倍
-
Map的遍历
先获取所有键的Set集合,再遍历(通过键获取值)
取出保存所有Entry的Set,再遍历此Set即可
-
Map的异常
Map接口中键和值一一映射. 可以通过键来获取值。
给定一个键和一个值,你可以将该值存储在一个Map对象. 之后,你可以通过键来访问对应的值。
当访问的值不存在的时候,方法就会抛出一个NoSuchElementException异常.
当对象的类型和Map里元素类型不兼容的时候,就会抛出一个 ClassCastException异常。
当在不允许使用Null对象的Map中使用Null对象,会抛出一个NullPointerException 异常。
当尝试修改一个只读的Map时,会抛出一个UnsupportedOperationException异常
-
Map基本操作:
Map 初始化
Map<String, String> map = new HashMap<String, String>();
插入元素
map.put("key1", "value1");
获取元素
map.get("key1")
移除元素
map.remove("key1");
清空map
map.clear();
Map的实现类
-
HashMap
1.hashMap的原理
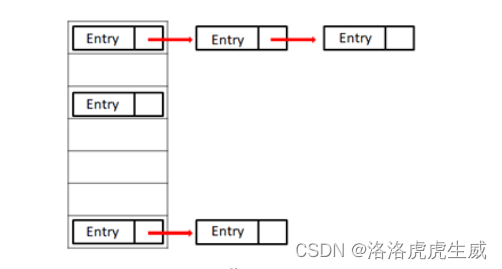
hashMap是由数组和链表这两个结构来存储数据。
数组:存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);寻址容易,插入和删除困难;
链表:存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N);寻址困难,插入和删除容易。
hashMap则结合了两者的优点,既满足了寻址,又满足了操作,为什么呢?关键在于它的存储结构。
它底层是一个数组,数组元素就是一个链表形式,见下图:
2.put执行过程:
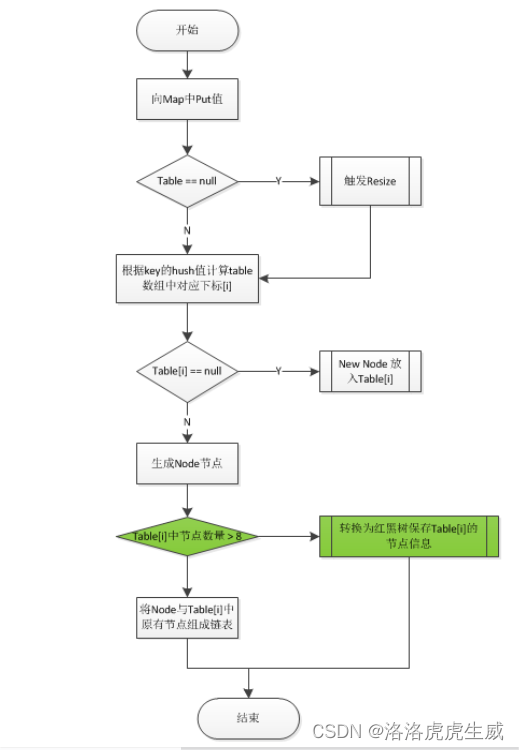
put方法的主要逻辑如下:
- 先获取
synchronized锁。 - put方法不允许
null值,如果发现是null,则直接抛出异常。 - 计算
key的哈希值和index - 遍历对应位置的链表,如果发现已经存在相同的hash和key,则更新value,并返回旧值。
- 如果不存在相同的key的Entry节点,则调用
addEntry方法增加节点。 addEntry方法中,如果需要则进行扩容,之后添加新节点到链表头部
3.HashMap的特点:
1.HashMap是可以序列化的。是线程不安全的
2.HashMap可以接受null键值和值.
3.HashMap的底层主要是基于数组和链表实现的,它之所以有相当快的查询速度主要是因为它是通过计算散列码来决定存储位置的
4.HashMap中主要是通过key的hashCode来计算hash值,然后通过hash值选择不同的数组来存储。只要hashCode相同,计算出来的hash值就一样,如果存储对象多了,就有可能不同的对象计算出来的hash值是相同的,这就出现了所谓的hash冲突,HashMap的底层是通过链表来解决hash冲突的。具体就是把相同hash值的HashMap,通过链表的形式进行存储,相当于存储的数组就是哈希表,数组的每个元素都是一个单链表的头结点,链表是用来解决hash冲突的,如果不同的key映射到了数组的同一位置,那么就将其放入单链表中。
5.HashMap的遍历方式比较单一,一般分两步走:
获得Entry或key或value的Set集合;
通过Iterator迭代器遍历此Set集合
HashMap的缺点
1.缺陷就在于其高度依赖hash算法,如果key是自定义类,你得自己重写hashcode方法,写hash算法
2.hashmap的元素存储位置,除了元素key的hash值有关,还跟数组本身长度有关,如果扩容数组长度发生变化,必须把所有元素重新计算其index存放位置,所以尽可能事先确定hashmap的大小,防止扩容
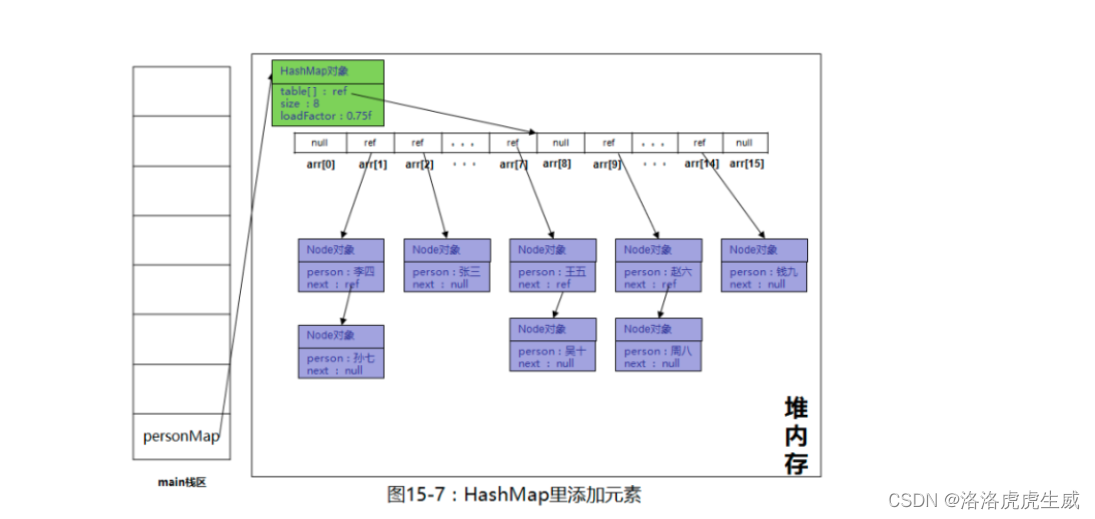
Table数组中的的Node:
链表结构示意图
红黑树结构示意图:
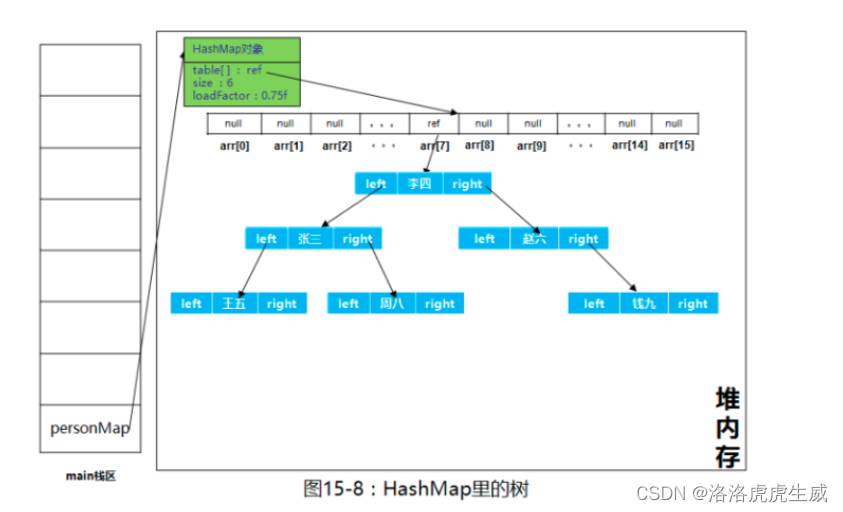
流程图中绿色标出的部分为JDK8新增的处理逻辑,目的是在Table[i]中的Node节点数量大于8时,通过红黑树提升查找速度
-
HashTable
1.HashTable的原理
HashTable类中,保存实际数据的,依然是Entry对象。其数据结构与HashMap是相同的
2.HashTable的优缺点
HashTable线程安全,但是不常用
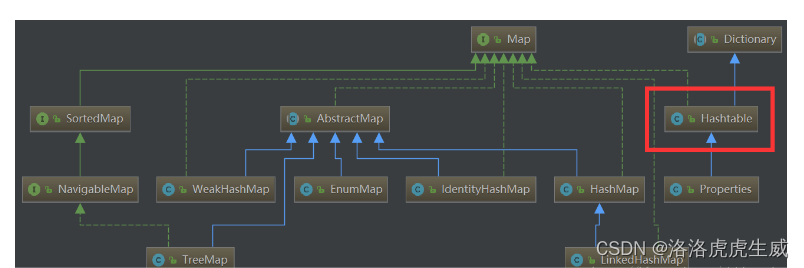
3.Hash Table的类图
-
ConcurrentHashMap
线程安全,比HashTable性能高
-
TreeMap
- 1.key值按一定的顺序排序,基于红黑树,容量无限制,非线程安全,比较常用
- 2.添加或获取元素时性能较HashMap慢(因为需求维护内部的红黑树,用于保证key值的顺序
- 3.能比较元素的大小,根据key比较(元素的自然顺序,集合中自定义的比较器也可排序
private TreeMap<String,Student> treeMap;
@Before
public void setup() {
treeMap = new TreeMap<String,Student>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
// 负数 0 正数
return o1.compareTo(o2);
}
});
treeMap.put("1", new Student(5, "小白"));
treeMap.put("2", new Student(3, "小黑"));
treeMap.put("3", new Student(2, "小黄"));
treeMap.put("4", new Student(4, "小明"));
treeMap.put("3", new Student(1, "小黑"));
treeMap.put("4", new Student(4, "小明"));
}-
LinkedHashMap
1.LinkedHashMap的原理
LinkedHashMap是hashmap和链表的结合体,通过链表记录元素的顺序和连接关系,通过hashmap来存储数据,可以控制元素被遍历的时候输出的顺序(按访问顺序,还是按照插入顺序)。
元素被保存在一个双向链表中,默认的遍历顺序是插入顺序来遍历,通过构造函数的accessOder来控制是否按照访问顺序来遍历,
linkedHashMap总是将最近访问的元素放在队列的尾部,所以第一个元素就是最不经常访问的元素,当容量充满了时候就会将第一个元素移除。
- get的时候将当前被访问的这个对象移动到表的最后面。
- linkedHashmap 没有put方法,直接调用父类hashmap的put方法
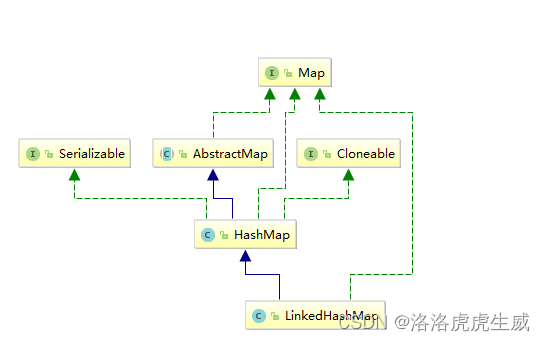
2.LinkedHashMap的类图
3.LinkedHashMap的特点
- 由于继承HashMap类,所以默认初始容量是16,加载因子是0.75。accessOrder为false时,表明按照插入顺序访问;为true时,表明按照访问顺序访问
- 线程不安全,可以使用Map m = Collections.synchronizedMap(new LinkedHashMap(…)); 来实现线程安全的操作
- 具有fail-fast的特征
- 底层使用双向链表,可以保存元素的插入顺序,顺序有两种方式:一种是按照插入顺序排序,一种按照访问做排序。默认以插入顺序排序
- key和value允许为null,key重复时,新value覆盖旧value
4.代码演示:
Map<String, String> linkedHashMap = new LinkedHashMap<>();
linkedHashMap.put("name1", "josan1");
linkedHashMap.put("name2", "josan2");
linkedHashMap.put("name3", "josan3");
Set<Entry<String, String>> set = linkedHashMap.entrySet();
Iterator<Entry<String, String>> iterator = set.iterator();
while(iterator.hasNext()) {
Entry entry = iterator.next();
String key = (String) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}今天的代码就到这里啦,家人们下期见~
今天也要记得微笑呀.















 2808
2808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









